上一篇讲了transformer的原理,接下来,看看它的衍生物们。
Transformer基本架构
Transformer模型主要由两部分组成:编码器(Encoder)和解码器(Decoder)。编码器负责处理输入序列,将其转换为一系列内部表示;解码器则根据这些内部表示生成输出序列。编码器和解码器都由多个相同的层堆叠而成,每层包括自注意力机制和全连接前馈网络两个子层,子层之间采用残差连接和层归一化技术。
自注意力机制是Transformer的核心所在,它通过计算输入序列中每个位置上的向量表示之间的相似度,为每个位置生成一个权重向量。这样,模型就能够在处理每个位置上的向量时,考虑到其他所有位置上的信息,从而实现对全局信息的捕捉。全连接前馈网络则负责进一步处理自注意力机制的输出,提取更高级的特征表示。
随着研究的深入,Transformer模型也涌现出了许多变种。这些变种模型在保持基本架构不变的基础上,对某些组件进行了改进或添加新的组件,以提高模型的性能或适应不同的任务需求。
1.bert(Bidirectional Encoder Representations from Transformers)
前面有一些bert原理相关的博客,这里主要讲下主要区别,不对原理深究。
BERT是Transformer的一个重要变种,它采用全连接的双向Transformer编码器结构,通过预训练的方式学习通用的语言表示。BERT在预训练时采用了两种任务:遮盖语言建模(Masked Language Modeling)和下一句预测(Next Sentence Prediction)。这两种任务使得BERT能够捕获到丰富的上下文信息,从而在下游任务中取得良好的表现。
BERT的双向表示前,先回顾一下常见的双向表示
网络结构的双向:首先区别于biLSTM那种双向, 那种是在网络结构上的双层
例如 biLSTM来进行一个单词的双向上下文表示
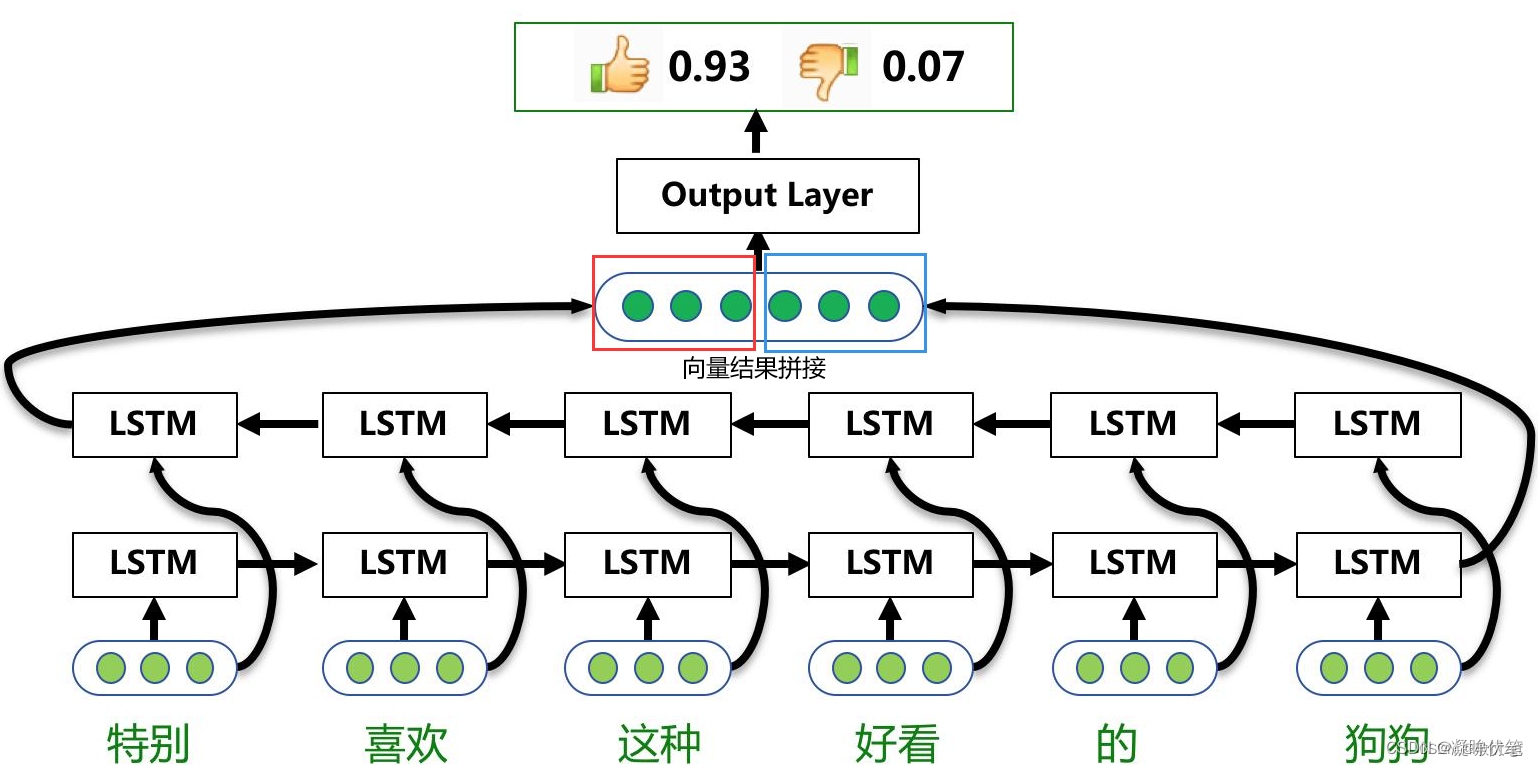
如图所示:单层的BiLSTM是由两个LSTM组合而成,一个是正向去处理输入序列;另一个反向处理序列,处理完成后将两个LSTM的输出拼接起来。在上图中,只有所有的时间步计算完成后,才能得到最终的BiLSTM的输出结果。正向的LSTM经过6个时间步得到一个结果向量;反向的LSTM同样经过6个时间步后得到另一个结果,将这两个结果向量拼接起来,得到最终的BiLSTM输出结果。
请注意,BERT并没有说讲一个序列反向输入到网络中,所以BERT并不属于这种。
用Bi-RNN或Bi-LSTM来“同时从左到右、从右到左扫描序列数据”。Bi-RNN是一种双向语言模型,刻画了正反两个方向上,序列数据中的时空依赖信息。双向语言模型,相比RNN等单向模型,可以提取更多的信息,模型潜力也更大。
Transformer也可以用来构建双向语言模型。最粗暴的方式,就是Bi-Transformer,即让2个Transformer分别从左到右和从右到左扫描输入序列。当然,这样做的话,模型参数太多,训练和推断阶段耗时会比较大。
BERT没有在Transformer的结构上费工夫,而是采用特别的训练策略,迫使模型像双向模型一样思考。这种训练策略就是随机遮蔽词语预测。BERT会对一个句子的token序列的一部分(15%)进行处理:(1)以80%的概率遮蔽掉;(2)以10%的概率替换为其他任意一个token;(3)以10%的概率保持。
预训练任务是一个mask LM ,通过随机的把句子中的单词替换成mask标签, 然后对单词进行预测。
这里注意到,对于模型,输入的是一个被挖了空的句子, 而由于Transformer的特性, 它是会注意到所有的单词的,这就导致模型会根据挖空的上下文来进行预测, 这就实现了双向表示, 说明BERT是一个双向的语言模型。
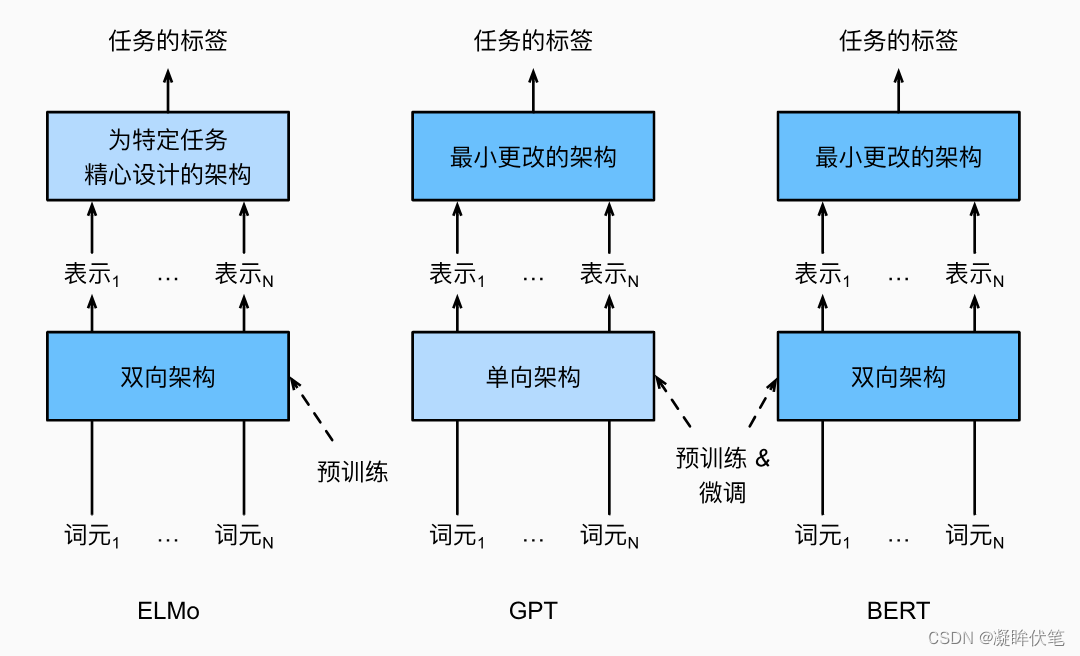
如我们所见,ELMo对上下文进行双向编码,但使用特定于任务的架构;而GPT是任务无关的,但是从左到右编码上下文。BERT(来自Transformers的双向编码器表示)结合了这两个方面的优点。它对上下文进行双向编码,并且对于大多数的自然语言处理任务 (Devlin et al., 2018)只需要最少的架构改变。通过使用预训练的Transformer编码器,BERT能够基于其双向上下文表示任何词元。在下游任务的监督学习过程中,BERT在两个方面与GPT相似。首先,BERT表示将被输入到一个添加的输出层中,根据任务的性质对模型架构进行最小的更改,例如预测每个词元与预测整个序列。其次,对预训练Transformer编码器的所有参数进行微调,而额外的输出层将从头开始训练。 描述了ELMo、GPT和BERT之间的差异。
2.gpt
GPT(Generative Pre Training,生成式预训练)模型为上下文的敏感表示设计了通用的任务无关模型 (Radford et al., 2018)。GPT建立在Transformer解码器的基础上,预训练了一个用于表示文本序列的语言模型。当将GPT应用于下游任务时,语言模型的输出将被送到一个附加的线性输出层,以预测任务的标签。与ELMo冻结预训练模型的参数不同,GPT在下游任务的监督学习过程中对预训练Transformer解码器中的所有参数进行微调。GPT在自然语言推断、问答、句子相似性和分类等12项任务上进行了评估,并在对模型架构进行最小更改的情况下改善了其中9项任务的最新水平。
然而,由于语言模型的自回归特性,GPT只能向前看(从左到右)。在“i went to the bank to deposit cash”(我去银行存现金)和“i went to the bank to sit down”(我去河岸边坐下)的上下文中,由于“bank”对其左边的上下文敏感,GPT将返回“bank”的相同表示,尽管它有不同的含义。
3.Transformer-XL
Transformer-XL旨在解决Transformer在处理长序列时遇到的问题。它通过引入分段循环机制和相对位置编码,使得Transformer能够处理更长的序列。此外,Transformer-XL还采用了分段注意力机制,以减少计算量和内存消耗。
4.gpt2
5.gpt3
6.chatgpt
7.大模型
其它:
transformer:
编码器可以用来做分类任务,解码器可以用来做语言建模。应用到各大主流模型中,会有意想不到的效果,最近看的论文中,大多从transformer中摘取一些结构,用在业务场景模型中。
参考:
1.双向lstm
2.bert
3.变体概要



![汇编原理(四)[BX]和loop指令](https://img-blog.csdnimg.cn/direct/6880f21668b942d9829a7d8e6fb2673d.png)