原理分析
pg_lakehouse 是 ParadeDB 推出的一个开源插件,支持对多种数据湖里的数据做分析计算。它的出现,使得 Postgres 能够像访问本地数据一样轻松访问 S3 等对象存储,轻松访问 Delta Lake 上的表格,具备数据湖分析能力。
pg_lakehouse 的查询计算能力是通过 Apache DataFusion 来支持的。DataFusion 是一个纯计算引擎,它不负责存储,内置了几种数据格式支持,并且可以通过 TableProvider 接口支持更多的数据输入方式[ref]。
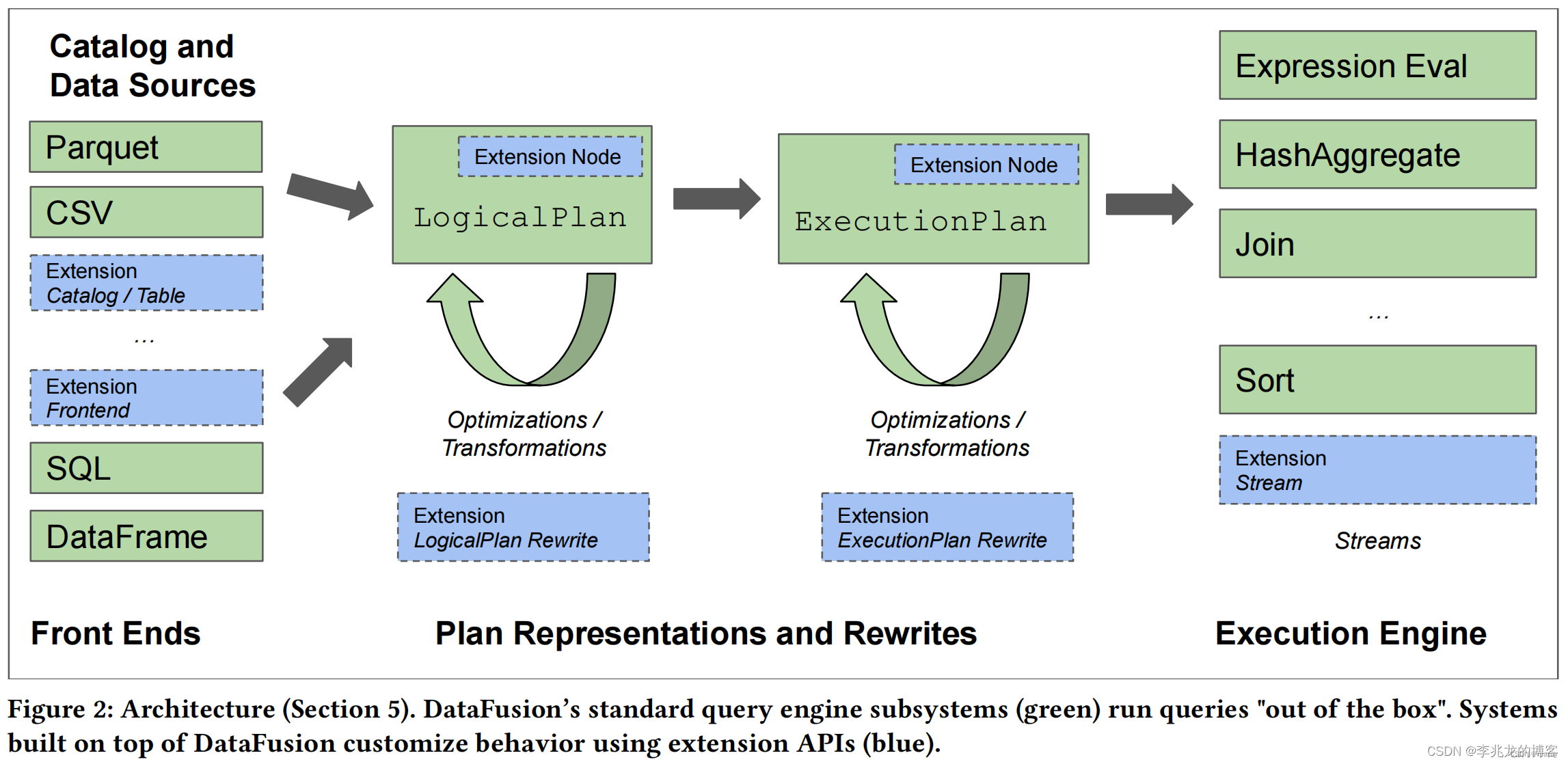
从原来上看, pg_lakehouse 提供了一组访问数据湖的方法,并将这些方法和 DataFusion 的计算能力结合起来,帮助 Postgres 获得分析数据湖数据的能力。
也就是说,Postgres 基于 pg_lakehouse 做数据湖分析时,计算能力主要靠 pg_lakehouse 提供,而不是依赖 Postgres 自身的计算引擎。Postgres 的价值在于给用户提供一个一致的操作界面,如 SQL dialect、schema view、生态工具等。
用户访问数据湖的整体交互流程如下:
SQL -(pgsql)-> Postgres --> pg_lakehouse -(FDW, DF understandable SQL Dialect)-> DataFusion
pg_lakehouse 对数据湖的访问,是基于 postgres 外表界面实现的。有几点需要注意:
- 集成湖的 catalog 不是必须的。Doris 等湖仓一体的数据库为了简化用户使用,会做 Multi External Catalog 集成,自动导入外表 schema。pg_lakehouse 依然要求用户在 Postgres 中创建外表。
- pg_lakehouse 支持通过 arrow_schema function 来自动获取湖中数据的 schema
- Postgres 还支持类似这样的语法批量导入外部 schema(但对于 lakehouse 的支持程度如何暂未调研):
import foreign schema public from server duckdb into public;
Thinking in MyDB
对于 MyDB 来说,计算引擎部分依然是使用 MyDB 自身的计算引擎,无需依赖第三方(如 DataFusion、Volex)。
MyDB 重点是实现可扩展的数据湖接入策略,降低接入新存储、新格式的成本。我们要区分好 Object Stores、File Format 和 Table Format 三方面的需求,各自做好扩展。
Object Stores:
- Amazon S3
- Aliyun OSS
- Tencent Cloud COS
- Huawei Cloud OBS
- S3-compatible object stores (e.g. MinIO)
- Azure Blob Storage
- Azure Data Lake Storage Gen2
- Google Cloud Storage
- Local file system
- potentially any service supported by Apache OpenDAL.
File Formats
- Parquet
- CSV
- JSON
- Avro
- ORC
Table Formats
- Delta Lake
- Apache Iceberg
- MaxCompute
Schema 的集成,要做一些聪明的事情。External Catalog 固然美好,但增加了对外部系统的依赖,压力大的情况下,外部系统可能先挂。如果能提供一套快速创建、刷新 External Table 的方法,也不失为一种好的解决方案。
参考
组件说明:
ParadeDB is an Elasticsearch alternative built on Postgres. We’re modernizing the features of Elasticsearch’s product suite, starting with real-time search and analytics.
pg_lakehouse is an extension that transforms Postgres into an analytical query engine over object stores like S3 and table formats like Delta Lake. Queries are pushed down to Apache DataFusion, which delivers excellent analytical performance. Combinations of the following object stores, table formats, and file formats are supported.
DataFusion includes several built in data sources for common use cases, and can be extended by implementing the TableProvider trait. A TableProvider provides information for planning and an ExecutionPlans for execution.
DataFusion Motivation
Today, a vast amount of non-operational data — events, metrics, historical snapshots, vendor data, etc. — is ingested into data lakes like S3. Querying this data by moving it into a cloud data warehouse or operating a new query engine is expensive and time consuming. The goal of pg_lakehouse is to enable this data to be queried directly from Postgres. This eliminates the need for new infrastructure, loss of data freshness, data movement, and non-Postgres dialects of other query engines.
.
pg_lakehouse uses the foreign data wrapper (FDW) API to connect to any object store or table format and the executor hook API to push queries to DataFusion. While other FDWs like aws_s3 have existed in the Postgres extension ecosystem, these FDWs suffer from two limitations:
.
Lack of support for most object stores, file, and table formats
Too slow over large datasets to be a viable analytical engine
pg_lakehouse differentiates itself by supporting a wide breadth of stores and formats (thanks to OpenDAL) and by being very fast (thanks to DataFusion).
FDW 工作原理:
在 PostgreSQL 中,外部数据包装器(Foreign Data Wrapper,FDW)允许一个 PostgreSQL 服务器访问外部数据源,如另一个 SQL 或 NoSQL 数据库。FDW 的工作机制基于 SQL/MED ("SQL Management of External Data") 标准,这提供了一个框架来访问和管理存储在不同数据源中的数据。
PostgreSQL FDW 如何工作主要包括以下步骤:
1. 加载和创建 FDW 扩展:
第一步是在 PostgreSQL 数据库中加载和创建相应的 FDW 扩展。例如,postgres_fdw 用于连接远程 PostgreSQL 服务器,其他 FDW 如 mysql_fdw 用于 MySQL 数据库连接等。
2. 定义外部服务器和用户映射:
在 PostgreSQL 中,指定外部数据源的详细信息,比如服务器地址、端口、登录凭证等,并为本地用户创建映射以授权远程数据访问。
3. 创建外部表:
定义外部表,这些表代表远程数据源中的表。这个步骤将远程表的模式映射到 PostgreSQL 中,来决定哪些列和数据类型将被访问。
4. 查询外部表:
当本地 PostgreSQL 服务器上的用户查询外部表时,查询将被转发到 FDW。
SQL 转化过程:
当一个 SQL 查询是对一个外部表的操作时,FDW 会接管这个查询,并进行以下转换过程:
解析:FDW 分析本地查询的结构,这通常涉及解析 SQL 语句并理解所请求的目标数据、过滤条件、聚合操作和排序需求。
转换:然后,FDW 会把本地 SQL 查询翻译(或重写)成远程数据库系统理解的"方言"。例如,如果远程数据源是 MySQL 数据库,postgres_fdw 会将 PostgreSQL SQL 查询转换为 MySQL 可以理解的 SQL 查询。
执行:转换过的查询被发送到远程数据库,由远程数据库执行。
结果获取:查询结果从远程数据库返回到 PostgreSQL 服务器,并在必要时进行进一步的处理(例如,如果一些请求在远程数据库上不能完成,如某些类型的JOIN操作,那么这些操作需要在返回结果之后由 PostgreSQL 本身完成)。
结果返回:经处理的数据最终返回给客户端。
这个过程的某些环节可能依赖特定的 FDW 实现。比如,并非所有的查询条件和聚合操作都可以推送到所有类型的远程数据源进行处理。可能某些操作必须在本地 PostgreSQL 端完成,这取决于 FDW 的功能和远程数据源的限制。
FDW 的优势之一是它提供了一种透明的机制来访问外部数据,使得外部数据源的表现形式与本地表非常相似,使开发者能以统一的方式查询和操作数据。然而,性能和功能上的限制要依赖于具体的 FDW 实现和外部数据源的能力。







![PS Adobe Photoshop 2024 for Mac[破]图像处理软件[解]PS 2024安装教程[版]](https://img-blog.csdnimg.cn/direct/035c7706653c47abb314221bf0d0d998.png)