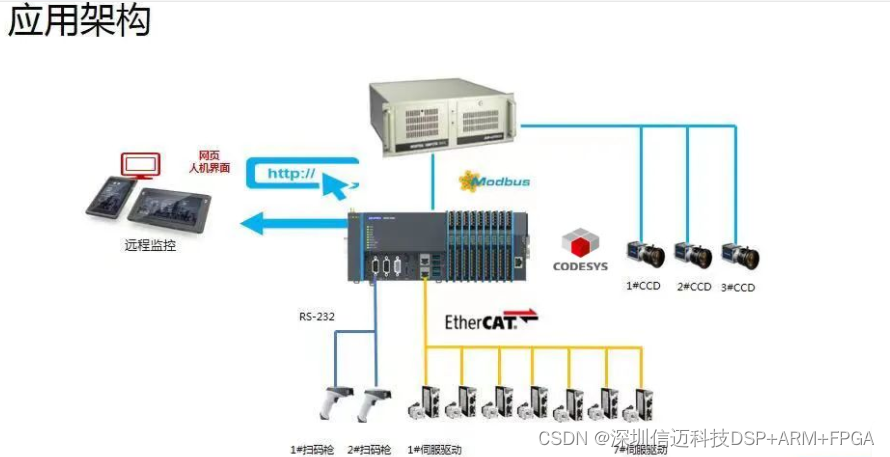
一.卷积神经网络
1. 导入资源包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import sklearn
import tensorflow as tf
from tensorflow import keras
注:from tensorflow import keras:从TensorFlow库中导入Keras模块,它是TensorFlow的一个高级API,用于构建和训练神经网络。Keras提供了一个简洁的接口,使得构建复杂的神经网络变得更加容易。
2.数据导入与数据观察
from sklearn.datasets import load_sample_image
#由于图像的像素值通常在0到255之间,这里将其缩放到[0, 1]的范围,以便于后续处理和可视化。
china = load_sample_image("china.jpg") / 255
flower = load_sample_image("flower.jpg") / 255
plt.subplot(1,2,1)
plt.imshow(china)
plt.subplot(1,2,2)
plt.imshow(flower)
运行结果:

注:这段代码使用了Scikit-learn库来加载两个示例图像,并将它们调整为[0, 1]的灰度值范围,然后使用Matplotlib库将这两个图像分别显示在一个2x1的子图中。
2.1.打印出两个图像的维度
print("china.jpg的维度:",china.shape)
print("flower.jpg的维度:",flower.shape)
运行结果:

注:由于图像数据通常是一个NumPy数组,其形状表示为高度、宽度和通道数(如果图像有多个通道的话)。这里,china.shape将返回一个元组,表示图像的形状。
2.2.将两个图像数组组合成一个NumPy数组,并打印出形状。
images = np.array([china,flower])
images_shape = images.shape
print("数据集的维度:",images_shape)
运行结果:
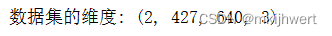
注:images = np.array([china,flower]):这行代码将两个图像数组(china和flower)作为列表的元素,并使用NumPy的array函数将它们组合成一个多维数组。这个数组可能包含两个图像,每个图像是一个二维数组(高度 x 宽度)。
3.卷积层
u = 7 #卷积核的边长
s = 1 #滑动步长
p = 5 #输入特征图数目
conv = keras.layers.Conv2D(filters = p, kernel_size = u, strides = s,
padding = "SAME", activation="relu", input_shape=images_shape)
image_after_conv = conv(images)
print("卷积后的张量大小:", image_after_conv.shape)
#activation = "relu":指定激活函数为ReLU
运行结果:

注:这段代码定义了一个二维卷积层(Conv2D),并将这个卷积层应用于一个名为images的NumPy数组。代码中的参数u、s和p分别表示卷积核的边长、滑动步长和输入特征图的数量。
4.汇聚层
4.1.最大汇聚
pool_max = keras.layers.MaxPool2D(pool_size=2)
#这行代码将image_after_conv张量作为输入传递给最大汇聚层pool_max,并计算汇聚操作后的输出。
image_after_pool_max = pool_max(image_after_conv)
print("最大汇聚后的张量大小:",image_after_pool_max.shape)
运行结果:

注:这段代码定义了一个最大汇聚层(MaxPool2D),并将这个汇聚层应用于之前通过卷积层(Conv2D)处理过的图像张量(image_after_conv)。代码中的参数pool_size定义了汇聚操作的窗口大小。
4.2.平均汇聚
pool_avg = keras.layers.AvgPool2D(pool_size=2)
image_after_pool_avg = pool_avg(image_after_conv)
print("平均汇聚后的张量大小:",image_after_pool_avg.shape)
运行结果:
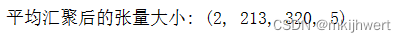
注:平均汇聚层通常用于减少特征图的大小,同时保留重要信息。通过将窗口内的值进行平均,平均汇聚层可以捕捉到图像中的关键特征。汇聚操作后,输出特征图的尺寸会减小,但每个元素都是通过计算窗口内所有元素的平均值得到的,因此保留了更多的上下文信息。
4.3.全局平均汇聚
pool_global_avg = keras.layers.GlobalAvgPool2D()
image_after_pool_global_avg = pool_global_avg(image_after_conv)
print("全局平均汇聚后的张量大小:",image_after_pool_global_avg.shape)
运行结果:

注:这段代码定义了一个全局平均汇聚层(GlobalAvgPool2D),并将这个汇聚层应用于之前通过卷积层(Conv2D)处理过的图像张量(image_after_conv)。全局平均汇聚层会在整个输入特征图上执行平均汇聚操作,这意味着它会将输入特征图的每个元素都除以特征图的总元素数,以计算每个特征的平均值。
5.搭建卷积神经网络进行手写数字识别
5.1.导入并对数据进行预处理
train_Data = pd.read_csv('mnist_train.csv',header = None) #训练数据
test_Data = pd.read_csv('mnist_test.csv',header = None) #测试数据
X, y = train_Data.iloc[:,1:].values/255, train_Data.iloc[:,0].values #数据归一化
X_valid, X_train = X[:5000].reshape(5000,28,28) , X[5000:].reshape(55000,28,28) #验证集与训练集
y_valid, y_train = y[:5000], y[5000:]
X_test,y_test = test_Data.iloc[:,1:].values.reshape(10000,28,28)/255, test_Data.iloc[:,0].values #测试集
print(X_train.shape)
print(X_valid.shape)
print(X_test.shape)
运行结果:

注:这段代码的输出将显示各个数据集的形状,即它们的样本数量和每个样本的特征维度。对于MNIST数据集,每个样本是一个28x28的图像,因此每个样本有784个特征(28*28)。
5.2.扩张为四维张量
X_train = X_train[..., np.newaxis]
X_valid = X_valid[...,np.newaxis]
X_test = X_test[...,np.newaxis]
print(X_train.shape)
print(X_valid.shape)
print(X_test.shape)
运行结果:

注:将这些数据集的形状从(样本数量, 高度, 宽度)扩展为(样本数量, 高度, 宽度, 通道数)。这是为了匹配卷积神经网络(CNN)的输入要求,其中通道数通常是1(对于灰度图像)或3(对于RGB彩色图像)。
5.3.搭建卷积神经网络
#搭建模型
model_cnn_mnist = keras.models.Sequential([
keras.layers.Conv2D(32, kernel_size=3, padding="same", activation="relu"),
keras.layers.Conv2D(64, kernel_size=3, padding="same", activation="relu"),
keras.layers.MaxPool2D(pool_size=2),
keras.layers.Flatten(),
keras.layers.Dropout(0.25),
keras.layers.Dense(128, activation="relu"),
keras.layers.Dropout(0.5),
keras.layers.Dense(10, activation="softmax")
])
#评估性能
model_cnn_mnist.compile(loss="sparse_categorical_crossentropy",optimizer="nadam",metrics=["accuracy"])
model_cnn_mnist.fit(X_train, y_train, epochs=10, validation_data=(X_valid, y_valid))
运行结果:

注:
第一层卷积层:使用32个大小的卷积核
第二层卷积层:使用64个大小的卷积核
第三层汇聚层:将所有特征映射的维度缩小至原先一半
第四层是平展层:将原先四维张量(55000,14,14,64)平展成两维张量(55000,),即将一个样本的所有参数项平展成一个维度
后续是全连接层
model_cnn_mnist.evaluate(X_test, y_test, batch_size=1)
运行结果:

注:使用model_cnn_mnist.evaluate方法来评估您的卷积神经网络(CNN)模型在MNIST测试集上的性能。这个方法将计算模型在测试数据上的损失和指标,这里是准确率。
model_cnn_mnist.summary()
运行结果:
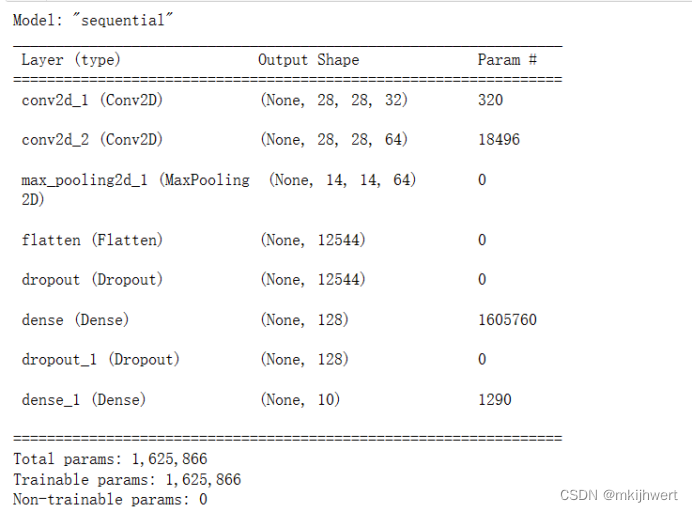
注:打印出模型的结构
6.利用函数式API与子类API搭建复杂神经网络
6.1.残差层
class ResidualUnit(keras.layers.Layer):
def __init__(self, filters, strides=1, activation="relu"):
super().__init__()
self.activation = keras.activations.get(activation)
self.main_layers = [
keras.layers.Conv2D(filters, 3, strides=strides, padding = "SAME", use_bias = False),
keras.layers.BatchNormalization(),
self.activation,
keras.layers.Conv2D(filters, 3, strides=1, padding = "SAME", use_bias = False),
keras.layers.BatchNormalization()]
# 当滑动步长s = 1时,残差连接直接将输入与卷积结果相加,skip_layers为空,即实线连接
self.skip_layers = []
# 当滑动步长s = 2时,残差连接无法直接将输入与卷积结果相加,需要对输入进行卷积处理,即虚线连接
if strides > 1:
self.skip_layers = [
keras.layers.Conv2D(filters, 1, strides=strides, padding = "SAME", use_bias = False),
keras.layers.BatchNormalization()]
def call(self, inputs):
Z = inputs
for layer in self.main_layers:
Z = layer(Z)
skip_Z = inputs
for layer in self.skip_layers:
skip_Z = layer(skip_Z)
return self.activation(Z + skip_Z)
注:定义了一个名为ResidualUnit的类,它继承自keras.layers.Layer,用于创建残差单元(Residual Unit),这是深度学习中常用的一种网络结构,特别是在残差网络(ResNet)中。残差单元允许网络在深层中传播信息,通过跳跃连接(skip connections)来缓解梯度消失问题,从而使网络能够成功训练更深的层次。
6.2.搭建完整的ResNet-34神经网络
model = keras.models.Sequential()
model.add(keras.layers.Conv2D(64, 7, strides=2, padding = "SAME", use_bias = False))
model.add(keras.layers.BatchNormalization())
model.add(keras.layers.Activation("relu"))
model.add(keras.layers.MaxPool2D(pool_size=3, strides=2, padding="SAME"))
prev_filters = 64
for filters in [64] * 3 + [128] * 4 + [256] * 6 + [512] * 3:
strides = 1 if filters == prev_filters else 2 #在每次特征图数目扩展时,设置滑动步长为2
model.add(ResidualUnit(filters, strides=strides))
prev_filters = filters
model.add(keras.layers.GlobalAvgPool2D())
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(10, activation="softmax"))
model.compile(loss="sparse_categorical_crossentropy",optimizer="sgd",metrics=["accuracy"])
model.fit(X_train, y_train, epochs=10, validation_data=(X_valid, y_valid))
model.evaluate(X_test, y_test, batch_size=1)
运行结果:
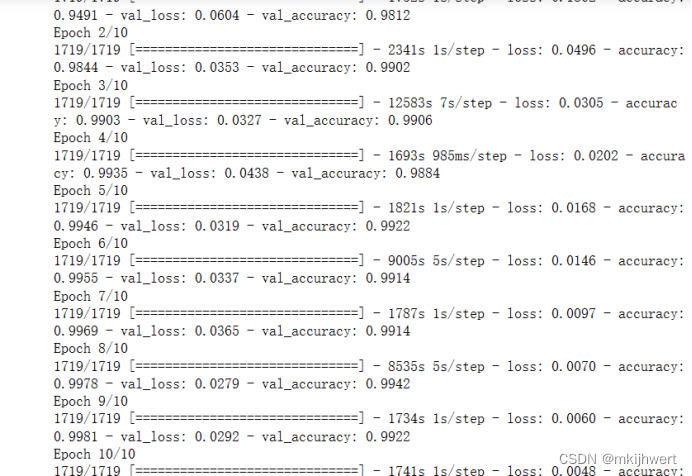
注:使用了一个循环来添加多个残差单元。残差单元的数量和过滤器数量根据您提供的列表 [64] * 3 + [128] * 4 + [256] * 6 + [512] * 3 来确定。在每次特征图数目扩展时,即从64到128,从128到256,从256到512时,您将步长设置为2,以便在空间维度上进行下采样。
二.总结:前馈神经网络与卷积神经网络的区别
1.结构差异:
前馈神经网络:由输入层、一个或多个隐藏层以及输出层组成,每层之间的神经元完全连接。前馈网络通常用于处理非空间数据,如图像的像素值在输入时会被展平成一维向量。
卷积神经网络:由输入层、一个或多个卷积层、池化层、全连接层以及输出层组成。卷积层和池化层允许网络在处理数据时保留空间结构,因此非常适合处理图像和视频数据。
2.参数效率:
前馈神经网络:由于每层神经元之间的完全连接,前馈网络通常具有大量的参数,这使得网络在训练时更容易过拟合,尤其是在训练数据量有限的情况下。
卷积神经网络:通过权值共享和局部连接,卷积网络大大减少了参数的数量,这使得网络更加高效,并且能够在有限的数据上训练出更好的模型。
3.局部连接:
前馈神经网络:每一层的所有神经元都与上一层的所有神经元相连接。
卷积神经网络:卷积层中的神经元只与输入数据的一个局部区域连接,这反映了图像的局部性质。
4.平移不变性:
前馈神经网络:不具备平移不变性,即对输入数据的平移会改变网络的输出。
卷积神经网络:由于卷积操作的性质,卷积网络具有平移不变性,这意味着即使图像在空间上发生了平移,网络仍然能够识别出相同的模式。
5.池化操作:
前馈神经网络:不包含池化层,因此不会减少数据的空间维度。
卷积神经网络:通过池化层减少数据的维度,同时保留最重要的信息。


![PS Adobe Photoshop 2024 for Mac[破]图像处理软件[解]PS 2024安装教程[版]](https://img-blog.csdnimg.cn/direct/035c7706653c47abb314221bf0d0d998.png)