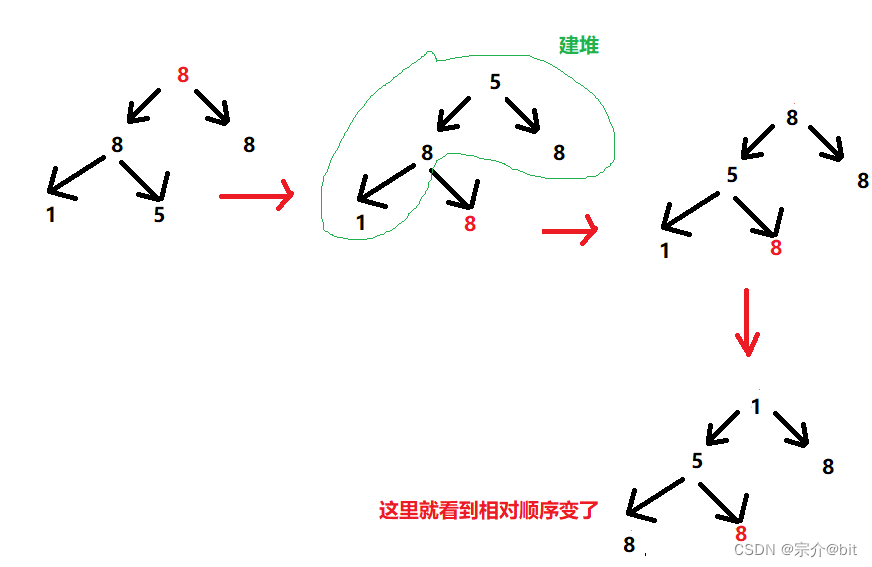
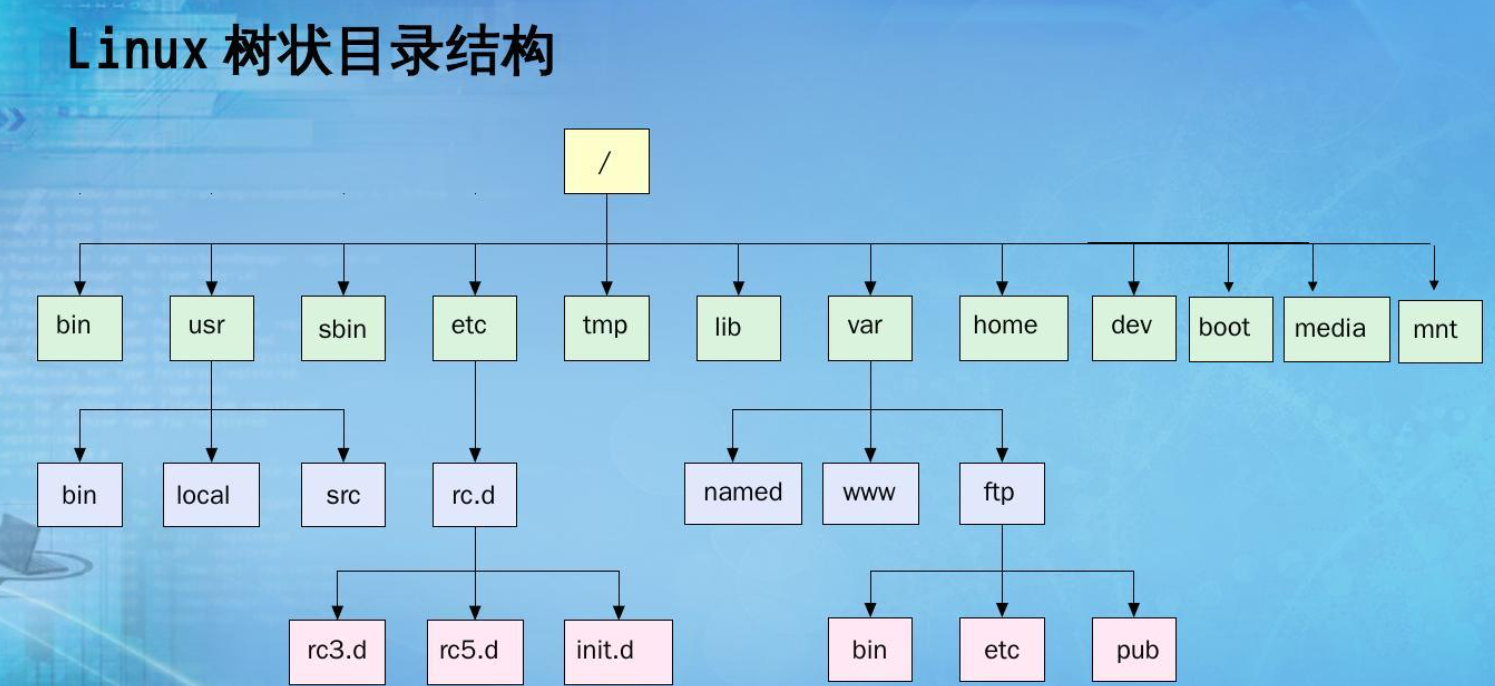
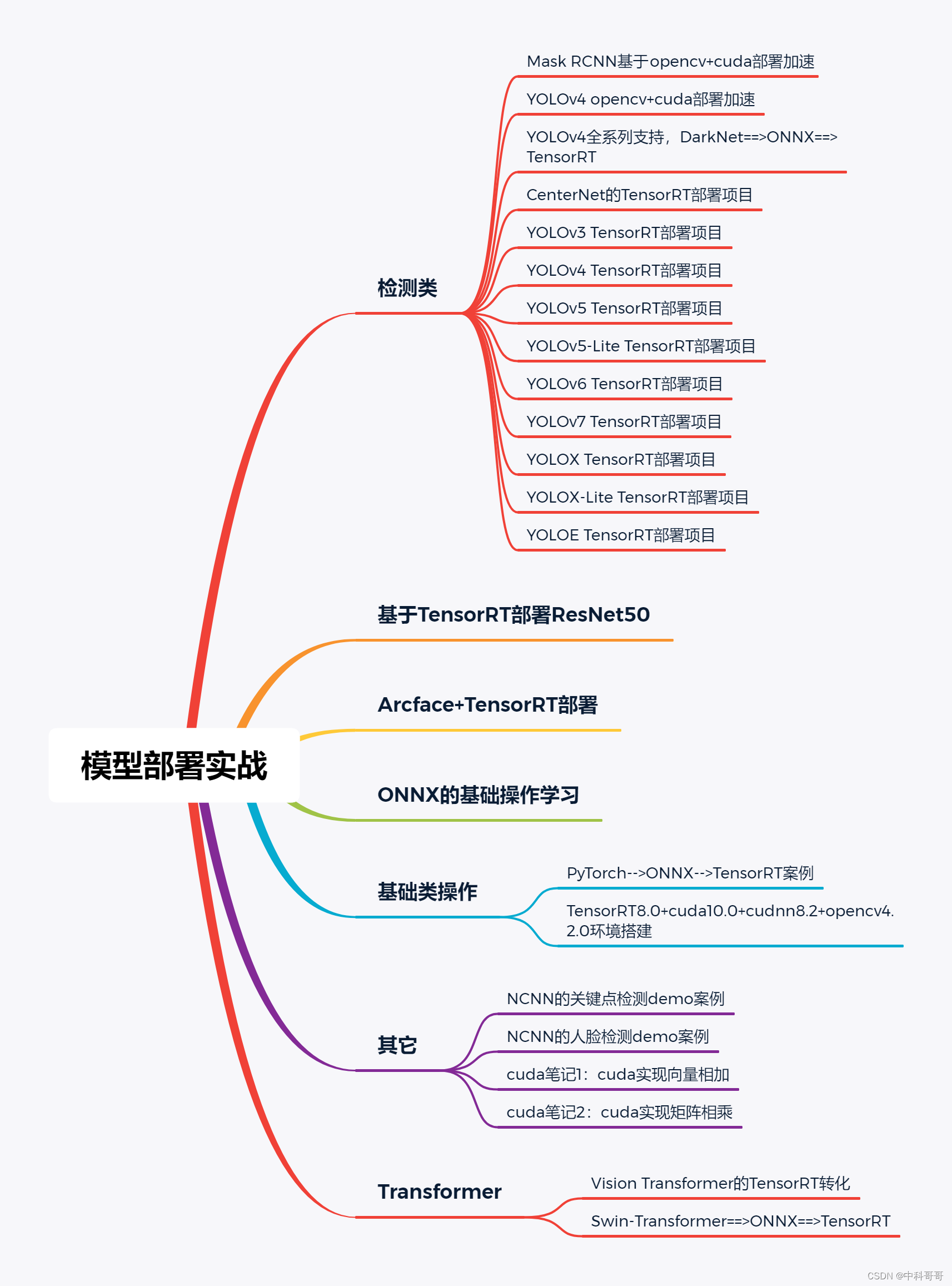
RB树
RB树和AVL树类似,是一种自平衡式的平衡二叉搜索树,AVL不是保证平衡因子不能超过1,红黑的话没有这个要求,他的结点非黑即红,可以达到Logn的查找,插入,删除
RB树的五条性质:
1、每个结点不是红的就是黑的,注意每次插入的结点都是红的,然后根据调整规则去改变最终的颜色
2、根结点一定是黑的
3、叶结点一定是黑的
4、每个红色结点他的子结点必须是黑的(就是从每个叶结点到根的路径上不能有两个连续的红色结点)
5、从任意的一个结点到叶子结点的各条路径上包含的黑色结点数一定相同
上面的性质就保证了从根到叶子结点的最长路径不会超过其根到叶节点最短路径的二倍,也就是所谓的达到一种自平衡
RB树的一些应用:

选AVL还是RB?

因为RB不追求完美的平衡,所以在插入删除过程中,任何不平衡的结点最多通过不会超过三次旋转就能达到平衡


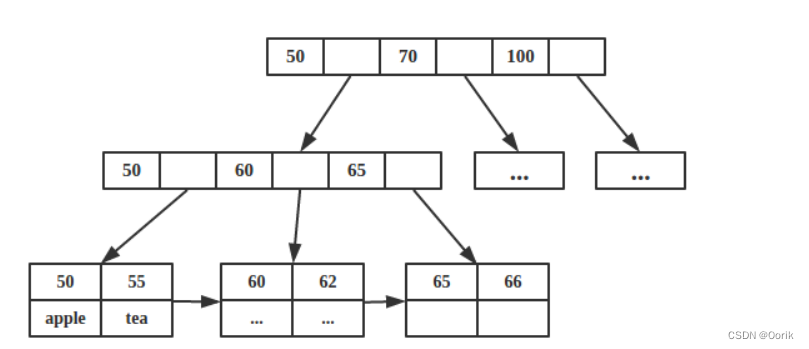
B树就是B-树
一种多叉搜索树,允许每个节点有更多的子节点,所以B树个子低,宽度宽
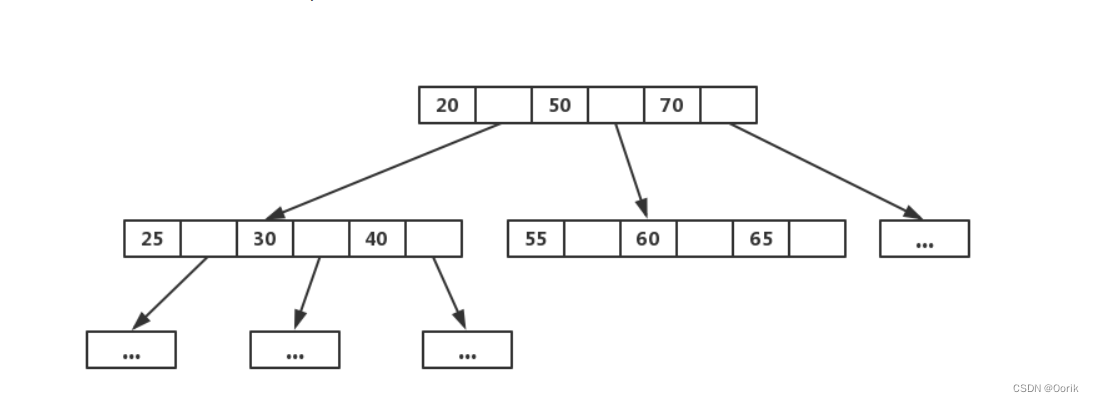
B树是为了磁盘,文件组织或者其他直接存取的辅助存储设备,数据索引,数据库索引,而设计的一种平衡查找树
他还有俩变种:B+树,B*树用在mysql底层

B-树的主要目的就是减少磁盘的 I/O 操作。大多数平衡树的操作(查找、插入、删除,最大值、最小值等等)需要 O(ℎ) 次磁盘访问操作,其中 ℎ 是树的高度。但是对于 B-树而言,树的高度将不再是 logn (其中 n是树中的结点个数),而是一个我们可控的高度 ℎ (通过调整 B-树中结点所包含的键【你也可以叫做数据库中的索引,本质上就是在磁盘上的一个位置信息】的数目,使得 B-树的高度保持一个较小的值)。
B树的相关定义特性:
对于一个M阶B树具有以下特性:M阶就是分支的个数
- 每个节点最多有
M个子节点;每个内部节点最少有⌈M/2⌉个子节点(⌈x⌉为向上取整符号); - 如果根节点不是叶子节点,那么它至少有两个子节点。
- 具有
N个子节点的非叶子节点拥有N-1个键。 - 所有叶子节点必须处于同一层上。

B树里面结点的信息:

B+树
因为内节点并不存储 data,所以一般B+树的叶节点和内节点大小不同,而B-树的每个节点大小一般是相同的,为一页
B+树内节点不存储数据,所有 data 存储在叶节点导致查询时间复杂度固定为 log n。而B-树查询时间复杂度不固定,与 key 在树中的位置有关,最好为O(1)。
一文彻底搞懂MySQL基础:B树和B+树的区别_
通俗易懂的图文 红黑树,B树,B+树 本质区别及应用场景 - 知乎 (zhihu.com)
键树
双链树和字典树是键树的两种表示方法,各有各的特点,具体使用哪种方式表示键树,需要根据实际情况而定。例如,若键树中结点的孩子结点较多,则使用字典树较双链树更为合适。
通过关键码找记录集
方便以某种关键字打头的字符串查找,什么意思,就是用在自动补齐的场景,你查东西打一个se,后面会出来很多种以se开头的字符串
优缺点:
键树的核心思想是空间换时间,
利用字符串的公共前缀来减少无谓的字符串的比较以达到提高查询效率的目的
找到具有同一前缀的全部键值。 按词典序枚举字符串的数据集。
长这样:
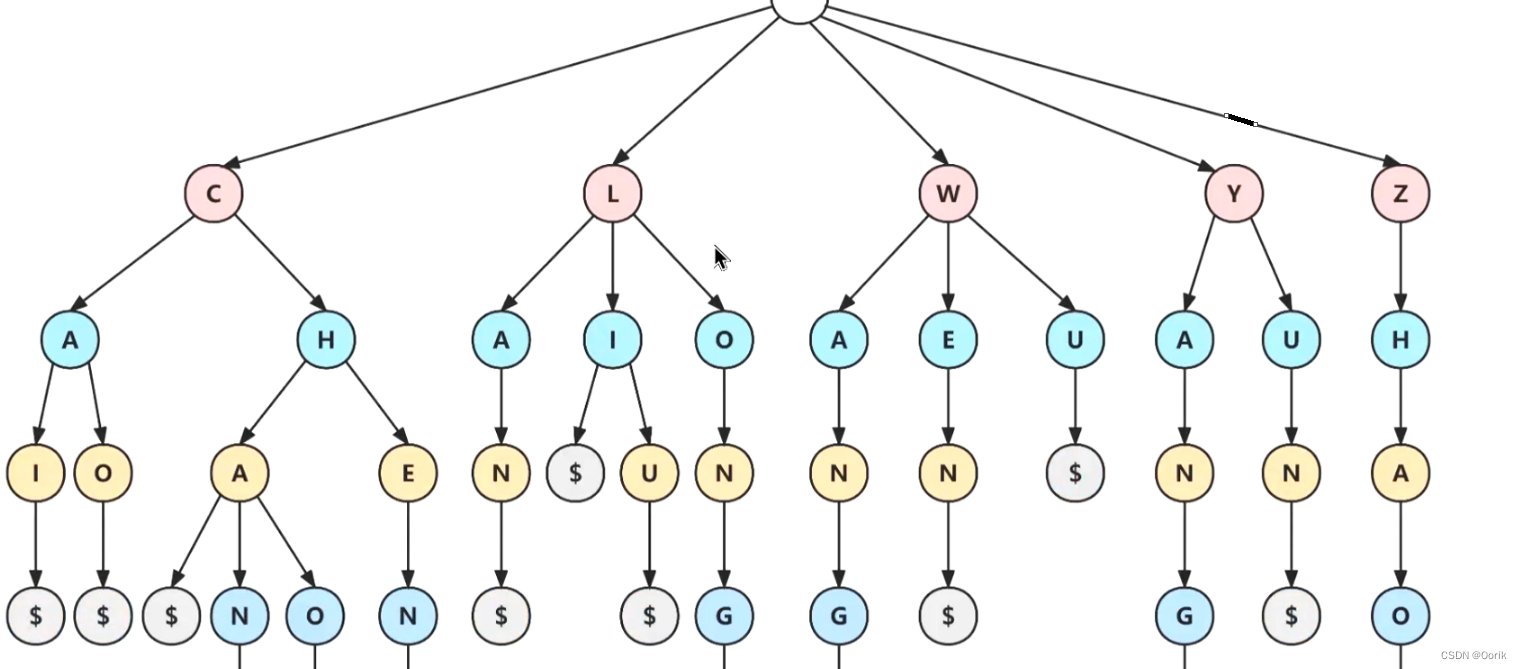
随着哈希表大小增加,会出现大量的冲突,时间复杂度可能增加到 O(n)与哈希表相比,Trie 树在存储多个具有相同前缀的键时可以使用较少的空间。此时 Trie 树只需要 O(m)的时间复杂度,其中 m 为键长(顶多5*m)。而在平衡树中查找键值需要 O(mlogn)时间复杂度。
键树的存储结构有两种:一种是通过使用树的孩子兄弟表示法来表示键树,即双链树;另一种是以树的多重链表表示键树,即 Trie 树,又称字典树。
实现方案:

这种方案就是把多叉树转成二叉树(结构上),左孩子右兄弟
俗称双链树的表现形式:
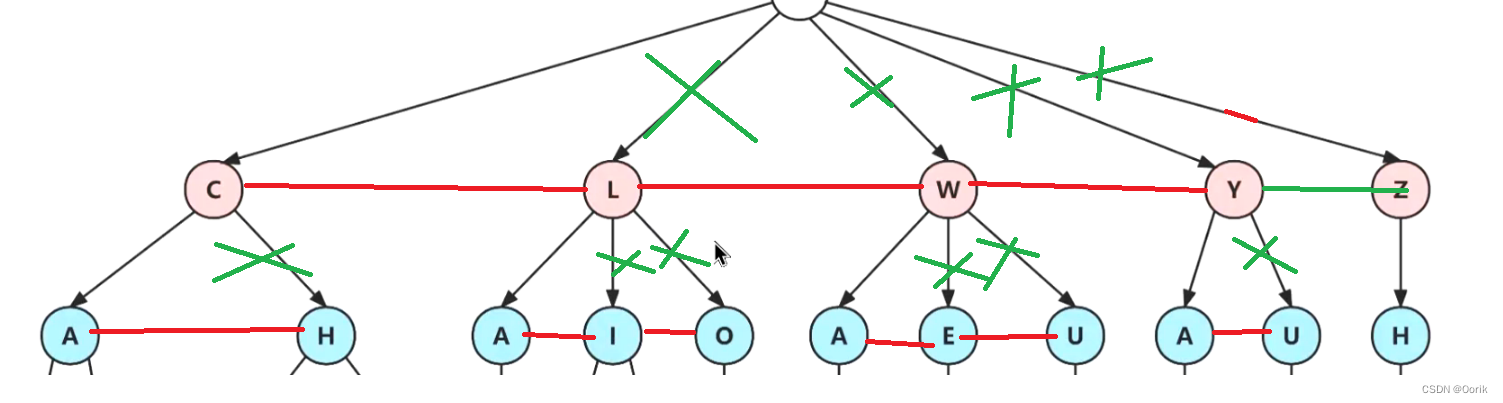
每个最下面叶子结点就挂着每条对应的记录集
用双链树结构的设置:
#define Nil '\0' //我们在叶结点尾巴给个标志,用来方便查询
const int MaxKeyLen=16;
typedef struct
{
//关键码类型
char ch[MaxKeyLen+1];
int num;//记录一下关键码里面字符的长度
}KeysType;
typedef struct
{ //记录集
KeysType keys;
//Other others;
int id;
}Record;
typedef enum{LEAF,BRACH}NodeKind;
//字典树的结点结构
typedef struct DLTNode
{
char symbol;//存储关键字的一个字符
struct DLTNode* next;//指向兄弟结点指针
union
{
Record *infoptr;//指向叶子结点的记录集
struct DLTNode *first;//指向分支结点的孩子链指针
};
}DLTNode;
typedef struct{//设计一个结构体,避免用二级指针
DLTNode* root;
int cursize;
}DLTTree;
初始化的简单函数
DLTNode* Buynode()
{
DLTNode*s=(DLTNode*)calloc(1,sizeof(DLTNode));
if(s==nullptr) exit(1);
return s;
}
void Freenode(DLTNode* node)
{
free(node);
}
void InitDLTTree(DLTTree* node)//初始化
{
assert(node!=nullptr);
node->root=Buynode();
node->cursize=0;
node->root->symbol=Nil;
}
根据上图模拟一下怎么去查询一条记录呢,其实也挺简单的
查找一个单词是否存在。
这里有两种情况:
查到一半发现单词断层了,这妥妥的没了、
查到最后,结果这个单词只是前缀,那也是不行的。
//查询记录集
Record *SerachRecord(DLTTree* node,KeysType kx)
{
Record *recptr=nullptr;
if(node==nullptr||node->root==nullptr)return recptr;
//开始遍历查询了
int i=0;//ch数组 字符集的下标
DLTNode*p=node->root->first;
while(p!=nullptr&&i<kx.num)
{
while(p!=nullptr&&p->symbol!=kx.ch[i])
{
p=p->next;//找兄弟
}
if(p!=nullptr&&i<kx.num)
{
p=p->first;//找孩子
}
i++;
}
if(p!=nullptr&&p->symbol==Nil)
{
recptr=p->infoptr;
}
return recptr;
}插入结点:
这有三种情况。
1、这个单词已经存在
2、这个单词已经是前缀了
3、这个单词不存在
对这三种情况,首先要做的都是遍历这棵树。
如果存在,那就没事儿了。
如果是前缀,那就改成完整的单词。
如果不存在,那就把缺少的字母补进去,并设为完整的单词。
void INsertItem(DLTTree *node,Record *ptr)
{
if(node==nullptr||ptr==nullptr||ptr->keys.num==0)
{
return ;
}
DLTNode*pa=node->root;
DLTNode *p=node->root->first;
DLTNode *s=nullptr;
int i=0;
while(p!=nullptr&&i<ptr->keys.num)
{
while(p->next!=nullptr&&ptr->keys.ch[i]>p->symbol)
{
pa=p;
p=p->next;
}
if(p->symbol!=ptr->keys.ch[i])break;
if(p->first!=nullptr&&p->symbol==ptr->keys.ch[i])
{
pa=p;
p=p->next;
}
++i;
}
s=Buynode();
s->symbol=ptr->keys.ch[i];
if(p==nullptr)
{
pa->first=s;
}
else if(ptr->keys.ch[i]<p->symbol)//变成第一个孩子
{
s->next=p;
pa->first=s;
}
else{//变成兄弟
pa=p;
p=p->next;
s->next=p;
pa->next=s;
}
//
s=pa;
for(i+=1;i<ptr->keys.num;++i)
{
s=Buynode();
s->symbol=ptr->keys.ch[i];
pa->first=s;
pa=s;
}
if(i<=ptr->keys.num)
{
s=Buynode();
}
s->symbol=Nil;
pa->first=s;
s->infoptr=ptr;
node->cursize+=1;
}Trie树实现:
若以树的多重链表表示键树,则树中如同双链树一样,会含有两种结点:
- 叶子结点:叶子结点中含有关键字域和指向该关键字的指针域;
- 除叶子结点之外的结点(分支结点):含有 d 个指针域和一个整数域(记录该结点中指针域的个数);
d 表示每个结点中存储的关键字的所有可能情况,如果存储的关键字为数字,则 d= 11(0—9,以及 $),同理,如果存储的关键字为字母,则 d=27(26个字母加上结束符 $)。
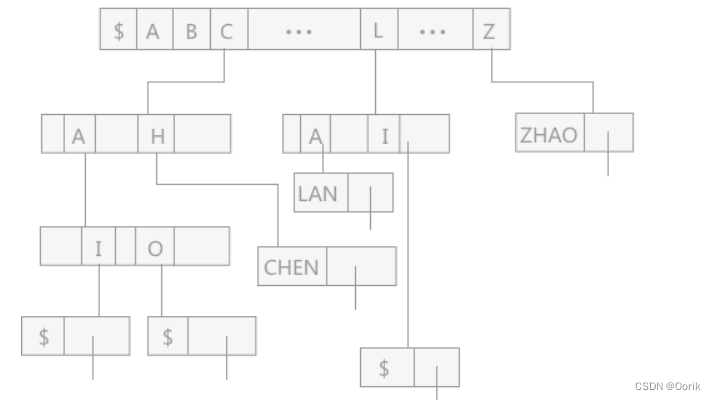
使用 Trie 树进行查找时,从根结点出发,沿和对应关键字中的值相对应的指针逐层向下走,一直到叶子结点,如果全部对应相等,则查找成功;反之,则查找失败。
使用 Trie 树进行查找的过程实际上是走了一条从根结点到叶子结点的路径,所以使用 Trie 进行的查找效率取决于该树的深度
const int MaxKeySize = 25;
const int LinkSize = 27;
typedef struct
{
char ch[MaxKeySize + 1];
int num;
}KeyType;
typedef struct { } Record;
typedef enum { ELEMENT = 0, BRANCH = 1 } NodeType;
struct TrieNode;
typedef struct
{
KeyType key;
Record* recptr;
}ElemType;
typedef struct
{
struct TrieNode* link[LinkSize];
int num;
}BrachType;
typedef struct TrieNode
{
NodeType utype; //
union
{
ElemType elem;
BrachType brch;
};
}TrieNode;
typedef struct
{
TrieNode* root;
}TrieTree;
TrieNode* Buynode()
{
TrieNode* s = (TrieNode*)calloc(1, sizeof(TrieNode));
if (nullptr == s) exit(1);
return s;
}
void Freenode(TrieNode* p)
{
free(p);
}
void InitTTree(TrieTree* ptree)
{
ptree->root = nullptr;
}
int KeyPos(const KeyType& kx,int k)
{
int pos = 0;
if (k < kx.num)
{
pos = tolower(kx.ch[k]) - 'a' + 1;
}
return pos;
}
TrieNode* SearchValue(TrieTree* ptree, const KeyType &kx)
{
if (nullptr == ptree || kx.num == 0) return nullptr;
TrieNode* p = ptree->root; //
int k = 0;
while (p != nullptr && p->utype == BRANCH && k <= kx.num)
{
int index = KeyPos(kx, k);
p = p->brch.link[index];
k += 1;
}
if (p != nullptr && p->utype == ELEMENT && strcmp(p->elem.key.ch, kx.ch) != 0)
{
p = nullptr;
}
return p;
}
TrieNode* BuyLeaf(const ElemType& item)
{
TrieNode* s = Buynode();
s->utype = ELEMENT;
s->elem = item;
return s;
}
TrieNode* BuyBrch(TrieNode* ptr, int k)
{
TrieNode* s = Buynode();
s->utype = BRANCH;
int pos = KeyPos(ptr->elem.key, k);
s->brch.link[pos] = ptr;
return s;
}
void InsertItem(TrieNode*& ptr, const ElemType& item, int k)
{
if (ptr == nullptr)
{
ptr = BuyLeaf(item);
}
else if (ptr->utype == ELEMENT)
{
ptr = BuyBrch(ptr, k);
int pos = KeyPos(item.key, k);
InsertItem(ptr->brch.link[pos], item, k + 1);
}
else// BRCH;
{
int pos = KeyPos(item.key, k);
InsertItem(ptr->brch.link[pos], item, k + 1);
}
}
void Insert(TrieTree* ptree, const ElemType& item)
{
assert(ptree != nullptr);
int k = 0;
InsertItem(ptree->root, item, k);
return ;
}
int main()
{
KeyType key[] = { {"CAI",3},{"CAO",3},{"CHA",3},{"CHANG",5},{"CHAO",4},{"LIU",3},{"LI",2} };
int n = sizeof(key) / sizeof(key[0]);
TrieTree tree;
InitTTree(&tree);
for (int i = 0; i < n; ++i)
{
ElemType item = { key[i],nullptr };
Insert(&tree, item);
}
return 0;
}
Trie树和其它数据结构的比较
Trie树(字典树,前缀树,键树)分析详解_
后面是转载这里的
Trie树与二叉搜索树
二叉搜索树应该是我们最早接触的树结构了,我们知道,数据规模为n时,二叉搜索树插入、查找、删除操作的时间复杂度通常只有O(log n),最坏情况下整棵树所有的节点都只有一个子节点,退变成一个线性表,此时插入、查找、删除操作的时间复杂度是O(n)。
通常情况下,Trie树的高度n要远大于搜索字符串的长度m,故查找操作的时间复杂度通常为O(m),最坏情况下的时间复杂度才为O(n)。很容易看出,Trie树最坏情况下的查找也快过二叉搜索树。
文中Trie树都是拿字符串举例的,其实它本身对key的适宜性是有严格要求的,如果key是浮点数的话,就可能导致整个Trie树巨长无比,节点可读性也非常差,这种情况下是不适宜用Trie树来保存数据的;而二叉搜索树就不存在这个问题。
Trie树与Hash表
考虑一下Hash冲突的问题。Hash表通常我们说它的复杂度是O(1),其实严格说起来这是接近完美的Hash表的复杂度,另外还需要考虑到hash函数本身需要遍历搜索字符串,复杂度是O(m)。在不同键被映射到“同一个位置”(考虑closed hashing,这“同一个位置”可以由一个普通链表来取代)的时候,需要进行查找的复杂度取决于这“同一个位置”下节点的数目,因此,在最坏情况下,Hash表也是可以成为一张单向链表的。
Trie树可以比较方便地按照key的字母序来排序(整棵树先序遍历一次就好了),这跟绝大多数Hash表是不同的(Hash表一般对于不同的key来说是无序的)。
在较理想的情况下,Hash表可以以O(1)的速度迅速命中目标,如果这张表非常大,需要放到磁盘上的话,Hash表的查找访问在理想情况下只需要一次即可;但是Trie树访问磁盘的数目需要等于节点深度。
很多时候Trie树比Hash表需要更多的空间,我们考虑这种一个节点存放一个字符的情况的话,在保存一个字符串的时候,没有办法把它保存成一个单独的块。Trie树的节点压缩可以明显缓解这个问题,后面会讲到
Trie树的改进
- 按位Trie树(Bitwise Trie):原理上和普通Trie树差不多,只不过普通Trie树存储的最小单位是字符,但是Bitwise Trie存放的是位而已。位数据的存取由CPU指令一次直接实现,对于二进制数据,它理论上要比普通Trie树快。
- 节点压缩。
- 分支压缩:对于稳定的Trie树,基本上都是查找和读取操作,完全可以把一些分支进行压缩。例如,前图中最右侧分支的inn可以直接压缩成一个节点“inn”,而不需要作为一棵常规的子树存在。Radix树就是根据这个原理来解决Trie树过深问题的。
- 节点映射表:这种方式也是在Trie树的节点可能已经几乎完全确定的情况下采用的,针对Trie树中节点的每一个状态,如果状态总数重复很多的话,通过一个元素为数字的多维数组(比如Triple Array Trie)来表示,这样存储Trie树本身的空间开销会小一些,虽说引入了一张额外的映射表。