学习前:
五大问题:
- 为什么SwiGLU激活函数能够提升模型性能?
- RoPE位置编码是什么?怎么用的?还有哪些位置编码方式?
GQA(Grouped-Query Attention, GQA)分组查询注意力机制是什么?- Pre-normalization前置了层归一化,使用
RMSNorm作为层归一化方法,这是什么意思?还有哪些归一化方法?LayerNorm? - 将self-attention改进为使用
KV-Cache的Grouped Query,怎么实现的?原理是什么?
Embedding
Embedding的过程:word -> token_id -> embedding_vector,其中第一步转化使用tokenizer的词表进行,第二步转化使用 learnable 的 Embedding layer。
这里的第二步,不是很明白怎么实现的,需要再细化验证

RMS Norm
对比Batch Norm 和 Layer Norm:都是减去均值Mean,除以方差Var(还加有一个极小值),最终将归一化为正态分布N(0,1)。只不过两者是在不同的维度(batch还是feature)求均值和方差,(其中,减均值:re-centering 将均值mean变换为0,除方差:re-scaling将方差varance变换为1)。
参考知乎的norm几则
RoPE(Rotary Positional Encodding)
绝对Positional Encodding的使用过程:word -> token_id -> embedding_vector + position_encodding -> Encoder_Input,其中第一步转化使用tokenizer的词表进行,第二步转化使用 learnable 的 Embedding layer。将得到的embedding_vector 和 position_encodding 进行element-wise的相加,然后才做为input送入LLM的encoder。
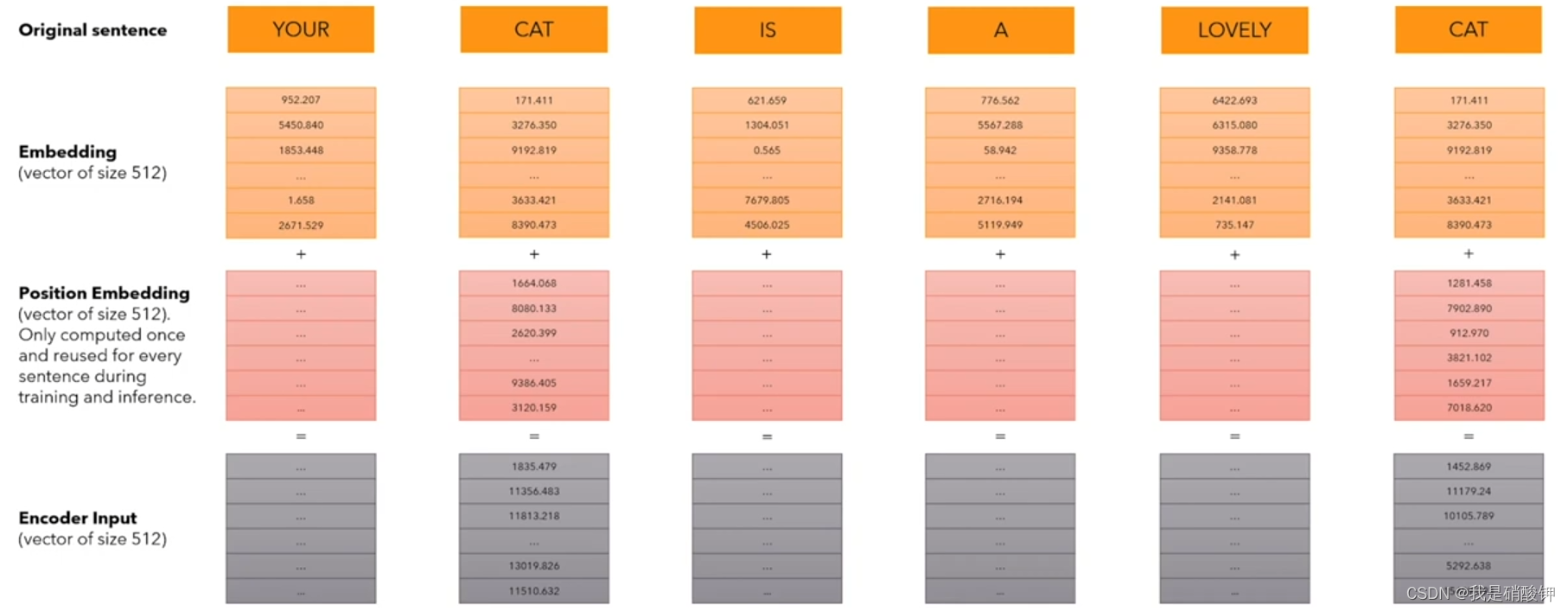
理解LLM位置编码:RoPE







![[机缘参悟-191] - 《道家-水木然人间清醒1》读书笔记 -14- 关系界限 - 经济和人格上的独立,走向成熟的必经之路,才能更好的谈其他情感(IT)](https://img-blog.csdnimg.cn/direct/b8c265c5a7e043ce80c87e5d24ff4999.png)