- 平台统一监控的介绍和调研
- 直观感受PromQL及其数据类型
- PromQL之选择器和运算符
PromQL 匹配器
- 相等匹配器(=)
选择与提供的字符串完全相同的数据
例:筛选出id=“G1 Eden Space” 的数据
jvm_memory_used_bytes{id="G1 Eden Space"}

- 不相等匹配器(!=)
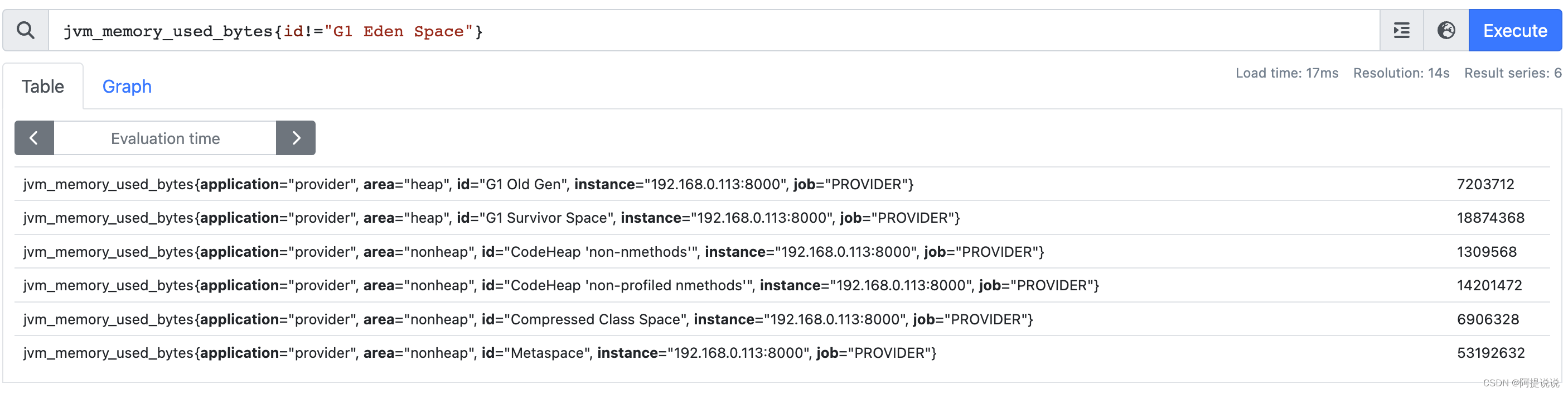
与相等匹配器相反,用来选择与提供字符串不相同的数据
例:选择 id 不为G1 Eden Space 的数据
jvm_memory_used_bytes{id!="G1 Eden Space"}
- 正则表达式匹配器(=~)
选择与提供的正则表达式相匹配的数据
例:从id 标签中筛选出 G1开头的数据
jvm_memory_used_bytes{id =~ "G1.*"}

- 不等于的正则表达式匹配器(!~)
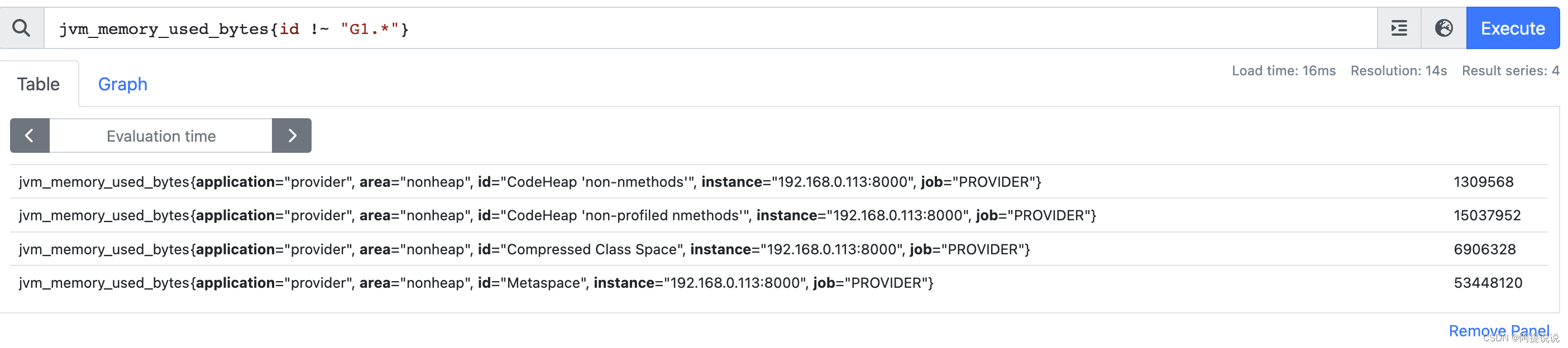
选择与提供的正则表达式不匹配的数据
例:从id 标签中筛选出 不以G1开头的数据
jvm_memory_used_bytes{id !~ "G1.*"}
jvm_memory_used_bytes 同 {name = “jvm_memory_used_bytes”},也可以用其他匹配器
PromQL 选择器
瞬时向量选择器
返回在指定时间戳查询到的最新样本值
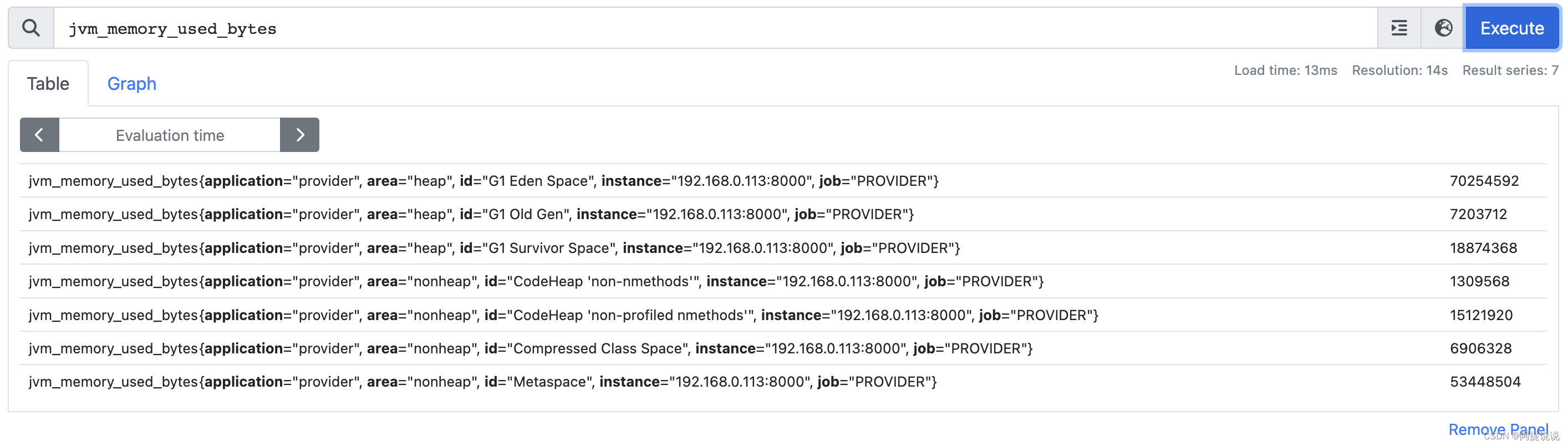
最简单形式:返回包含该指标名称的所有时间序列的瞬时向量
例:筛选出了所有指标为jvm_memory_used_bytes的数据
jvm_memory_used_bytes
区间向量选择器
返回一段时间内的样本数据。通过末尾[]进行时间定义,如[1m],表示1分钟之内
例:返回一分钟内的数据
jvm_memory_used_bytes[1m]
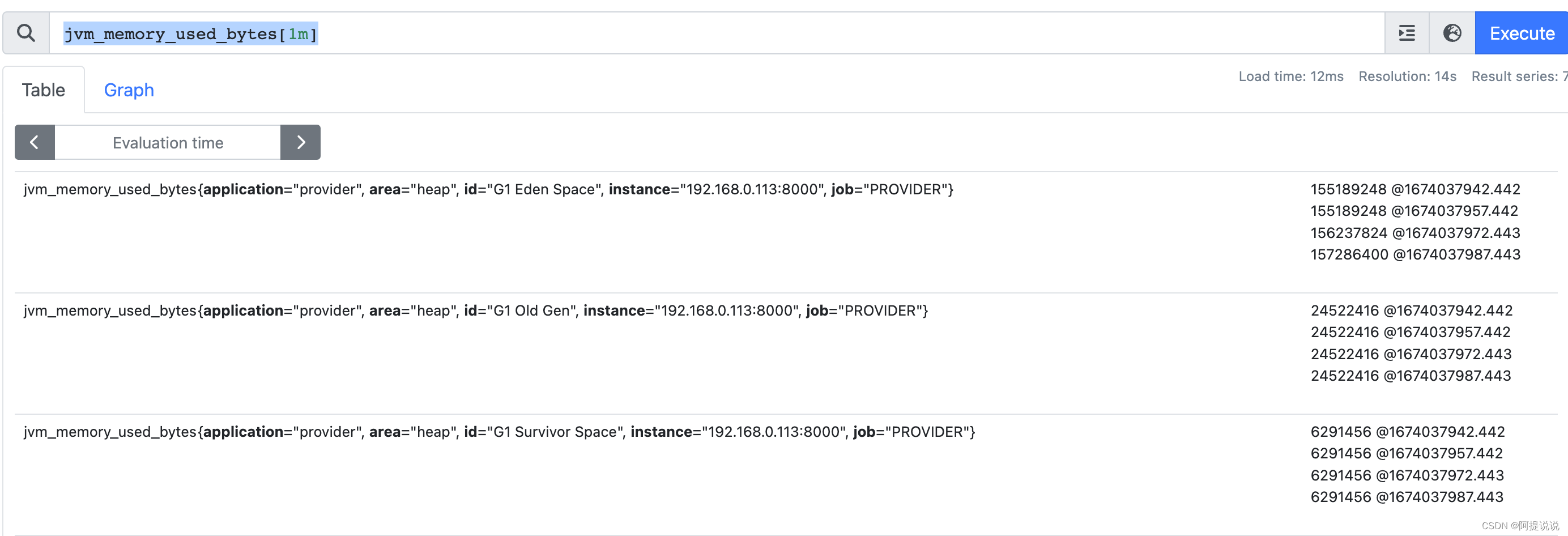
图中每一条数据都4个样本值,表示1分钟之内采集了4次数据。
可使用的时间单位:秒(s)、分钟(m)、小时(h)、天(d)、周(w)、年(y)
偏移量修改器
可以让瞬时向量和区间向量的时间发生偏移
例:查询前1分钟的jvm_memory_used_bytes 样本值
jvm_memory_used_bytes offset 1m
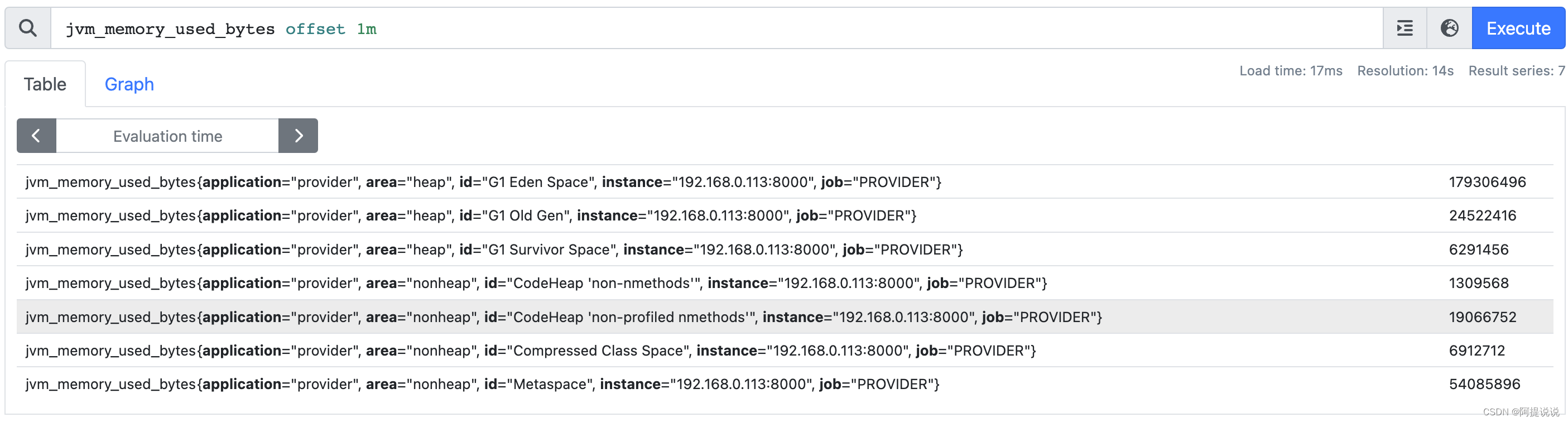
注意与 jvm_memory_used_bytes[1m] 的区别
@ 修饰符
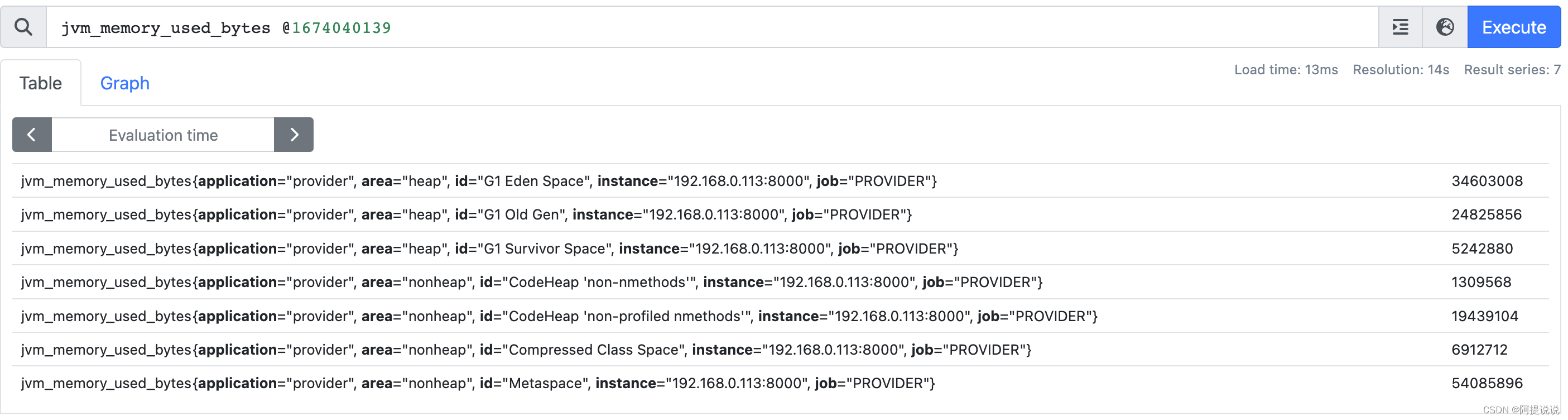
@ 修饰符能够修改瞬时向量和区间向量的求值时间,使用@时间戳 表示
例:查询 2023-01-18 19:08:59 的 jvm_memory_used_bytes 指标
jvm_memory_used_bytes @1674040139
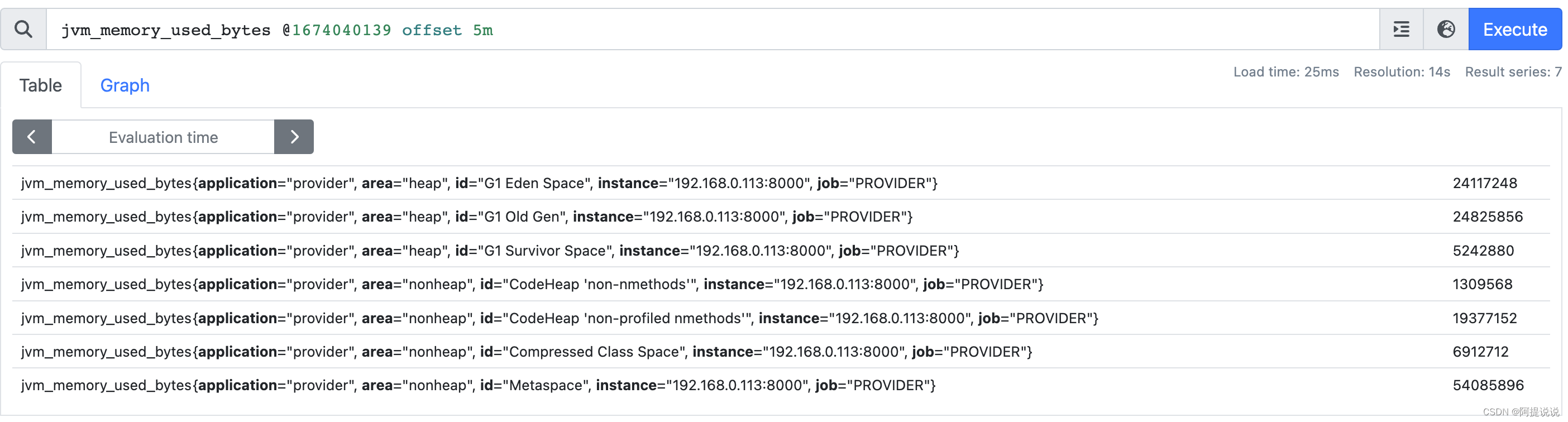
例:查询2023-01-18 19:08:59 时,前 5分钟的 jvm_memory_used_bytes指标
jvm_memory_used_bytes @1674040139 offset 5m
PromQL 运算符
算术运算符
支持6种算术运算符,加法(+)、减法(-)、乘法(*)、除法(/)、模(%)、幂(^)
例1:计算堆内存使用率
sum(jvm_memory_used_bytes{area=“heap”}) 表示已使用的堆内存
sum(jvm_memory_max_bytes{area=“heap”}) 表示堆总内存
sum(jvm_memory_used_bytes{area="heap"})*100 / sum(jvm_memory_max_bytes{area="heap"})

逻辑运算符
and(并且)、or(或者)、unless(排除)
- vector1 and vector2 :产生一个新的向量,向量中的元素由vector1完全匹配 vector2的元素组成
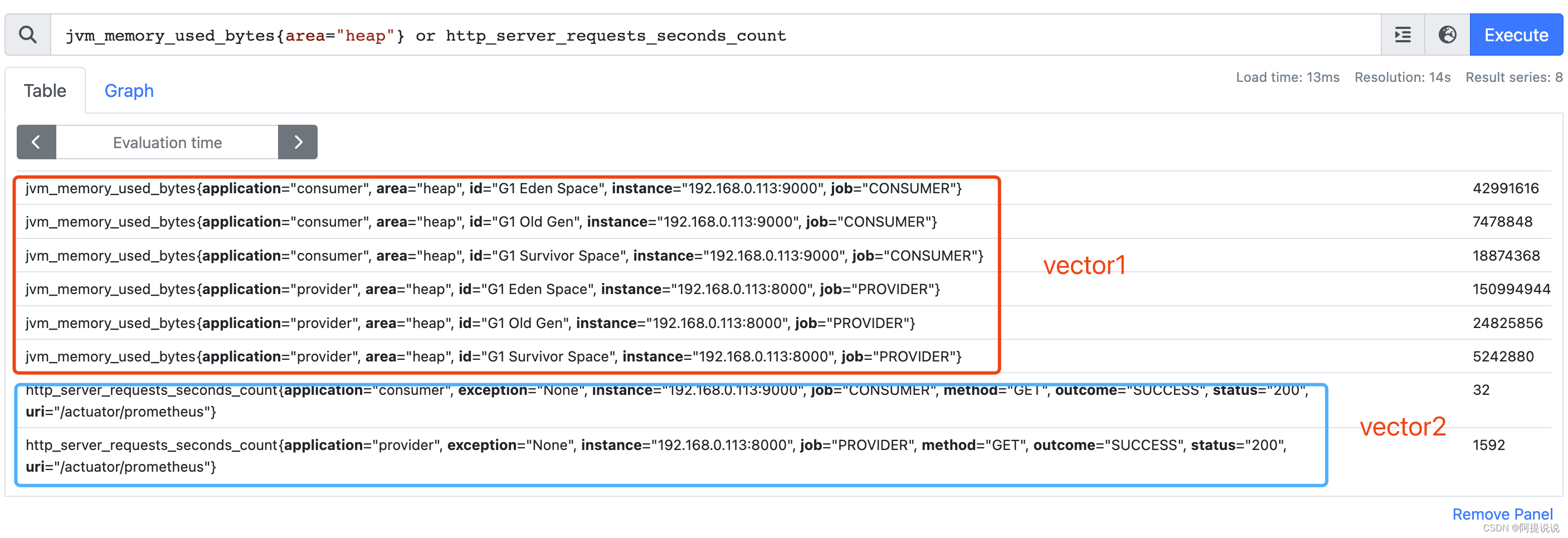
- vector1 or vector2:产生一个新的向量,由vector1中的元素 和 vector2中不与vector1匹配的元素 组成
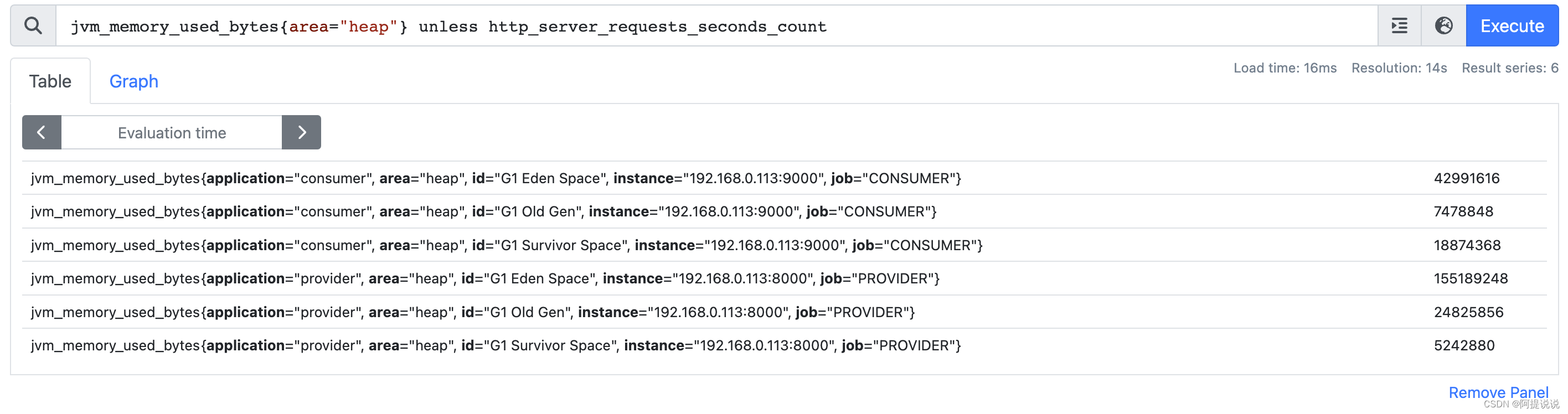
- vector1 unless vector2:产生一个新的向量,由vector1 中没有与vector2匹配的元素组成
还是用jvm_memory_used_bytes 指标来举例。
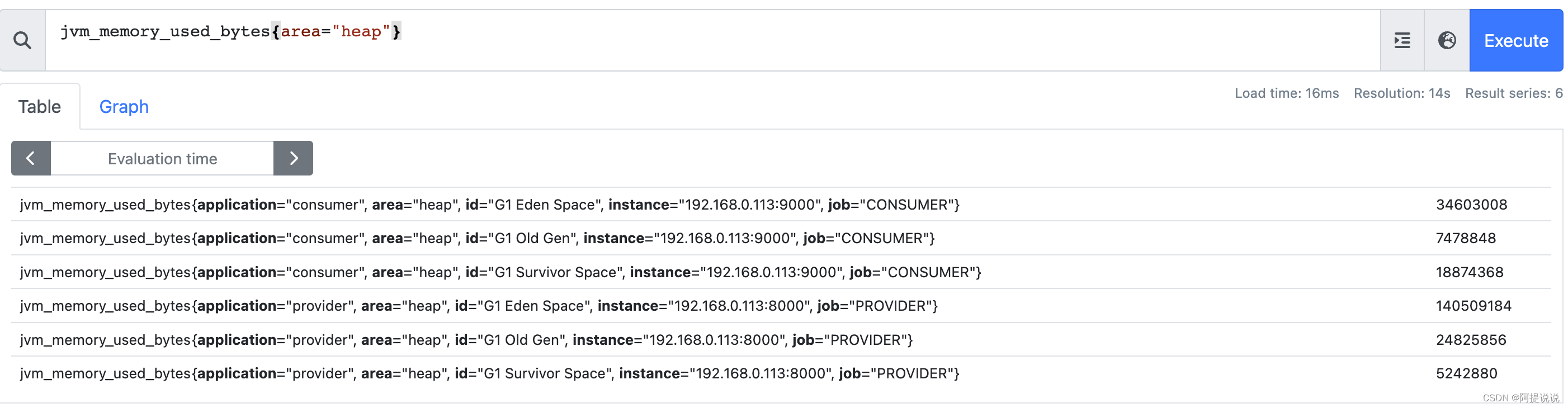
and 示例:
vector1:所有实例的堆内存数据
jvm_memory_used_bytes{area="heap"}
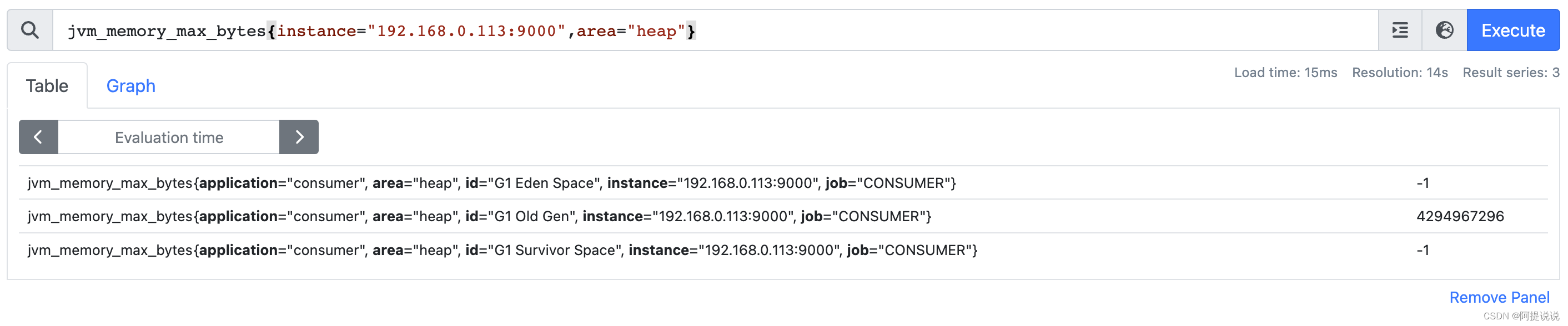
vector2:筛选出 instance=“192.168.0.113:9000”,area=“heap” 数据
jvm_memory_max_bytes{instance="192.168.0.113:9000",area="heap"}
and 运算符后,只保留了instance=“192.168.0.113:9000”,area=“heap” 标签相同的数据
jvm_memory_used_bytes{area="heap"} and jvm_memory_max_bytes{instance="192.168.0.113:9000",area="heap"}
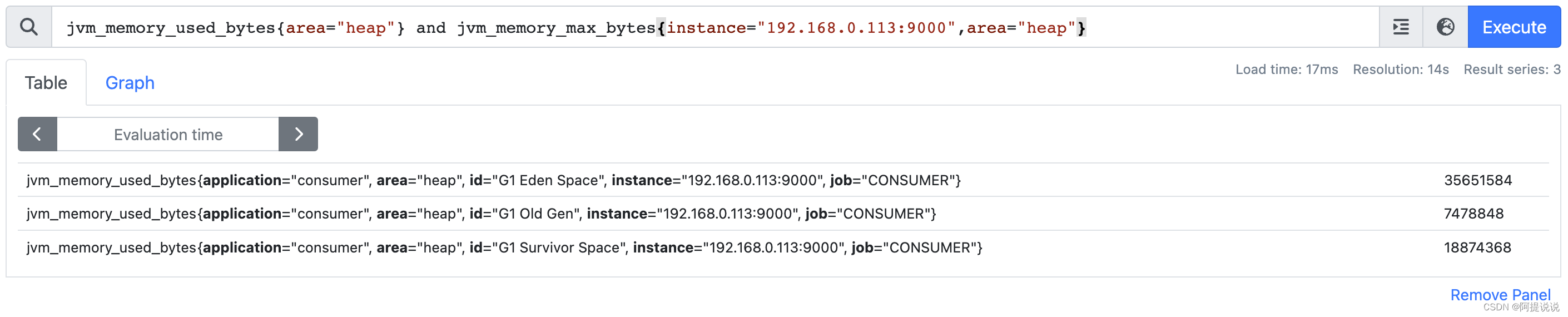
发现 and 运算符并不管 指标名是否一样
or 示例:
为了更加直观,使用另外一个指标http_server_requests_seconds_count
unless 示例:
比较运算符
== 相等、!=不相等、>大于、<小于、>=大于等于、<=小于等于
例:在运算符之后加上bool关键字可以让结果返回0或1
99 >= bool 88
向量匹配
Prometheus 的向量与向量 之间进行运算操作时会基于默认的匹配规则:依次找到与左边向量元素匹配(标签完全一致)的右边向量元素进行运算,如果没有找到匹配元素,直接丢弃。向量匹配主要有:一对一,一对多,多对一。
一对一匹配:
即两遍拥有的标签完全相同,找到唯一一条条目依次进行匹配。
process_open_fds / process_max_fds
如果两边拥有的标签不一致可以用 on 或 ignoring 关键字修改标签间的匹配行为。
on:指定要匹配的标签,只匹配指定的标签。
ignoring:忽略某些标签,就是指定的这些标签不匹配,其他的都匹配。
如下示例中只对 instance 和 job 两个标签进行匹配。
sum by(instance, job) (rate(node_cpu_seconds_total{mode="idle"}[5m]))
/ on (instance, job)
sum by(instance, job) (rate(node_cpu_seconds_total [5m] ))
两个瞬时向量进行比较时都会返回左边的表达式:
如下示例都会返回左边的表达式:可以根据需求来写表达式。
process_open_fds < process_max_fds
process_max_fds > process_open_fds
一对多或多对一匹配:
group_left: 左边有更多的子集
group_right:右边有更多的子集
用法:
<vector expr> <bin-op> ignoring(<label list>) group_left(<label list>) <vector expr>
<vector expr> <bin-op> ignoring(<label list>) group_right(<label list>) <vector expr>
<vector expr> <bin-op> on(<label list>) group_left(<label list>) <vector expr>
<vector expr> <bin-op> on(<label list>) group_right(<label list>) <vector expr>
分组只能用于 比较和算术运算符中
作者其他文章:
Grafana 系列文章,版本:OOS v9.3.1
- Grafana 的介绍和安装
- Grafana监控大屏配置参数介绍(一)
- Grafana监控大屏配置参数介绍(二)
- Grafana监控大屏可视化图表
- Grafana 查询数据和转换数据
- Grafana 告警模块介绍
- Grafana 告警接入飞书通知
Spring Boot Admin 系列
- Spring Boot Admin 参考指南
- SpringBoot Admin服务离线、不显示健康信息的问题
- Spring Boot Admin2 @EnableAdminServer的加载
- Spring Boot Admin2 AdminServerAutoConfiguration详解
- Spring Boot Admin2 实例状态监控详解
- Spring Boot Admin2 自定义JVM监控通知
- Spring Boot Admin2 自定义异常监控
- Spring Boot Admin 监控指标接入Grafana可视化