在数据推送的时候,我们使用Feed流
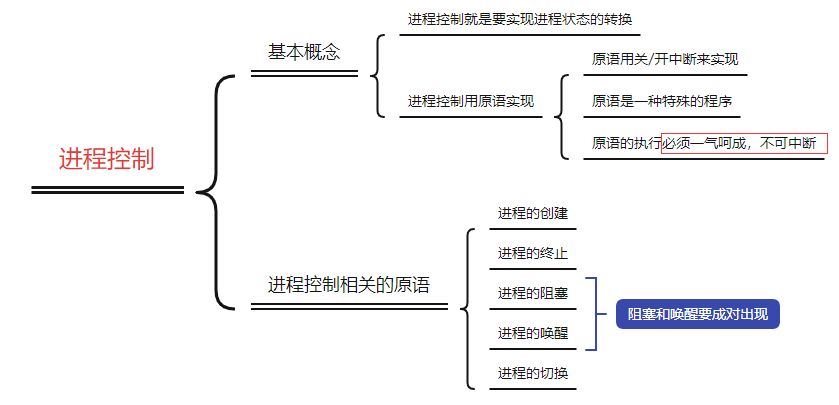
Feed流有三种推送数据的方式(以微博订阅为例)
1.推模式(Push)
将数据在发出后直接推到每个收件箱中.这样会造成发送方的内存占用很大 
2.拉模式
用户每次登录后主动的将数据从收件箱中拉去到,会造成用户的负载增加(如果关注的人很多,甚至会导致上千万条数据的情况)
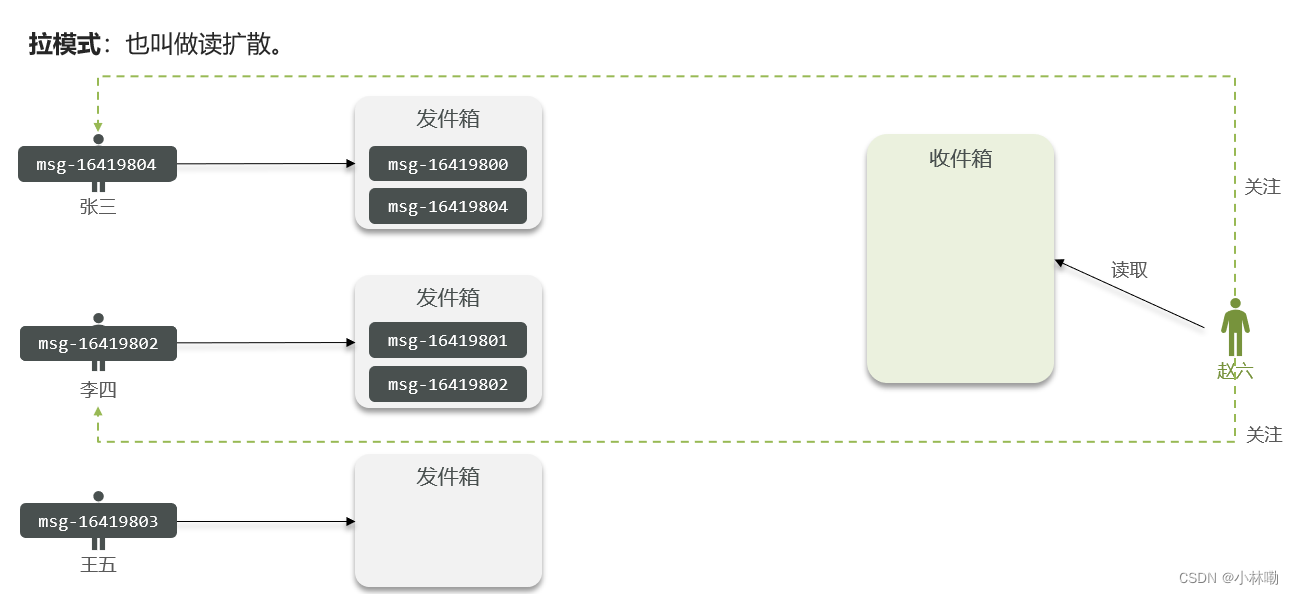
3.推拉结合模式
对于普通用户,该用户发布的信息实时推送到订阅的粉丝手中,而对应于大v(拥有粉丝数量众多的用户),对于其粉丝分两种情况:
1.非活跃用户 : 采用拉模式,即该用户上线后才去获取数据
2.活跃用户: 采用推模式,将数据推送到该用户的收件箱中
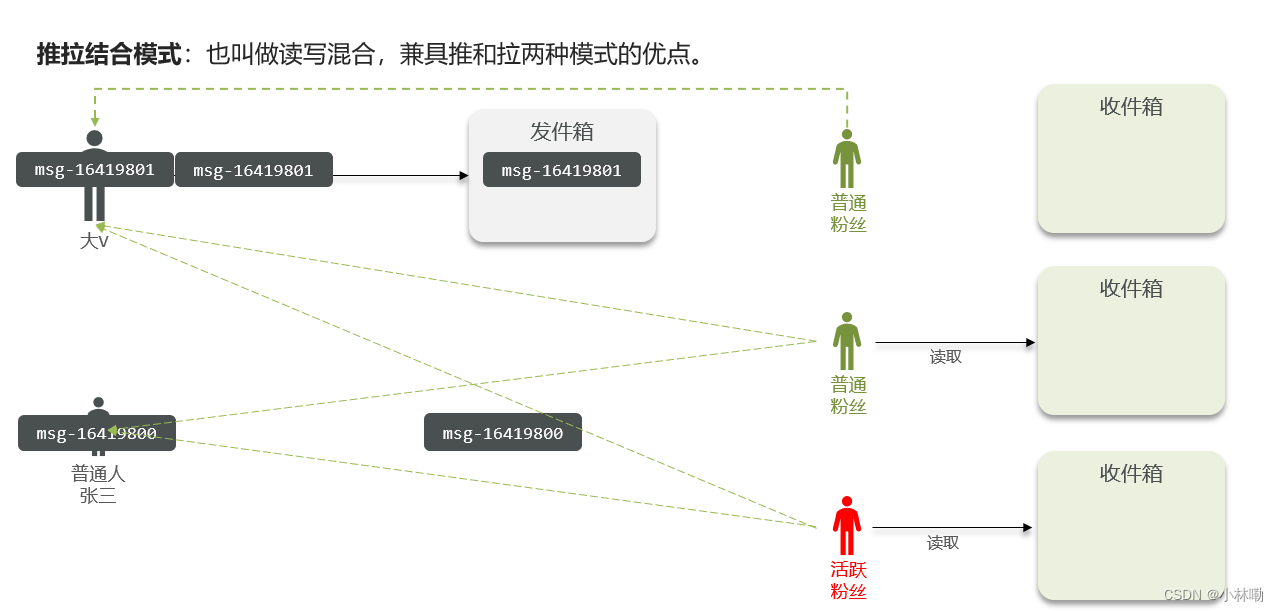
三者的对比
在实现Feed流的时候(用推方案)选用List还是Set的取舍问题:
技术要求:
必须是有序的收件箱,因为要根据数据的先后顺序分页拉取数据的结果 
List:
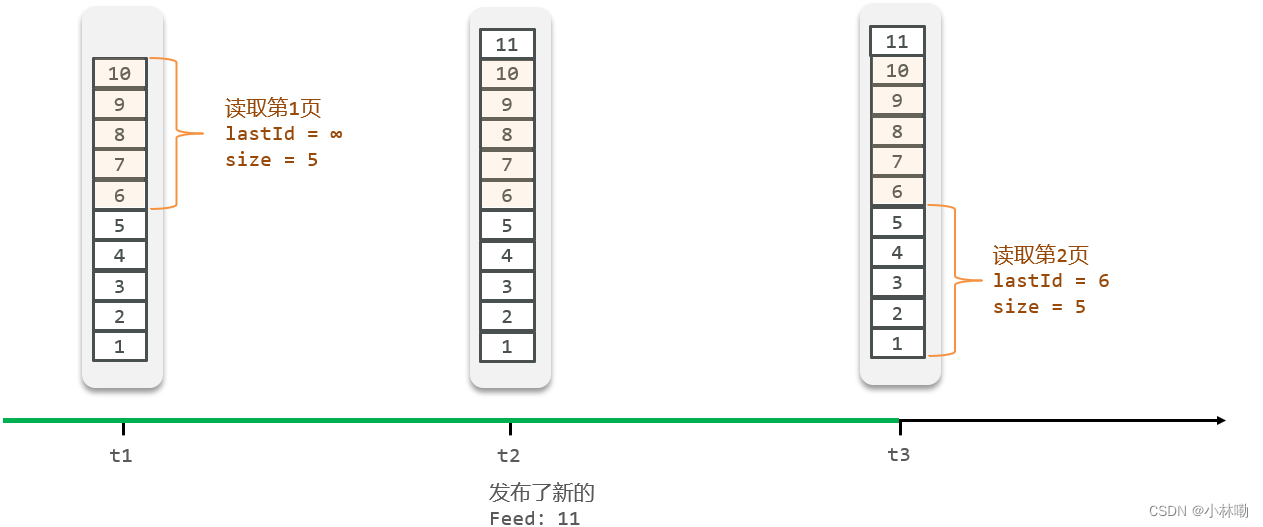
可以通过下标实现有序的要求,但是面对动态生成的数据会出现问题,由于list的下标是不可变得,所以会出现插入新数据之后导致之前的分页 信息错乱,具体情况如下所示,重复读取了数据6
原本第二页应当是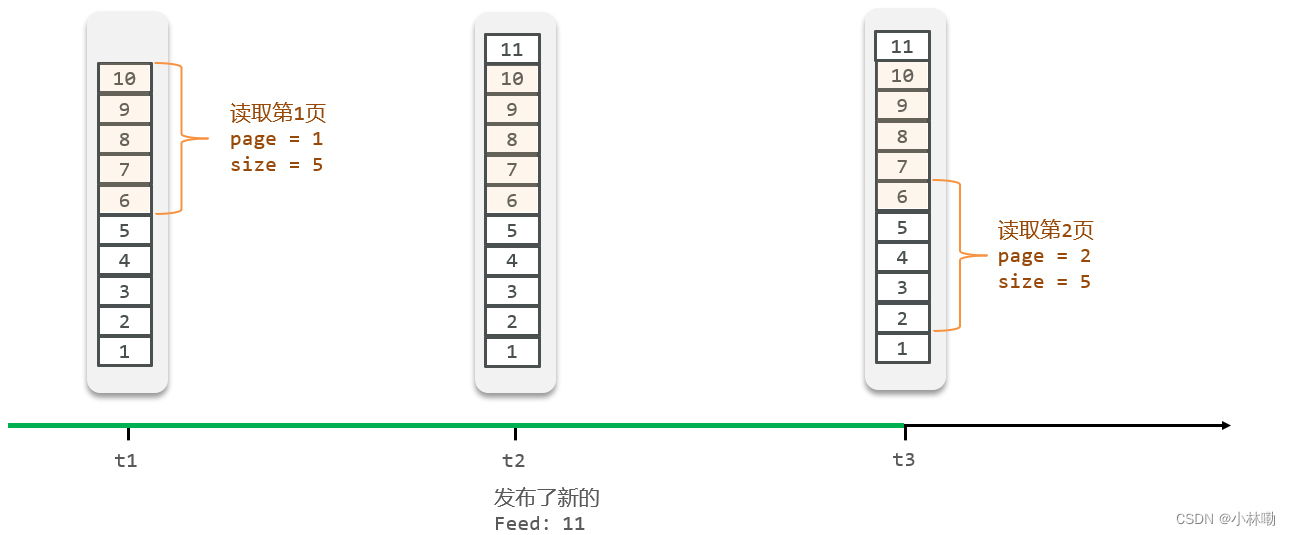
SortedSet:
可以通过score来实现排序的要求,也就是说在取数据的时候按照时间戳(自行设计的当做score的变量)来实现取后几名的情况.同时可以在取得数据后记住当前页的最后的时间戳,在下次取数据的时候直接和存取的上次取得的最后的时间戳做比较,只有大于上次时间戳的数据才来做分页.
总结: 当数据会发生变化时,将数据存到SortedSet中!!(比如排行榜之类的情况)