Eagle and Finch: RWKV withMatrix-Valued States and Dynamic Recurrence
公众号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)

目录
0. 摘要
3. Eagle/Finch 架构
4. 方法
4.1 Eagle
4.1.1 Eagle token 移位
4.1.2 Eagle 时间混合
4.1.3 通道混合
4.2 Finch
4.2.1 Finch token 移位
4.2.2 Finch 时间混合
5. RWKV World Tokenizer
6. RWKV World v2 数据集
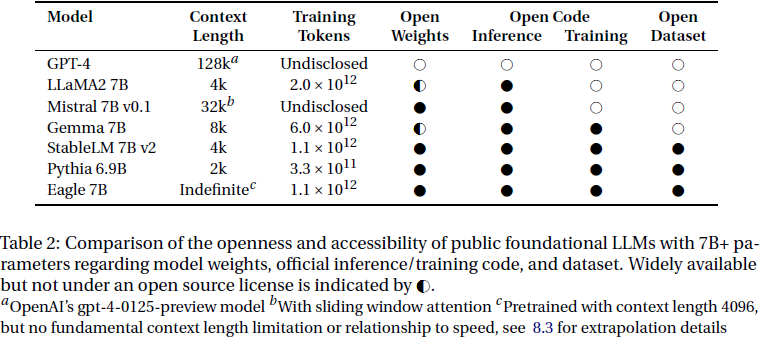
7. 预训练模型
8. 语言建模实验
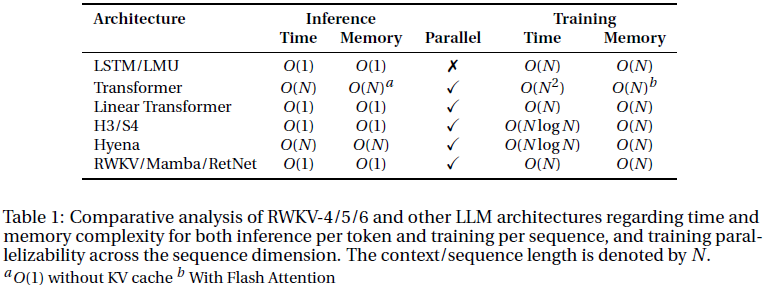
9. 速度和存储 Benchmark
10. 多模态实验
11. 结论
附录
B. 额外架构细节
F. 额外评估
0. 摘要
我们介绍了 Eagle(RWKV-5)和 Finch(RWKV-6),这是在 RWKV(RWKV-4)(Peng 等,2023年)架构的基础上改进的序列模型。我们的架构设计进步包括多头矩阵值状态(multi-headed matrix-valued states)和动态循环机制(dynamic recurrence mechanism),这些改进提高了表达能力,同时保持了 RNN 的推断效率特性。我们引入了一个新的多语言语料库,拥有 1120B 个 token,并基于贪婪匹配(greedy matching)设计了一个快速的分词器(tokenizer),以增强多语言性能。我们训练了四个 Eagle 模型,参数范围从 0.46 到 75 亿,以及两个 Finch 模型,参数分别为 16 亿和 31 亿,并发现它们在各种基准测试中取得了竞争性能。我们在 HuggingFace 上以 Apache 2.0 许可证发布了我们的所有模型。
模型位于:https://huggingface.co/RWKV
训练代码位于:https://github.com/RWKV/RWKV-LM
推理代码位于:https://github.com/RWKV/ChatRWKV
时间并行训练代码位于:https://github.com/RWKV/RWKV-infctx-trainer
(2023|EMNLP,RWKV,Transformer,RNN,AFT,时间依赖 Softmax,线性复杂度)
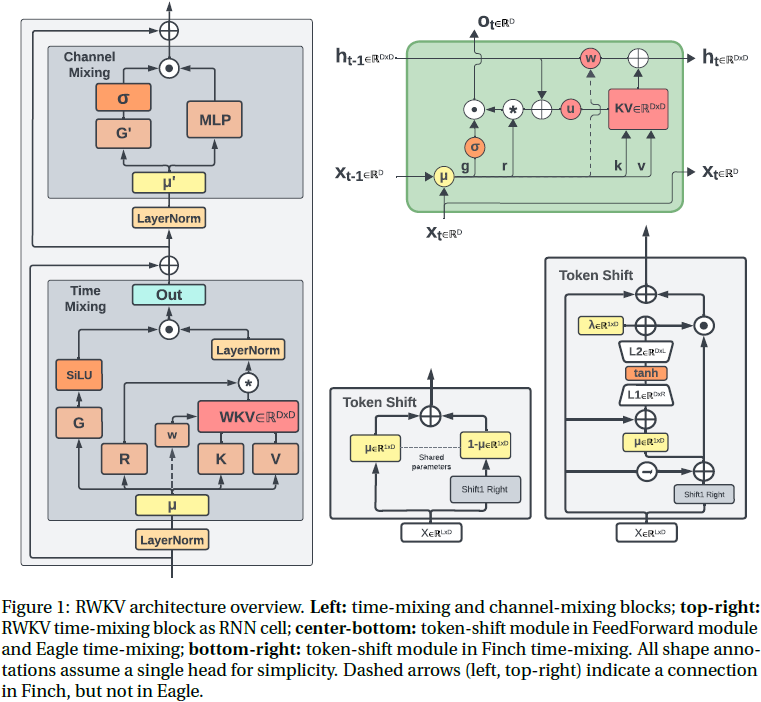
3. Eagle/Finch 架构
我们通过两个步骤对 RWKV 架构进行了优化,并观察到每一步都有显著的建模改进。与基线 RWKV-4 相比,Eagle 增加了矩阵值注意力状态、注意力头上的 LayerNorm、SiLU 注意力门控和改进的初始化。它还取消了接受(receptance)的 Sigmoid 激活。Finch 进一步将数据依赖性应用于衰减调度和 token 移位(shift)。
核心架构与 RWKV-4 类似,由一系列堆叠的残差块组成,形状类似于传统的 Transformer。根据(Tolstikhin 等,2021年)的符号表示,每个块包含一个 Pre-LayerNorm 时间混合子层,后跟一个 Pre-LayerNorm 通道混合子层,如图 1 左侧所示。这些对应于 Transformer 的传统注意力和前馈网络子层。有关我们的训练实现及与 RWKV-4 的差异的更多细节,请参见附录 B,有关速度和内存基准测试,请参见第 9 节。
4. 方法
在本节中,我们使用 D 来表示模型维度,除非明确说明,本节中出现的所有向量都是维度 D/h,其中 h 表示注意力头的数量,属于 R^(D/h)。为了简洁和简便起见,我们以每个头的方式显示计算,省略头索引。我们使用的约定是,除非明确转置,所有向量都是行向量,因此所有矩阵都在右侧操作。
4.1 Eagle
4.1.1 Eagle token 移位
我们采用了前一版 RWKV 中的 token 移位 (shift) 技术,类似于大小为 2 的一维因果卷积,如图 1 中下部所示。为了更好地介绍 token 移位技术,我们定义一些符号。在 RWKV-4 和 Eagle token 移位中使用的 xt 和 x_(t−1) 之间的线性插值(lerp)定义为:
![]()
其中每个 μ□ ∈ R^D 是一个可学习的向量。 token 移位允许模型独立且独特地为每个头每个时间步的接受(receptance)、键、值和门向量(r、k、v 和 g)的每个通道分配新旧信息的数量。这使得在单个层内可以形成归纳头(induction heads)(Elhage 等人,2021年),因为即使是单个头也可以直接将过去和当前的 token 数据分别累积到这些向量的不同子空间中。
4.1.2 Eagle 时间混合
Eagle 时间混合的公式可以写成如下形式:
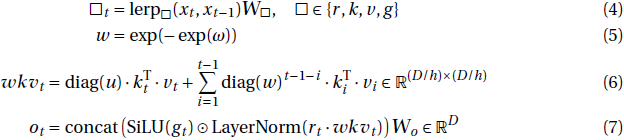
其中 LayerNorm 分别作用于 h 个头的每一个,这也等价于在 h 个组上进行的 Group-Norm(Wu & He (2018))操作。值得注意的是,w 是从 w = exp(−exp(ω)) 获得的,其中 ω ∈ R^(D/h) 是实际的按头(headwise)可训练参数。这确保 w 落在区间 (0,1) 内,保证了 diag(w) 是一个收缩矩阵。
wkvt 注意力计算也可以用循环形式来写成:

RWKV 的 wkv 项可以被视为线性注意力中归一化的 k^T·v 项的基于衰减的等效项。值得注意的是,对于给定的头 j,循环状态 s 是 k^T·v 的总和,其中每个 s 通道在每个时间步都会由 w 的相应通道进行衰减。在应用接收向量 r、门控 g 和输出权重 w 之前,会将每个通道学习的增益 u 与当前 token 的 k^T·v 相乘,并与状态求和,如图 1 右上方所示。这使得当前 token 相对于包含在衰减状态历史中的过去 token 的总和具有特殊的处理方式。接收向量乘以这个总和,就像在 Linear Attention 中的 query 项一样。
4.1.3 通道混合
在 Eagle 和 Finch 中,通道混合模块与之前的 RWKV-4 架构相同,只是隐藏维度从 4D 降低到了3.5D。这个降维考虑到了在 Eagle 时间混合中的新门控权重,以确保与先前模型在相同层数和嵌入维度上具有等参数关系。尽管在 Finch 中添加了一小部分新的 LoRA 权重参数,但我们并没有进一步降低隐藏维度。通道混合的公式与 RWKV-4 相同,但我们在此重新陈述它们以确保符号一致性,使用方程式 3 中的线性插值:

4.2 Finch
4.2.1 Finch token 移位
在 Finch token 移位(shift)中使用的 xt 和 x_(t−1) 之间的数据依赖线性插值(data-dependent linear interpolation,ddlerp)定义为:
![]()
其中 μx 和每个 λ□ 引入了一个维度为 D 的可训练向量,每个 A□ ∈ R^(D×32),B□ ∈ R^(32×D) 引入了新的可训练权重矩阵。对于下面所示的 LoRA_ω 的特殊情况,我们引入了双倍大小的可训练权重矩阵 Aω ∈ R^(D×64),Bω ∈ R^(64×D)。图 1 右下方可以找到示意图。请注意,预期未来的 7B 及更大的雀模型将进一步将这些权重矩阵的大小增加一倍或更多。 这种增强了数据相关性的新 token 移位形式旨在将模型的能力扩展到超出 RWKV-4/Eagle 风格的 token 移位,以便每个通道分配的新旧数据量取决于当前和先前时间步的输入。
4.2.2 Finch 时间混合
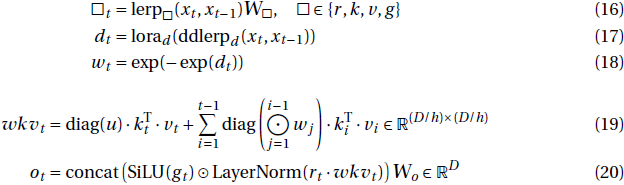
wkv_t 注意力计算也可以用循环的方式来写:

不像在 Eagle 中,wt 在这里不是跨序列静态的(图 1 左边和右上方的虚线箭头)。这是 Finch 中衰减的核心变化,因为现在 wt 的每个通道可以以数据相关的方式随时间变化,而不是以前的固定学习向量。
上述新的 LoRA 机制用于获取学习向量(与 Eagle 中相同),并以低成本的方式用传入的输入确定的额外 offset 对其进行增强。请注意,LoRA 过程本身使用的是 Eagle 风格的 token 移位值作为其输入,而不仅仅是最新的 token。新的时间变化衰减 wt 更进一步,之后再次应用 LoRA。直观地说,这是 token 移位的二阶变体,允许 wt 的每个通道根据当前和先前 token 的混合以及混合本身的方面而变化。
5. RWKV World Tokenizer
在语言建模中,标记化(Tokenization)很重要,因为它会影响 token 之间的学习关系以及基于这些模式生成新文本。然而,构建单个语义块所需的 token 数量通常在非欧洲和其他代表性较低的语言中分布非常不均匀。基于字节对编码(Byte-pair-encoding,BPE)的 tokenizer 在训练时考虑到这种不平等会导致不仅在代表性较低的语言方面性能较低,而且还会产生不必要的经济成本,例如推理(Ahia等人,2023年)和持续的预训练与扩展的词汇表(Lin等人,2024年;Sasaki等人,2023年)。为了解决这些问题,我们从多个词汇文件中手动选择标记,以确保非欧洲语言得到充分代表。
为了构建标记器的词汇表,我们合并了以下 tokenizer 的词汇表,然后手动选择非欧洲语言的标记。
- GPT-NeoX-20B (Black等人,2022年): https://huggingface.co/EleutherAI/gpt-neox-20b
- GPT2 (Radford等人,2019年): https://huggingface.co/openai-community/gpt2
- tiktoken 的 cl100k_base: https://github.com/openai/tiktoken
- Llama2 (Touvron等人,2023年): https://huggingface.co/meta-llama/Llama-2-7b-hf
- Bloom (Workshop等人,2023年): https://huggingface.co/bigscience/bloom
该 tokenizer 的词汇表大小为 V = 65536,编号从 0 到 65535,其中 token 按其字节长度排列。以下是简要概述:
- token 0: 表示文本文档之间的边界,称为 <EOS> 或 <SOS>。此 token 不编码任何特定内容,仅用于文档分隔。
- token 1-256: 由字节编码组成(token k 编码字节 k-1),其中 token 1-128 对应于标准 ASCII 字符。
- token 257-65529: 在 UTF-8 中具有至少 2 字节长度的 token,包括单词、前缀和后缀、重音字母、汉字、韩文字母、平假名、片假名和表情符号。例如,汉字分配从 token 10250 到 18493。
- token 65530-65535: 保留用于未来使用的 token。
这些指定旨在增强 tokenizer 在多语言语料库以及编程语言源代码上的效率。
该 tokenizer 是通过前缀树(Trie)实现的,以提高速度同时保持简单性。编码是通过从左到右将输入字符串与词汇表中的最长元素匹配来执行的。我们注意到,我们的 tokenizer 词汇表的构建是为了减轻对次要语言造成的不必要负担,而这种负担是朴素 BPE 和相关方法引起的。
6. RWKV World v2 数据集
我们在新的 RWKV World v2 数据集上训练我们的模型,这是一个新的多语言 1120B token 数据集,来自各种手动选择的公开可用数据源。该数据集旨在超越当前广泛用于训练 LLM 的许多数据集对英语的重视。我们这样做是为了支持全球绝大多数非英语母语人士的使用,以提高模型响应中的表现,并使迁移学习成为可能,使我们的模型可以跨文化和地区应用知识。我们非常注重事实知识和代码,但也注重文化作品,包括故事、书籍、字幕和对话。源数据大约有 70% 是英语,15% 是多语言,15% 是代码。我们在附录 D 中详细描述了我们数据集的组成部分。
7. 预训练模型
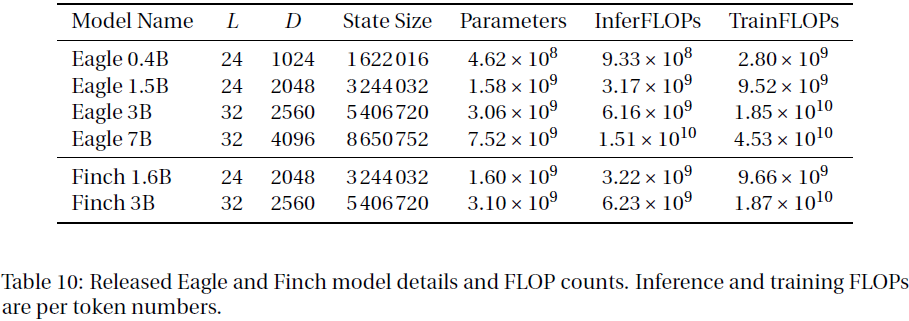
我们已经预训练并公开发布了六个受 Apache 2.0 许可的 Eagle and Finch 模型:Eagle 0.4B、Eagle 1.5B、Eagle 3B、Eagle 7B、Finch 1.6B 和 Finch 3B。所有模型都是在 1120B token 的 RWKV World v2 多语言语料库上进行训练的。有关详细的参数计数和 FLOPs 计算,请参见附录E。
8. 语言建模实验
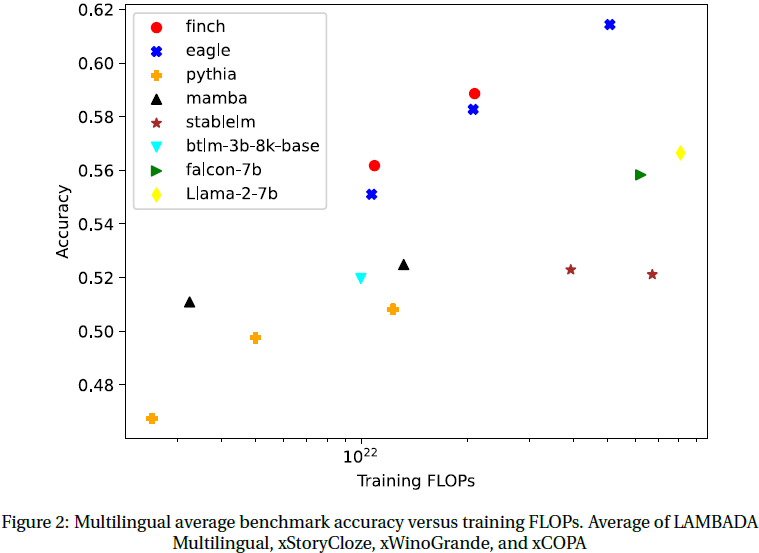
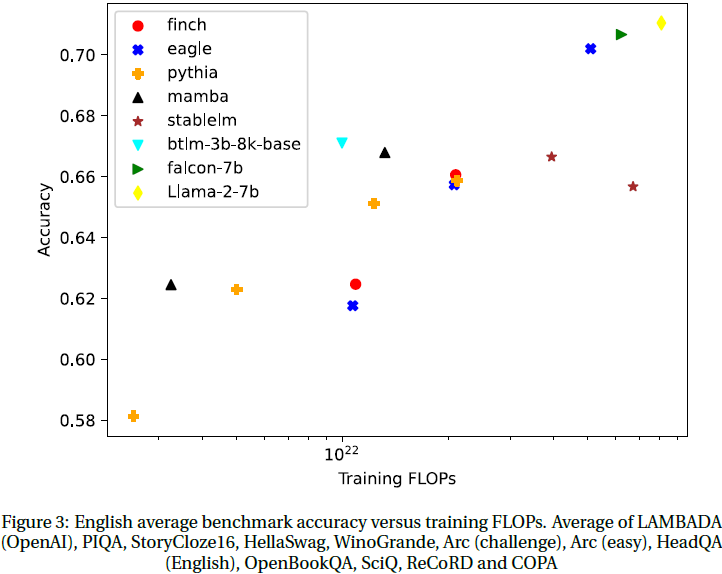
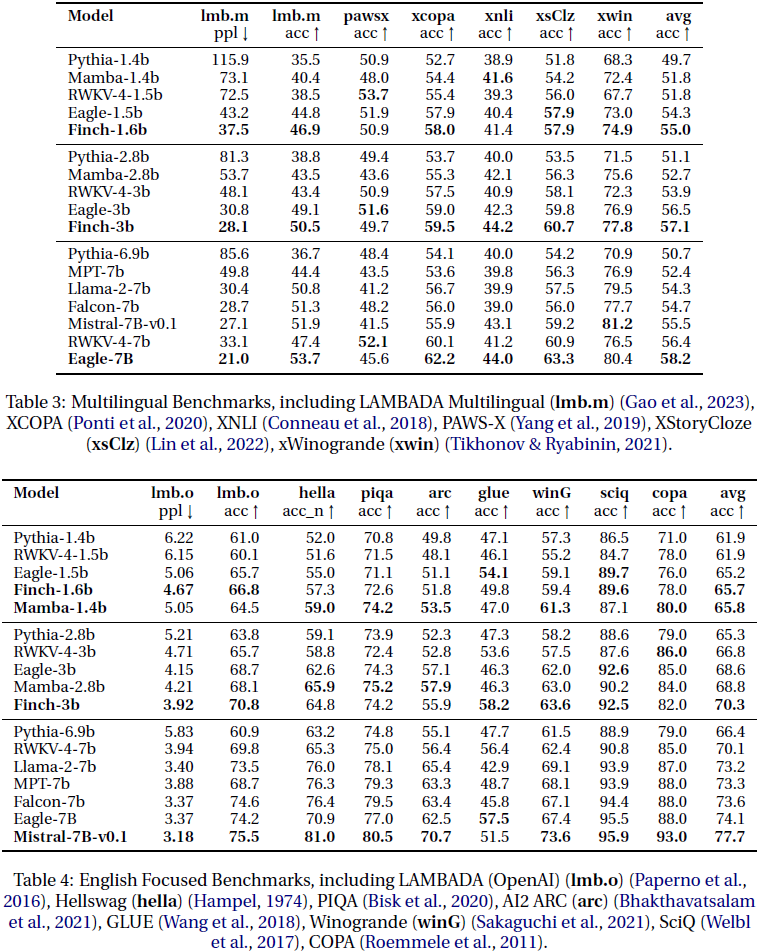
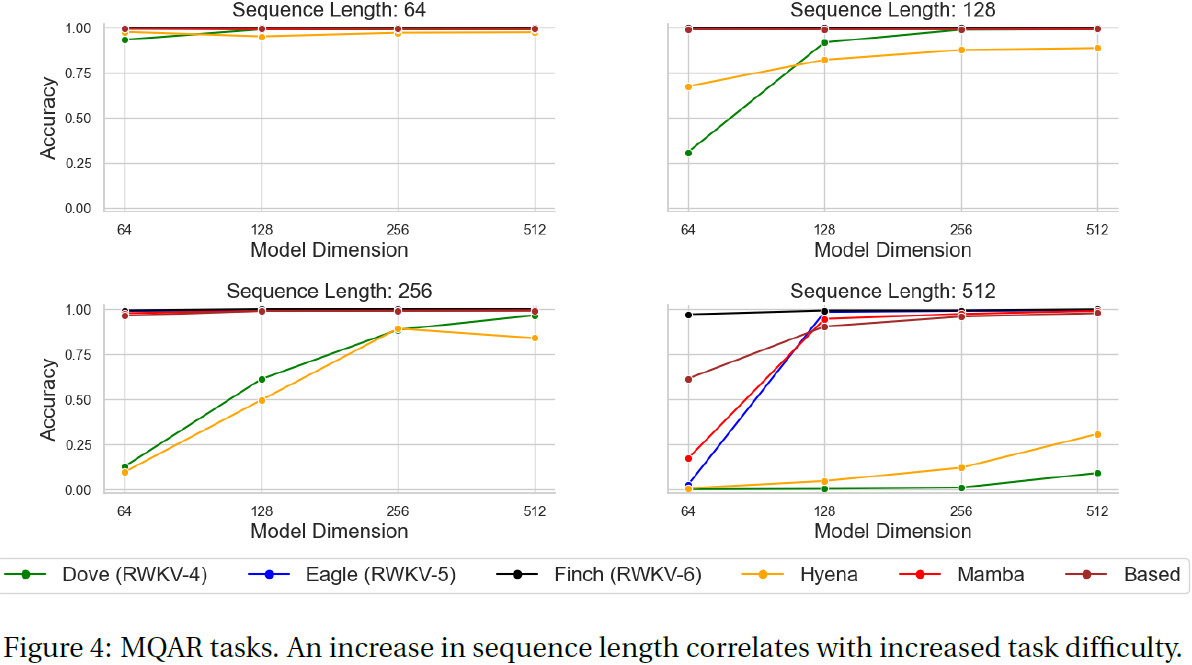
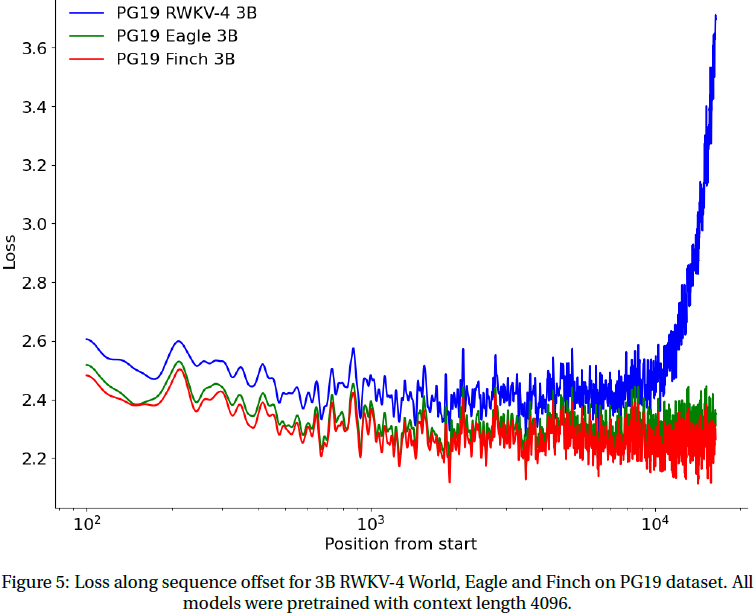
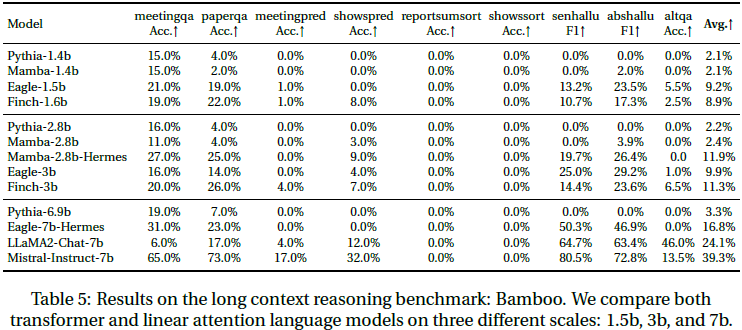
9. 速度和存储 Benchmark

10. 多模态实验
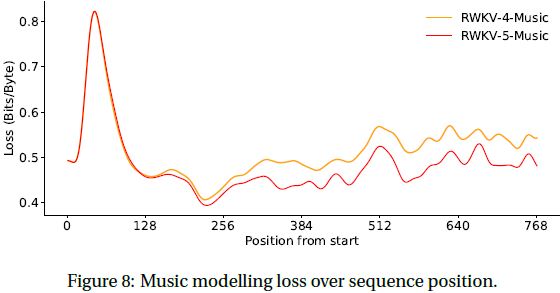
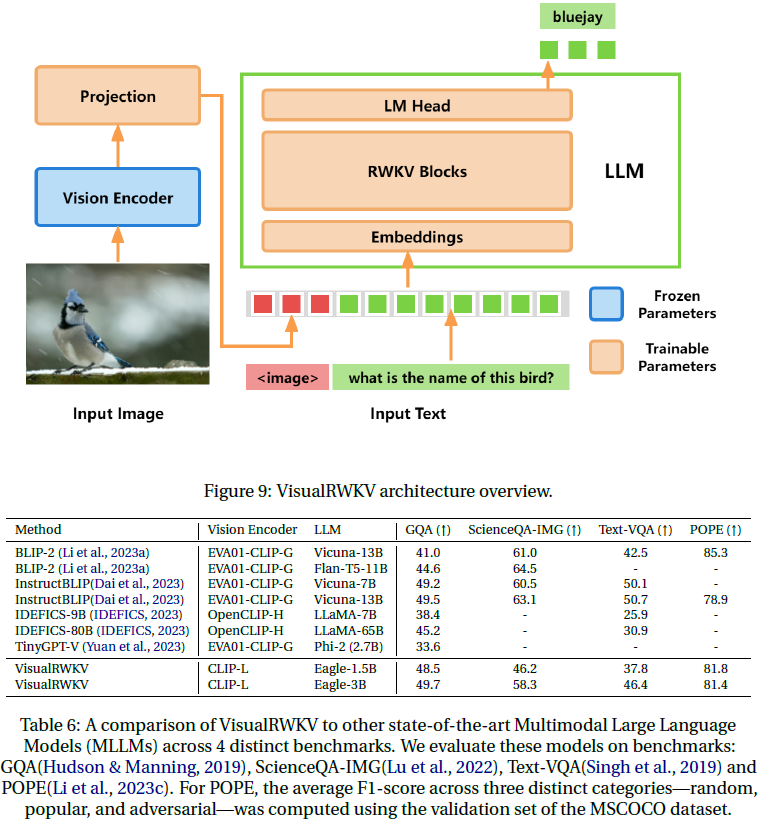
11. 结论
在本工作中,我们介绍了 Eagle(RWKV-5)和 Finch(RWKV-6),通过整合多头矩阵值状态和动态数据驱动的递归机制,取得了基于 RNN 的语言模型的实质性进展。这些模型在 MQAR 和各种语言基准测试中表现出色,挑战了传统 Transformer 架构的主导地位,同时保留了关键的 RNN 优势。通过在 Apache 2.0 许可下公开提供模型并在广泛的多语言语料库上进行训练,我们的工作不仅推动了语言模型的能力发展,还强调了社区的可访问性和在各个领域的适用性。尽管我们意识到未来存在计算和伦理挑战,但我们希望 Eagle 和 Finch 的高效新架构和广泛可用性将有助于推动语言建模的边界,并为未来的创新铺平道路。
限制:Eagle 和 Finch 模型在某些方面存在不足,可以在未来的工作中得到缓解和解决。
我们尝试将 Eagle 用作大规模文本嵌入基准测试(theMassive Text Embedding Benchmark,MTEB)(Muennighoff等人,2023年)的嵌入模型,但未能获得强大的嵌入性能。我们认为它的状态是上下文的高质量嵌入,但需要适当的方法来聚合信息内容。我们将这留给未来的工作。
由于我们的训练语料库包含来自 GPT-3.5 和 ChatGPT 的一些合成数据,我们发布的模型表现出与 ChatGPT 类似的行为,并将模仿 ChatGPT 的对话风格和语调。例如,模型偶尔会声称它是由 OpenAI 训练的。然而,这不是 RWKV 架构的一般特性,而是数据和训练过程的特定结果。
未来工作:我们的 1120B token 的多语言训练语料库远远小于当今模型(如 LLaMA2)的训练数据规模,扩展我们的训练语料库以使其更加多样化和广泛化是提高模型性能的关键优先事项。我们还计划训练和发布更大的 Finch 版本,如 7B 和 14B 参数,并通过专家混合(Mixture of Experts)进一步降低推理和训练成本来扩展其性能。
附录
B. 额外架构细节

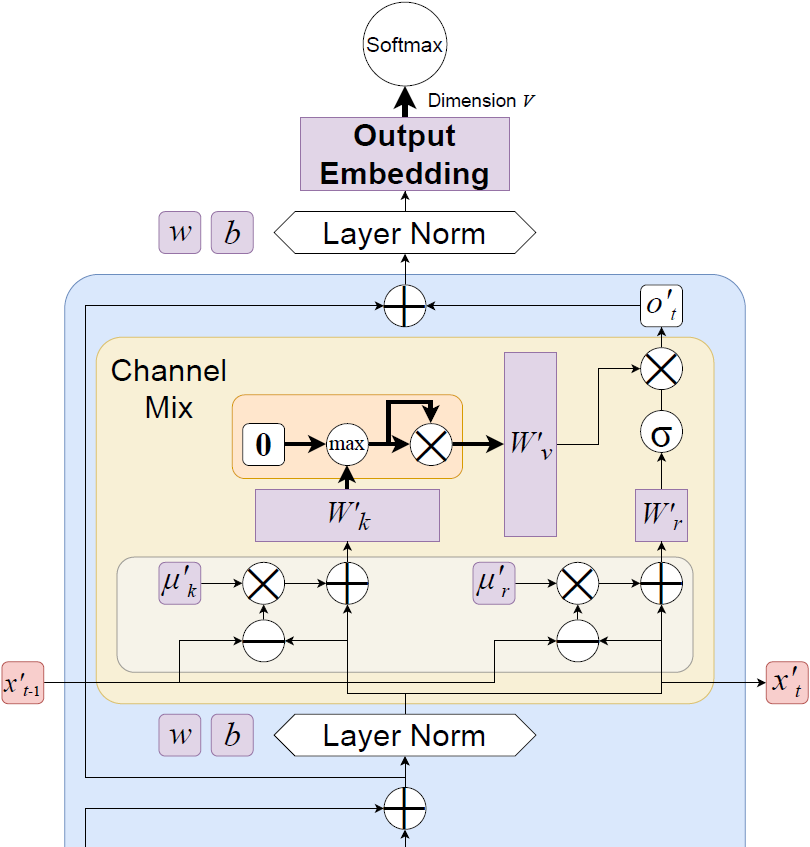
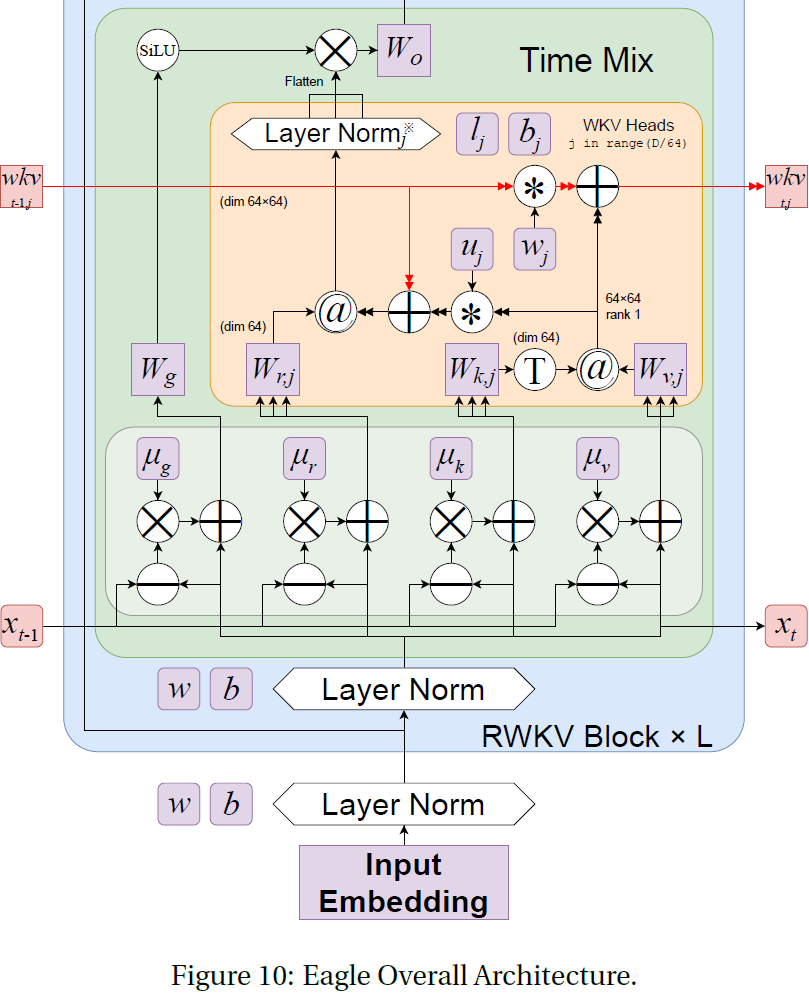
F. 额外评估



![[XYCTF新生赛]-Reverse:你是真的大学生吗?解析(汇编异或逆向)](https://img-blog.csdnimg.cn/direct/f7ef41a79b5547e0a55559fa0ef25b05.png)