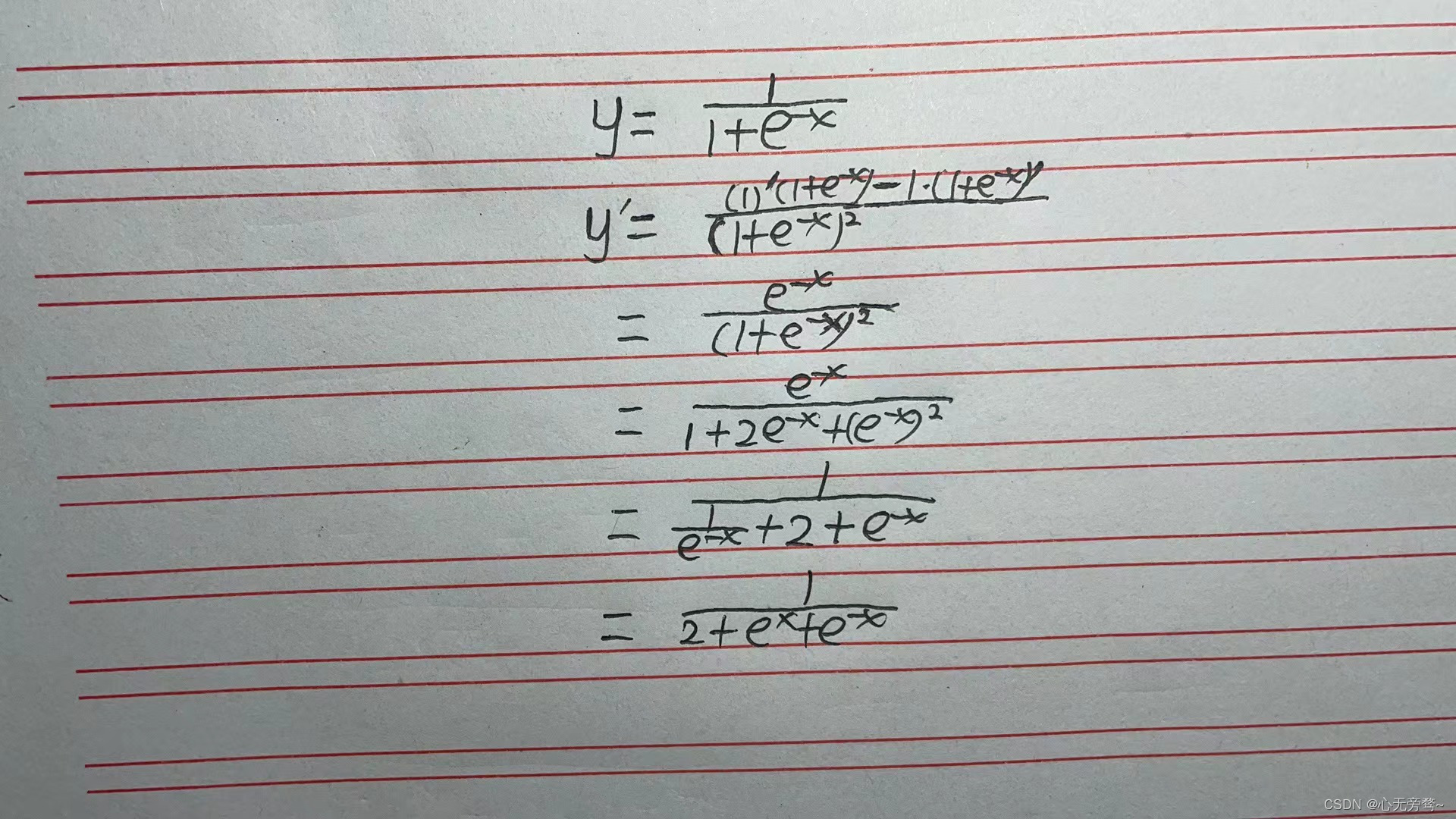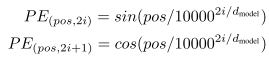想要入门深度学习的小伙伴们,可以了解下本博主的其它基础内容:
🏠我的个人主页
🚀深度学习入门基础CNN系列——卷积计算
🌟深度学习入门基础CNN系列——填充(padding)与步幅(stride)
😊深度学习入门基础CNN系列——感受野和多输入通道、多输出通道以及批量操作基本概念
池化(Pooling)
池化是使用某一位置的相邻输出的总体统计特征代替网络在该位置的输出,其好处是当输入数据做出少量平移时,经过池化函数后的大多数输出还能保持不变。比如:当识别一张图像是否是人脸时,我们需要知道人脸左边有一只眼睛,右边也有一只眼睛,而不需要知道眼睛的精确位置,这时候通过池化某一片区域的像素点来得到总体统计特征会显得很有用。由于池化之后特征图会变得更小,如果后面连接的是全连接层,能有效的减小神经元的个数,节省存储空间并提高计算效率。
**如下图所示:**将一个
2
×
2
2\times2
2×2的区域池化成一个像素点。通常有两种方法,平均池化和最大池化。

- 如图(a):平均池化。这里使用大小为 2 × 2 2\times2 2×2的池化窗口,每次移动的步幅为2,对池化窗口覆盖区域内的像素取平均值,得到相应的输出特征图的像素值。
- 如图(b):最大池化。对池化窗口覆盖区域内的像素取最大值,得到输出特征图的像素值。当池化窗口在图片上滑动时,会得到整张输出特征图。池化窗口的大小称为池化大小,用 k h × k w k_{h}\times k_w kh×kw表示。在卷积神经网络中用的比较多的是窗口大小为 2 × 2 2\times2 2×2,步幅为2的池化。
与卷积核类似,池化窗口在图片上滑动时,每次移动的步长称为步幅,当宽和高方向的移动大小不一样时,分别用
S
w
和
S
h
S_w和S_h
Sw和Sh表示。也可以对需要进行池化的图片进行填充,填充方式与卷积类似,假设在第一行之前填充
p
h
1
p_{h1}
ph1行,在最后一行后面填充
p
h
2
p_{h2}
ph2行。在第一列之前填充
p
w
1
p_{w1}
pw1列,在最后一列之后填充
p
w
2
p_{w2}
pw2列,则池化层的输出特征图大小为:
H
o
u
t
=
H
+
p
h
1
+
p
h
2
−
k
h
s
h
+
1
W
o
u
t
=
H
+
p
h
1
+
p
h
2
−
k
w
s
w
+
1
H_{out}=\frac{H+p_{h1}+p_{h2}-k_h}{s_h}+1\\ W_{out}=\frac{H+p_{h1}+p_{h2}-k_w}{s_w}+1
Hout=shH+ph1+ph2−kh+1Wout=swH+ph1+ph2−kw+1
在卷积神经网络中,通常使用
2
×
2
2\times2
2×2大小的池化窗口,步幅也使用2,填充为0,则输出特征图的尺寸为:
H
o
u
t
=
H
2
W
o
u
t
=
W
2
\begin{aligned} H_{out}=\frac{H}{2}\\ W_{out}=\frac{W}{2} \end{aligned}
Hout=2HWout=2W
通过这种方式的池化,输出特征图的高和宽都减半,但通道数不会改变。
Sigmoid和ReLU激活函数
前面介绍的网络结构中,普遍使用Sigmoid函数做激活函数。在神经网络发展的早期,Sigmoid函数用的比较多,而目前用的较多的激活函数是ReLU。这是因为Sigmoid函数在反向传播过程中,容易造成梯度的衰减。让我们仔细观察Sigmoid函数的形式,就能发现这一问题。
Sigmoid激活函数的定义如下:
y
=
1
1
+
e
−
x
y=\frac{1}{1+e^{-x}}
y=1+e−x1
ReLU激活函数的定义如下:
y
=
{
0
,
x
<
0
x
,
x
≥
0
y= \begin{cases} 0,\quad x< 0\\ x, \quad x\ge0 \end{cases}
y={0,x<0x,x≥0
下面的程序画出了Sigmoid和ReLU函数的曲线图:
# ReLU和Sigmoid激活函数示意图
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.patches as patches
plt.figure(figsize=(10, 5))
# 创建数据x
x = np.arange(-10, 10, 0.1)
# 计算Sigmoid函数
s = 1.0 / (1 + np.exp(0. - x))
# 计算ReLU函数
y = np.clip(x, a_min=0., a_max=None)
#####################################
# 以下部分为画图代码
f = plt.subplot(121)
plt.plot(x, s, color='r')
currentAxis=plt.gca()
plt.text(-9.0, 0.9, r'$y=Sigmoid(x)$', fontsize=13)
currentAxis.xaxis.set_label_text('x', fontsize=15)
currentAxis.yaxis.set_label_text('y', fontsize=15)
f = plt.subplot(122)
plt.plot(x, y, color='g')
plt.text(-3.0, 9, r'$y=ReLU(x)$', fontsize=13)
currentAxis=plt.gca()
currentAxis.xaxis.set_label_text('x', fontsize=15)
currentAxis.yaxis.set_label_text('y', fontsize=15)
下面是我再notebook上执行的结果:
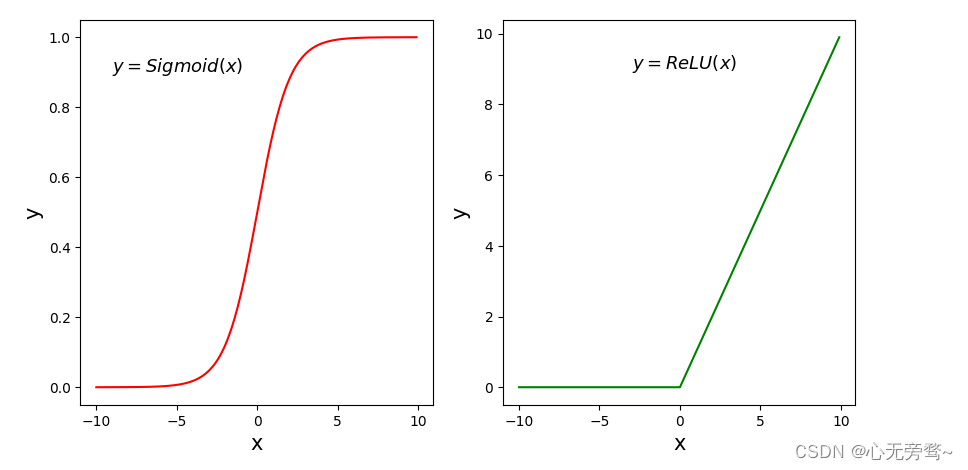
梯度消失现象
在神经网络里,将经过反向传播之后,梯度值衰减到接近于零的现象称作梯度消失现象。
从上面的函数曲线可以看出,当
x
x
x为较大的正数的时候,Sigmoid函数数值非常接近于1,函数曲线变得很平滑,在这些区域Sigmoid函数的导数接近于零。当
x
x
x为较小的负数时,Sigmoid函数值也非常接近于0,函数曲线也很平滑,在这些区域Sigmoid函数的导数也接近于0。只有当
x
x
x的取值在0附近时,Sigmoid函数的导数才比较大。对Sigmoid函数求导数,结果如下所示:
d
y
d
x
=
−
1
(
1
+
e
−
x
)
2
⋅
d
(
e
−
x
)
d
x
=
1
2
+
e
x
+
e
−
x
\frac{dy}{dx}=-\frac{1}{(1+e^{-x})^2}\cdot \frac{d(e^{-x})}{dx}=\frac{1}{2+e^{x}+e^{-x}}
dxdy=−(1+e−x)21⋅dxd(e−x)=2+ex+e−x1
从上面的可以看出,Sigmoid函数的导数
d
y
d
x
\frac{dy}{dx}
dxdy的最大值为
1
4
\frac{1}{4}
41。在前向传播的时候,
y
=
S
i
g
m
o
i
d
(
x
)
y=Sigmoid(x)
y=Sigmoid(x);而在反向传播中,
x
x
x的梯度等于
y
y
y的梯度乘以
S
i
g
m
o
i
d
Sigmoid
Sigmoid函数的导数,如下所示:
∂
L
∂
x
=
∂
L
∂
y
⋅
∂
y
∂
x
\frac{\partial L}{\partial x}=\frac{\partial L}{\partial y}\cdot\frac{\partial y}{\partial x}
∂x∂L=∂y∂L⋅∂x∂y
得到
x
x
x的梯度数值最大不会超过
y
y
y的梯度的
1
4
\frac{1}{4}
41。
由于最开始是将神经网络的参数随机初始化的, x x x的取值很有可能在很大或者很小的区域,这些地方都可能造成Sigmoid函数的导数接近于0,导致 x x x的梯度接近于0;即是 x x x取值在接近于0的地方,按上面的分析,经过Sigmoid函数反向传播之后, x x x的梯度不会超过 y y y的梯度的 1 4 \frac{1}{4} 41,如果有多层网络使用了Sigmoid激活函数,则比较靠后的那些层梯度将衰减到非常小的值。
ReLU函数则不同,虽然在 x < 0 x<0 x<0的地方,ReLU函数的导数为0。但是在 x > 0 x>0 x>0的地方,ReLU函数的导数为1,能够将 y y y的梯度完整的传递给 x x x,从而不会引起梯度消息。
附录:
在此附上Sigmoid的求导过程(字太丑,线条也不优美,往各路大神海涵😜),怕有的人时间太长忘记了怎么求导。