目录
一.缺省参数
1. 基本概念
2.多参函数中使用缺省参数的情形分类
二.函数重载
(1)形参类型不同构成的重载
(2)形参个数不同构成的重载
(3)形参类型顺序不同构成的重载
函数重载的注意事项:
三.C++支持函数重载的底层原理--函数名修饰
编译器生成可执行程序的过程:
一.缺省参数
1. 基本概念
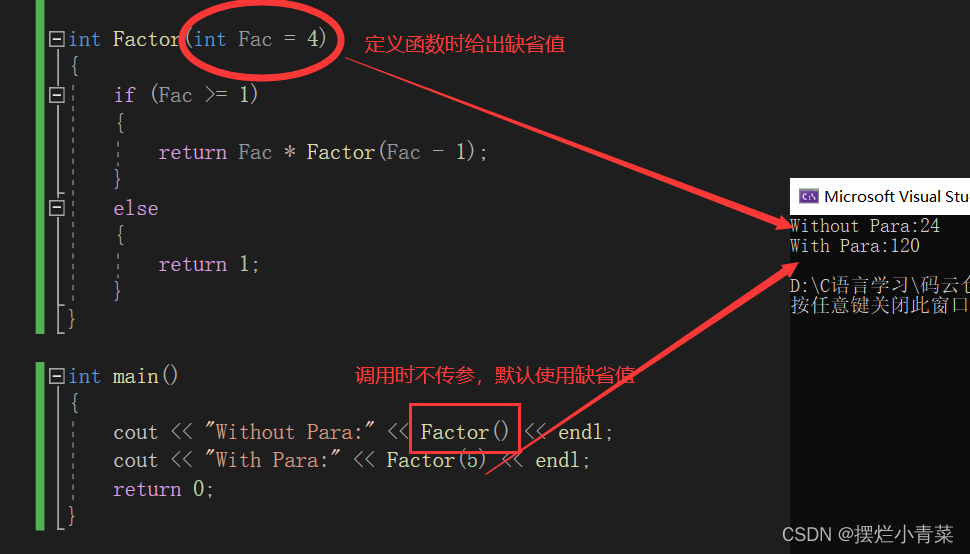
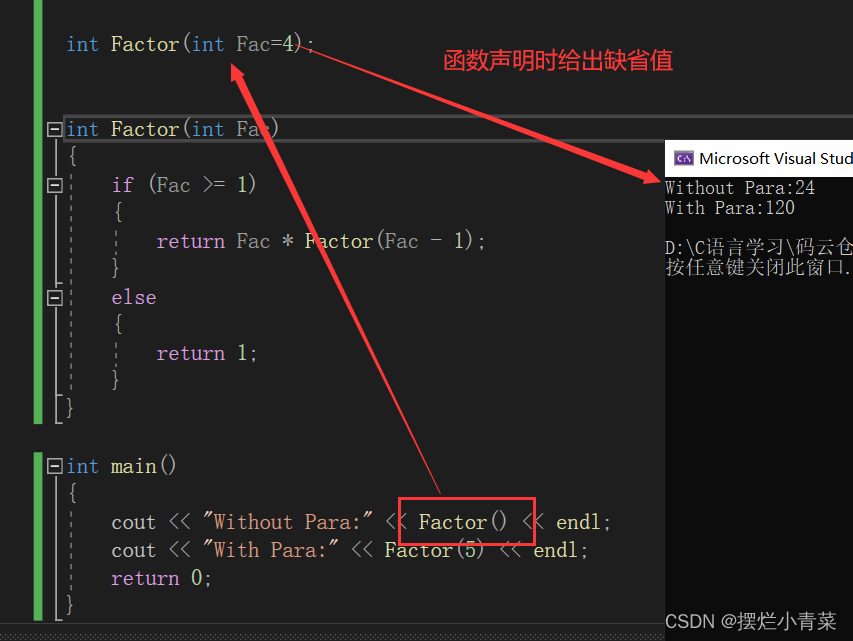
缺省参数是声明或定义函数时为函数的参数指定的默认调用值。
在调用该函数时,如果没有指定实参则采用该形参的缺省值作为该形参的值,否则使用指定的实参。
注意缺省值(函数形参的默认值)不能同时在函数声明和函数定义中给出(缺省参数不能在函数声明和定义中同时出现)
注意缺省值必须是常量或者全局变量。
2.多参函数中使用缺省参数的情形分类
当函数有多个形参时,缺省参数的指定分多种情况:
(1).全缺省参数:为每个形参都指定默认值
void Func(int a = 10, int b = 20, int c = 30) { cout<<"a = "<<a<<endl; cout<<"b = "<<b<<endl; cout<<"c = "<<c<<endl; }此时函数的可能调用情形有四种:
int main () { Func(); 三个参数都是用缺省值 Func(1); 1是赋给a的,b和c使用缺省值 Func(1,2); 1赋给a,2赋给b,c使用缺省值 Func(1,2,3); 为三个参数都递值 return 0; }函数调用时,传入的实参从左往右依次地赋值给形参,无法间隔着传值。(比如上述例子中无法只为形参a,c递值而不为形参b递值)
(2):半缺省参数:为部分形参指定默认值
void Func(int a, int b = 10, int c = 20) { cout<<"a = "<<a<<endl; cout<<"b = "<<b<<endl; cout<<"c = "<<c<<endl; }此时函数的可能调用情形有三种:
int main () { Func(1); 1赋给a, b和c使用缺省值 Func(1,2); 1赋给a,2赋给b,c使用缺省值 Func(1,2,3); 为三个形参都递值 return 0; } 由于a没有指定默认值,所以调用函数时必须为a指定实参。为函数的部分形参指定缺省值(默认值)时必须从右往左依次连续地指定,不能间隔着指定。
比如如下情形是不允许的:

二.函数重载
C++允许在同一作用域中声明几个功能类似的同名函数,这些同名函数的形参列表(参数个数 或类型或类型顺序)不同,常用来处理实现功能类似数据类型不同的问题。
关键点:
重载函数之间是通过函数的 形参个数 或 形参类型 或 形参类型顺序 来区分的(只有这三个区分标准),重载函数之间的区分在于形参的差异。
(1)形参类型不同构成的重载
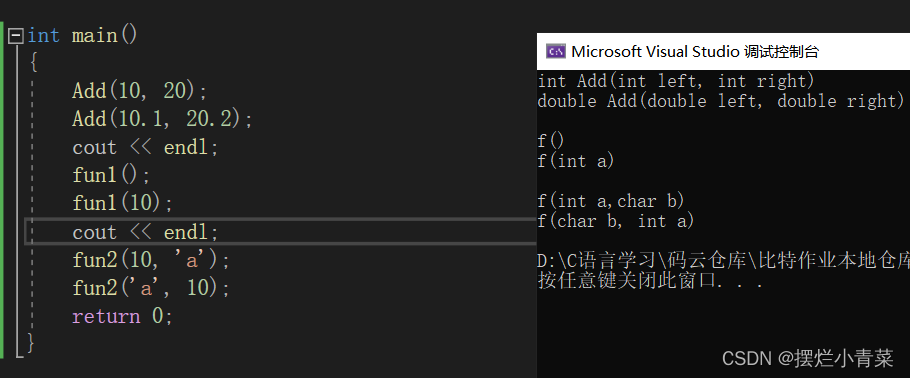
using std::cout; using std::cin; using std::endl; // 1、参数类型不同 int Add(int left, int right) { cout << "int Add(int left, int right)" << endl; return left + right; } double Add(double left, double right) { cout << "double Add(double left, double right)" << endl; return left + right; }(2)形参个数不同构成的重载
// 2、参数个数不同 void fun1() { cout << "f()" << endl; } void fun1(int a) { cout << "f(int a)" << endl; }(3)形参类型顺序不同构成的重载
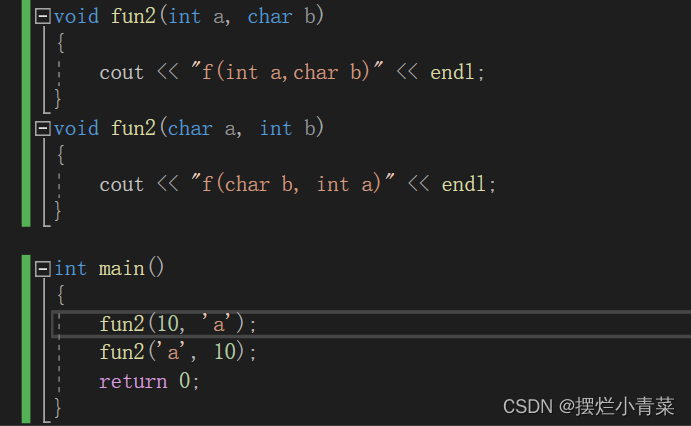
// 3、参数类型顺序不同 void fun2(int a, char b) { cout << "f(int a,char b)" << endl; } void fun2(char b, int a) { cout << "f(char b, int a)" << endl; }int main() { Add(10, 20); Add(10.1, 20.2); fun1(); fun1(10); fun2(10, 'a'); fun2('a', 10); return 0; }
形参个数 或 形参类型 或 形参类型顺序三种差异可以任意组合构成函数重载。
函数重载的注意事项:
当两个同标识名函数形参列表完全相同时:
(1)返回值不同,不能构成函数重载
仅返回值不同时,调用该标识名定义的函数时编译器无法确定应调用哪个具体的重载
(2)形参缺省值不同,不能构成重载

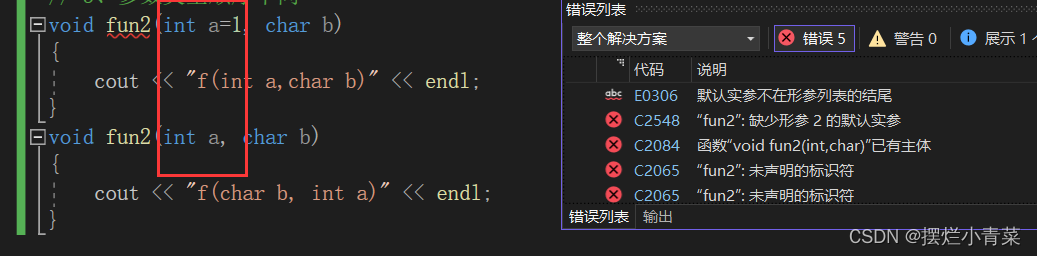
三.C++支持函数重载的底层原理--函数名修饰
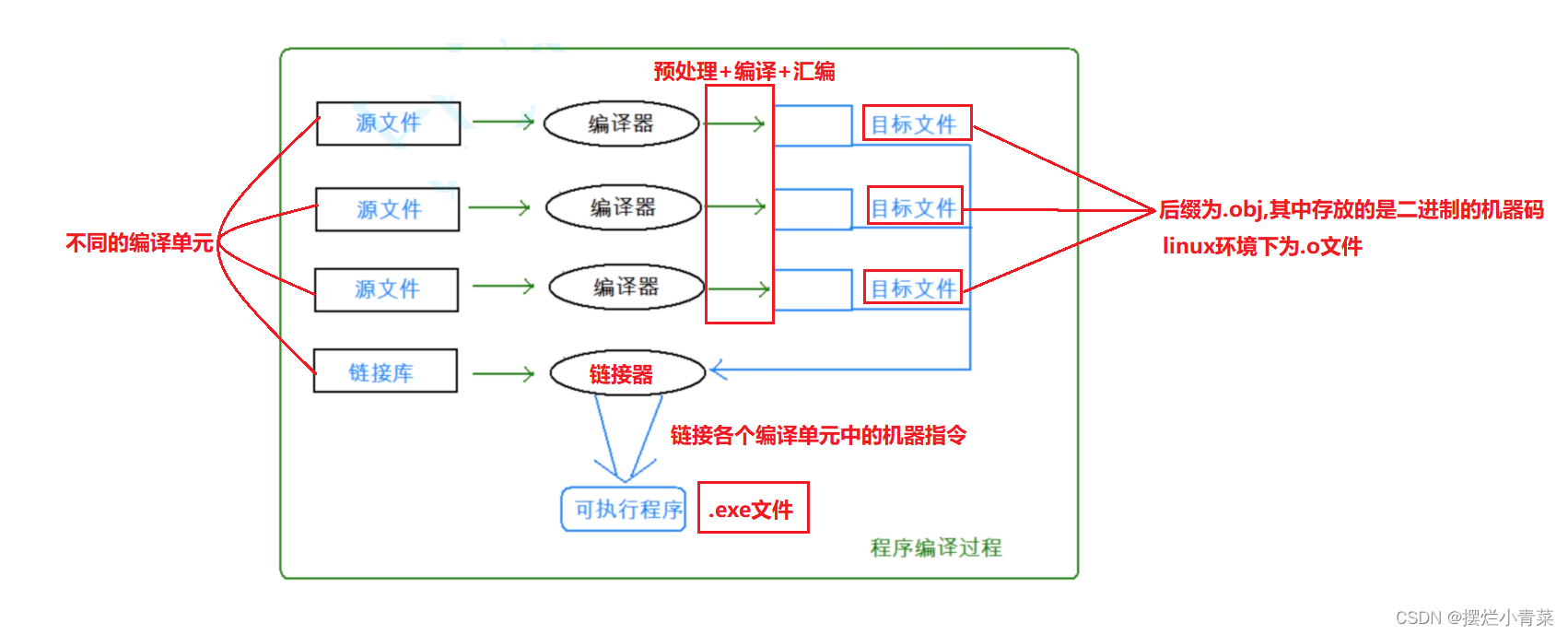
编译器生成可执行程序的过程:
(Linux环境下)
1.对源文件进行预处理: 头文件展开,宏替换,条件编译,去除注释 生成 .i文件
2.编译 : 检查语法,生成汇编代码 生成 .s文件
3.汇编 : 将汇编指令转成二进制机器码 生成 .0文件
4.链接 : 将各编译单元的机器码链接在一起 生成可执行文件
对该段代码进行编译生成汇编指令:
每个函数调用语句都会生成call指令用于寻找内存中存放函数体的地址
call指令是通过函数的符号表来定位函数的地址的。
符号表:
编译器在执行链接之前,会针对各个编译单元生成一个符号表用来记录各个函数的地址(函数的函数体存储在只读常量区中) (每个函数在符号表中都有自己的符号表命名)。
在符号表中,各个函数的命名都遵循一定的函数名修饰规则:
在g++编译环境中,符号表中的函数名经过修饰后变成【_Z+函数名长度+函数名+类型首字母】
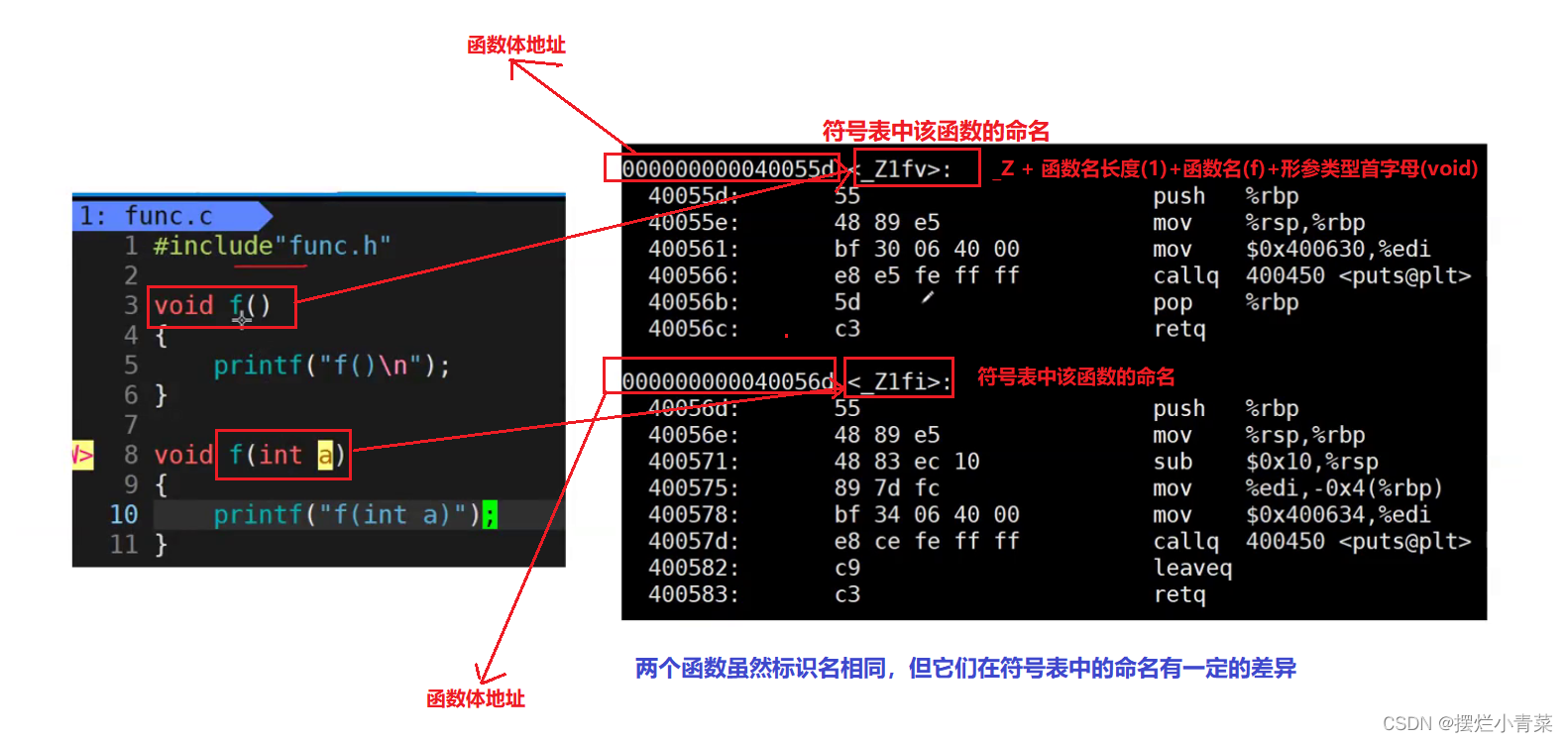
C++(g++编译环境)这种名字修饰规则使得标识名相同,形参不同的函数在符号表中得到了区分,因此编译器在编译和链接的过程中就能根据函数调用语句具体的实参类型明确地找到相应重载函数的函数体的地址并访问函数体中的指令,实现了重载函数的调用。
C语言中不存在这种名词修饰规则,因此在符号表中标识名相同的函数的命名也是相同的,所以编译器在编译和链接的过程中无法对同标识名函数进行区分,所以无法实现函数重载。









![[ZJCTF 2019]NiZhuanSiWei](https://img-blog.csdnimg.cn/e8ca14f4b0a8475ebb743c9ea967e69c.png)