目录
string的应用
insert插入元素
erase删除元素
assign赋值:
replace代替函数的一部分
find:从string对象中找元素
c_str:得到c类型的字符串的指针
substr:取部分元素构建成新的string对象
rfind
find_first_of:从string查找元素
string算法题目:
题目1:字符串中的第一个唯一字符:
题目2:字符串最后一个单词的长度
string的模拟实现(上)
构造函数:
c_str
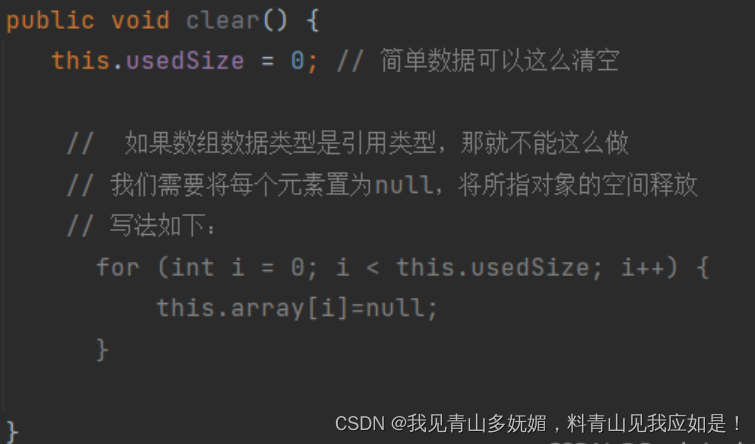
_size
[]
实现迭代器:
迭代器和范围for的关系:
实现尾插:
reserve:修改容量
继续实现尾插:
string的应用
insert插入元素

insert函数的作用是插入字符到string对象中。
其中,第一个函数是比较常用的,我们进行实验:
第一个函数是插入string对象(字符或字符串)到string对象中,例如:
#define _CRT_SECURE_NO_WARNINGS 1
using namespace std;
#include<iostream>
#include<string>
void test1()
{
string s1 = "hello world";
s1.insert(0, "bit");
cout << s1 << endl;
s1.insert(9, "bit");
cout << s1 << endl;
}
int main()
{
test1();
return 0;
}创建string对象s1,string对象的内容是字符串hello world,我们调用insert插入函数,表示分别从下标为0和下标为9的位置插入字符串bit,我们进行输出打印:
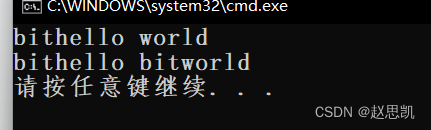
1:insert函数表示插入元素到string对象中,insert函数并不常用,原因是对于头部或者中间位置的插入需要挪动数据,挪动数据会导致效率偏低
erase删除元素

erase函数的作用是从字符串中删除元素。
其中,第一个函数比较常用,我们对第一个函数进行分析:

第一个参数pos表示我们要删除元素的下标,缺省值为0,如果我们不输出第一个参数的话,默认从string对象的首元素的下标开始删除,第二个参数是要删除元素的个数,缺省值是npos。

npos对应的是无符号整型的最大值,大约在42亿左右。
我们进行实验:
void test1()
{
string s1 = "hello world";
s1.insert(0, "bit");
cout << s1 << endl;
s1.insert(9, "bit");
cout << s1 << endl;
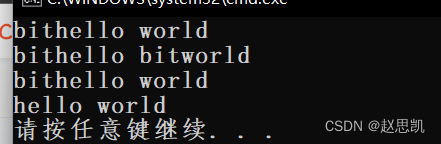
s1.erase(9, 3);
cout << s1 << endl;
s1.erase(0, 3);
cout << s1 << endl;
}
int main()
{
test1();
return 0;
}
注意:假如我们调用函数的第二个参数比我们pos位置之后的元素个数大时,我们会删除之后的全部元素,例如:
void test1()
{
string s1 = "hello world";
/*s1.insert(0, "bit");
cout << s1 << endl;
s1.insert(9, "bit");
cout << s1 << endl;
s1.erase(9, 3);
cout << s1 << endl;
s1.erase(0, 3);
cout << s1 << endl;*/
s1.erase(6, 200);
}
int main()
{
test1();
return 0;
}我们pos位置之后只有5个元素,我们却要删除200个元素,因为200大于5,所以我们会删除pos位置之后的全部元素,具体的原理如图:

所以假如我们想要更轻松的达到以上的效果,我们可以不传第二个参数,因为第二个参数的缺省值是npos,对应的数是42亿,远大于我们剩余元素的个数。
void test1()
{
string s1 = "hello world";
/*s1.insert(0, "bit");
cout << s1 << endl;
s1.insert(9, "bit");
cout << s1 << endl;
s1.erase(9, 3);
cout << s1 << endl;
s1.erase(0, 3);
cout << s1 << endl;*/
s1.erase(6);
cout << s1 << endl;
}
int main()
{
test1();
return 0;
}
1:erase函数表示删除元素。
assign赋值:
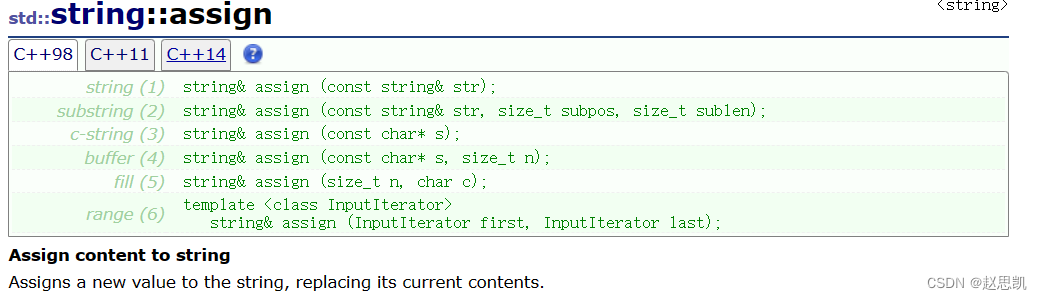
assign相当于把先把原来的string对象清空,然后赋值。
例如:
void test1()
{
string s1 = "hello world";
s1.assign("bit");
cout << s1 << endl;
///*s1.insert(0, "bit");
//cout << s1 << endl;
//s1.insert(9, "bit");
//cout << s1 << endl;
//s1.erase(9, 3);
//cout << s1 << endl;
//s1.erase(0, 3);
//cout << s1 << endl;*/
//s1.erase(6);
//cout << s1 << endl;
}
int main()
{
test1();
return 0;
}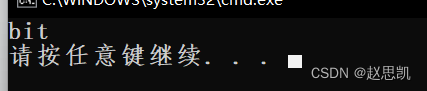
assign函数把string对象原来的hello world替换成了bit。
replace代替函数的一部分

我们使用第一个函数:
![]()
第一个参数表示从pos位置开始,第二个参数len表示代替len个,第三个参数str表示用str来代替这部分。
我们举一个例子:
void test1()
{
string s1 = "hello world";
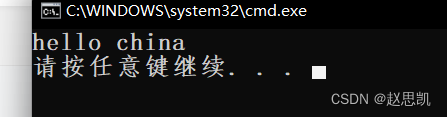
s1.replace(6, 5, "china");
cout << s1 << endl;
/*s1.assign("bit");
cout << s1 << endl;*/
///*s1.insert(0, "bit");
//cout << s1 << endl;
//s1.insert(9, "bit");
//cout << s1 << endl;
//s1.erase(9, 3);
//cout << s1 << endl;
//s1.erase(0, 3);
//cout << s1 << endl;*/
//s1.erase(6);
//cout << s1 << endl;
}
int main()
{
test1();
return 0;
}这里我们用字符串"china"代替从第六个元素开始的五个元素。
find:从string对象中找元素


返回值是如果我们找到了匹配的元素,我们会返回对应匹配元素的第一个元素的下标,如果没有元素匹配,我们返回npos
我们主要理解第一个函数
![]()
第一个参数表示我们要寻找匹配的字符串,第二个参数pos表示我们要从string对象的pos下标开始寻找,pos的缺省值为0,表示如果我们不传参的话,默认从首元素的下标开始查找。
我们可以用一个题目进行练习:
题目1:把字符串中空格全部替换成为"%20"
例如:string s1="hello world hello"
替换之后的结果为"hello%20world%20hello"
我们可以这样写:
void test1()
{
string s1 = "hello world hello";
size_t pos = s1.find(' ');
while (pos != string::npos)
{
s1.replace(pos, 1, "%20");
pos = s1.find(' ', pos + 3);
}
cout << s1 << endl;
/*s1.replace(6, 5, "china");
cout << s1 << endl;*/
/*s1.assign("bit");
cout << s1 << endl;*/
///*s1.insert(0, "bit");
//cout << s1 << endl;
//s1.insert(9, "bit");
//cout << s1 << endl;
//s1.erase(9, 3);
//cout << s1 << endl;
//s1.erase(0, 3);
//cout << s1 << endl;*/
//s1.erase(6);
//cout << s1 << endl;
}
int main()
{
test1();
return 0;
}我们进行运行:
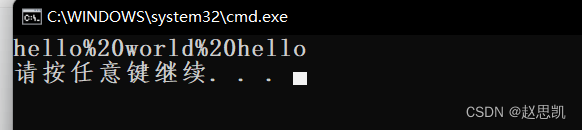
我们完成了需求。
方法2:
void test1()
{
string s1 = "hello world hello";
string ret;
for (auto ch : s1)
{
if (ch!=' ')
{
ret += ch;
}
else
{
ret += "%20";
}
}
cout << ret << endl;
/*size_t pos = s1.find(' ');
while (pos != string::npos)
{
s1.replace(pos, 1, "%20");
pos = s1.find(' ', pos + 3);
}
cout << s1 << endl;*/
/*s1.replace(6, 5, "china");
cout << s1 << endl;*/
/*s1.assign("bit");
cout << s1 << endl;*/
///*s1.insert(0, "bit");
//cout << s1 << endl;
//s1.insert(9, "bit");
//cout << s1 << endl;
//s1.erase(9, 3);
//cout << s1 << endl;
//s1.erase(0, 3);
//cout << s1 << endl;*/
//s1.erase(6);
//cout << s1 << endl;
}
int main()
{
test1();
return 0;
}我们创建一个空对象ret,使用auto for循环,对s1的每一个元素进行判断,假如元素为' ',我们让ret+="%20",假如元素不为' ' ,我们就+=该元素即可。
我们进行运行:
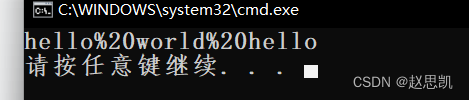
优化:
这里会涉及到容量不够的问题,我们可以实现开辟足够的容量,降低扩容的成本。
void test1()
{
string s1 = "hello world hello";
string ret;
ret.reserve(s1.size());
for (auto ch : s1)
{
if (ch!=' ')
{
ret += ch;
}
else
{
ret += "%20";
}
}
cout << ret << endl;
/*size_t pos = s1.find(' ');
while (pos != string::npos)
{
s1.replace(pos, 1, "%20");
pos = s1.find(' ', pos + 3);
}
cout << s1 << endl;*/
/*s1.replace(6, 5, "china");
cout << s1 << endl;*/
/*s1.assign("bit");
cout << s1 << endl;*/
///*s1.insert(0, "bit");
//cout << s1 << endl;
//s1.insert(9, "bit");
//cout << s1 << endl;
//s1.erase(9, 3);
//cout << s1 << endl;
//s1.erase(0, 3);
//cout << s1 << endl;*/
//s1.erase(6);
//cout << s1 << endl;
}
int main()
{
test1();
return 0;
}c_str:得到c类型的字符串的指针
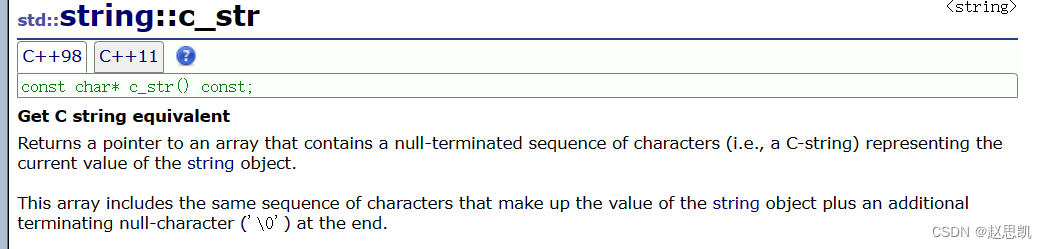
我们知道,string的底层实现的大致格式如下
class string
{
public://成员函数
private:
char* _str;
size_t _size;
size_t _capacity;
};这里的c_str就是这里的_str。
substr:取部分元素构建成新的string对象

![]()
这个函数的作用如下:我们从string对象的pos位置开始,取len个元素产生一个新的string对象并返回。pos的缺省值为0,len的缺省值为npos,表示假如我们不传参数时,我们会构建从0位置开始到string对象最后一个元素的所有元素构成一个新的string对象。
我们如何应用呢?我们可以使用它去取文件的后缀。
例如:
void test2()
{
string s1;
cin >> s1;
size_t pos = s1.find('.');
if (pos != string::npos)
{
string suffix = s1.substr(pos, s1.size() - pos);
cout << suffix << endl;
}
}
int main()
{
test2();
return 0;
}我们进行运行:

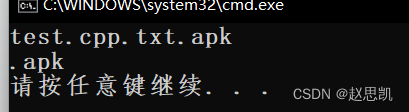
rfind

rfind就是倒着的find
假如我们的文件名如下:test.cpp.txt.apk,我们知道,文件的后缀一定是最后一个.后面的元素。
我们使用rfind解决问题:
find_first_of:从string查找元素

我们解释第一个函数:
![]()
表示我们从pos位置开始找,直到找到与str字符串内部任意相等的元素,并返回第一个相等的元素的下标
void test3()
{
string str("Please, replace the vowels in this sentence by asterisks.");
size_t found = str.find_first_of("aeiou");
while (found != string::npos)
{
str[found] = '*';
found = str.find_first_of("aeiou", found + 1);
}
cout << str << '\n';
}
int main()
{
test3();
return 0;
}我们进行运行:

我们把string对象中的全部的"aeiou"全部替换成了"*".
string算法题目:
题目1:字符串中的第一个唯一字符:

387. 字符串中的第一个唯一字符 - 力扣(Leetcode)
class Solution {
public:
int firstUniqChar(string s) {
int count[26]={0};
for(auto ch:s)
{
count[ch-'a']++;
}
for(size_t i=0;i<s.length();i++)
{
if(count[s[i]-'a']==1)
{
return i;
}
}
return -1;
}
};我们画图进行讲解:
这道题目的要求是要我们找到第一个只出现一次的字符,我们的思路如下:
我们可以创建一个数组,该数组有26个元素,从第1个元素到第26个元素对应的是a到z元素在s
中出现的次数。

数组中每一个元素的初始值都为0。
然后我们使用范围for来统计每一个小写字母出现的次数
class Solution {
public:
int firstUniqChar(string s) {
int count[26] = { 0 };
for (auto ch : s)
{
count[ch - 'a']++;
}
}
};ch对应的是小写字母,ch-'a'就是该小写字母相对于字符'a'的距离,我们可以把'a'的位置设为0,其他的元素按照顺序往后排列。

这个时候,我们的数组记录了每一个元素出现的次数。
接下来,我们遍历s,把s的元素放到count数组中找,直到找到第一个对应元素值为1的,这就是我们第一个只出现一次的字符,我们返回该元素的下标即可
class Solution {
public:
int firstUniqChar(string s) {
int count[26] = { 0 };
for (auto ch : s)
{
count[ch - 'a']++;
}
for (size_t i = 0; i < s.size(); i++)
{
if (count[s[i] - 'a'] == 1)
{
return i;
}
}
return -1;
}
};题目2:字符串最后一个单词的长度
我们可以使用rfind函数,找到最后一个空格,最后一个空格之后的元素个数就是我们要求的长度。
我们可以这样写:
int main()
{
string str;
cin >> str;
size_t pos = str.rfind(' ');
cout << str.size() - pos - 1 << endl;
return 0;
}但是这里有一个问题,cin的输入本身就是以空格和换行为多组输入的间隔,我们可以把空格设置为一个普通的字符,让换行成为多组输入的间隔,我们可以使用getline函数:

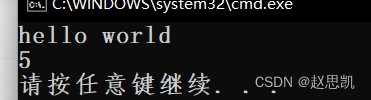
表示从流中取出字符串的一行,默认以换行为间隔,我们可以这样写:
int main()
{
string str;
getline(cin, str);
size_t pos = str.rfind(' ');
cout << str.size() - pos - 1 << endl;
return 0;
}我们进行实验:
string的模拟实现(上)
#pragma once
namespace bit
{
class string
{
public:
private:
char*_str;
size_t _size;
size_t _capacity;
};
}我们先写出框架:
我们用命名空间bit对string类进行封装:
我们一共有三个成员变量,分别是str,_size,_capacity,和顺序表非常相似。
str表示指向string空间的指针,_size表示string的有效元素个数,_capacity表示string的容量。
构造函数:
我们首先要实现构造函数:
string(const char*str)
{
_size = strlen(str);
_capacity = _size;
_str = new char(_capacity + 1);
strcpy(_str, str);
}我们对构造函数进行分析:
我们构造函数的参数用const修饰,因为我们要用该参数构建string对象,不能通过该参数修改string对象。
我们首先使用strlen计算字符串str的有效元素的个数,并赋给_size
然后把_size赋给_capacity,接下来,我们来申请空间。
申请_capacity+1个空间,原因是我们需要给\0留一个空间,所有的成员变量都已经处理完毕,接下来,我们要实现数据的拷贝,我们使用strcpy把字符串str的内容拷贝到_str.
c_str
c_str就是c类型的指针,我们可以把他当成字符串类型首元素的地址,本质上就是_str
const char*c_str()
{
return _str;
}const修饰的意思就是我们只能访问c_str,不能对c_str进行修改。
我们进行实验:
void test_string1()
{
string s1("hello world");
cout << s1.c_str() << endl;
}我们进行运行:

_size
size_t size()
{
return _size;
}[]
char&operator[](size_t pos)
{
assert(pos < _size);
return _str[pos];
}我们要对[]进行重载,我们首先要进行断言,为了防止pos大于有效元素的个数而导致的越界问题,然后我们返回_str[pos],并用引用来接收,原因是[]的元素既可以访问,又可以修改。
我们对[]进行实验:
void test_string1()
{
string s1("hello world");
cout << s1.c_str()<<endl;
for (size_t i = 0;i<s1.size();i++)
{
s1[i]++;
}
cout << s1.c_str() << endl;
}我们进行运行:

证明我们的[]是有效的。
实现迭代器:
迭代器是像指针的一样的,在目前阶段,我们可以把迭代器理解成一个指针。
typedef char*iterator;
iterator begin()
{
return _str;
}
iterator end()
{
return _str + _size;
}我们对迭代器进行实验:
void test_string1()
{
string s1("hello world");
string::iterator it1 = s1.begin();
while (it1 != s1.end())
{
(*it1)++;
it1++;
}
cout << s1.c_str() << endl;
}我们进行运行:

我们成功实现了迭代器。
迭代器和范围for的关系:
void test_string1()
{
string s1("hello world");
for (auto ch : s1)
{
cout << ch << ' ';
}
cout << endl;
}我们进行编译:

我们什么都没有实现,我们却可以调用范围for,原因是什么呢?
范围for的本质是替换成了迭代器,当我们实现了迭代器之后,范围for就可以使用了。
当我们注释掉了迭代器之后

范围for就无法使用:

当我们恢复迭代器并把迭代器的begin换成Begin时:
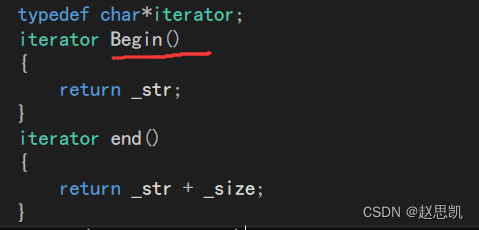

依旧会报错,原因是范围for发生了盲目的简单的替换,只会识别begin而无法识别大写的Begin
实现尾插:
void push_back(char ch)
{
}
void append(const char*str)
{
}前者是尾插一个字符,后者是尾插一个字符串。
实现尾插我们首先要实现+=,不仅要实现+=一个字符,也要实现+=一个字符串。

我们模仿+=实现一个+=字符串和+=字符。
string&operator+=(char ch)
{
push_back(ch);
return *this;
}
string&operator+=(const char*str)
{
append(str);
return *this;
}我们要实现+=的话,首先要想到的就是扩容,要解决扩容的问题,我们就要实现reserve函数:
reserve:修改容量
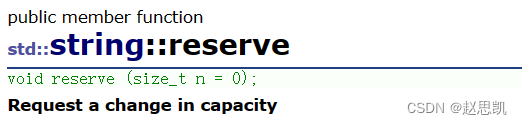
void rerserve(size_t n)
{
char*tmp = new char[n + 1];
strcpy(tmp, _str);
delete[] _str;
_str = tmp;
_capacity = n;
}我们的思路如下:我们与其修改容量,我们不如创建一个更大的空间,然后把原空间的内容拷贝到这个新空间里面,然后释放掉原空间,并且把原空间的容量修改为我们要修改的n
之所以修改为n+1,是因为我们需要多开辟一个空间给\0。
继续实现尾插:
void push_back(char ch)
{
if (_size == _capacity)
{
reserve(_capacity * 2);
}
_str[_size] = ch;
_size++;
_str[_size] = '\0';
}如果我们的容量和我们的有效元素相等时,表示我们的容量已满,我们需要扩容,这里我们可以直接采用扩容二倍的方法,然后把要插入的元素放到string的_size位置处,让_size++,然后把\0放到string的_size位置处。
下节课我们完成append函数。








![[ZJCTF 2019]NiZhuanSiWei](https://img-blog.csdnimg.cn/e8ca14f4b0a8475ebb743c9ea967e69c.png)