from collections import OrderedDict
from typing import Tuple, Union
import numpy as np
import torch
import torch.nn.functional as F
from torch import nn
# 上面都是头文件
Bottleneck类的作用

残差网络 ResNet 等我再去补一补相关知识。
# 这段代码定义了一个名为 Bottleneck 的类,它是一个 PyTorch 模型的子类,用于实现 ResNet 中的瓶颈块
class Bottleneck(nn.Module):
# expansion这个类属性定义了瓶颈块中特征图通道数的扩展倍数。
# 在 ResNet 架构中,瓶颈块的最后一个卷积层输出的特征图通道数是前两个卷积层输出通道数的 4 倍。
expansion = 4
# 这个初始化方法定义了瓶颈块的构造函数。它接受三个参数:输入通道数 inplanes、输出通道数 planes 和步长 stride。
# 默认情况下,步长为 1。
def __init__(self, inplanes, planes, stride=1):
# 这一行调用了父类 nn.Module 的初始化方法,以确保正确地初始化模型。
super().__init__()
# 接下来的代码段初始化了瓶颈块的各个组件,包括三个卷积层、三个批归一化层和三个激活函数层。
# 其中,第一个卷积层的输入通道数为 inplanes,输出通道数为 planes,卷积核大小为 1;
# 第二个卷积层的输入和输出通道数都是 planes,卷积核大小为 3,padding 为 1;
# 第三个卷积层的输入通道数为 planes,输出通道数为 planes * expansion,卷积核大小为 1。
# all conv layers have stride 1. an avgpool is performed after the second convolution when stride > 1
self.conv1 = nn.Conv2d(inplanes, planes, 1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.relu1 = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(planes, planes, 3, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.relu2 = nn.ReLU(inplace=True)
# 这行代码创建了一个平均池化层(nn.AvgPool2d),如果步长大于 1;否则创建了一个恒等映射层(nn.Identity())。
self.avgpool = nn.AvgPool2d(stride) if stride > 1 else nn.Identity()
self.conv3 = nn.Conv2d(planes, planes * self.expansion, 1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * self.expansion)
self.relu3 = nn.ReLU(inplace=True)
self.downsample = None
self.stride = stride
# 这个条件语句判断是否需要进行下采样。
# 如果步长大于 1,或者输入通道数不等于输出通道数乘以扩展倍数,就需要进行下采样。
# 下采样操作包括一个平均池化层、一个 1x1 卷积层和一个批归一化层。
if stride > 1 or inplanes != planes * Bottleneck.expansion:
# downsampling layer is prepended with an avgpool, and the subsequent convolution has stride 1
self.downsample = nn.Sequential(OrderedDict([
("-1", nn.AvgPool2d(stride)),
("0", nn.Conv2d(inplanes, planes * self.expansion, 1, stride=1, bias=False)),
("1", nn.BatchNorm2d(planes * self.expansion))
]))
# 这个方法定义了模型的前向传播过程。它接受一个输入张量 x,并按照瓶颈块的顺序依次执行各个层操作,最终返回输出张量。
def forward(self, x: torch.Tensor):
# 前向传播过程中,首先将输入张量保存到 identity 中,
# 然后依次通过第一个卷积层、批归一化层和激活函数层得到 out1,
# 再通过第二个卷积层、批归一化层和激活函数层得到 out2。
# 如果需要进行下采样,还会对 out2 进行下采样操作。
# 接着,将 out2 通过第三个卷积层和批归一化层得到 out3。最后,将 out3 与 identity 相加,并通过激活函数得到最终的输出
identity = x
out = self.relu1(self.bn1(self.conv1(x)))
out = self.relu2(self.bn2(self.conv2(out)))
out = self.avgpool(out)
out = self.bn3(self.conv3(out))
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu3(out)
return out
# 这段代码定义了一个名为 AttentionPool2d 的类,
# 实现了一个基于注意力机制的二维池化层,可以用于图像等二维数据的特征提取和降维。
class AttentionPool2d(nn.Module):
# 这是初始化方法,用于创建一个 AttentionPool2d 的实例。
# 它接受四个参数:spacial_dim 表示输入特征图的空间维度大小,embed_dim 表示嵌入维度大小,
# num_heads 表示注意力头的数量,output_dim 表示输出维度大小(默认为 None,如果未指定则与嵌入维度相同)。
def __init__(self, spacial_dim: int, embed_dim: int, num_heads: int, output_dim: int = None):
# 调用父类 nn.Module 的初始化方法,确保正确初始化模型。
super().__init__()
# 初始化了几个参数化的层,包括位置嵌入(positional_embedding)、查询投影(q_proj)、
# 键投影(k_proj)、值投影(v_proj)和输出投影(c_proj)。
# 这些层的作用是将输入特征映射到注意力空间,并最终得到输出。
self.positional_embedding = nn.Parameter(torch.randn(spacial_dim ** 2 + 1, embed_dim) / embed_dim ** 0.5)
self.k_proj = nn.Linear(embed_dim, embed_dim)
self.q_proj = nn.Linear(embed_dim, embed_dim)
self.v_proj = nn.Linear(embed_dim, embed_dim)
self.c_proj = nn.Linear(embed_dim, output_dim or embed_dim)
self.num_heads = num_heads
# 这是前向传播方法,接受输入张量 x,并按照注意力池化的过程进行计算,最终返回池化后的特征张量。
def forward(self, x):
# 在前向传播过程中,首先将输入张量 x 展平,并将通道维度移到第一个维度上,以便后续的注意力计算。
x = x.flatten(start_dim=2).permute(2, 0, 1) # NCHW -> (HW)NC
# 然后,在特征图的开头添加了一个位置嵌入,用于引入位置信息。
x = torch.cat([x.mean(dim=0, keepdim=True), x], dim=0) # (HW+1)NC
x = x + self.positional_embedding[:, None, :].to(x.dtype) # (HW+1)NC
# 接着,调用了 PyTorch 提供的 F.multi_head_attention_forward() 函数进行多头注意力计算,得到了池化后的特征张量。
x, _ = F.multi_head_attention_forward(
query=x[:1], key=x, value=x,
embed_dim_to_check=x.shape[-1],
num_heads=self.num_heads,
q_proj_weight=self.q_proj.weight,
k_proj_weight=self.k_proj.weight,
v_proj_weight=self.v_proj.weight,
in_proj_weight=None,
in_proj_bias=torch.cat([self.q_proj.bias, self.k_proj.bias, self.v_proj.bias]),
bias_k=None,
bias_v=None,
add_zero_attn=False,
dropout_p=0,
out_proj_weight=self.c_proj.weight,
out_proj_bias=self.c_proj.bias,
use_separate_proj_weight=True,
training=self.training,
need_weights=False
)
# 最后,将池化后的特征张量进行了维度调整,去除了添加的位置嵌入,并返回池化后的特征张量
return x.squeeze(0)
# 这段代码定义了一个名为 ModifiedResNet 的类,它是一个修改过的 ResNet 类,
# 与 torchvision 中的 ResNet 类相似,但包含一些改变
class ModifiedResNet(nn.Module):
"""
A ResNet class that is similar to torchvision's but contains the following changes:
- There are now 3 "stem" convolutions as opposed to 1, with an average pool instead of a max pool.
- Performs anti-aliasing strided convolutions, where an avgpool is prepended to convolutions with stride > 1
- The final pooling layer is a QKV attention instead of an average pool
"""
# 这是初始化方法,用于创建一个 ModifiedResNet 的实例。
# 它接受几个参数:layers 是一个列表,表示每个阶段的残差块数量;
# output_dim 是输出维度大小;heads 是注意力头的数量;
# input_resolution 是输入图像的分辨率,默认为 224;width 是网络的初始通道数,默认为 64。
def __init__(self, layers, output_dim, heads, input_resolution=224, width=64):
super().__init__()
self.output_dim = output_dim
self.input_resolution = input_resolution
# the 3-layer stem
# 初始化了几个参数化的层,包括 3 个卷积层和相应的批归一化层和激活函数层,
# 用于构建网络的初始部分(称为“stem”)。这里的改变包括了将原始的 1 个卷积层改为 3 个卷积层,
# 并使用平均池化代替了最大池化。
self.conv1 = nn.Conv2d(3, width // 2, kernel_size=3, stride=2, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(width // 2)
self.relu1 = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(width // 2, width // 2, kernel_size=3, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(width // 2)
self.relu2 = nn.ReLU(inplace=True)
self.conv3 = nn.Conv2d(width // 2, width, kernel_size=3, padding=1, bias=False)
self.bn3 = nn.BatchNorm2d(width)
self.relu3 = nn.ReLU(inplace=True)
self.avgpool = nn.AvgPool2d(2)
# residual layers
# 通过调用 _make_layer 函数创建了 4 个残差阶段(layer1 到 layer4),每个阶段包含了一系列残差块
self._inplanes = width # this is a *mutable* variable used during construction
self.layer1 = self._make_layer(width, layers[0])
self.layer2 = self._make_layer(width * 2, layers[1], stride=2)
self.layer3 = self._make_layer(width * 4, layers[2], stride=2)
self.layer4 = self._make_layer(width * 8, layers[3], stride=2)
embed_dim = width * 32 # the ResNet feature dimension
self.attnpool = AttentionPool2d(input_resolution // 32, embed_dim, heads, output_dim)
# 定义了一个辅助函数 _make_layer(self, planes, blocks, stride=1),用于构建残差块序列。
# 在这个函数中,通过多次调用 Bottleneck 类创建了指定数量的残差块,并将它们组合成一个 nn.Sequential 对象。
def _make_layer(self, planes, blocks, stride=1):
layers = [Bottleneck(self._inplanes, planes, stride)]
self._inplanes = planes * Bottleneck.expansion
for _ in range(1, blocks):
layers.append(Bottleneck(self._inplanes, planes))
return nn.Sequential(*layers)
# 最后,定义了一个前向传播方法 forward(self, x)。在这个方法中,
# 首先通过 stem 函数对输入进行初始处理,然后依次经过残差阶段和注意力池化层,最终得到网络的输出。
def forward(self, x):
def stem(x):
x = self.relu1(self.bn1(self.conv1(x)))
x = self.relu2(self.bn2(self.conv2(x)))
x = self.relu3(self.bn3(self.conv3(x)))
x = self.avgpool(x)
return x
x = x.type(self.conv1.weight.dtype)
x = stem(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.attnpool(x)
return x
# 这段代码定义了一个名为 LayerNorm 的类,它是 nn.LayerNorm 类的子类,用于处理带有 FP16 数据类型的输入
class LayerNorm(nn.LayerNorm):
"""Subclass torch's LayerNorm to handle fp16."""
# 这是前向传播方法。它接受一个输入张量 x,并返回经过 LayerNorm 处理后的张量。
def forward(self, x: torch.Tensor):
# 保存输入张量 x 的原始数据类型。
orig_type = x.dtype
# 调用父类的前向传播方法,并将输入张量的数据类型转换为 torch.float32,
# 因为 nn.LayerNorm 类默认只支持 torch.float32 类型的张量。
ret = super().forward(x.type(torch.float32))
# 将处理后的张量的数据类型转换回原始数据类型,并返回。这样做是为了避免输出张量的数据类型与输入张量不匹配的问题
return ret.type(orig_type)
# 这段代码定义了一个名为 QuickGELU 的类,它是一个快速实现的 GELU(Gaussian Error Linear Units)激活函数
class QuickGELU(nn.Module):
def forward(self, x: torch.Tensor):
# 这行代码实现了 GELU 激活函数的计算公式。GELU 激活函数是基于 Sigmoid 函数的改进版本,在神经网络中常用于增加非线性。
return x * torch.sigmoid(1.702 * x)
QuickGELU 类设计的细节

# 这段代码定义了一个名为 ResidualAttentionBlock 的类,它实现了一个残差注意力块(Residual Attention Block)
class ResidualAttentionBlock(nn.Module):
# 这是初始化方法,用于创建一个 ResidualAttentionBlock 的实例。
# 它接受三个参数:d_model 表示输入特征的维度大小,n_head 表示注意力头的数量,
# attn_mask 是一个可选的注意力掩码,默认为 None。
def __init__(self, d_model: int, n_head: int, attn_mask: torch.Tensor = None):
super().__init__()
# 初始化了几个子模块,包括多头注意力机制层(attn)、LayerNorm 层(ln_1 和 ln_2)以及 MLP 层(mlp)。
# 其中,多头注意力机制层接受输入特征,并计算出注意力加权的输出;
# LayerNorm 层用于对输入和注意力输出进行层归一化;
# MLP 层包含了两个线性层和一个 GELU 激活函数,用于对注意力输出进行非线性变换。
self.attn = nn.MultiheadAttention(d_model, n_head)
self.ln_1 = LayerNorm(d_model)
self.mlp = nn.Sequential(OrderedDict([
("c_fc", nn.Linear(d_model, d_model * 4)),
("gelu", QuickGELU()),
("c_proj", nn.Linear(d_model * 4, d_model))
]))
self.ln_2 = LayerNorm(d_model)
self.attn_mask = attn_mask
# 这是一个辅助方法,用于计算多头注意力机制的输出。它接受输入特征 x,并返回注意力加权的输出。
# 在这个方法中,注意力掩码(如果提供)会被转换为与输入特征相同的数据类型和设备类型。
def attention(self, x: torch.Tensor):
self.attn_mask = self.attn_mask.to(dtype=x.dtype, device=x.device) if self.attn_mask is not None else None
return self.attn(x, x, x, need_weights=False, attn_mask=self.attn_mask)[0]
# 这是前向传播方法,接受输入特征 x,并返回经过残差注意力块处理后的特征。
# 在这个方法中,首先对输入特征进行层归一化,并通过多头注意力机制层得到注意力加权的输出;
# 然后将输入特征与注意力输出相加,得到残差连接的结果;
# 最后,通过 MLP 层对残差连接的结果进行非线性变换,并再次与输入特征相加,得到最终的输出特征。
def forward(self, x: torch.Tensor):
x = x + self.attention(self.ln_1(x))
x = x + self.mlp(self.ln_2(x))
return x
# 这段代码定义了一个 Transformer 模型类,用于自然语言处理等任务。
# 它包含了多个残差注意力块(Residual Attention Block)。
# 在初始化方法中,模型的参数包括宽度(width)、层数(layers)、注意力头数(heads),还有一个可选的注意力掩码(attn_mask)。
# 在前向传播方法中,输入张量 x 通过一系列残差注意力块(resblocks)进行处理,并直接返回输出。
class Transformer(nn.Module):
def __init__(self, width: int, layers: int, heads: int, attn_mask: torch.Tensor = None):
super().__init__()
self.width = width
self.layers = layers
self.resblocks = nn.Sequential(*[ResidualAttentionBlock(width, heads, attn_mask) for _ in range(layers)])
def forward(self, x: torch.Tensor):
return self.resblocks(x)
# 这段代码定义了一个视觉 Transformer 模型类,通常用于图像处理任务
class VisionTransformer(nn.Module):
def __init__(
self,
# 输入图像的分辨率。
input_resolution: int,
# 用于将图像分割成小块的大小。
patch_size: int,
# 模型中隐藏层的维度。
width: int,
# Transformer 中的层数。
layers: int,
# 注意力机制中的头数。
heads: int,
# 最终输出的维度。
output_dim: int
):
super().__init__()
self.input_resolution = input_resolution
self.output_dim = output_dim
# 这是一个 2D 卷积层,将输入的图像进行卷积操作,用于提取局部特征。
self.conv1 = nn.Conv2d(in_channels=3, out_channels=width, kernel_size=patch_size, stride=patch_size, bias=False)
scale = width ** -0.5
# 类嵌入 (self.class_embedding) 和 位置嵌入 (self.positional_embedding):
# 这些嵌入向量用于将类别信息和位置信息引入到模型中。
# class_embedding 是一个 learnable 的参数,用于表示整个输入的类别信息。
self.class_embedding = nn.Parameter(scale * torch.randn(width))
# positional_embedding 是一个 learnable 的参数,用于表示每个位置的位置信息。
self.positional_embedding = nn.Parameter(scale * torch.randn((input_resolution // patch_size) ** 2 + 1, width))
# 层归一化 (self.ln_pre 和 self.ln_post):
# 这些层归一化模块用于在输入进入 Transformer 前后对特征进行归一化处理。
self.ln_pre = LayerNorm(width)
# Transformer 模块 (self.transformer):
# 这是核心的 Transformer 结构,接受特征表示作为输入,在多个层间进行自注意力和前馈网络操作。
self.transformer = Transformer(width, layers, heads)
# 这些层归一化模块用于在输入进入 Transformer 前后对特征进行归一化处理。
self.ln_post = LayerNorm(width)
# 线性变换参数 (self.proj):
# 这个参数用于将 Transformer 的输出映射到最终的输出维度
self.proj = nn.Parameter(scale * torch.randn(width, output_dim))
def forward(self, x: torch.Tensor):
x = self.conv1(x) # shape = [*, width, grid, grid]
x = x.reshape(x.shape[0], x.shape[1], -1) # shape = [*, width, grid ** 2]
x = x.permute(0, 2, 1) # shape = [*, grid ** 2, width]
# 输入图像经过卷积层和形状变换后,与类嵌入和位置嵌入相加
x = torch.cat([self.class_embedding.to(x.dtype) + torch.zeros(x.shape[0], 1, x.shape[-1], dtype=x.dtype, device=x.device), x], dim=1) # shape = [*, grid ** 2 + 1, width]
x = x + self.positional_embedding.to(x.dtype)
# 进行层归一化和维度调整后,输入进入 Transformer 模块处理。
x = self.ln_pre(x)
x = x.permute(1, 0, 2) # NLD -> LND
x = self.transformer(x)
# 处理后的结果再次进行维度调整和层归一化。
x = x.permute(1, 0, 2) # LND -> NLD
x = self.ln_post(x[:, 0, :])
# 如果有线性变换参数,则进行线性变换
if self.proj is not None:
x = x @ self.proj
# 最终返回输出结果
return x
# 这个 CLIP 类实现了一个混合视觉-文本编码器,该编码器能够将图像和文本转换为嵌入向量,
# 并通过计算它们之间的余弦相似度来产生分类的 logits
class CLIP(nn.Module):
def __init__(self,
# 嵌入向量的维度
embed_dim: int,
# vision:
# 输入图像的分辨率
image_resolution: int,
# 用于视觉编码的层级结构。它可以是一个整数,表示 Vision Transformer 的层数,
# 或者是一个长度为 4 的元组,表示 Modified ResNet 的各个层级的卷积层数
vision_layers: Union[Tuple[int, int, int, int], int],
# 视觉编码器中隐藏层的宽度
vision_width: int,
# 视觉编码器中的图像块大小
vision_patch_size: int,
# text:
# 文本输入的长度
context_length: int,
# 词汇表的大小
vocab_size: int,
# Transformer 模型的隐藏层宽度
transformer_width: int,
# Transformer 模型中的注意力头数
transformer_heads: int,
# Transformer 模型的层数
transformer_layers: int
):
super().__init__()
# context_length 被保存为一个属性
self.context_length = context_length
# 如果 vision_layers 是一个元组或列表,则使用 Modified ResNet 构建图像编码器,
# 否则使用 Vision Transformer 构建。
if isinstance(vision_layers, (tuple, list)):
vision_heads = vision_width * 32 // 64
self.visual = ModifiedResNet(
layers=vision_layers,
output_dim=embed_dim,
heads=vision_heads,
input_resolution=image_resolution,
width=vision_width
)
else:
vision_heads = vision_width // 64
self.visual = VisionTransformer(
input_resolution=image_resolution,
patch_size=vision_patch_size,
width=vision_width,
layers=vision_layers,
heads=vision_heads,
output_dim=embed_dim
)
# 使用传入的参数初始化 Transformer 模型
self.transformer = Transformer(
width=transformer_width,
layers=transformer_layers,
heads=transformer_heads,
attn_mask=self.build_attention_mask()
)
# 初始化词嵌入、位置嵌入、层归一化、文本投影和 logits 缩放参数
self.vocab_size = vocab_size
self.token_embedding = nn.Embedding(vocab_size, transformer_width)
self.positional_embedding = nn.Parameter(torch.empty(self.context_length, transformer_width))
self.ln_final = LayerNorm(transformer_width)
self.text_projection = nn.Parameter(torch.empty(transformer_width, embed_dim))
self.logit_scale = nn.Parameter(torch.ones([]) * np.log(1 / 0.07))
# 调用 initialize_parameters() 方法,该方法用于初始化各个组件的参数
self.initialize_parameters()
def initialize_parameters(self):
# 词嵌入和位置嵌入的初始化:
# self.token_embedding.weight 是词嵌入矩阵,通过正态分布初始化,标准差为 0.02。
nn.init.normal_(self.token_embedding.weight, std=0.02)
# self.positional_embedding 是位置嵌入矩阵,也通过正态分布初始化,标准差为 0.01。
nn.init.normal_(self.positional_embedding, std=0.01)
# Modified ResNet 的参数初始化:
# 如果视觉编码器选择的是 Modified ResNet,那么它的参数也需要进行初始化
if isinstance(self.visual, ModifiedResNet):
# 如果 Modified ResNet 中包含注意力池化层(attnpool),则注意力池化层中的参数也通过正态分布初始化。
if self.visual.attnpool is not None:
std = self.visual.attnpool.c_proj.in_features ** -0.5
nn.init.normal_(self.visual.attnpool.q_proj.weight, std=std)
nn.init.normal_(self.visual.attnpool.k_proj.weight, std=std)
nn.init.normal_(self.visual.attnpool.v_proj.weight, std=std)
nn.init.normal_(self.visual.attnpool.c_proj.weight, std=std)
# 对于 Modified ResNet 的各个残差块(layer1、layer2、layer3、layer4)中的 BatchNorm 层的权重,
# 将其初始化为零。
for resnet_block in [self.visual.layer1, self.visual.layer2, self.visual.layer3, self.visual.layer4]:
for name, param in resnet_block.named_parameters():
if name.endswith("bn3.weight"):
nn.init.zeros_(param)
# Transformer 模型的参数初始化:
proj_std = (self.transformer.width ** -0.5) * ((2 * self.transformer.layers) ** -0.5)
attn_std = self.transformer.width ** -0.5
fc_std = (2 * self.transformer.width) ** -0.5
# 对于 Transformer 模型中的每个残差块(resblocks)的注意力层和前馈网络层的参数,
# 通过正态分布进行初始化,其中注意力层的标准差为 attn_std,前馈网络层的标准差为 fc_std。
# 这些标准差是根据 Transformer 的隐藏层宽度和层数计算得到的(上面三行代码)。
for block in self.transformer.resblocks:
nn.init.normal_(block.attn.in_proj_weight, std=attn_std)
nn.init.normal_(block.attn.out_proj.weight, std=proj_std)
nn.init.normal_(block.mlp.c_fc.weight, std=fc_std)
nn.init.normal_(block.mlp.c_proj.weight, std=proj_std)
# 文本投影矩阵的初始化:
# 如果存在文本投影矩阵(text_projection),则通过正态分布初始化,标准差为 Transformer 的隐藏层宽度的倒数的平方
if self.text_projection is not None:
nn.init.normal_(self.text_projection, std=self.transformer.width ** -0.5)
# 这个方法用于构建 Transformer 模型中的自注意力机制所需的掩码矩阵
def build_attention_mask(self):
# lazily create causal attention mask, with full attention between the vision tokens
# pytorch uses additive attention mask; fill with -inf
# 创建空的掩码矩阵:
# 通过调用 torch.empty 创建一个空的二维张量(矩阵),其大小为 self.context_length × self.context_length。
# 这个矩阵用于存储掩码值
mask = torch.empty(self.context_length, self.context_length)
# 填充掩码矩阵:
# 使用 fill_ 方法将整个矩阵填充为负无穷(float("-inf"))。
# 这是因为在 PyTorch 中,自注意力机制的掩码矩阵采用了加性注意力掩码的方式,
# 其中掩码值被加到注意力分数上,以实现屏蔽某些位置的效果
mask.fill_(float("-inf"))
# 将掩码下三角区域置零:
# 使用 triu_ 方法将掩码矩阵的下三角区域(包括对角线)置零,
# 这样就保证了模型在自注意力计算中只能注意到当前位置及其之前的位置,实现了“因果”注意力机制。
mask.triu_(1) # zero out the lower diagonal
# 返回掩码矩阵:
# 返回构建好的掩码矩阵,该矩阵将在 Transformer 模型的前向传播过程中被应用于自注意力机制中。
return mask
# 这段代码定义了一个属性 dtype,它返回了视觉编码器中的第一个卷积层参数 conv1 的数据类型:
# @property 装饰器将方法 dtype() 转换为属性,这意味着你可以像访问属性一样使用它,而不需要使用括号调用它。
@property
def dtype(self):
# 在方法体中,self.visual.conv1.weight.dtype 返回了第一个卷积层的权重张量的数据类型。
# .dtype 是 PyTorch 张量的一个属性,用于获取张量的数据类型。
return self.visual.conv1.weight.dtype
# 这个方法 encode_image 用于将输入的图像通过视觉编码器进行编码,生成图像的特征表示
# image 参数是输入的图像数据
def encode_image(self, image):
# self.visual 是视觉编码器模型,它将被用来处理输入图像
# image.type(self.dtype) 将输入图像的数据类型转换为与视觉编码器的第一个卷积层参数相同的数据类型。
# 这是因为在 PyTorch 中,数据类型必须匹配才能进行计算,所以要确保输入图像的数据类型与模型的参数数据类型一致。
# 最后,将转换后的图像数据传递给视觉编码器 self.visual 进行处理,并返回处理后的特征表示。
return self.visual(image.type(self.dtype))
# 这个方法 encode_text 用于将输入的文本通过文本编码器进行编码,生成文本的特征表示
# text 参数是输入的文本数据
def encode_text(self, text):
# 首先,将文本数据通过词嵌入 self.token_embedding 进行编码,得到文本的嵌入表示 x。
# 这里使用 .type(self.dtype) 将其数据类型转换为与模型的参数数据类型相同的类型。
x = self.token_embedding(text).type(self.dtype) # [batch_size, n_ctx, d_model]
# 然后,将文本的嵌入表示 x 加上位置嵌入 self.positional_embedding,这是为了加入文本的位置信息。
x = x + self.positional_embedding.type(self.dtype)
# 接着,通过 permute 方法将 x 的维度从 NLD(批大小、文本长度、嵌入维度)转换为 LND(文本长度、批大小、嵌入维度),
# 以满足 Transformer 模型的输入要求。
x = x.permute(1, 0, 2) # NLD -> LND
# 将转换后的 x 输入到 Transformer 模型 self.transformer 中进行处理,得到处理后的特征表示。
x = self.transformer(x)
# 再次通过 permute 方法将特征表示的维度从 LND 转换回到 NLD。
x = x.permute(1, 0, 2) # LND -> NLD
# 通过层归一化 self.ln_final 处理特征表示,并将其数据类型转换为与模型参数数据类型相同的类型。
x = self.ln_final(x).type(self.dtype)
# x.shape = [batch_size, n_ctx, transformer.width]
# take features from the eot embedding (eot_token is the highest number in each sequence)
# 接下来,根据文本的最高数值所在位置,提取对应的特征,并通过线性变换 self.text_projection 将其映射到所需的维度上。
x = x[torch.arange(x.shape[0]), text.argmax(dim=-1)] @ self.text_projection
# 最后,返回经过线性变换后的特征表示。
return x
# 这个 forward 方法定义了模型的前向传播过程,即输入图像和文本,
# 通过编码器将它们转换为特征表示,并计算它们之间的余弦相似度作为分类的 logits
def forward(self, image, text):
# 图像和文本编码:
# 调用 encode_image 方法和 encode_text 方法,分别将输入的图像和文本转换为特征表示
image_features = self.encode_image(image)
text_features = self.encode_text(text)
# normalized features
# 特征向量的归一化:
# 对图像特征向量和文本特征向量进行 L2 归一化,以确保它们具有单位长度,这对于余弦相似度的计算非常重要。
# 归一化后,两个特征向量的余弦相似度将只受它们之间的角度影响,而不受它们的原始长度影响
image_features = image_features / image_features.norm(dim=1, keepdim=True)
text_features = text_features / text_features.norm(dim=1, keepdim=True)
# cosine similarity as logits
# 计算余弦相似度:
# 将图像特征向量和文本特征向量的余弦相似度作为分类的 logits。
# logit_scale.exp() 将 logit_scale 参数作为指数函数进行指数化,以确保它的值始终为正。
logit_scale = self.logit_scale.exp()
# 使用矩阵乘法 @ 计算图像特征向量和文本特征向量之间的相似度矩阵,并乘以 logit_scale。
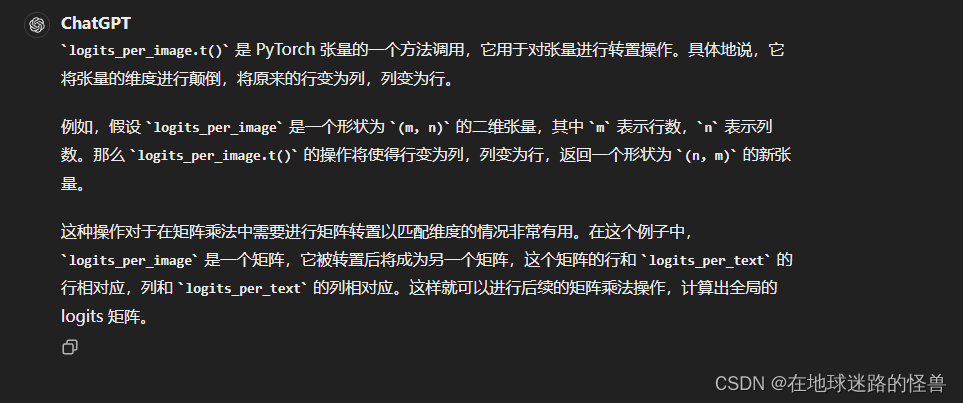
logits_per_image = logit_scale * image_features @ text_features.t()
# 返回两个方向上的 logits:logits_per_image 和 logits_per_text。
logits_per_text = logits_per_image.t()
# shape = [global_batch_size, global_batch_size]
# 将计算得到的 logits 返回作为方法的输出。这些 logits 将用于后续的损失计算和训练过程中。
return logits_per_image, logits_per_text
logits_per_image.t() 这个方法的作用
# 这个 convert_weights 函数的作用是将模型中适用的参数转换为半精度浮点数格式(FP16)
def convert_weights(model: nn.Module):
"""Convert applicable model parameters to fp16"""
# 这是一个内部函数,用于将给定层 l 的参数转换为半精度浮点数格式。
def _convert_weights_to_fp16(l):
# 首先,它检查层的类型是否为卷积层 (nn.Conv1d, nn.Conv2d) 或线性层 (nn.Linear),
# 如果是,则将权重 (weight) 和偏置 (bias) 的数据类型转换为半精度浮点数。
if isinstance(l, (nn.Conv1d, nn.Conv2d, nn.Linear)):
l.weight.data = l.weight.data.half()
if l.bias is not None:
l.bias.data = l.bias.data.half()
# 接着,如果层是多头注意力层 (nn.MultiheadAttention),则对其内部的参数进行相同的操作,
# 包括输入、查询、键、值的投影权重、输入投影偏置以及键值投影的偏置。
if isinstance(l, nn.MultiheadAttention):
for attr in [*[f"{s}_proj_weight" for s in ["in", "q", "k", "v"]], "in_proj_bias", "bias_k", "bias_v"]:
tensor = getattr(l, attr)
if tensor is not None:
tensor.data = tensor.data.half()
# 最后,它检查层是否具有名为 text_projection 或 proj 的属性,如果有,则将其数据类型转换为半精度浮点数。
for name in ["text_projection", "proj"]:
if hasattr(l, name):
attr = getattr(l, name)
if attr is not None:
attr.data = attr.data.half()
# 这一行代码是将 _convert_weights_to_fp16 函数应用于模型中的每一层
# model.apply() 方法接受一个函数,并将该函数应用于模型的每一层,以实现对模型中所有适用参数的批量操作。
model.apply(_convert_weights_to_fp16)
#综合起来,这个函数用于将模型中的适用参数转换为半精度浮点数格式,以减少内存占用并提高计算速度,
# 尤其适用于在计算资源有限的情况下
# 这个 build_model 函数根据给定的模型参数的状态字典来构建一个 CLIP 模型
def build_model(state_dict: dict):
# 1、确定视觉编码器参数:
# 首先,检查状态字典中是否存在 visual.proj 键,以确定是使用 Vision Transformer 还是 Modified ResNet 进行视觉编码。
vit = "visual.proj" in state_dict
if vit:
# 如果是 Vision Transformer,根据状态字典中的参数确定视觉编码器的宽度、层数、图像分辨率和补丁大小。
vision_width = state_dict["visual.conv1.weight"].shape[0]
vision_layers = len([k for k in state_dict.keys() if k.startswith("visual.") and k.endswith(".attn.in_proj_weight")])
vision_patch_size = state_dict["visual.conv1.weight"].shape[-1]
grid_size = round((state_dict["visual.positional_embedding"].shape[0] - 1) ** 0.5)
image_resolution = vision_patch_size * grid_size
else:
# 如果是 Modified ResNet,则根据状态字典中的参数确定视觉编码器的层数、宽度和图像分辨率,补丁大小将被设为 None
counts: list = [len(set(k.split(".")[2] for k in state_dict if k.startswith(f"visual.layer{b}"))) for b in [1, 2, 3, 4]]
vision_layers = tuple(counts)
vision_width = state_dict["visual.layer1.0.conv1.weight"].shape[0]
output_width = round((state_dict["visual.attnpool.positional_embedding"].shape[0] - 1) ** 0.5)
vision_patch_size = None
assert output_width ** 2 + 1 == state_dict["visual.attnpool.positional_embedding"].shape[0]
image_resolution = output_width * 32
# 2、确定文本编码器参数
# 提取状态字典中的参数,如嵌入维度、上下文长度和词汇表大小等。
embed_dim = state_dict["text_projection"].shape[1]
context_length = state_dict["positional_embedding"].shape[0]
vocab_size = state_dict["token_embedding.weight"].shape[0]
transformer_width = state_dict["ln_final.weight"].shape[0]
transformer_heads = transformer_width // 64
transformer_layers = len(set(k.split(".")[2] for k in state_dict if k.startswith("transformer.resblocks")))
# 3、构建 CLIP 模型
# 使用上述提取的参数来构建 CLIP 模型实例。
model = CLIP(
embed_dim,
image_resolution, vision_layers, vision_width, vision_patch_size,
context_length, vocab_size, transformer_width, transformer_heads, transformer_layers
)
# 4、删除不需要的键:
# 从状态字典中删除一些不再需要的键,如输入分辨率、上下文长度和词汇表大小等
for key in ["input_resolution", "context_length", "vocab_size"]:
if key in state_dict:
del state_dict[key]
# 5、转换模型参数为半精度浮点数
# 调用 convert_weights 函数,将模型的适用参数转换为半精度浮点数格式。
convert_weights(model)
# 6、加载状态字典到模型:
# 将经过处理的状态字典加载到构建好的模型中
model.load_state_dict(state_dict)
# 7、返回模型:
# 返回构建好的模型,并将其设置为评估模式。
return model.eval()