目录:
(1)ES集群-集群结构介绍
(2)es集群-搭建集群
(3)es集群-集群职责及脑裂
(4)es集群-分布式新增和查询流程
(5) es集群-故障转移
(1)ES集群-集群结构介绍

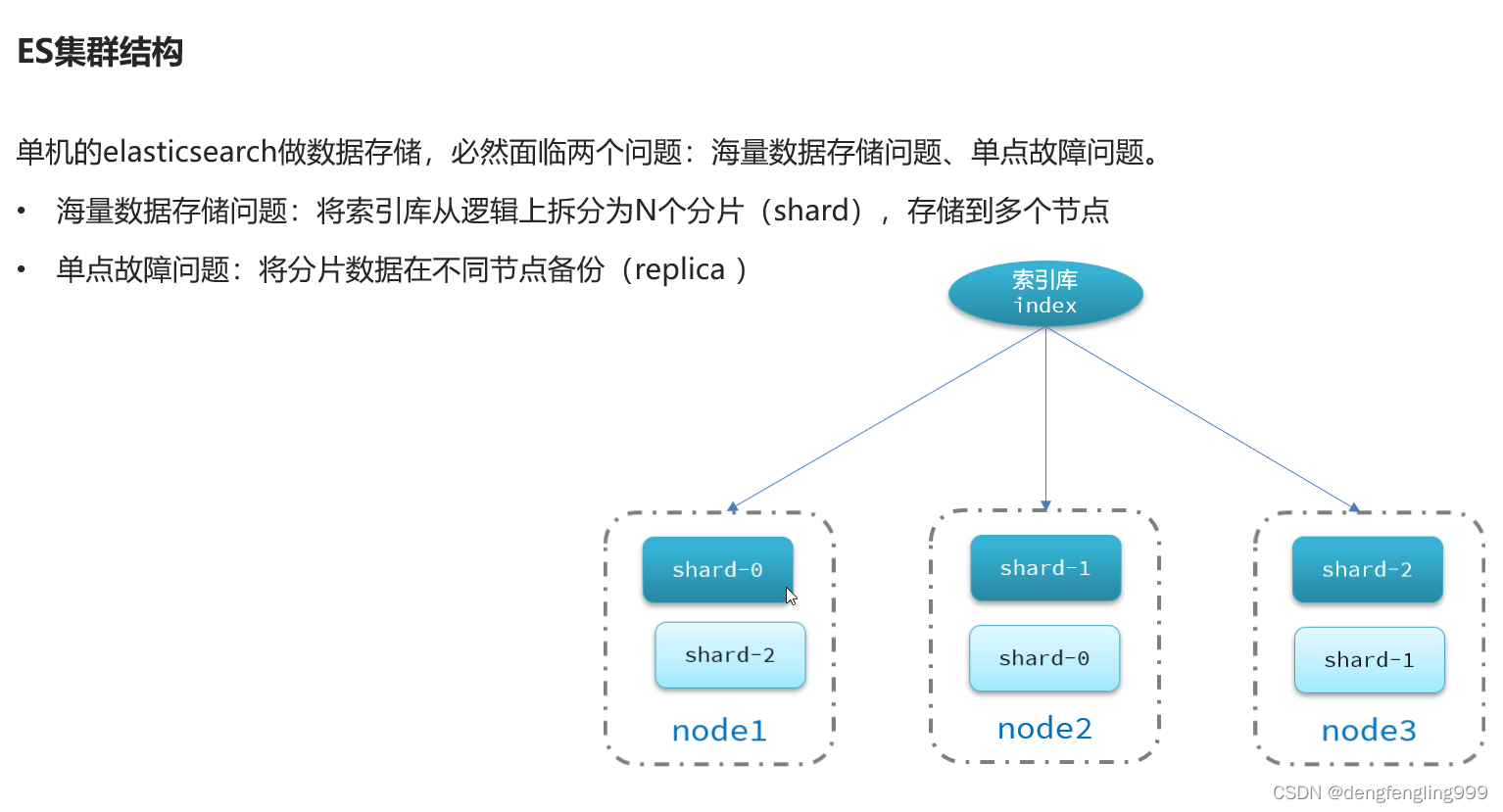
(2)es集群-搭建集群
 只有一台电脑, 用docker容器用来模拟节点,docker之间相互隔离,用来,模拟机器是没有问题的
只有一台电脑, 用docker容器用来模拟节点,docker之间相互隔离,用来,模拟机器是没有问题的

docker-compose文件是在一个文本文件里去描述多个容器的部署方式,从而形成将来一键部署,在这个compose文件里描述了我们要部署的三个ES节点的容器部署方案es01、es02、es03
image:镜像
container_name:容器的名称
node.name:节点名称,在ES中每个节点都要有一个节点名称,不能重复
cluster.name:是集群名称,ES是天生支持集群的,启动多台机器以后,怎样形成集群呢?只需要让他的集群名称一样就可以了,集群名称一样ES会自动把它们组装成一个集群
discovery.seed_hosts:集群中另外两个节点的ip地址,我们用的是docker容器,容器内互联可以直接用容器名互联
cluster.initial_master_nodes:初始化主节点,可以通过选举产生,配置的是哪个节点都可以参与选主
ES_JAVA_OPTS:JVM的内存大小
volumes:数据卷



version: '2.2'
services:
es01:
image: docker.elastic.co/elasticsearch/elasticsearch:7.12.1
container_name: es01
environment:
- node.name=es01
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es02,es03
- cluster.initial_master_nodes=es01,es02,es03
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- data01:/usr/share/elasticsearch/data
ports:
- 9200:9200
networks:
- elastic
es02:
image: docker.elastic.co/elasticsearch/elasticsearch:7.12.1
container_name: es02
environment:
- node.name=es02
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es03
- cluster.initial_master_nodes=es01,es02,es03
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- data02:/usr/share/elasticsearch/data
networks:
- elastic
es03:
image: docker.elastic.co/elasticsearch/elasticsearch:7.12.1
container_name: es03
environment:
- node.name=es03
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es02
- cluster.initial_master_nodes=es01,es02,es03
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- data03:/usr/share/elasticsearch/data
networks:
- elastic
volumes:
data01:
driver: local
data02:
driver: local
data03:
driver: local
networks:
elastic:
driver: bridge把准备好的文件上传到虚拟机里面:


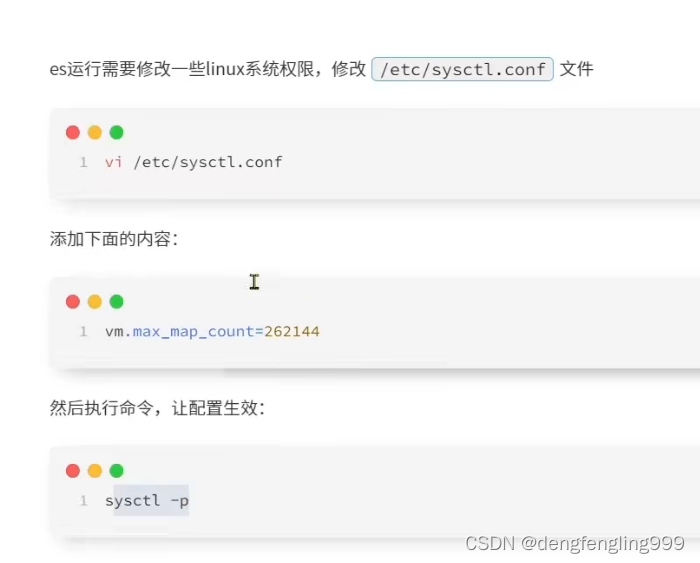

 有这个显示证明配置成功,虚拟机内存的大小就放开了ES就能正常个运行了
有这个显示证明配置成功,虚拟机内存的大小就放开了ES就能正常个运行了

运行:

查看启动状态:


分被查看节点日志,监控每个节点的运行状态

怎么去知道集群有没有运行成功呢?


解压文件:

双击运行:cerebro
通过浏览器访问: 输入一个节点地址:可以输入虚拟机上的任意一个节点的地址,这里访问es01节点,点击连接

进入:有一个绿色的条,表示集群的状态健康的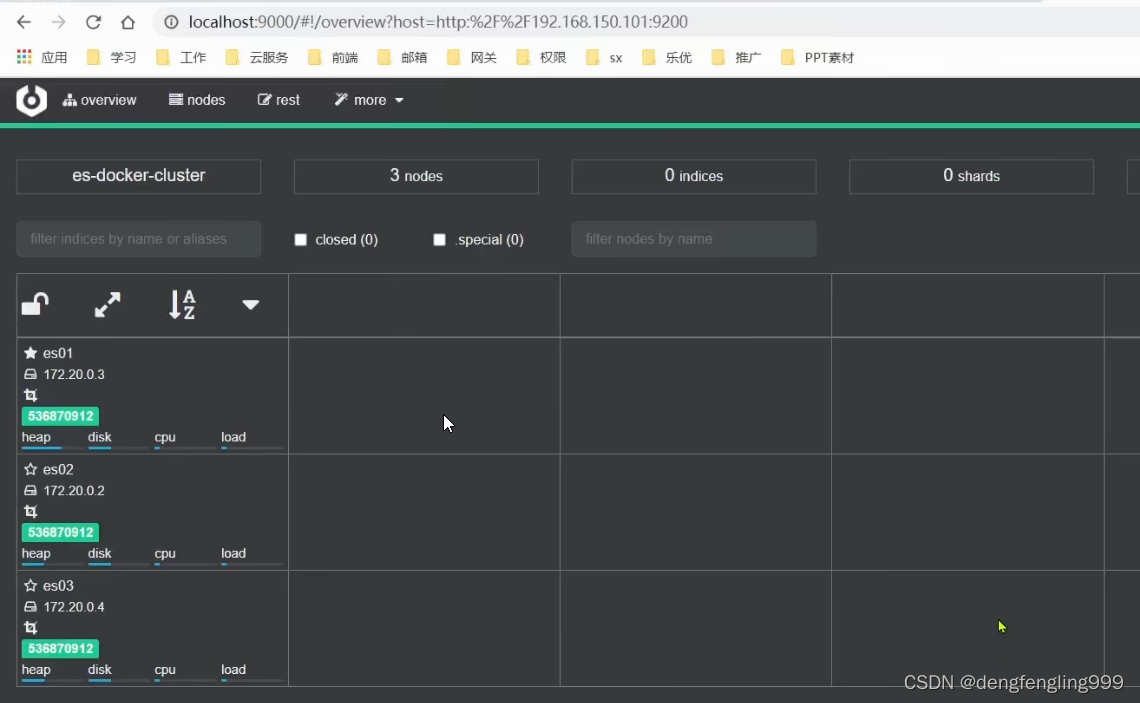
实心的星代表它是主节点
空心的星:候选节点,将来可以参与主节点的选举

我们需要把索引库进行分片, 在创建索引库的时候指定分片信息:

创建索引库:

点击右下角创建:

主页:显示创建的索引库,并进行了分片,实线框:0 1 2主分片 虚线框:副本分片
并且每个分片在不同的机器上,这样就确保了如果有任意一台机器宕机备份依然在保存的,避免出现数据故障

(3)es集群-集群职责及脑裂

nmaster eligible:备选主节点(候选主节点)可以参与选主 ,为了防止主节点挂了,候选主节点可以顶上去,做到高可用
ingest:预处理节点,可以度节点的预处理,比如插入一个文档到索引库里,插入之前呢ingest节点,可以对这个文档做预处理,加一个字段啊,删除一个字段啊,对某些字段的内容做修改,都可以由它来做 但是在准备文档是时候已经用java代码把文档处理好了,直接往索引库插入不需要预处理
corrindinating:协调节点 比如说有用户请求搜索数据,到达协调节点,它会把这个请求路由到真正处理的数据节点上去,数据节点处理完之后把结果返回,它在把结果合并,返回给用户,协调节点自己不需要去处理,只要路由一下,路由的时候还可以随机路由,还起到负载均衡的作用。这个节点就可以说是路由+负载均衡 然后合并结果
默认ES节点同时具备这四种角色,身兼数职,但是在实际开发过程中,不能让节点身兼数职,原因:不同的职责对硬件的需要是不一样的,主节点是管理集群的,不做数据处理,只需要对cpu有一定的要请就可以了。数据节点要求较高,需要磁盘大一点,对内存要求较高,对cpu也有要求。协调节点要求较低,对cpu要求一点,对磁盘没有要求
我们可以把角色分离,针对不同的角色,给它搭配不同的硬件,来减少成本,第二个因为他们之间的职责会产生影响,比如说数据节点跟主节点耦合在一起,数据子啊处理的时候会大量的占用CPU和内存,主节点的任务有可能就不能完成了,没办法去监管整个集群了出现主节点无法连接的情况
来降低他们之间的业务影响
因此一个典型的ES集群,它一定是把每个节点的职责,分离出去,不同的节点去干不同的事,怎样去控制节点的职责呢,在环境变量里去控制几个参数
默认情况下所有节点都是协调节点,可以控制一个节点只干协调,不干别的,把上面三个都调成false

有三个协调节点,N个数据节点(海量数据存储),3个候选节点(保证高可用)
还可以有一个负载均衡器,最协调节点做负载均衡比如说用nginx,用户请求来了,可以由不同的协调节点去接受,这样就提升了并发能力,协调节点,再把请求路由到数据节点,n个数据节点可以做海量数据存储,可以避免单点故障
这样的ES集群就是一个比较健壮的集群了,缺点是:搭建起来比较麻烦,往往会有一个脑裂的问题


脑裂:当出现网路阻塞node1节点是好的,但是导致node1和node2 node3连接不上了
node1根其他的部分数据节点还是能联通的
node1 node2根一些数据节点也是能联通的
这时候相当于集群被分开了一部分连node1,一部分连node2 node3 ,当node2 node3连不上node1的时候,会认为node1挂了,他两会选举成新的主节点,这个时候相当于集群中出现了两个主节点
一部分节点跟node1结合,有数据做增删改查的时候由node1来控制,还有一部分由node3来结合,数据做增删改查的时候由node3来控制,这两部分各自处理各自的集群,一旦网络恢复,用户在来访问的时候会出现数据不一致的情况,这就是脑裂问题,一个集群出现了两个主节点


(4)es集群-分布式新增和查询流程

测试插入数据:在9200端口,相当于集群的es01节点



查询:在9200查询


在9201查询:也查到这三条


那么这些数据到底存储到那个分片上呢?
添加一个命令:explain:true可以查看存储到那个分片上



我们明明是在9200上插入的,为什么在3个片上都有呢,说明协调节点确实工作了,它是怎么工作的呢?

存入的使用分片的数量运算存储,查询的时候使用分片的数量去运算那个分片查询 ,分片的数量一定不能更改了



(5) es集群-故障转移

当主节点挂掉之后,会重新选举,选出主节点,(此时的节点数据状态是不安全的,p-1没有副本分片,r-0没有主分片)0号片和0号片的数据是不安全的,因为只有一份一旦挂了就完了,此时寄集群的状态处于危险的边缘转态,主节点发现挂的节点 ,看一下上面有什么分片,然后把它迁移到健康的节点上面,确保任何一份分片都由两份,确保数据的安全

测试把01节点停掉:

使用docker命令:

颜色变了: 变黄了

不健康了因为0 1号片每有地方放了
需要经过一会等待:会进行数据迁移,把故障节点的数据迁移到正常的节点上了es02和es03上都由了3个片了,集群中每一个片都由2分满足了最低要求,集群又变成绿色了,这就是故障转移

那么数据有没有丢失呢?查询一下变没有丢失

如果重启es01:

控制台等待一下:es01恢复,此时他不是主节点了,此时主分片es03把分片又迁回去了,确保每个分片上都有数据,重新做了rebanlace,确保数据是均衡的

此时es01也能正常工作:






![[网鼎杯 2020 青龙组]AreUSerialz](https://img-blog.csdnimg.cn/99059d6e16cd4d1dad1bd32ef91d2fef.png)