mysql:索引的数据结构
什么是索引?
索引(Index)是帮助MySQL高效获取数据的数据结构
为什么学索引?
之前应该有概念说,把索引理解为目录,比如通过s就可以查询到s开头的汉子从哪也开始,到结束,这样快速定位。
索引需要记住哪些?
innodb的索引的数据结构使用的是b+树,那么我们就要知道b+数的数据结构
既然使用索引,那就一定会占用存储空间,当然索引不是越多越好。

B+树
b+数,我们要记住,所有的数据存在叶子节点上,每个数据页里面的数据是单链表的形式连接,数据页之间是双向链表,图上花得很清楚。
InnoDB要求表 必须有主键 ( MyISAM可以没有 )。如果没有显式指定,则MySQL系统会自动选择一个,可以非空且唯一标识数据记录的列作为主键。如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整型。
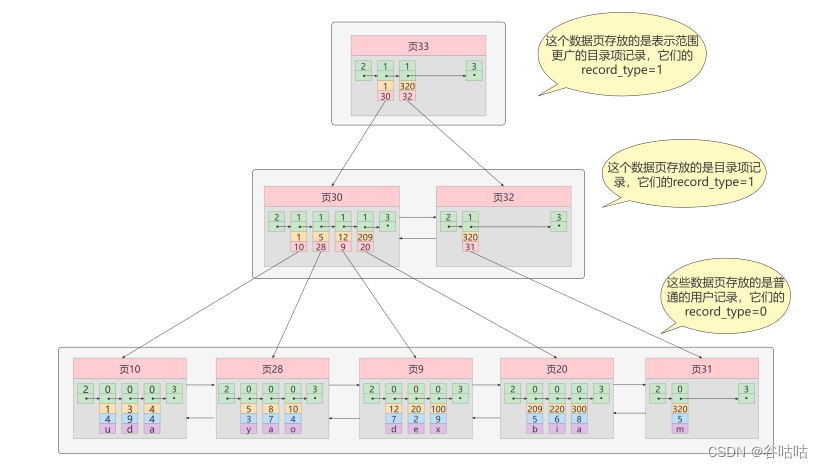
解释一下图,
最下面的是一个个数据,(1,4,‘u’)(3,9,‘d’),(4,4,‘a’),当然这个表就是3个字段。
可以看到第30页就有一个数据(1,10),其中10就是指向第10页,1就是这个页面中最小的值。
这样的话,例如你根据主键查,为20的数据,就会去从页33查,查到页33=》页30=》页9
这样的只有2次io,就是吧两个数据页加载到内存中,不需要把所有的叶子节点,加载到内存中。
为什么是2次io?因为根节点常驻内存。
聚簇索引和非聚簇索引(都是b+树的结构)这里比较抽象的话可以看尚硅谷康老师是的mysql第115-120
其实聚簇,非聚簇,就是看b+数中存储的是真的数据,还是主键。
因为非聚簇索引,查到最后的是主键值,还是要回表,做一次查询真正数据的操作。
聚簇索引,使用记录主键值的大小进行记录和页的排序
- 页内 的记录是按照主键的大小顺序排成一个 单向链表 。
- 各个存放 用户记录的页 也是根据页中用户记录的主键大小顺序排成一个 双向链表 。
- 存放 目录项记录的页 分为不同的层次,在同一层次中的页也是根据页中目录项记录的主键
大小顺序排成一个 双向链表 。
myisam
myisam都是非聚簇的,都是存放的地址,而不是真正的数据。
MyISAM索引文件和数据文件是 分离的 ,索引文件仅保存数
据记录的地址。
MySQL数据结构选择的合理性
上面聊了一下B+树
下面看看所有的数据结构
Hash结构
B树
多路平衡查找树
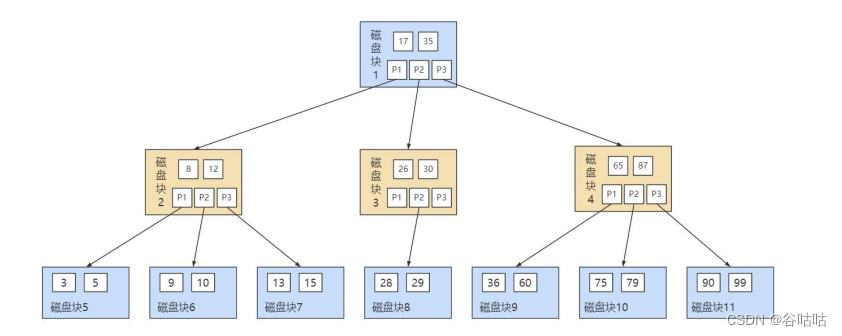
非叶子节点既保存索引,也保存数据记录
注意:
b+树比b树的查询更加稳定,
b+树的查询更快,因为在同样的磁盘空间下,b+树的根节点不存放实际数据,可以可以容纳更多的数据,树形更加广。
在范围查找上,b+树更快,因为b+树的叶子节点上的数据是顺序排序的,而b树因为根节点也存储数据,就要通过数的查询方式去找。
B+树的存储能力如何?为何说一般查找行记录,最多只需1~3次磁盘IO
一般指针为8B,主键值为8或4B,这样一个数据页16k可以存放1000个数据,那么深度为3的b+树就可以存放10亿个数据。
b+树的高度一般为2~4,但是根节点一般常驻内存,所以一般要1到3次io
hash和b+区别
hash是无序的但是b+树是有序的更适合范围查询。
hash不支持排序。
但是innodb引入了 自适应hash
![[网鼎杯 2020 青龙组]AreUSerialz](https://img-blog.csdnimg.cn/99059d6e16cd4d1dad1bd32ef91d2fef.png)