AUTOMATIC DIFFERENTIATION WITH torch.autograd
在训练神经网络时,最常用的算法是反向传播算法,在该算法中,参数根据损失函数相对于给定参数的梯度进行调整。
为了计算这些梯度, PyTorch 有一个内置的微分引擎 torch.autograd 。它智慧任何计算图的梯度自动计算。
考虑最简单的单层神经网络,输入 x, 参数 w 和 b, 以及一些损失函数。 它可以在 PyTorch 中以以下方式定义:
import torch
x = torch.ones(5) # 输入
y = torch.zeros(3) # 输出
w = torch.randn(5, 3, requires_grad=True) # 权重
b = torch.randn(3, requires_grad=True) # 偏置
z = torch.matmul(x, w) + b
loss = torch.nn.functional.binary_cross_entropy_with_logits(z, y)
print(f"loss = {loss}")
loss = 0.7214622497558594
Tensors, Functions and Computational graph
上述代码定义了以下计算图
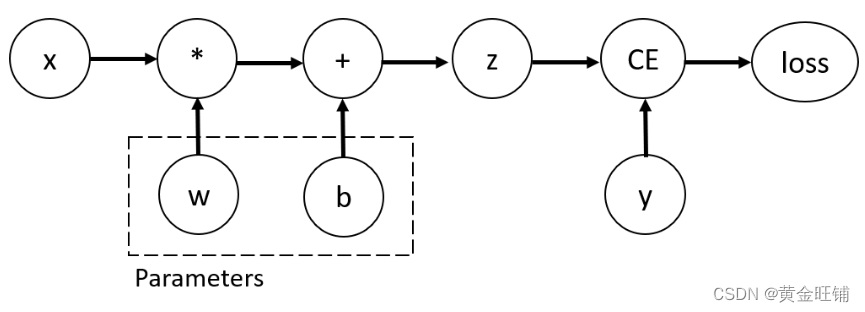
这个网络中,w 和 b 是需要优化的参数。因此,我们需要能够计算关于这些变量的损失函数的梯度。为了做到这一点,我们设置了这些 tensor 的 requires_grad 属性。
你可以在创建一个
tensor时设置requires_grad值,也可以在以后使用时利用x.requires_grad(True)方法。
应用于 tensor 来构建计算图的函数实际上 function 类的一个对象,该对象知道如何前向计算,也知道在反向传播时计算导数。反向传播的引用存储在 tensor 的 grad_fn 属性中。
print(f"Gradient function for z = {z.grad_fn}")
print(f"Gradient function for loss = {loss.grad_fn}")
Gradient function for z = <AddBackward0 object at 0x00000230B70C84F0>
Gradient function for loss = <BinaryCrossEntropyWithLogitsBackward object at 0x00000230B70C8D30>
Computing Gradients
为了计算神经网络的权重参数,我们需要计算 loss function 对参数的导数。即,我们需要在给定
x
x
x 和
y
y
y 计算
∂
l
o
s
s
∂
w
\frac{\partial loss }{\partial w}
∂w∂loss 和
∂
l
o
s
s
∂
b
\frac{\partial loss }{\partial b}
∂b∂loss 。为了计算这些导数,我们调用 loss.backward(), 然后从 w.grad 和 b.grad 提取值。
loss.backward()
print(w.grad)
print(b.grad)
tensor([[0.0494, 0.0666, 0.2772],
[0.0494, 0.0666, 0.2772],
[0.0494, 0.0666, 0.2772],
[0.0494, 0.0666, 0.2772],
[0.0494, 0.0666, 0.2772]])
tensor([0.0494, 0.0666, 0.2772])
我们只能获得计算图的叶节点的
grad属性,它们的requires_grad属性设置为True。对于图中的所有其他节点,梯度将不可用。
出于性能考虑,我们只能在给定的图上反向执行一次梯度计算。如果我们需要对同一个图执行多个反向调用,我们需要将retain_graph=True传递给反向调用。
Disabling Gradient Tracking (不跟踪梯度)
默认情况下,所有 requires_grad=True 的 tensor 都在跟踪它们的计算历史并支持梯度计算。然而,有些情况下我们不需要这样做,例如,当我们训练了模型,只想对输入数据进行计算,我们只需要通过网络进行 forward 计算。我们可以用 torch.no_grad() 停止跟踪梯度计算。
z = torch.matmul(x, w) + b
print(z.requires_grad)
with torch.no_grad():
z = torch.matmul(x, w) + b
print(z.requires_grad)
True
False
实现相同结果的另一种方法是在
tensor上使用detach()方法
z = torch.matmul(x, w) + b
z_det = z.detach()
print(z_det.requires_grad)
False
为什么要禁用梯度跟踪呢?
- 将神经网络中的一些参数标记为冻结参数,这是一个非常常见的场景finetuning a pretrained network
- 为了加速计算。因为在不跟踪梯度的 tensor 上计算会更有效。
More on Computational Graphs
从概念上讲,autograd 在一个由 Function 对象组成的有向无环图 ( DAG ) 中保存数据( tensors )和所有执行的操作( 以及由此产生的新张量 )的记录。在这个 DAG 中,叶子节点是输入 tensors ,根是输出 tensors 。通过从根到叶跟踪这个图,您可以使用链式法则自动计算梯度。
在向前传播中,autograd 同时做两件事:
- 根据要求的操作计算结果
tensor。 - 在
DAG中维护操作的梯度函数。
当在 DAG 根上调用 .backward() 时,后向传播开始,autograd 然后
- 从每个
.grad_fn中计算梯度; - 在各自的
tensor的.grad属性中累积它们 - 利用链式法则,一直传播到叶子
tensor。
PyTorch中的DAG是动态的,需要注意的一件重要的事情是,图是从头开始重新创建的,在每次.backward()调用之后,autograd开始填充一个新的图。 这正是允许您在模型中使用控制流语句的原因,如果需要,您可以在每次迭代中更改形状、大小和操作等。
Optional Reading: Tensor Gradients and Jacobian Products
在很多情况下,我们有一个标量损失函数,我们需要计算关于一些参数的梯度,然后,也有输出函数是任意 tensor 的情况,在这种情况下,PyTorch 允许你计算所谓的雅克比矩阵积,而不是实际的梯度。
对于一个向量函数
y → = f ( x → ) \overrightarrow{y} = f(\overrightarrow{x}) y=f(x) , 当 $ \overrightarrow{x}=<x_1,…x_n>$, y → = < y 1 , . . . y m > \overrightarrow{y}=<y_1,...y_m> y=<y1,...ym>, y → \overrightarrow{y} y 对 x → \overrightarrow{x} x 的导数可以利用 Jacobian matrix (雅克比矩阵):
J = ( ∂ y 1 ∂ x 1 ⋯ ∂ y 1 ∂ x n ⋮ ⋱ ⋮ ∂ y m ∂ x 1 ⋯ ∂ y m ∂ x n ) \begin{equation*} J = \begin{pmatrix} \frac{\partial y_1}{\partial x_1} & \cdots & \frac{\partial y_1}{\partial x_n} \\ \vdots & \ddots & \vdots \\ \frac{\partial y_m}{\partial x_1} & \cdots & \frac{\partial y_m}{\partial x_n} \\ \end{pmatrix} \end{equation*} J= ∂x1∂y1⋮∂x1∂ym⋯⋱⋯∂xn∂y1⋮∂xn∂ym
PyTorch 允许你在给定
v
=
(
v
1
,
.
.
.
v
m
)
v=(v_1,...v_m)
v=(v1,...vm) 向量时计算雅克比矩阵的点积
v
T
⋅
J
v^T \cdot J
vT⋅J, 而不是雅克比矩阵本身。可以通过 backward 以
v
v
v 作为参数而获得。
v
v
v 的大小应该与原始的 tensor 大小相同。
inp = torch.eye(4, 5, requires_grad=True)
out = (inp+1).pow(2).t()
out.backward(torch.ones_like(out), retain_graph=True)
print(f"First call\n{inp.grad}")
out.backward(torch.ones_like(out), retain_graph=True)
print(f"\nSecond call\n{inp.grad}")
inp.grad.zero_()
out.backward(torch.ones_like(out), retain_graph=True)
print(f"\nCall after zeroing gradients\n{inp.grad}")
First call
tensor([[4., 2., 2., 2., 2.],
[2., 4., 2., 2., 2.],
[2., 2., 4., 2., 2.],
[2., 2., 2., 4., 2.]])
Second call
tensor([[8., 4., 4., 4., 4.],
[4., 8., 4., 4., 4.],
[4., 4., 8., 4., 4.],
[4., 4., 4., 8., 4.]])
Call after zeroing gradients
tensor([[4., 2., 2., 2., 2.],
[2., 4., 2., 2., 2.],
[2., 2., 4., 2., 2.],
[2., 2., 2., 4., 2.]])
注意: 当我们用相同的参数第二次调用 backward() 时,梯度值是不同的。这是因为在进行反向传播时,PyTorch 会累积梯度,即计算梯度的值被添加到计算图的所有叶节点的 grad 属性中,如果逆向计算合适的梯度,你需要在之前讲梯度属性归零。在现实训练中,优化器可以帮助我们做到这一点。
以前我们调用 backward() 函数时不带参数。这本质上相当于调用 backward(torch.tensor(1.0)),这是一种有用的方法,可以在标量值函数的情况下计算梯度,例如神经网络训练期间的损失。
【参考】
Automatic Differentiation with torch.autograd — PyTorch Tutorials 1.13.1+cu117 documentation




![[网鼎杯 2020 青龙组]AreUSerialz](https://img-blog.csdnimg.cn/99059d6e16cd4d1dad1bd32ef91d2fef.png)