获取本文论文原文PDF,请在公众号【AI论文解读】留言:论文解读

摘要
本研究展示了利用人类偏好数据集来精细调整文本到图像生成模型的潜力,增强了生成图像与文本提示之间的一致性。尽管取得了进展,现有的人类偏好数据集要么构建成本过高,要么在偏好维度上缺乏多样性,限制了其在开源文本到图像生成模型指导调整中的应用,并阻碍了进一步的探索。为了应对这些挑战并通过指导调整促进生成模型的一致性,我们利用多模态大型语言模型创建了一个高质量、细粒度的偏好数据集 VisionPrefer,该数据集捕获了多个偏好方面。我们从AI注释者那里聚合了关于四个方面的反馈:遵循提示、美学、保真度和无害性,以构建 VisionPrefer。为了验证 VisionPrefer 的有效性,我们训练了一个奖励模型 VP-Score,通过 VisionPrefer 来指导文本到图像生成模型的训练,VP-Score 的偏好预测准确性与人类注释者相当。此外,我们使用了两种强化学习方法对生成模型进行了监督微调,以评估 VisionPrefer 的性能,广泛的实验结果表明,VisionPrefer 在多样化方面显著提高了文本图像一致性,例如美学,并且比以前的人类偏好度量在各种图像分布上具有更好的泛化性。此外,VisionPrefer 表明,将 AI 生成的合成数据作为监督信号的整合是实现视觉生成模型与人类偏好更好一致性的有前景的途径。
论文概览
1. 标题:Multimodal Large Language Model is a Human-Aligned Annotator for Text-to-Image Generation
2. 作者:Xun Wu, Shaohan Huang, Furu Wei
3. 机构:
- Microsoft Research Asia, Beijing, China
- Tsinghua University, Beijing, China
4. 论文链接:https://arxiv.org/pdf/2404.15100
引言:多模态大型语言模型在文本到图像生成中的新角色
随着人工智能技术的飞速发展,多模态大型语言模型(MLLMs)在文本到图像的生成领域扮演着越来越重要的角色。这些模型不仅能够理解和生成文本,还能够理解和生成与文本对应的图像,极大地推动了生成模型的发展。尤其是在与人类偏好对齐的文本到图像生成任务中,MLLMs展示出了其独特的优势。
传统的文本到图像生成模型,如Imagen和DALLE2,虽然能够生成高质量和具有创造性的图像,但它们在生成过程中往往忽略了与人类偏好的对齐。这些模型生成的图像可能与文本提示不够匹配,或者在某些情况下生成不当或不安全的内容。为了解决这些问题,研究者们开始探索使用人类偏好数据来微调这些生成模型,以提高它们的生成质量和安全性。
然而,收集和构建高质量的人类偏好数据集是一个既昂贵又耗时的过程,且容易受到偏见的影响。在这种背景下,MLLMs的出现为这一挑战提供了新的解决方案。通过利用MLLMs,研究者们可以自动生成大规模、高质量且细粒度的偏好数据集,这些数据集能够覆盖多个偏好维度,如图像的真实性、美观性和无害性等。
一个典型的例子是VisionPrefer数据集,它是一个公开可用的、由AI生成的偏好数据集,包含了120万个人类偏好选择,涵盖了179K对图像。这个数据集不仅规模庞大,而且在偏好的细粒度和反馈格式上都进行了精心设计。与现有的人类偏好数据集相比,VisionPrefer在可扩展性、细粒度注释和综合反馈格式方面具有明显优势。
基于VisionPrefer数据集,研究者们开发了VP-Score奖励模型,该模型在指导文本到图像生成模型的训练过程中,展现了与人类注释者相媲美的偏好预测准确性。此外,通过使用两种强化学习方法对生成模型进行微调,实验结果表明,VisionPrefer显著提高了文本图像对齐的质量,尤其是在图像的美观性方面。
总之,多模态大型语言模型作为人类对齐的注释者,在文本到图像生成领域展现出巨大的潜力和价值。它们不仅能够提高生成图像的质量和安全性,还能够通过生成高质量的偏好数据来推动相关研究的进展。这标志着AI在艺术和创意表达领域中,向着更加智能和人性化的方向迈进了一大步。

VisionPrefer数据集的创新介绍
1. 数据集构建的动机与目标
VisionPrefer数据集的构建动机源于现有文本到图像生成模型在生成过程中常常无法精确地反映人类的偏好,例如生成的图像可能会出现不符合文本描述的内容或者生成不安全的内容。此外,现有的人类偏好数据集构建成本高昂,且在偏好维度上缺乏多样性,这限制了其在开源文本到图像生成模型中的应用,并阻碍了进一步的探索。为了解决这些问题,VisionPrefer利用多模态大型语言模型(MLLMs),如GPT-4 Vision,来作为人类对齐的注释者,创建了一个高质量、细粒度的偏好数据集,该数据集能够捕捉模型生成图像的多个偏好方面。
2. VisionPrefer的详细构建过程
VisionPrefer的构建过程包括三个主要步骤:提示生成、图像生成和偏好生成。
- 提示生成:首先利用大规模文本到图像提示基准(如DiffusionDB)生成文本提示。为了确保提示的无偏性和安全性,使用GPT-4 Vision对这些提示进行了润色和NSFW过滤。
- 图像生成:根据生成的提示,使用不同的文本到图像生成模型生成图像。为了增加多样性,对每个提示生成多个图像,以便进行全面评估。
- 偏好生成:最后,使用GPT-4 Vision对生成的图像进行评分,生成标量分数、偏好排名和文本批评。这些反馈覆盖了四个不同的方面:遵循提示、美学、保真度和无害性。
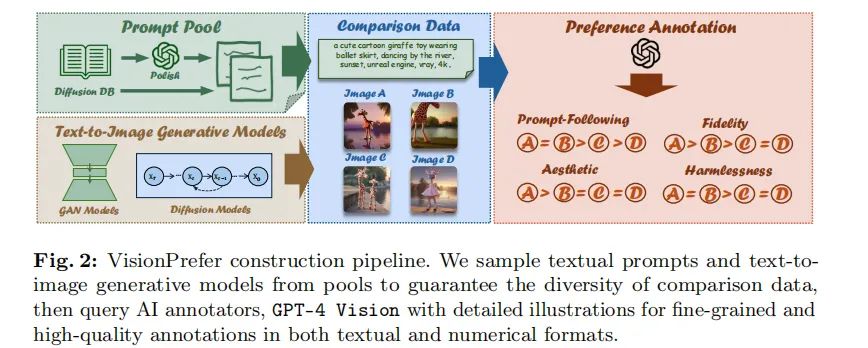

3. 数据集的规模与细粒度特征
VisionPrefer是迄今为止最大的文本到图像生成偏好数据集,包含1.2M个人类偏好选择,涵盖179K对图像。与现有的人类偏好基准相比,VisionPrefer不仅提供排名,还要求AI注释者分配数值偏好分数并为每个注释方面提供文本解释,这些方面包括遵循提示、美学、保真度和无害性。这种细粒度的反馈格式为文本到图像生成模型的训练提供了更丰富的信息,使得模型能够更好地与人类偏好对齐。
VP-Score奖励模型的开发与应用
1. 奖励模型的设计与训练
VP-Score奖励模型的开发基于VisionPrefer数据集,这是一个由多模态大型语言模型(MLLMs)生成的高质量、细粒度的人类偏好数据集。该数据集涵盖了1.2M的人类偏好选择,涉及179K对图像,覆盖了四个主要方面:遵循提示、美学、真实性和无害性。
在设计VP-Score时,我们采用了与ImageReward模型相同的结构,后者是一个开源的人类偏好奖励模型,使用BLIP作为骨干网络。我们将VisionPrefer中的偏好注释视为排名,采用平均分数作为最终偏好得分,并根据这些得分对图像进行排名。VP-Score的训练采用了对数损失函数,以优化模型对偏好的预测准确性。
2. 在现有人类偏好数据集上的表现分析
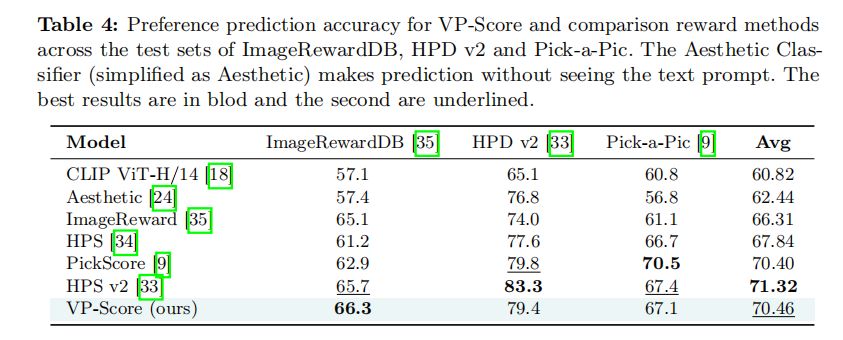
为了验证VP-Score的有效性,我们在几个现有的人类偏好数据集上进行了测试,包括ImageRewardDB、HPD v2和Pick-a-Pic。VP-Score在这些测试集上的表现与人类注释者相媲美,显示出与人类偏好的高度相关性。
具体来说,VP-Score在ImageRewardDB数据集上的表现优于HPS v2,这表明利用AI注释者提供的细粒度反馈可以有效地学习人类偏好奖励模型。此外,VP-Score在所有测试数据集上的平均表现位居第二,仅次于HPS v2,显示出其在多个偏好维度上的广泛适用性和强大的竞争力。
这些结果不仅证明了VP-Score模型的有效性,也展示了使用由MLLMs生成的偏好数据进行奖励模型训练的潜力,为未来的图像生成模型提供了新的调整方向和优化手段。
使用VisionPre
细粒度反馈的重要性与实际效果
1. 提升模型对提示的遵循性
细粒度反馈通过精确评估模型生成的图像与文本提示的一致性,显著提升了模型对提示的遵循性。例如,在使用VisionPrefer数据集进行训练的模型中,生成的图像更加准确地反映了文本提示的具体要求,如场景描述、对象属性等。这种对细节的关注使得生成的图像不仅在视觉上更加吸引人,而且在内容上也更加贴合用户的预期。
2. 提高生成图像的美观度与减少图像失真
通过对美观度和图像保真度的细粒度评估,AI模型能够在生成图像时更好地掌握色彩搭配、光影效果以及细节表现,从而显著提高图像的整体视觉效果。在实验中,使用VisionPrefer进行训练的模型在多个测试集上展示了优于传统模型的图像美观度,同时在图像的真实性方面也表现出较少的失真现象,这表明细粒度反馈在提升图像质量方面发挥了关键作用。
3. 增强图像的安全性
安全性是图像生成模型中一个不容忽视的方面,尤其是在生成可能直接面向公众的内容时。细粒度反馈通过对生成图像进行严格的安全性评估,有效地减少了生成内容中不适宜的元素,如暴力、色情或歧视性内容。在使用VisionPrefer数据集训练的模型中,生成的图像在安全性评估中的得分显著提高,NSFW(不适合在工作场合显示的内容)的比例大幅降低,这一点在公共媒体发布和品牌营销等领域尤为重要。
通过这些实际效果的展示,我们可以看到细粒度反馈在提升文本到图像生成模型的性能方面起到了至关重要的作用。这不仅提升了模型的实用性和用户体验,也为未来AI在艺术创作和多媒体内容生成领域的应用开辟了新的可能。
结论与未来方向:VisionPrefer的影响与潜在的研究扩展
VisionPrefer作为一个由多模态大型语言模型(MLLMs)生成的高质量偏好数据集,已经在文本到图像生成模型的校准中显示出显著的潜力。通过详细的实验和分析,我们可以看到VisionPrefer在提高生成模型与人类偏好对齐方面的有效性。以下是对VisionPrefer未来发展方向的一些思考和建议。
1. 扩展和深化数据集:尽管VisionPrefer已经是一个大规模的数据集,但在未来的工作中,我们可以进一步扩展数据集的规模和多样性。这包括增加更多的图像对,以及覆盖更广泛的文本提示和图像风格。此外,增加数据集中的细粒度标注,如情感倾向、文化背景等,也将使模型能更好地理解和生成符合特定需求的图像。
2. 提高模型的泛化能力:当前的VP-Score已经显示出与人类标注者相媲美的表现,但仍有进一步优化的空间。例如,可以通过集成更多种类的反馈和评价机制来提高模型的泛化能力。此外,探索不同模型架构和训练策略,如对抗性训练或元学习等,可能会进一步提高模型在未见过的文本提示或图像风格上的表现。
3. 利用文本解释数据:VisionPrefer不仅提供了图像的偏好评分,还包括了AI生成的文本解释。这些文本解释为理解模型偏好提供了额外的语境信息,但目前还未被充分利用。未来的研究可以探索如何结合这些文本解释来提升模型的解释能力和透明度,例如通过自然语言处理技术分析解释中的关键因素,或将其用于模型的决策过程中。
4. 探索新的应用场景:除了文本到图像的生成,VisionPrefer的方法和技术也可以应用到其他多模态任务中,如视频生成、音频合成等。此外,这些技术也可以用于提高AI系统的安全性和可靠性,例如通过更好的理解和预测潜在的有害内容。
5. 加强与人类反馈的结合:尽管VisionPrefer利用了MLLMs来生成偏好数据,人类的直观反馈仍然非常宝贵。未来的研究可以探索如何更有效地结合机器学习模型和人类标注者的优势,例如通过交互式学习或半监督学习等方式,使模型在学习过程中能够不断调整并优化其生成的内容。
通过上述方向的探索和实施,VisionPrefer及其相关技术有望在未来继续推动文本到图像生成领域,以及更广泛的AI领域的发展,实现更精准、更个性化、更符合人类期望的生成结果。
![[Algorithm][动态规划][简单多状态DP问题][买卖股票的最佳时机 III][买卖股票的最佳时机 Ⅳ]详细讲解](https://img-blog.csdnimg.cn/direct/b3a12acf506943bcb693463656f1ec9e.png)