文章目录
- DrissionPage爬虫库简介
- 1. 浏览器操控模式(类似于游戏中的后台模拟鼠标键盘)
- 2. 数据包收发模式(类似于游戏中的协议封包)
- 实战中学习
- 需求:爬取Gitee开源项目的标题与描述
- 解决方案1:用数据包方式获取
- 解决方案2:用操控浏览器方式获取
DrissionPage爬虫库简介
DrissionPage爬虫库提供了两种主要模式,分别为:
1. 浏览器操控模式(类似于游戏中的后台模拟鼠标键盘)
优点:
- 快速实现数据获取需求
- 相对简单易用
缺点:
- 执行效率较慢
- 可能存在不稳定性
2. 数据包收发模式(类似于游戏中的协议封包)
优点:
- 高效执行
- 可以绕过浏览器限制,自由获取数据
缺点:
- 需要耗费较多时间进行逆向分析
你可以单独使用其中一种模式,也可以交替使用两种模式。这正是我对它感兴趣的原因。有时候,我们只是想简单获取一些数据,而不愿花费时间分析数据包。关于如何安装DrissionPage库,这里直接跳过,请查阅作者网站的安装步骤。作者提供了详细的使用文档,但我觉得针对初学者的角度,有必要写一篇自己的学习总结。初学者需要根据自身的知识水平,制定适合自己的学习流程。通过实践,发现不熟悉的地方,再去学习。
实战中学习
需求:爬取Gitee开源项目的标题与描述
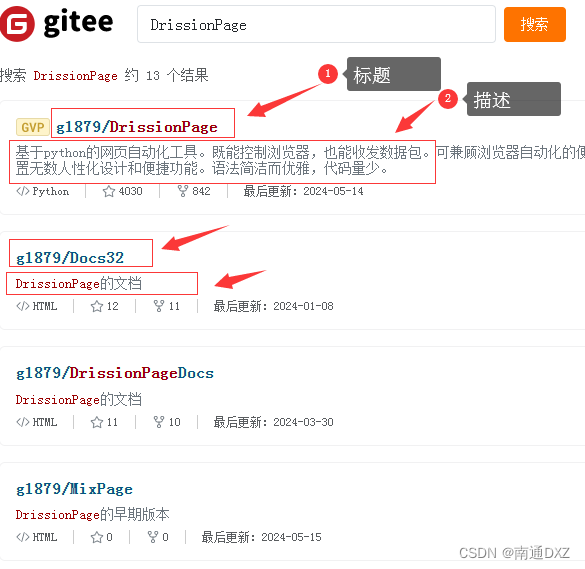
解决方案1:用数据包方式获取
F12分析数据包得出结论:
Get:
https://api.indexea.com/v1/search/widget/wjawvtmm7r5t25ms1u3d?query=1048&q=DrissionPage&from=0&size=20&sort_by_f=
Response:
{
"took": 0,
"hits": {
"total": {
"value": 13,
"relation": "eq"
},
"max_score": 185.50804,
"hits": [
{
"_index": 1027,
"_id": "9101163",
"_score": 185.50804,
"fields": {
"last_push_at": [
"2024-05-14 17:08:51"
],
"license": [
"BSD-3-Clause"
],
"fork": [
0
],
"count.fork": [
842
],
"description": [
"基于python的网页自动化工具。既能控制浏览器,也能收发数据包。可兼顾浏览器自动化的便利性和requests的高效率。功能强大,内置无数人性化设计和便捷功能。语法简洁而优雅,代码量少。"
],
"recomm": [
2
],
"langs": [
"Python"
],
"count.star": [
4030
],
"id": [
9101163
],
"title": [
"g1879/DrissionPage"
],
"url": [
"https://gitee.com/g1879/DrissionPage"
]
}
},
{
"_index": 1027,
"_id": "27108495",
"_score": 7.674755,
"fields": {
"last_push_at": [
"2024-01-08 20:34:25"
],
"fork": [
0
],
"count.fork": [
11
],
"description": [
"DrissionPage的文档"
],
"recomm": [
0
],
"langs": [
"HTML",
"JavaScript"
],
"count.star": [
12
],
"id": [
27108495
],
"title": [
"g1879/Docs32"
],
"url": [
"https://gitee.com/g1879/Docs32"
]
}
}
]
},
"suggest": {
"name": [
{
"text": "drissionpage",
"offset": 0,
"length": 12,
"options": []
}
]
},
"cache": 1716708583505,
"action": "20240526162838_cdffgkei6kksr7o69ezazp1vgh"
}
返回的 JSON 代码已进行了简化,去除了一些数组成员,但这不会影响我们的分析。由于之前对 Python 中的 JSON 解析语法一无所知,因此需要进行一次关于 JSON 解析的知识弥补,这将为下一篇文章提供基础:如何在 Python 中解析 JSON 数据。
直接上代码:
from DrissionPage import SessionPage
import json
# 创建页面对象
page = SessionPage()
page.get(f'https://api.indexea.com/v1/search/widget/wjawvtmm7r5t25ms1u3d?query=1048&q=DrissionPage&from=0&size=20&sort_by_f=')
data = page.json
hits = data['hits']['hits']
for hit in hits:
if 'title' in hit['fields']:
print(hit['fields']['title'][0])
if 'description' in hit['fields']:
print(hit['fields']['description'][0])
print()
解决方案2:用操控浏览器方式获取
代码:
from DrissionPage import WebPage
# 创建页面对象
page = WebPage()
# 访问网址
page.get('https://gitee.com/explore')
# 查找文本框元素并输入关键词
page('#q').input('DrissionPage')
# 点击搜索按钮
page('tag:button@class=ui orange button').click()
# 等待页面加载
page.wait.load_start()
# 获取所有行元素
items = page.eles('.card-body')
for item in items:
print(item.ele('.title').text)
print(item.ele('.col-12 outline text-secondary').text)
print()
最烦人的部分是元素的查找、操作和定位等操作,这启发了我写第三篇文章的想法:如何充分利用 DrissionPage 中的元素操控功能。









![C++进阶 | [4] map and set](https://img-blog.csdnimg.cn/direct/6638f7de97ce4e25ac4ab6a0bbfa765e.png)
