目录
- 克隆Github YOLO-Mamba源码
- YOLO-Mamba数据集格式
- 下载的公开数据集目录
- 边界框坐标文件
- 类别标签文件
- 数据集格式转换代码
- 转换格式的效果展示
今天为大家解析YOLO-Mamba这篇论文开源的代码,首先讲解YOLO格式数据集转换为YOLO-Mamba等特定工具指定的数据集格式的操作。

克隆Github YOLO-Mamba源码
git clone https://github.com/SwjtuMa/FER-YOLO-Mamba.git
YOLO-Mamba数据集格式
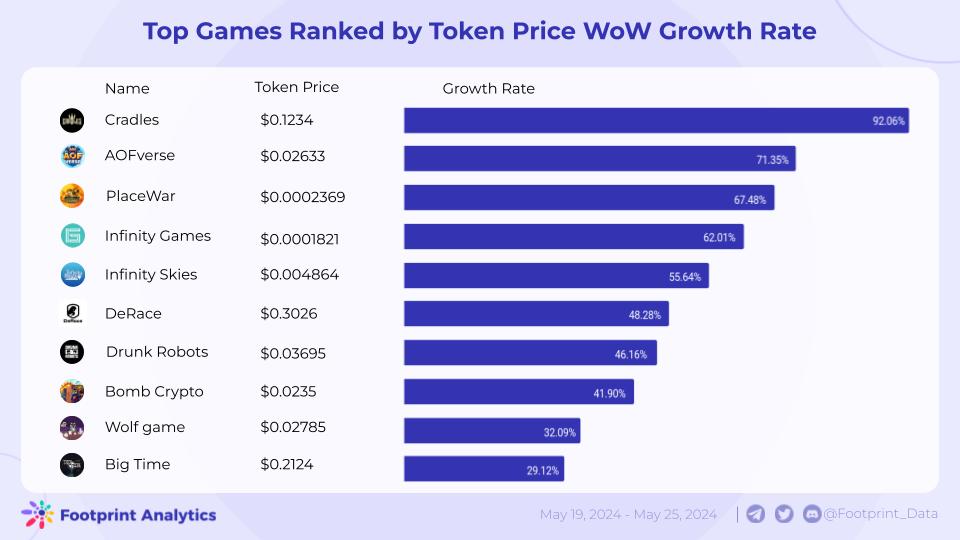
在FER_YOLO_Mamba/data/2007_val.txt中可以看到YOLO-Mamba接受的特定数据集格式
注意:相比源码最高级文件夹,我的文件夹修改为FER_YOLO_Mamba
/workspace/yolox/VOCdevkit/VOC2007/JPEGImages/Hangover_011409414_00000041.jpg 431,124,535,285,3
这种指定格式实际上不是标准的YOLO格式,而是更接近Pascal VOC或自定义的文本标注格式。这种格式通常包含图像文件的路径,以及每个目标物体的坐标和类别信息,但表达方式与YOLO格式有所不同。
- 图像路径:每行开始是图像的完整文件路径,例如
/workspace/yolox/VOCdevkit/VOC2007/JPEGImages/...jpg。 - 坐标信息:紧接着是一个由逗号分隔的坐标序列,通常表示目标框的左上角和右下角坐标(而非YOLO格式中的中心坐标和宽高比例)。例如,
431,124,535,285表示一个目标框左上角位于图像坐标(431, 124),右下角位于(535, 285)。 - 类别ID:坐标序列之后是一个整数,表示目标物体的类别ID。例如,
3表示第三个类别。
这种格式与标准YOLO格式的主要区别在于:
- 坐标表示:标准YOLO格式使用边界框的中心点坐标(归一化到图像尺寸的百分比)和宽高比例,而上述格式使用的是绝对像素坐标来直接表示边界框的左上角和右下角。
- 信息排列:YOLO格式每行数据包含一个物体的所有信息(类别ID+中心点坐标+宽高比例),而上述格式首先是图像路径,随后是每个物体的坐标和类别ID,没有直接体现中心点坐标和宽高比例的归一化信息。
这种格式是为了适应例如YOLO-mamba的特定处理流程或工具,比如某些数据集处理脚本或自定义的数据加载器,它不一定遵循YOLO算法的标准输入格式。
下载的公开数据集目录
以下是我从Kaggle官网下载的一个RAF-DB表情识别数据集目录
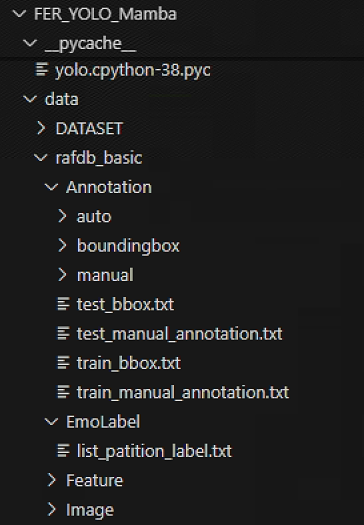
在bbox坐标文件FER_YOLO_Mamba/data/rafdb_basic/Annotation/boundingbox/test_0001_boundingbox.txt中
153.841080 130.382935 327.412231 355.140106
在类别标签文件FER_YOLO_Mamba/data/rafdb_basic/EmoLabel/list_patition_label.txt中
train_12267.jpg 7
train_12268.jpg 7
train_12269.jpg 7
train_12270.jpg 7
train_12271.jpg 7
test_0001.jpg 5
test_0002.jpg 1
test_0003.jpg 4
test_0004.jpg 1
YOLO(You Only Look Once)是一种广泛使用的实时目标检测算法,它的数据标注格式简洁明了,主要用来指示图像中目标物体的位置和类别。在上述例子中,涉及到两个文件:一个是边界框坐标文件,另一个是类别标签文件。下面我将分别解释这两个文件的内容和格式。
边界框坐标文件
在YOLO格式中,每个目标物体的边界框坐标信息通常按照以下格式存储在一个文本文件中,每行代表一个目标物体的信息,具体到上述例子:
153.841080 130.382935 327.412231 355.140106
这四个数字分别代表:
- 第一个和第二个数字是边界框的中心点坐标相对于图像宽度和高度的归一化值。即
x_center, y_center。在这个例子中,中心点坐标为(153.841080, 130.382935),这些值通常范围在0到1之间,表示相对于图像宽度和高度的比例位置。 - 第三个和第四个数字是边界框的宽度和高度相对于图像尺寸的归一化值。即
width, height。这里边界框的宽度为327.412231 - 153.841080,高度为355.140106 - 130.382935的比例,同样也是归一化的。
类别标签文件
这个文件每一行对应一张图像及其对应的类别标签,格式为:
image_filename.jpg category_id
例如:
test_0001.jpg 5
这意味着文件名为 test_0001.jpg 的图像被标记为类别ID为5的情感表情。类别ID是整数,对应于特定的情感分类,如高兴、悲伤、愤怒等。在实际应用中,通常会有一个类别ID与实际情感名称的映射表,以解释每个ID所代表的情感。
结合上述两个文件,可以理解为在图像test_0001.jpg中有一个目标物体,其边界框信息由boundingbox/test_0001_boundingbox.txt文件提供,且该目标物体表达的情感类别为ID为5的情感(具体情感需参照类别ID映射表)。这种格式使得YOLO算法能够直接读取并理解图像中的目标及其类别信息,进而进行目标检测和分类。
数据集格式转换代码
import os
def load_class_labels(label_file_path):
"""
加载类别标签文件,返回一个字典,键为图像ID,值为类别ID。
"""
labels_dict = {}
with open(label_file_path, 'r') as label_file:
for line in label_file:
img_id, class_id = line.strip().split()
labels_dict[os.path.splitext(img_id)[0]] = int(class_id) # 去除文件扩展名,确保与img_id匹配
return labels_dict
def separate_and_merge_yolo_txts(input_folder, label_file_path, train_output, test_output):
"""
将带有'train_'和'test_'前缀的YOLO格式标签文件分别合并到训练集和测试集的输出文件中,并整合类别标签。
:param input_folder: 包含所有单个txt标签文件的目录
:param label_file_path: 类别标签文件路径
:param train_output: 训练集合并后的输出文件路径
:param test_output: 测试集合并后的输出文件路径
"""
class_labels = load_class_labels(label_file_path)
train_file = open(train_output, 'w')
test_file = open(test_output, 'w')
for txt_file in os.listdir(input_folder):
if txt_file.endswith('.txt'):
img_id = os.path.splitext(os.path.splitext(txt_file)[0])[0].replace("_boundingbox", "")
prefix = img_id.split('_')[0]
txt_path = os.path.join(input_folder, txt_file)
with open(txt_path, 'r') as infile:
# 读取并转换坐标为整数
float_strings = infile.read().split()
int_values = list(map(int, map(float, float_strings)))
str_value = ' '.join(map(str, int_values))
# 获取并添加类别ID
class_id = class_labels.get(img_id)
if class_id is None:
print(f"Warning: No class label found for {img_id}. Skipping.")
continue
# 写入相应文件
if prefix == 'train':
train_file.write("FER_YOLO_Mamba/data/rafdb_basic/Image/original/" + f"{img_id}.jpg {str_value} {class_id}\n")
elif prefix == 'test':
test_file.write("FER_YOLO_Mamba/data/rafdb_basic/Image/original/" + f"{img_id}.jpg {str_value} {class_id}\n")
train_file.close()
test_file.close()
# 使用示例
input_folder = 'FER_YOLO_Mamba/data/rafdb_basic/Annotation/boundingbox'
label_file_path = 'FER_YOLO_Mamba/data/rafdb_basic/EmoLabel/list_patition_label.txt'
train_annotation = 'FER_YOLO_Mamba/data/rafdb_basic/Annotation/train_bbox.txt'
test_annotation = 'FER_YOLO_Mamba/data/rafdb_basic/Annotation/test_bbox.txt'
separate_and_merge_yolo_txts(input_folder, label_file_path, train_annotation, test_annotation)
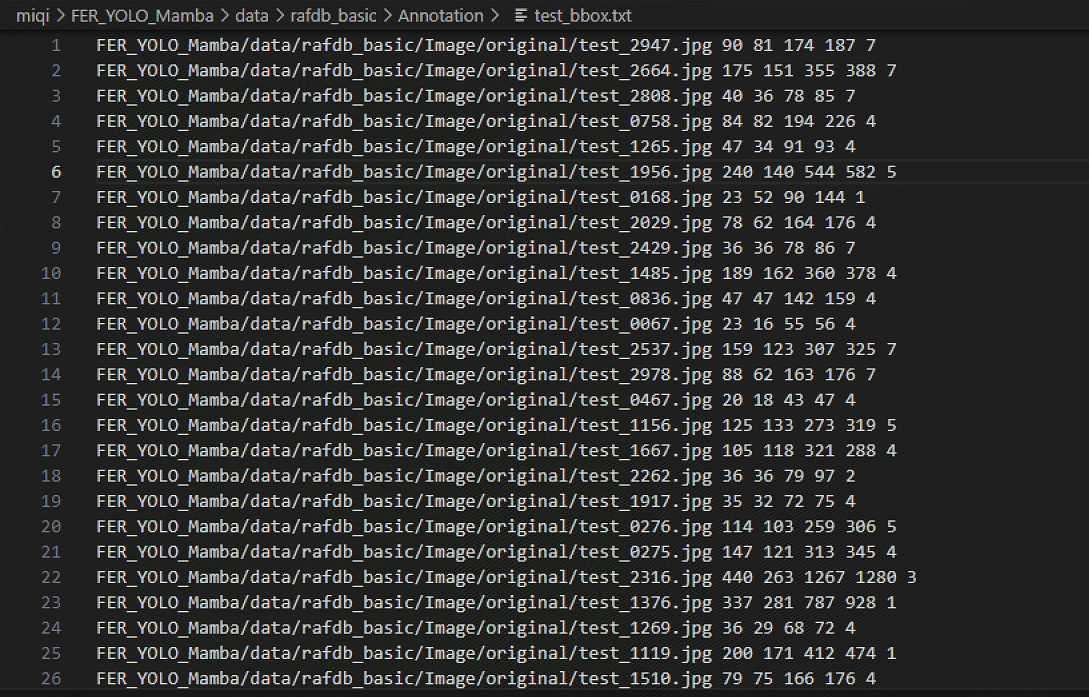
转换格式的效果展示
![[笔试强训day09]](https://img-blog.csdnimg.cn/direct/0efe72fbad0b476f8474d15793cb0ca7.png)