原理
一个数据库由很多表的构成,每个表对应的不同的业务,垂直切分是指按照业务将表进行分类,分不到不同的数据库上,这样压力就分担到了不同的库上面。
数据分片
数据分片包括里:垂直分片和水平分片,垂直分片包括:垂直分库和垂直分表,水平分片包括: 水平分库和水平分表。
垂直分片
垂直分库
数据库中不同的表对应着不同的业务,垂直切分是指按照业务的不同将表进行分类,分布到不同的数据库上面;
将数据库部署在不同服务器上,从而达到多个服务器共同分摊压力的效果
垂直分表
表中字段太多且包含大字段的时候,在查询时对数据库的IO、内存会受到影响,同时更新数据时,产生的binlog文件会很大,MySQL在主从同步时也会有延迟的风险。
将⼀个表按照字段分成多表,每个表存储其中⼀部分字段。
对职位表进⾏垂直拆分, 将职位基本信息放在⼀张表, 将职位描述信息存放在另⼀张表

好处
- 解决业务层面的耦合,业务清晰
- 能对不同业务的数据进行分级管理、维护、监控、扩展等
- 高并发场景下,垂直分库⼀定程度的提高访问性能
- 垂直拆分没有彻底解决单表数据量过大的问题
水平分片
水平分库
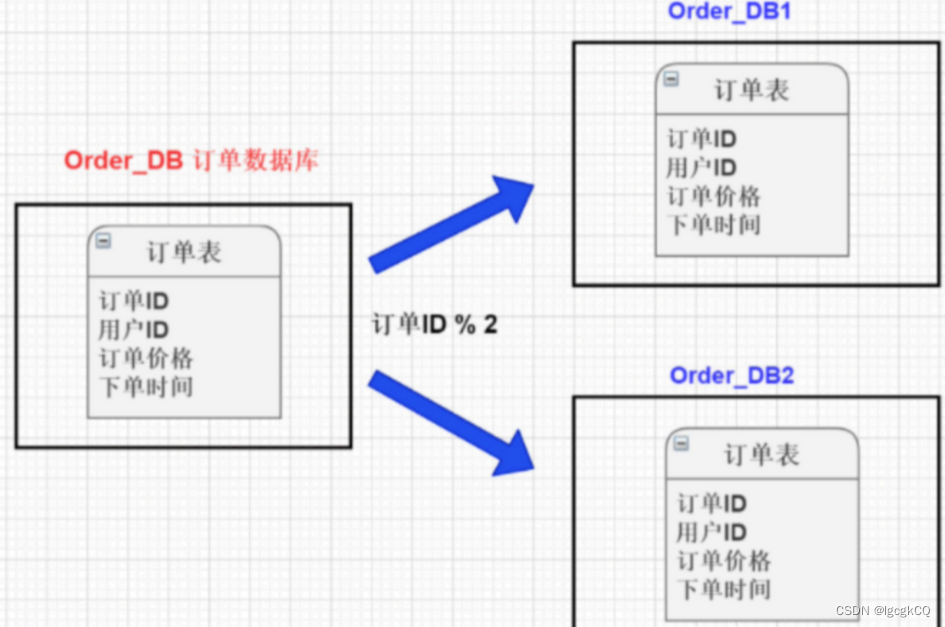
将单张表的数据切分到多个服务器上去,每个服务器具有相应的库表,只是表中数据集合不同。 水平分库分表能够有效的缓解单机和单库的性能瓶颈和压力,突破IO、连接数、硬件资源等的瓶颈。
水平分表
针对数据量巨大的单张表(比如订单表),按照规则把⼀张表的数据切分到多张表里面去。 但是这些表还是在同⼀个库中,所以库级别的数据库操作还是有IO瓶颈。

总结
垂直分表: 将⼀个表按照字段分成多表,每个表存储其中⼀部分字段。
垂直分库: 根据表的业务不同,分别存放在不同的库中,这些库分别部署在不同的服务器.
水平分库: 把⼀张表的数据按照⼀定规则,分配到不同的数据库,每⼀个库只有这张表的部分数据.
水平分表: 把⼀张表的数据按照⼀定规则,分配到同⼀个数据库的多张表中,每个表只有这个表的部分数据。
分库分表
按照⼀定规则把数据库中的表拆分为多个带有数据库实例,物理库,物理表访问路径的分表。

实现
1.添加数据库、存储数据源
/*+ mycat:createDataSource{
"name":"dw0",
"url":"jdbc:mysql://192.168.140.100:3306", "user":"root",
"password":"123123"
} */;
/*+ mycat:createDataSource{
"name":"dr0", "url":"jdbc:mysql://192.168.140.100:3306", "user":"root",
"password":"123123"
} */;
/*+ mycat:createDataSource{ "name":"dw1", "url":"jdbc:mysql://192.168.140.99:3306", "user":"root",
"password":"123123"
} */;
/*+ mycat:createDataSource{ "name":"dr1", "url":"jdbc:mysql://192.168.140.99:3306", "user":"root",
"password":"123123"
} */;
#通过注释命名添加数据源后,在对应目录会生成相关配置文件 cd /usr/local/mycat/conf/datasources
如下图:

2.添加集群配置
把新添加的数据源配置成集群
#//在 mycat 终端输入
/*! mycat:createCluster{"name":"c0","masters":["dw0"],"replicas":["dr0"]} */;
/*! mycat:createCluster{"name":"c1","masters":["dw1"],"replicas":["dr1"]} */;
#可以查看集群配置信息
cd /usr/local/mycat/conf/clusters
如下图:

3.创建全局表
#添加数据库db1 CREATE DATABASE db1;
#在建表语句中加上关键字 BROADCAST(广播,即为全局表) CREATE TABLE db1.`travelrecord` (
`id` bigint NOT NULL AUTO_INCREMENT, `user_id` varchar(100) DEFAULT NULL, `traveldate` date DEFAULT NULL, `fee` decimal(10,0) DEFAULT NULL, `days` int DEFAULT NULL,
`blob` longblob,
PRIMARY KEY (`id`),
KEY `id` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 BROADCAST; #进入相关目录查看 schema 配置
vim /usr/local/mycat/conf/schemas/db1.schema.json #可以看到自动生成的全局表配置信息

4.创建分片表(分库分表)
#在 Mycat 终端直接运行建表语句进行数据分片 CREATE TABLE db1.orders(
id BIGINT NOT NULL AUTO_INCREMENT, order_type INT,
customer_id INT,
amount DECIMAL(10,2),
PRIMARY KEY(id),
KEY `id` (`id`)
)ENGINE=INNODB DEFAULT CHARSET=utf8
dbpartition BY mod_hash(customer_id) tbpartition BY mod_hash(customer_id) tbpartitions 1 dbpartitions 2;
#数据库分片规则,表分片规则,以及各分多少片
INSERT INTO orders(id,order_type,customer_id,amount)
VALUES(1,101,100,100100);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES(2,101,100,100300);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES(3,101,101,120000);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES(4,101,101,103000);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES(5,102,101,100400);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES(6,102,100,100020);
SELECT * FROM orders;
#同样可以查看生成的配置信息
#进入相关目录查看 schema 配置
vim /usr/local/mycat/conf/schemas/db1.schema.json



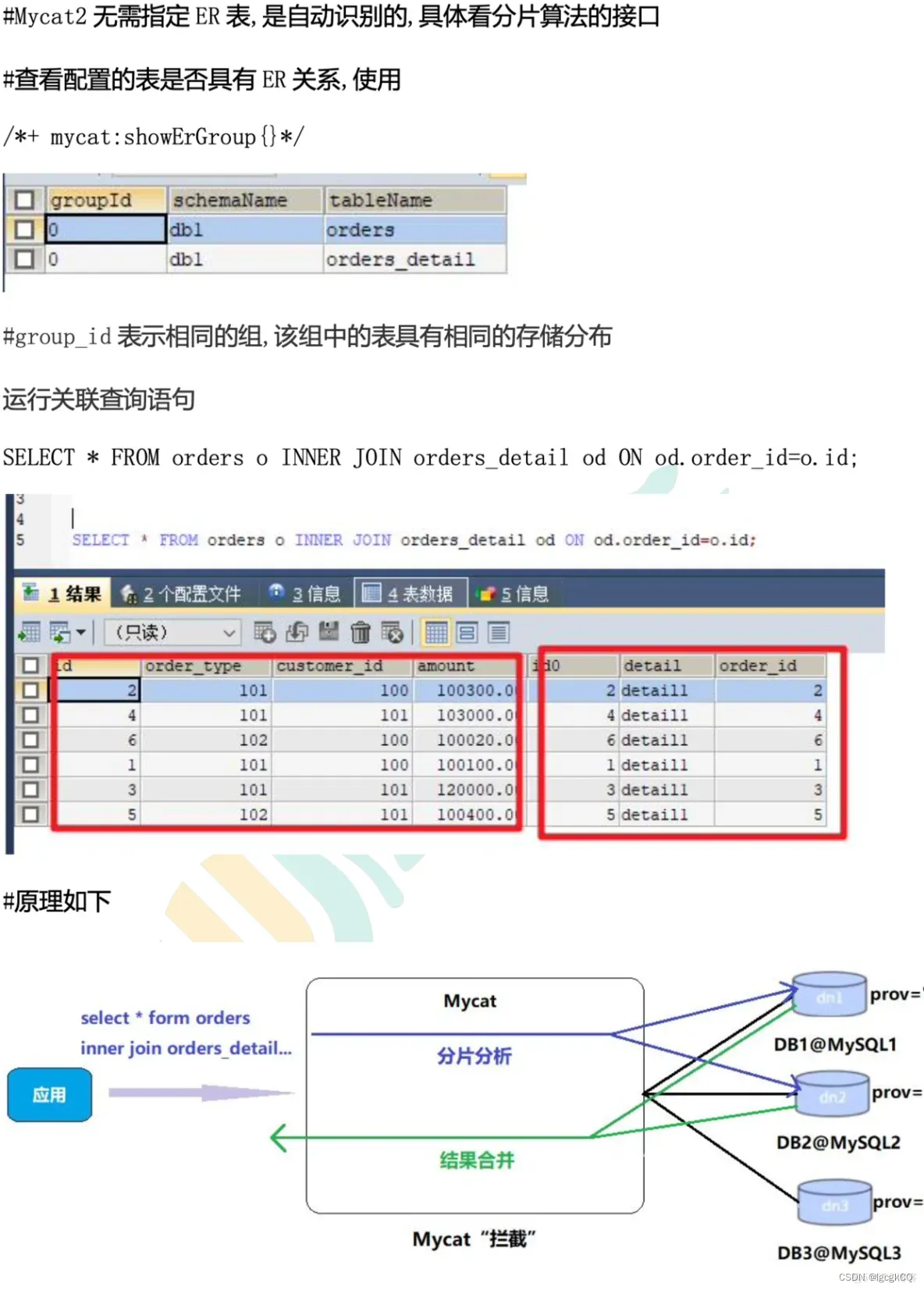
5.创建ER表


上述两表具有相同的分片算法,但是分片字段不相同 Mycat2 在涉及这两个表的 join 分片字段等价关系的时候可以完成 join 的下推
常用分片规则

MOD_HASH
如果分片值是字符串则先对字符串进行hash转换为数值类型
分库键和分表键是同键
分表下标=分片值%(分库数量*分表数量)
分库下标=分表下标/分表数量
分库键和分表键是不同键
分表下标= 分表分片值%分表数量
分库下标= 分库分片值%分库数量
create table travelrecord (
....
) ENGINE=InnoDB DEFAULT CHARSET=utf8
dbpartition by MOD_HASH (id) dbpartitions 6
tbpartition by MOD_HASH (id) tbpartitions 6;create table travelrecord (
....
) ENGINE=InnoDB DEFAULT CHARSET=utf8
dbpartition by MOD_HASH (id) dbpartitions 6
tbpartition by MOD_HASH (id) tbpartitions 6;
RANGE_HASH
RANGE_HASH(字段1, 字段2, 截取开始下标)
仅支持数值类型,字符串类型
当时字符串类型时候,第三个参数生效
计算时候优先选择第一个字段,找不到选择第二个字段
如果是字符串则根据下标截取其后部分字符串,然后该字符串hash成数值
根据数值按分片数取余
要求截取下标不能少于实际值的长度
两个字段的数值类型要求一致
create table travelrecord(
...
)ENGINE=InnoDB DEFAULT CHARSET=utf8
dbpartition by RANGE_HASH(id,user_id,3) dbpartitions 3
tbpartition by RANGE_HASH(id,user_id,3) tbpartitions 3;
RIGHT_SHIFT
RIGHT_SHIFT(字段名,位移数)
仅支持数值类型
分片值右移二进制位数,然后按分片数量取余
create table travelrecord(
...
)ENGINE=InnoDB DEFAULT CHARSET=utf8
dbpartition by RIGHT_SHIFT(id,4) dbpartitions 3
tbpartition by RIGHT_SHIFT(user_id,4) tbpartitions 3;
UNI_HASH
如果分片值是字符串则先对字符串进行hash转换为数值类型
分库键和分表键是同键
分库下标=分片值%分库数量
分表下标=(分片值%分库数量)*分表数量+(分片值/分库数量)%分表数量
分库键和分表键是不同键
分表下标= 分片值%分表数量
分库下标=分片值%分库数量
create table travelrecord (
....
) ENGINE=InnoDB DEFAULT CHARSET=utf8
dbpartition by UNI_HASH (id) dbpartitions 6
tbpartition by UNI_HASH (id) tbpartitions 6;
WEEK
仅用于分表
仅DATE/DATETIME
一周之中的星期(1-7)进行取余运算
tbpartitions不超过7
create table travelrecord (
....
) ENGINE=InnoDB DEFAULT CHARSET=utf8
dbpartition by xxx(xx) dbpartitions 8
tbpartition by WEEK(xx) tbpartitions 7;
YYYYDD
仅用于分库
DD是一年之中的天数
(YYYY*366+DD)%分库数
create table travelrecord (
....
) ENGINE=InnoDB DEFAULT CHARSET=utf8
dbpartition by YYYYDD(xxx) dbpartitions 8
tbpartition by xxx(xxx) tbpartitions 12;
YYYYMM
仅用于分库:(YYYY*12+MM)%分库数.MM是1-12
create table travelrecord (
....
) ENGINE=InnoDB DEFAULT CHARSET=utf8
dbpartition by YYYYMM(xxx) dbpartitions 8
tbpartition by xxx(xx) tbpartitions 12;
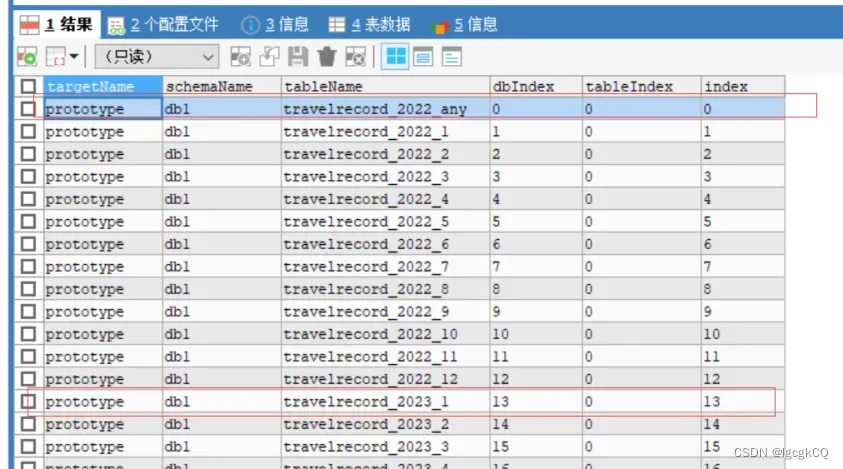
"travelrecord":{
"createTableSQL":"CREATE TABLE db1.travelrecord (\n\t`id` bigint(22) NOT NULL\n) ENGINE = InnoDB CHARSET = utf8\nDBPARTITION BY YYYYMM(id) DBPARTITIONS 12",
"function":{
"properties":{
"dbNum":"36",
"mappingFormat":"prototype/db1/travelrecord_${ 2022+(index.toInteger()-1).intdiv(12) }_${ if(index.toInteger()==0)return 'any'; var i= (index.toInteger()).mod(12); if(i==0)return '12'; return i; }","storeNum":1,
"dbMethod":"YYYYMM(id)"
}
},
"shardingIndexTables":{}
}
DD
仅用于分表
仅DATE/DATETIME
一月中的第几天(1-31)%分表数
tbpartitions不能超过31
create table travelrecord (
....
) ENGINE=InnoDB DEFAULT CHARSET=utf8
dbpartition by xxx(xx) dbpartitions 8
tbpartition by DD(xx) tbpartitions 31;
YYYYWEEK
支持分库分表
(YYYY*54+WEEK)%分片数
WEEK的范围是1-53
java.time.temporal.WeekFields#weekOfWeekBasedYear
create table travelrecord (
....
) ENGINE=InnoDB DEFAULT CHARSET=utf8
dbpartition by YYYYWEEK(xx) dbpartitions 8
tbpartition by xxx(xx) tbpartitions 12;
MM
仅用于分表
仅支持DATE/DATETIME
月份(1-12)%分表数
tbpartitions不超过12
create table travelrecord (
....
) ENGINE=InnoDB DEFAULT CHARSET=utf8
dbpartition by xxx(xxx) dbpartitions 12
tbpartition by MM(xxx) tbpartitions 12;
MMDD
仅用于分表
仅DATE/DATETIME
一年之中第几天%分表数
tbpartitions不超过366
create table travelrecord (
....
) ENGINE=InnoDB DEFAULT CHARSET=utf8
dbpartition by xxx(xx) dbpartitions 8
tbpartition by MMDD(xx) tbpartitions 366;