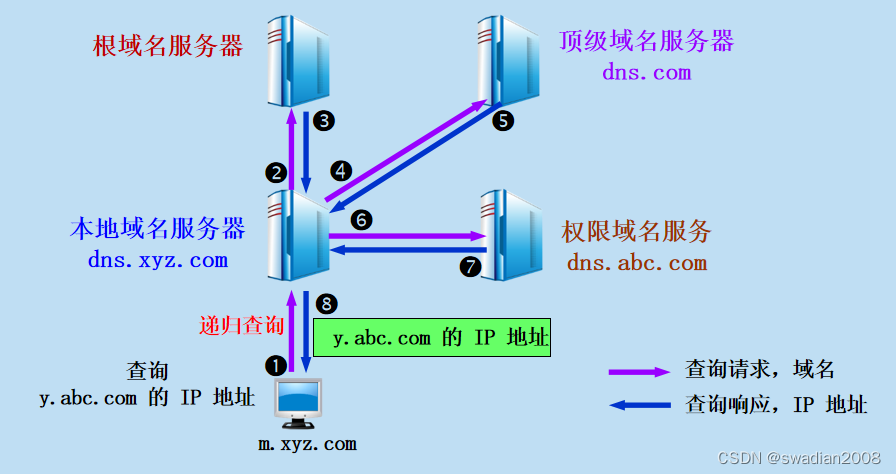
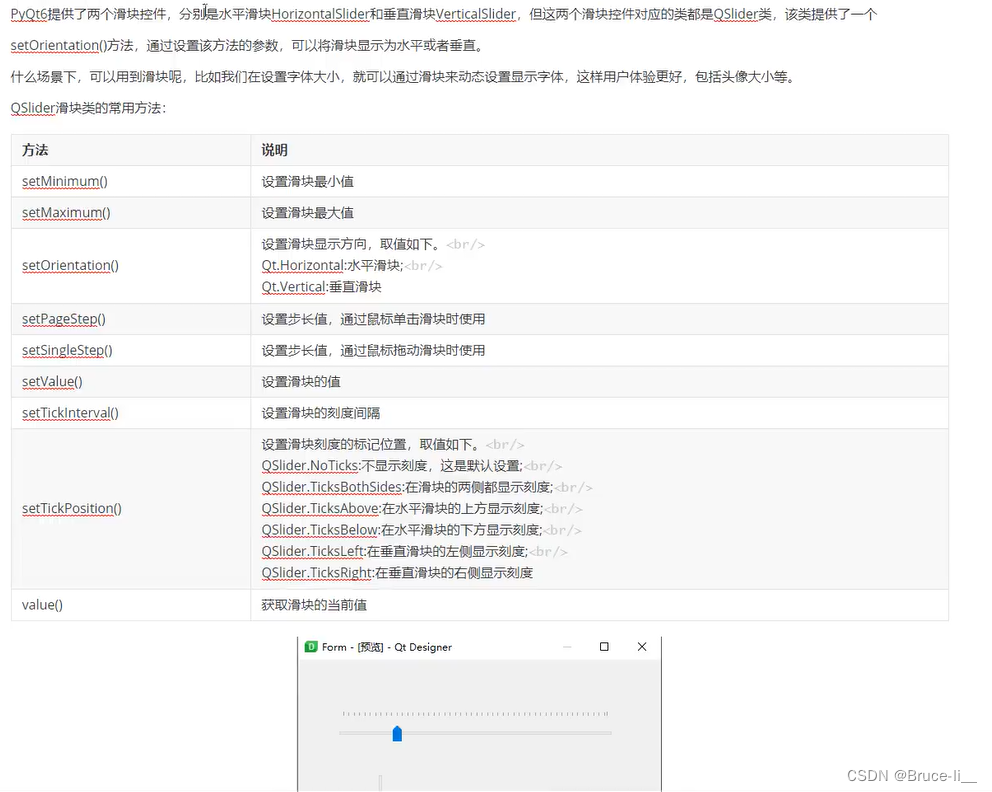
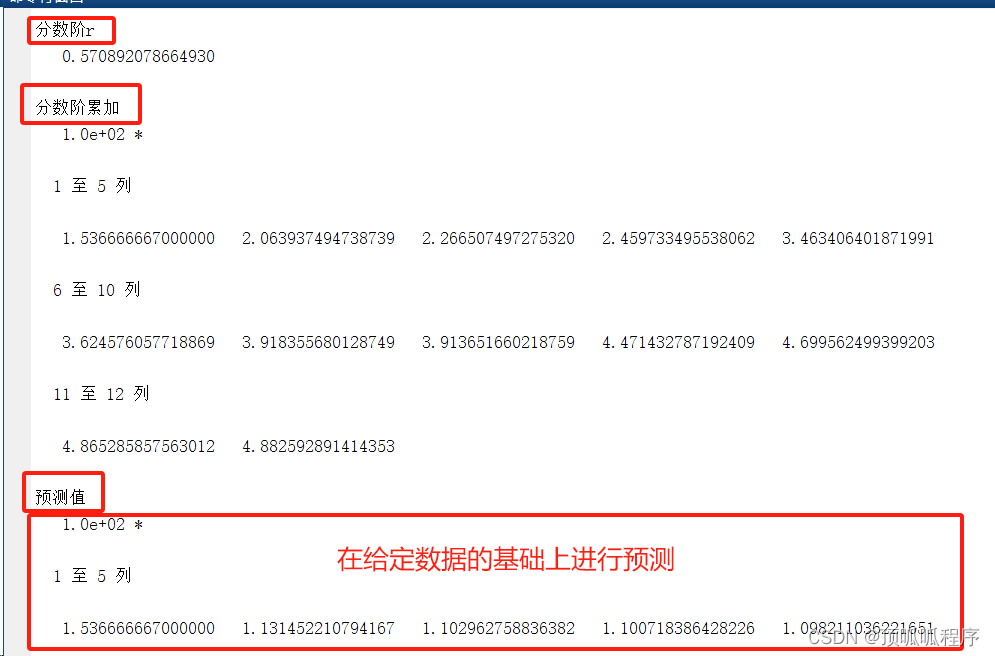
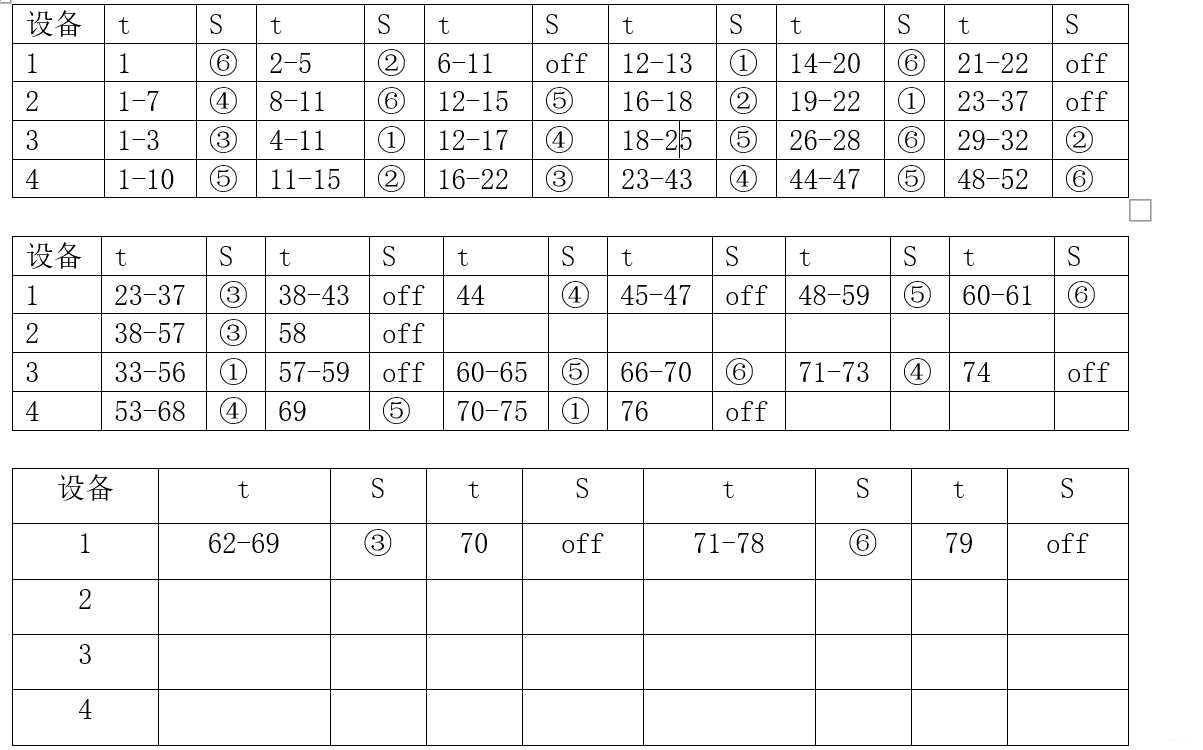
目录
一、文件操作
1、文件打开与关闭
2、文件读写
3、文件操作模式
4、文件编码
二、文件夹操作
1、创建文件夹
2、删除文件夹
3、改变当前工作目录
4、获取当前工作目录
5、检查文件/文件夹是否存在
6、遍历文件夹
三、文件路径操作
1、获取绝对路径
2、构建完整路径
3、检查路径是否存在
4、判断是否为目录
5、获取路径的目录部分和文件名部分
6、获取文件名(不含扩展名)和扩展名
四、流
1、流的理解
2、流的特性
2-1、顺序性
2-2、连续性
2-3、抽象性
3、流的分类
3-1、根据读写操作
3-1-1、输入流
3-1-2、输出流
3-2、根据数据类型
3-2-1、字节流
3-2-2、字符流
3-3、根据环境
3-3-1、文件流
3-3-2、网络流
3-3-3、内存流
3-3-4、数据库流
4、流的操作
4-1、打开流(如打开文件或建立网络连接)
4-2、读取数据(从输入流中)
4-3、写入数据(到输出流中)
4-4、关闭流(释放资源)
五、推荐阅读
1、Python函数之旅
2、Python算法之旅
3、博客个人主页



一、文件操作
1、文件打开与关闭
# 1、文件打开和关闭
# 1-1、读取文件
with open('test.txt', 'r') as file:
# 读取文件内容
content = file.read()
print(content)
# with语句块结束时,文件会自动关闭
# 1-2、写入文件
# 打开文件以写入,如果文件不存在则创建它
with open('test.txt', 'w') as file:
# 写入内容到文件
file.write('Hello, World!')
# with语句块结束时,文件会自动关闭
# 1-3、追加到文件
with open('test.txt', 'a') as file:
# 追加内容到文件
file.write('\nAnother line of text.')
# with语句块结束时,文件会自动关闭
# 1-4、读取文件行
with open('test.txt', 'r') as file:
# 逐行读取文件内容
for line in file:
print(line, end='') # 使用 end='' 避免打印额外的换行符
# with语句块结束时,文件会自动关闭2、文件读写
# 2、文件读写
# 2-1、读取整个文件
# 打开文件并读取整个内容
with open('test.txt', 'r', encoding='utf-8') as file:
content = file.read()
print(content)
# 文件会在with语句块结束时自动关闭
# 2-2、逐行读取文件
# 打开文件并逐行读取内容
with open('test.txt', 'r', encoding='utf-8') as file:
for line in file:
print(line, end='') # 如果不想在每行后都打印换行符,可以使用end=''
# 文件会在with语句块结束时自动关闭
# 2-3、读取并修改文件内容(不推荐在原文件修改)
# 读取文件内容
with open('test.txt', 'r', encoding='utf-8') as file:
content = file.read()
modified_content = content.replace('World', 'Python')
# 将修改后的内容写回到文件
with open('test.txt', 'w', encoding='utf-8') as file:
file.write(modified_content)
with open('test.txt', 'r', encoding='utf-8') as file:
content = file.read()
print(content)
# 文件会在with语句块结束时自动关闭
# 2-4、读取和写入二进制文件
# 读取二进制文件
with open('example.bin', 'rb') as file:
binary_content = file.read()
# 处理二进制内容(这里只是简单打印长度)
print(len(binary_content))
# 写入二进制内容到文件(这里只是一个示例,你需要有有效的二进制数据)
with open('output.bin', 'wb') as file:
file.write(b'\x00\x01\x02\x03') # 写入四个字节的二进制数据
# 文件会在with语句块结束时自动关闭3、文件操作模式
# 3、文件操作模式
# 3-1、读取模式(r)
# 读取文件内容,文件必须存在,否则会引发FileNotFoundError
with open('test.txt', 'r', encoding='utf-8') as file:
content = file.read()
print(content)
# 3-2、写入模式(w)
# 写入文件内容,如果文件不存在则创建它,如果文件已存在则覆盖它
with open('test.txt', 'w', encoding='utf-8') as file:
file.write('Hello, World!\n')
# 3-3、追加模式(a)
# 将内容追加到文件末尾,如果文件不存在则创建它
with open('test.txt', 'a', encoding='utf-8') as file:
file.write('This is appended content.\n')
# 3-4、读写模式(r+)
# 打开文件进行读写,文件指针会放在文件的开头
with open('test.txt', 'r+', encoding='utf-8') as file:
content = file.read()
print(content)
file.seek(0) # 将文件指针重置到文件开头
file.write('This will replace the first line if it\'s short enough.\n')
# 3-5、写入并读取模式(w+)
# 打开文件进行读写,如果文件已存在则覆盖它,如果文件不存在则创建它
with open('test.txt', 'w+', encoding='utf-8') as file:
file.write('Hello, World!\n')
file.seek(0) # 将文件指针重置到文件开头
content = file.read()
print(content)
# 3-6、追加并读取模式(a+)
# 打开文件进行读写。如果文件已存在,文件指针会放在文件的末尾(即追加模式);如果文件不存在,创建文件
with open('test.txt', 'a+', encoding='utf-8') as file:
file.write('Appending content...\n')
file.seek(0) # 将文件指针重置到文件开头
content = file.read()
print(content) # 注意:这里会先打印出原有内容,然后是新追加的内容
# 3-7、二进制读取模式(rb)
# 读取二进制文件内容
with open('example.bin', 'rb') as file:
binary_content = file.read()
# 处理二进制内容...
# 3-8、二进制写入模式(wb)
# 写入二进制文件内容
with open('example.bin', 'wb') as file:
file.write(b'\x00\x01\x02\x03')
# 3-9、二进制追加模式(ab)
# 将二进制内容追加到文件末尾
with open('example.bin', 'ab') as file:
file.write(b'\x04\x05\x06\x07')4、文件编码
# 4、文件编码
# 4-1、读取不同编码的文件
# 读取UTF-8编码的文件
with open('utf8_file.txt', 'r', encoding='utf-8') as file:
content = file.read()
print(content)
# 读取ISO-8859-1(Latin-1)编码的文件
with open('latin1_file.txt', 'r', encoding='iso-8859-1') as file:
content = file.read()
print(content)
# 注意:如果文件编码与指定的编码不匹配,可能会出现乱码
# 4-2、将文本写入文件并指定编码
# 将文本写入UTF-8编码的文件
with open('output_utf8.txt', 'w', encoding='utf-8') as file:
file.write('你好,世界!')
# 将文本写入ISO-8859-1编码的文件(注意:非ASCII字符可能会被编码为替代字符)
with open('output_latin1.txt', 'w', encoding='iso-8859-1', errors='replace') as file:
file.write('你好,世界!') # 这将写入替代字符,因为Latin-1不支持中文字符
# 使用二进制模式写入,并手动编码为UTF-8
with open('output_binary_utf8.txt', 'wb') as file:
file.write('你好,世界!'.encode('utf-8'))
# 4-3、转换文件编码
# 将UTF-8编码的文件转换为GBK编码的文件
with open('input_utf8.txt', 'r', encoding='utf-8') as file_utf8, \
open('output_gbk.txt', 'w', encoding='gbk') as file_gbk:
content = file_utf8.read()
file_gbk.write(content)
# 注意:如果原始文件包含GBK不支持的字符,这可能会导致错误,你可能需要处理这种情况
# 4-4、检测文件编码
# 首先,你需要安装chardet库
import chardet
# 检测文件的编码
with open('test.txt', 'rb') as file:
raw_data = file.read()
result = chardet.detect(raw_data)
print(result) # 输出类似{'encoding': 'ascii', 'confidence': 1.0, 'language': ''}的字典
# 使用检测到的编码读取文件
encoding = chardet.detect(raw_data)['encoding']
with open('test.txt', 'r', encoding=encoding) as file:
content = file.read()
print(content)二、文件夹操作
1、创建文件夹
# 5-1、创建单个文件夹
import os
# 定义要创建的文件夹路径,根据实际情况,自行修改即可
folder_path = 'E:\测试代码\my_new_folder'
# 使用os.makedirs创建文件夹
# 如果文件夹已存在并且没有设置exist_ok=True,则会抛出FileExistsError异常
try:
os.makedirs(folder_path)
print(f"文件夹 '{folder_path}' 已成功创建!")
except FileExistsError:
print(f"文件夹 '{folder_path}' 已存在!")
# 如果你想避免异常,并允许文件夹已存在,可以这样做:
try:
os.makedirs(folder_path, exist_ok=True)
print(f"文件夹 '{folder_path}' 已创建或已存在!")
except Exception as e:
print(f"创建文件夹时发生错误:{e}")
# 5-2、创建嵌套的文件夹
import os
# 定义要创建的嵌套文件夹路径
nested_folder_path = 'E:\测试代码\Myelsa'
# 使用os.makedirs创建嵌套的文件夹
try:
os.makedirs(nested_folder_path)
print(f"嵌套文件夹 '{nested_folder_path}' 已成功创建!")
except FileExistsError:
print(f"嵌套文件夹 '{nested_folder_path}' 已存在!")
# 如果你想避免异常,并允许文件夹已存在,可以这样做:
try:
os.makedirs(nested_folder_path, exist_ok=True)
print(f"嵌套文件夹 '{nested_folder_path}' 已创建或已存在!")
except Exception as e:
print(f"创建嵌套文件夹时发生错误:{e}")2、删除文件夹
# 6、删除文件夹
# 6-1、使用os.rmdir()删除空文件夹
import os
# 定义要删除的文件夹路径(注意:这个文件夹必须是空的)
folder_path = 'E:\测试代码\Myelsa'
# 使用os.rmdir删除文件夹
try:
os.rmdir(folder_path)
print(f"文件夹 '{folder_path}' 已成功删除!")
except OSError as e:
print(f"删除文件夹时发生错误:{e}") # 输出:删除文件夹时发生错误:[WinError 145] 目录不是空的。: 'E:\\测试代码\\Myelsa'
# 注意:如果文件夹不为空,os.rmdir()会抛出OSError异常
# 6-2、使用shutil.rmtree()删除文件夹及其内容
import shutil
# 定义要删除的文件夹路径(可以包含文件和其他文件夹)
folder_path = 'E:\测试代码\Myelsa'
# 使用shutil.rmtree删除文件夹及其内容
try:
shutil.rmtree(folder_path)
print(f"文件夹 '{folder_path}' 及其内容已成功删除!")
except OSError as e:
print(f"删除文件夹时发生错误:{e}")
# shutil.rmtree()会递归地删除指定目录及其所有内容3、改变当前工作目录
# 7、改变当前工作目录
# 7-1、改变当前工作目录
import os
# 打印当前工作目录
print(f"当前工作目录是:{os.getcwd()}")
# 定义新的工作目录路径
new_dir = 'E:\测试代码/directory' # 替换成你想要的工作目录路径
# 改变当前工作目录
try:
os.chdir(new_dir)
print(f"已成功改变工作目录到:{os.getcwd()}")
except FileNotFoundError:
print(f"目录 '{new_dir}' 不存在!")
except PermissionError:
print(f"你没有权限访问目录 '{new_dir}'!")
except Exception as e:
print(f"改变工作目录时发生错误:{e}")
# 7-2、使用相对路径改变工作目录
import os
# 假设你的脚本位于 /home/user/scripts 目录下
# 并且你想要改变到它的上一级目录 /home/user
# 打印当前工作目录
print(f"当前工作目录是:{os.getcwd()}")
# 定义新的工作目录(这里使用相对路径 ".." 表示上一级目录)
new_dir = '..'
# 改变当前工作目录
try:
os.chdir(new_dir)
print(f"已成功改变工作目录到:{os.getcwd()}")
except Exception as e:
print(f"改变工作目录时发生错误:{e}")4、获取当前工作目录
# 8、获取当前工作目录
import os
# 使用os.getcwd()获取当前工作目录
current_working_directory = os.getcwd()
# 打印当前工作目录
print(f"当前工作目录是:{current_working_directory}")5、检查文件/文件夹是否存在
# 9、检查文件/文件夹是否存在
# 9-1、检查文件是否存在
import os
# 定义文件路径
file_path = 'E:\测试代码\Myelsa/file.txt'
# 使用os.path.exists()检查文件是否存在
if os.path.exists(file_path):
print(f"文件 '{file_path}' 存在!")
else:
print(f"文件 '{file_path}' 不存在!")
# 如果你还想检查它是否是一个文件(而不是文件夹),可以使用os.path.isfile()
if os.path.isfile(file_path):
print(f"'{file_path}' 是一个文件!")
elif os.path.isdir(file_path):
print(f"'{file_path}' 是一个文件夹!")
# 9-2、检查文件夹是否存在
import os
# 定义文件夹路径
folder_path = 'E:\测试代码\Myelsa'
# 使用os.path.exists()检查文件夹是否存在
if os.path.exists(folder_path):
print(f"文件夹 '{folder_path}' 存在!")
else:
print(f"文件夹 '{folder_path}' 不存在!")
# 如果你只想检查它是否是一个文件夹(而不是文件),可以使用os.path.isdir()
if os.path.isdir(folder_path):
print(f"'{folder_path}' 是一个文件夹!")6、遍历文件夹
# 10、遍历文件夹
# 10-1、遍历指定文件夹中的所有文件和子文件夹
import os
# 定义要遍历的文件夹路径
folder_path = 'E:\测试代码\Myelsa'
# 遍历文件夹
for root, dirs, files in os.walk(folder_path):
for name in files:
# 构建文件的完整路径
file_path = os.path.join(root, name)
print(file_path) # 打印文件路径
for name in dirs:
# 构建子文件夹的完整路径
subfolder_path = os.path.join(root, name)
print(subfolder_path) # 打印子文件夹路径
# 如果你想递归遍历子文件夹,你可以在这里递归调用你的遍历函数
# 注意:os.walk()默认就是递归遍历的,所以你不需要额外写递归代码
# 10-2、仅遍历当前文件夹(不包括子文件夹)
import os
# 定义要遍历的文件夹路径
folder_path = 'E:\测试代码\Myelsa'
# 遍历文件夹中的文件和子文件夹
for name in os.listdir(folder_path):
# 构建文件的完整路径(如果是文件)
full_path = os.path.join(folder_path, name)
# 判断是文件还是文件夹
if os.path.isfile(full_path):
print(f"文件: {full_path}")
elif os.path.isdir(full_path):
print(f"文件夹: {full_path}")三、文件路径操作
1、获取绝对路径
# 11、获取绝对路径
# 11-1、获取当前工作目录的绝对路径
import os
# 获取当前工作目录的绝对路径
current_working_directory = os.path.abspath('.')
print(f"当前工作目录的绝对路径是:{current_working_directory}")
# 11-2、获取文件或文件夹的绝对路径
import os
# 定义文件或文件夹的相对路径
relative_path = 'E:\测试代码\Myelsa'
# 获取文件或文件夹的绝对路径
absolute_path = os.path.abspath(relative_path)
print(f"文件或文件夹的绝对路径是:{absolute_path}")
# 11-3、获取脚本文件的绝对路径
import os
# 获取脚本文件的绝对路径
script_dir = os.path.dirname(os.path.abspath(__file__))
print(f"脚本文件的绝对路径是:{script_dir}")
# 如果你想要获取脚本文件所在目录下的某个文件的绝对路径
file_in_same_dir = os.path.join(script_dir, 'file.txt')
print(f"同一目录下的某个文件的绝对路径是:{file_in_same_dir}")2、构建完整路径
# 12、构建完整路径
# 12-1、使用os.path.join()构建相对路径
import os
# 定义路径组件
directory = 'path'
subdirectory = 'to'
filename = 'your_file.txt'
# 使用os.path.join()构建相对路径
relative_path = os.path.join(directory, subdirectory, filename)
print(f"相对路径是:{relative_path}")
# 12-2、使用os.path.join()和os.getcwd()构建绝对路径
import os
# 定义路径组件
relative_directory = 'path'
relative_filename = 'your_file.txt'
# 获取当前工作目录的绝对路径
current_directory = os.getcwd()
# 使用os.path.join()将当前工作目录和相对路径组件合并成绝对路径
absolute_path = os.path.join(current_directory, relative_directory, relative_filename)
print(f"绝对路径是:{absolute_path}")
# 12-3、构建具有特定根目录的完整路径
import os
# 定义根目录和路径组件
root_directory = '/home/user'
directory = 'data'
filename = 'important_data.csv'
# 使用os.path.join()构建完整路径
full_path = os.path.join(root_directory, directory, filename)
print(f"完整路径是:{full_path}")3、检查路径是否存在
# 13、检查路径是否存在
# 13-1、检查文件是否存在
import os
# 定义文件路径
file_path = '/path/to/your/file.txt'
# 检查文件是否存在
if os.path.exists(file_path):
print(f"文件 {file_path} 存在!")
else:
print(f"文件 {file_path} 不存在!")
# 13-2、检查文件夹是否存在
import os
# 定义文件夹路径
folder_path = 'E:\测试代码\Myelsa'
# 检查文件夹是否存在
if os.path.exists(folder_path):
print(f"文件夹 {folder_path} 存在!")
# 如果需要,还可以检查它是否真的是一个文件夹
if os.path.isdir(folder_path):
print(f"并且它是一个文件夹!")
else:
print(f"但它不是一个文件夹!")
else:
print(f"文件夹 {folder_path} 不存在!")
# 13-3、检查路径是否存在,并根据情况创建文件夹
import os
# 定义文件夹路径
folder_path = 'E:\测试代码\Myelsa'
# 检查文件夹是否存在
if not os.path.exists(folder_path):
# 如果文件夹不存在,则创建它
os.makedirs(folder_path)
print(f"文件夹 {folder_path} 已创建!")
else:
print(f"文件夹 {folder_path} 已经存在!")4、判断是否为目录
# 14、判断是否为目录
# 14-1、判断一个路径是否为目录
import os
# 定义路径
path = 'E:\测试代码\Myelsa'
# 判断是否为目录
if os.path.isdir(path):
print(f"路径 {path} 是一个目录!")
else:
print(f"路径 {path} 不是一个目录或不存在!")
# 14-2、结合os.path.exists()和os.path.isdir()
# 如果你想先检查路径是否存在,然后再判断它是否是一个目录
import os
# 定义路径
path = 'E:\测试代码\Myelsa'
# 检查路径是否存在
if os.path.exists(path):
# 如果存在,再判断是否为目录
if os.path.isdir(path):
print(f"路径 {path} 是一个存在的目录!")
else:
print(f"路径 {path} 存在,但它不是一个目录,可能是一个文件!")
else:
print(f"路径 {path} 不存在!")
# 14-3、处理多个路径
# 如果你想检查多个路径,并将它们是否为目录的信息打印出来
import os
# 定义多个路径
paths = [
'E:\测试代码\Myelsa',
'E:\测试代码\Myelsa/folder1',
'E:\测试代码\Myelsa/file.txt'
]
# 遍历路径并判断
for path in paths:
if os.path.isdir(path):
print(f"路径 {path} 是一个目录!")
else:
print(f"路径 {path} 不是一个目录或不存在!")5、获取路径的目录部分和文件名部分
# 15、获取路径的目录部分和文件名部分
# 15-1、获取目录部分和文件名部分
import os
# 定义文件路径
path = 'E:\测试代码\Myelsa/file.txt'
# 获取目录部分
dir_path = os.path.dirname(path)
print(f"目录部分是:{dir_path}")
# 获取文件名部分
file_name = os.path.basename(path)
print(f"文件名部分是:{file_name}")
# 15-2、处理多个文件路径
import os
# 定义多个文件路径
paths = [
'E:\测试代码\Myelsa/file.txt',
'E:\测试代码\Myelsa/folder1/file.txt',
'E:\测试代码\Myelsa/folder2/file.txt'
]
# 遍历路径并获取目录部分和文件名部分
for path in paths:
dir_path = os.path.dirname(path)
file_name = os.path.basename(path)
print(f"路径 {path} 的目录部分是:{dir_path}")
print(f"路径 {path} 的文件名部分是:{file_name}")
print() # 打印一个空行分隔不同的路径信息6、获取文件名(不含扩展名)和扩展名
# 16、获取文件名(不含扩展名)和扩展名
# 16-1、获取文件名(不含扩展名)和扩展名
import os
# 定义文件路径
path = 'E:\测试代码\Myelsa/file.txt'
# 获取文件名和扩展名
filename, extension = os.path.splitext(os.path.basename(path))
# 打印结果
print(f"文件名(不含扩展名)是:{filename}")
print(f"扩展名是:{extension}")
# 16-2、处理多个文件路径
import os
# 定义多个文件路径
paths = [
'E:\测试代码\Myelsa/file.txt',
'E:\测试代码\Myelsa/folder1/file.txt',
'E:\测试代码\Myelsa/folder2/file.txt'
]
# 遍历路径并获取文件名(不含扩展名)和扩展名
for path in paths:
filename, extension = os.path.splitext(os.path.basename(path))
print(f"路径 {path} 的文件名(不含扩展名)是:{filename}")
print(f"路径 {path} 的扩展名是:{extension}")
print() # 打印一个空行分隔不同的路径信息四、流
1、流的理解
在Python中,"流"(stream)这个概念通常与文件I/O(输入/输出)或网络通信等场景相关,它指的是一种数据传输的抽象,允许数据以连续的方式从一个位置移动到另一个位置,流可以是输入流(从源读取数据),也可以是输出流(将数据写入目标)。
2、流的特性
2-1、顺序性
数据在流中是按顺序传输的。
2-2、连续性
数据在流中是连续不断的,直到整个数据传输完成。
2-3、抽象性
流提供了一个对数据传输的抽象层,使得我们不必关心底层的实现细节。
3、流的分类
3-1、根据读写操作
3-1-1、输入流
用于从数据源读取数据。
3-1-2、输出流
用于将数据写入到目标位置。
3-2、根据数据类型
3-2-1、字节流
用于处理二进制数据,如图像、音频、视频等。
3-2-2、字符流
用于处理文本数据,即字符序列。
| 流的分类 | 数据类型 | 处理对象 |
| 字符流 | 处理文本数据,遵循字符编码规则 | 以字符为单位进行读写,需要考虑字符编码 |
| 字节流 | 处理二进制数据,不遵循字符编码规则 | 以字节为单位进行读写,不关心字符编码 |
3-3、根据环境
3-3-1、文件流
用于文件的读写操作。
3-3-2、网络流
用于网络通信中的数据传输。
3-3-3、内存流
在内存中处理数据,如缓存、临时存储等。
3-3-4、数据库流
与数据库交互时使用的数据流。
4、流的操作
对于流,我们通常可以执行以下操作: