目录
一、前言
1.1 闭散列
1.2 开散列
1.3 string 与 非 string
二、哈希桶的构成
2.1 哈希桶的节点
2.2 哈希桶类
三、 Insert 函数
3.1 无需扩容时
3.2 扩容
复用 Insert:
逐个插入:
优缺点比对:
第一种写法优点
第一种写法缺点
第二种写法优点
第二种写法缺点
3.3 完整代码
四、 Erase 函数
4.1 析构函数
4.2 Erase 函数
五、 Find 函数
六、完整代码
一、前言
上一篇文章讲的哈希表,属于闭散列。可以解决哈希冲突有两种方式:闭散列和开散列。现在要学习的哈希桶就是开散列。
1.1 闭散列
闭散列:也叫开放定址法,当发生哈希冲突时,如果哈希表未被装满,说明在哈希表中必然还有
空位置,那么可以把key存放到冲突位置中的“下一个” 空位置中去。

1.2 开散列
开散列法又叫链地址法(开链法),首先对关键码集合用散列函数计算散列地址,具有相同地
址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链
接起来,各链表的头结点存储在哈希表中。
下面则是即将学习的哈希桶的简易图: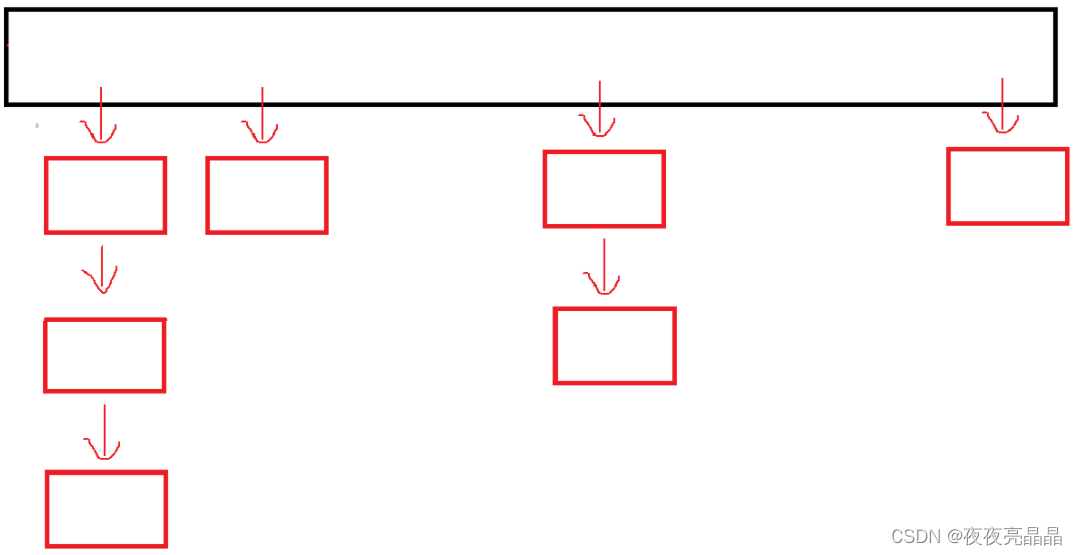
类似于一个数组中存了若干个链表头,每个头所代表的链表成为一个桶。
1.3 string 与 非 string
在上一篇博客的最后:哈希表HashTable-CSDN博客
探讨过当 Key 为负数、浮点数、字符串...时,类函数逻辑中有关 Key 取模的问题,当 Key 为负数、浮点数、字符、字符串时,显然这几个内置类型无法完成取模的操作,这时就用到了仿函数,这里不再多说,直接来看仿函数的代码,下面会直接使用仿函数来完成 HashBucket
template<class T>
class HashFunc<>
{
size_t operator()(const T& Key)
{
return (size_t)Key;
}
}
template<>
class HashFunc<string>
{
size_t operator()(const string& Key)
{
size_t hash = 0;
for (auto ch : Key)
{
hash *= 131;
hash += ch;
}
return hash;
}
}
二、哈希桶的构成
2.1 哈希桶的节点
由上图就可以看出来,每个结点必要存一个 pair 和一个指向下一个节点的指针 _next。
template<class K, class V>
struct HashNode
{
pair<K, V> _kv;
HashNode* _next;
}2.2 哈希桶类
哈希桶类的构成和哈希表类似,都是一个由一个 vector 存放每个节点,但是这里与 HashTable 不同的是需要存放的是节点的指针。还有一个 _n 代表有效数据的个数:
template<class K, class V, class Hash = HashFunc<K>>
class HashBucket
{
typedef HashNode Node;
private:
vector<Node*> _bucket;
size_t _n;
};三、 Insert 函数
3.1 无需扩容时
下面要介绍的是不需要扩容时的插入逻辑:
此时只需要使用 Key 模数组的大小来计算出该节点需要连接在 vector 上的位置,然后使用 new 得到储存 kv 的新节点,当 new 一个新节点时,节点的构造函数必不可少,下面先来看一下单个节点的构造函数以及类的构造函数:
template<class K, class V>
struct HashNode
{
pair<K, V> _kv;
HashNode* _next;
HashNode(const pair<K, V>& kv):_kv(kv), _next(nullptr)
{}
};
template<class K, class V, class Hash = HashFunc<K>>
class HashBucket
{
typedef HashNode<K, V> Node;
HashBucket()
{
_bucket.resize(10, nullptr);
_n = 0;
}
private:
vector<Node*> _bucket;
size_t _n;
}
此时需要思考的是,既然 vector 每个节点都要存放一个链表,那么链表头插还是尾插的效率更高呢?
显然是头插,所以这个新结点就需要以类似头插的方式添加到 vector 的这个位置上,
bool Insert(const pair<K, V>& kv)
{
Hash hs;
size_t index = hs(kv.first) % _bucket.size();
Node* newnode = new Node(kv);
newnode->_next = _bucket[index];
_buckte[index] = newnode;
++_n;
return true;
}3.2 扩容
这里的载荷因子可以直接设为1,至于载荷因子是什么,可以查看上一篇博客哈希表HashTable-CSDN博客,在扩容中的何时扩容标题下,介绍了载荷因子的概念。
在扩容中,既可以使用 HashTable 中类似的写法直接复用 Insert ,也可以直接挨个让节点插入,下面先介绍每种方式,再进行优缺点的处理:
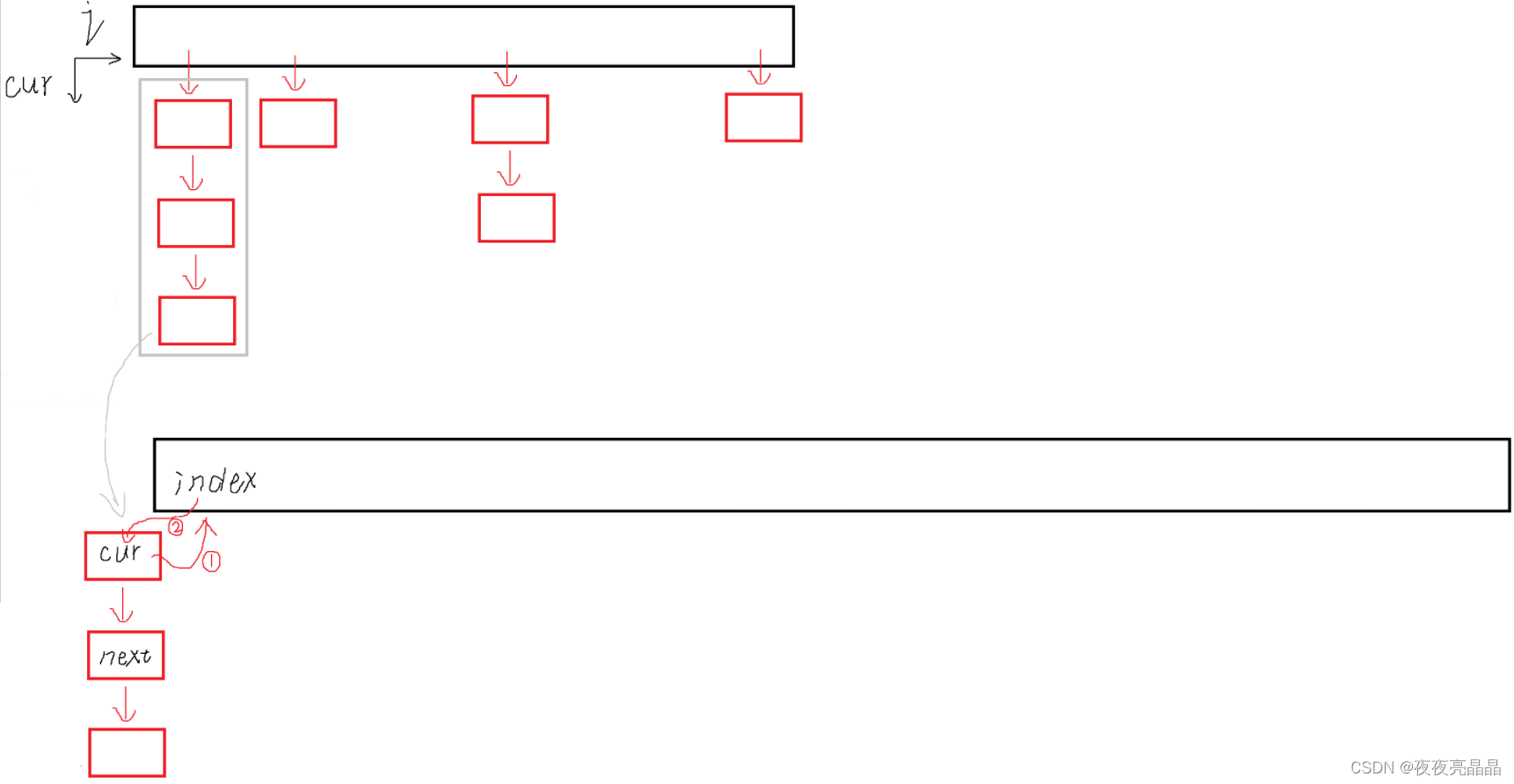
复用 Insert:
bool Insert(const pair<K, V>& kv)
{
Hash hs;
if (_n == _bucket.size())
{
HashBucket newHB = new HashBucket;
newHB._bucket.resize(_bucket.size() * 2, nullptr);
for (size_t i = 0; i < _bucket.size(); i++)
{
Node* cur = _bucket[i];
while(cur)
{
Node* next = cur->_next; // 保存下一个节点指针
newHB.Insert(cur->_kv); // 插入当前节点的键值对到新哈希表
cur = next; // 移动到下一个节点
}
_bucket[i] = nullptr;
}
_bucket.swap(newHB);
}
}逐个插入:
bool Insert(const pair<K, V>& kv)
{
Hash hs;
if (_n == _bucket.size())
{
vector<Node*> newBucket(_bucket.size() * 2, nullptr);
for (size_t i = 0; i < _bucket.size(); i++)
{
Node* cur = _bucket[i];
while (cur)
{
Node* next = cur->_next;
size_t index = hs(cur->_kv.first) % newBucket.size();
cur->_next = newBucket[index];
newBucket[index] = cur;
cur = next;
}
_bucket[i] = nullptr;
}
_bucket.swap(newBucket);
}
}优缺点比对:
第一种写法优点
- 代码复用:通过调用
newHB.Insert(cur->_kv)来重新插入节点,重用了Insert方法,减少了代码重复。 - 逻辑清晰:将旧节点迁移到新桶中,然后交换桶,逻辑分离清晰。
第一种写法缺点
- 性能:因为每次扩容时调用
Insert,可能会多次计算哈希值和处理冲突,性能可能稍差。
第二种写法优点
- 性能:直接处理节点迁移,无需调用
Insert方法,减少了函数调用和重复计算,提高了性能。 - 直接操作:直接操作指针,代码简洁,性能高效。
第二种写法缺点
- 代码重复:需要手动处理节点迁移逻辑,代码重复。
- 复杂性:直接操作指针可能增加代码的复杂性,增加错误的可能性。
3.3 完整代码
bool Insert(const pair<K, V>& kv)
{
if (Find(kv.first)) return false;
Hash hs;
if (_n == _bucket.size())
{
HashBucket newHB;
newHB._bucket.resize(_bucket.size() * 2, nullptr);
for (size_t i = 0; i < _bucket.size(); i++)
{
Node* cur = _bucket[i];
while (cur)
{
Node* next = cur->_next; // 保存下一个节点指针
newHB.Insert(cur->_kv); // 插入当前节点的键值对到新哈希表
cur = next; // 移动到下一个节点
}
_bucket[i] = nullptr;
}
_bucket.swap(newHB._bucket);
}
size_t index = hs(kv.first) % _bucket.size();
Node* newnode = new Node(kv);
newnode->_next = _bucket[index];
_bucket[index] = newnode;
++_n;
return true;
}
bool Insert(const pair<K, V>& kv)
{
if (Find(kv.first)) return false;
Hash hs;
if (_n == _bucket.size())
{
vector<Node*> newBucket(_bucket.size() * 2, nullptr);
for (size_t i = 0; i < _bucket.size(); i++)
{
Node* cur = _bucket[i];
while (cur)
{
Node* next = cur->_next;
size_t index = hs(cur->_kv.first) % newBucket.size();
cur->_next = newBucket[index];
newBucket[index] = cur;
cur = next;
}
_bucket[i] = nullptr;
}
_bucket.swap(newBucket);
}
size_t index = hs(kv.first) % _bucket.size();
Node* newnode = new Node(kv);
newnode->_next = _bucket[index];
_bucket[index] = newnode;
++_n;
return true;
}四、 Erase 函数
4.1 析构函数
根据 Insert 函数中,可以得知, HashBucket 的每个节点都是 new 出来的,那删除的时候就要使用 delete ,又因为每个节点都是自定义类型,所以要为 HashBucket 写一个析构函数。
对类的析构就是遍历 vector 的每个节点,再从每个节点遍历每个链表,以此遍历全部节点。
~HashBucket()
{
for (size_t i = 0; i < _bucket.size(); i++)
{
Node* cur = _bucket[i];
while (cur)
{
Node* next = cur->_next;
delete cur;
cur = next;
}
_bucket[i] = nullptr;
}
}4.2 Erase 函数
下面介绍一下Erase函数的步骤:
-
计算哈希值:使用哈希函数
hs计算给定键Key的哈希值,并确定它在桶中的索引index。 -
遍历链表:从索引
index开始,遍历链表中的每个节点。 -
查找节点:检查当前节点的键是否等于
Key。- 如果找到匹配节点:
- 如果该节点是链表的第一个节点,将桶的头指针
_bucket[index]指向下一个节点。 - 否则,将前一个节点的
_next指针指向当前节点的下一个节点。 - 删除当前节点
cur,释放内存。 - 返回
true,表示删除成功。
- 如果该节点是链表的第一个节点,将桶的头指针
- 如果没有找到匹配节点,继续遍历链表,更新
prev和cur。
- 如果找到匹配节点:
-
返回结果:如果遍历完整个链表未找到匹配节点,返回
false,表示删除失败。
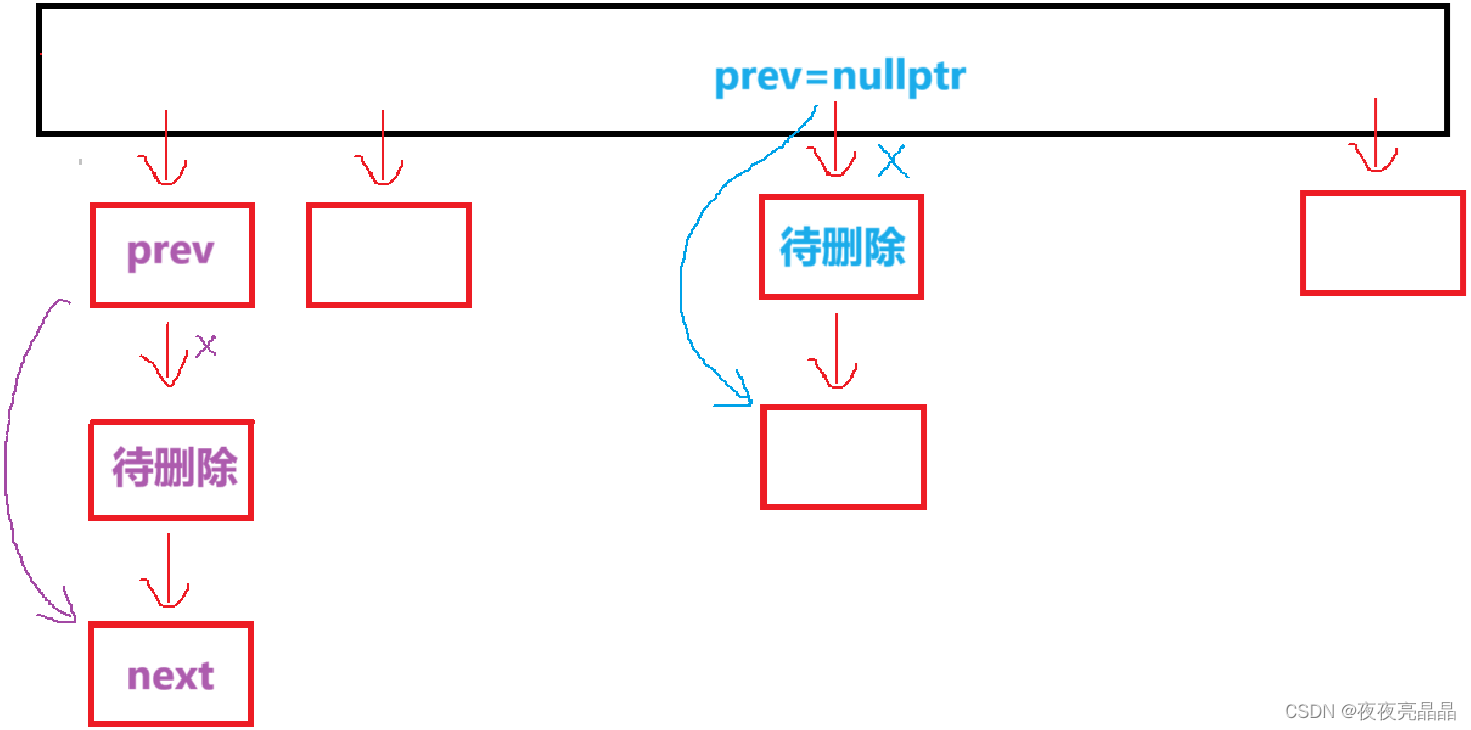
bool Erase(const K& Key)
{
Hash hs;
size_t index = hs(Key) % _bucket.size();
Node* cur = _bucket[index];
Node* prev = nullptr;
while (cur)
{
if (cur->_kv.first == Key)
{
//删除的是第一个节点
if (prev == nullptr)
{
_bucket[index] = cur->_next;
}
else
{
prev->_next = cur->_next;
}
delete cur;
return true;
}
else
{
prev = cur;
cur = cur->_next;
}
}
return false;
}五、 Find 函数
这里的 Find 函数与 HashTable 中的 Find 函数逻辑略有不同,因为这里如果发送哈希冲突,那么存储的位置还是 vector 中取模后的位置,不需要像 HashTable 那样进行线性探测,只需要取一个指针挨个遍历位于 _bucket[index] 链表上的节点即可。
Node* Find(const K& Key)
{
if (_bucket.empty()) return nullptr;
Hash hs;
size_t index = hs(Key) % _bucket.size();
Node* cur = _bucket[index];
while (cur)
{
if (cur->_kv.first == Key)
return cur;
else cur = cur->_next;
}
return nullptr;
}写完 Find 后,还可以进一步改进 Insert 函数,在插入时可以先进行查找,如果存在,那就插入失败;如果不存在,再继续插入。这样避免了哈希桶中数据冗余的结果。
六、完整代码
#pragma once
#include <iostream>
#include <vector>
#include <string>
using namespace std;
template<class K>
struct HashFunc
{
size_t operator()(const K& Key)
{
return (size_t)Key;
}
};
template<>
struct HashFunc<string>
{
size_t operator()(const string& Key)
{
size_t hash = 0;
for (auto ch : Key)
{
hash *= 131;
hash += ch;
}
return hash;
}
};
template<class K, class V>
struct HashNode
{
pair<K, V> _kv;
HashNode* _next;
HashNode(const pair<K, V>& kv):_kv(kv), _next(nullptr)
{}
};
template<class K, class V, class Hash = HashFunc<K>>
class HashBucket
{
public:
typedef HashNode<K, V> Node;
HashBucket()
{
_bucket.resize(10, nullptr);
_n = 0;
}
~HashBucket()
{
for (size_t i = 0; i < _bucket.size(); i++)
{
Node* cur = _bucket[i];
while (cur)
{
Node* next = cur->_next;
delete cur;
cur = next;
}
_bucket[i] = nullptr;
}
}
bool Insert(const pair<K, V>& kv)
{
if (Find(kv.first)) return false;
Hash hs;
if (_n == _bucket.size())
{
vector<Node*> newBucket(_bucket.size() * 2, nullptr);
for (size_t i = 0; i < _bucket.size(); i++)
{
Node* cur = _bucket[i];
while (cur)
{
Node* next = cur->_next;
size_t index = hs(cur->_kv.first) % newBucket.size();
cur->_next = newBucket[index];
newBucket[index] = cur;
cur = next;
}
_bucket[i] = nullptr;
}
_bucket.swap(newBucket);
}
size_t index = hs(kv.first) % _bucket.size();
Node* newnode = new Node(kv);
newnode->_next = _bucket[index];
_bucket[index] = newnode;
++_n;
return true;
}
bool Insert(const pair<K, V>& kv)
{
if (Find(kv.first)) return false;
Hash hs;
if (_n == _bucket.size())
{
HashBucket newHB;
newHB._bucket.resize(_bucket.size() * 2, nullptr);
for (size_t i = 0; i < _bucket.size(); i++)
{
Node* cur = _bucket[i];
while (cur)
{
Node* next = cur->_next; // 保存下一个节点指针
newHB.Insert(cur->_kv); // 插入当前节点的键值对到新哈希表
cur = next; // 移动到下一个节点
}
_bucket[i] = nullptr;
}
_bucket.swap(newHB._bucket);
}
size_t index = hs(kv.first) % _bucket.size();
Node* newnode = new Node(kv);
newnode->_next = _bucket[index];
_bucket[index] = newnode;
++_n;
return true;
}
bool Erase(const K& Key)
{
Hash hs;
size_t index = hs(Key) % _bucket.size();
Node* cur = _bucket[index];
Node* prev = nullptr;
while (cur)
{
if (cur->_kv.first == Key)
{
//删除的是第一个节点
if (prev == nullptr)
{
_bucket[index] = cur->_next;
}
else
{
prev->_next = cur->_next;
}
delete cur;
return true;
}
else
{
prev = cur;
cur = cur->_next;
}
}
return false;
}
Node* Find(const K& Key)
{
if (_bucket.empty()) return nullptr;
Hash hs;
size_t index = hs(Key) % _bucket.size();
Node* cur = _bucket[index];
while (cur)
{
if (cur->_kv.first == Key)
return cur;
else cur = cur->_next;
}
return nullptr;
}
private:
vector<Node*> _bucket;
size_t _n;
};
void TestHB1()
{
int ret[] = {5, 15, 3, 12, 13, 31};
HashBucket<int, int> hb;
for (auto e : ret)
{
hb.Insert(make_pair(e, e));
}
cout << hb.Erase(0) << endl;
cout << hb.Erase(5) << endl;
}
void TestHB2()
{
HashBucket<string, int> hb;
hb.Insert(make_pair("sort", 1));
hb.Insert(make_pair("left", 1));
hb.Insert(make_pair("insert", 1));
}