在网上下载了60多幅包含西瓜和冬瓜的图像组成melon数据集,使用 LabelMe 工具进行标注,然后使用 labelme2yolov8 脚本将json文件转换成YOLOv8支持的.txt文件,并自动生成YOLOv8支持的目录结构,包括melon.yaml文件,其内容如下:
path: ../datasets/melon # dataset root dir
train: images/train # train images (relative to 'path')
val: images/val # val images (relative to 'path')
test: # test images (optional)
# Classes
names:
0: watermelon
1: wintermelon使用以下python脚本进行训练生成torchscript文件:
import argparse
import colorama
from ultralytics import YOLO
def parse_args():
parser = argparse.ArgumentParser(description="YOLOv8 object detect")
parser.add_argument("--yaml", required=True, type=str, help="yaml file")
parser.add_argument("--epochs", required=True, type=int, help="number of training")
args = parser.parse_args()
return args
def train(yaml, epochs):
model = YOLO("yolov8n.pt") # load a pretrained model
results = model.train(data=yaml, epochs=epochs, imgsz=640) # train the model
metrics = model.val() # It'll automatically evaluate the data you trained, no arguments needed, dataset and settings remembered
model.export(format="onnx") #, dynamic=True) # export the model, cannot specify dynamic=True, opencv does not support
# model.export(format="onnx", opset=12, simplify=True, dynamic=False, imgsz=640)
model.export(format="torchscript") # libtorch
if __name__ == "__main__":
colorama.init()
args = parse_args()
train(args.yaml, args.epochs)
print(colorama.Fore.GREEN + "====== execution completed ======")以下是使用libtorch接口加载torchscript文件进行目标检测的实现代码:
namespace {
constexpr bool cuda_enabled{ false };
constexpr int image_size[2]{ 640, 640 }; // {height,width}, input shape (1, 3, 640, 640) BCHW and output shape(s) (1, 6, 8400)
constexpr float model_score_threshold{ 0.45 }; // confidence threshold
constexpr float model_nms_threshold{ 0.50 }; // iou threshold
#ifdef _MSC_VER
constexpr char* onnx_file{ "../../../data/best.onnx" };
constexpr char* torchscript_file{ "../../../data/best.torchscript" };
constexpr char* images_dir{ "../../../data/images/predict" };
constexpr char* result_dir{ "../../../data/result" };
constexpr char* classes_file{ "../../../data/images/labels.txt" };
#else
constexpr char* onnx_file{ "data/best.onnx" };
constexpr char* torchscript_file{ "data/best.torchscript" };
constexpr char* images_dir{ "data/images/predict" };
constexpr char* result_dir{ "data/result" };
constexpr char* classes_file{ "data/images/labels.txt" };
#endif
std::vector<std::string> parse_classes_file(const char* name)
{
std::vector<std::string> classes;
std::ifstream file(name);
if (!file.is_open()) {
std::cerr << "Error: fail to open classes file: " << name << std::endl;
return classes;
}
std::string line;
while (std::getline(file, line)) {
auto pos = line.find_first_of(" ");
classes.emplace_back(line.substr(0, pos));
}
file.close();
return classes;
}
auto get_dir_images(const char* name)
{
std::map<std::string, std::string> images; // image name, image path + image name
for (auto const& dir_entry : std::filesystem::directory_iterator(name)) {
if (dir_entry.is_regular_file())
images[dir_entry.path().filename().string()] = dir_entry.path().string();
}
return images;
}
void draw_boxes(const std::vector<std::string>& classes, const std::vector<int>& ids, const std::vector<float>& confidences,
const std::vector<cv::Rect>& boxes, const std::string& name, cv::Mat& frame)
{
if (ids.size() != confidences.size() || ids.size() != boxes.size() || confidences.size() != boxes.size()) {
std::cerr << "Error: their lengths are inconsistent: " << ids.size() << ", " << confidences.size() << ", " << boxes.size() << std::endl;
return;
}
std::cout << "image name: " << name << ", number of detections: " << ids.size() << std::endl;
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_int_distribution<int> dis(100, 255);
for (auto i = 0; i < ids.size(); ++i) {
auto color = cv::Scalar(dis(gen), dis(gen), dis(gen));
cv::rectangle(frame, boxes[i], color, 2);
std::string class_string = classes[ids[i]] + ' ' + std::to_string(confidences[i]).substr(0, 4);
cv::Size text_size = cv::getTextSize(class_string, cv::FONT_HERSHEY_DUPLEX, 1, 2, 0);
cv::Rect text_box(boxes[i].x, boxes[i].y - 40, text_size.width + 10, text_size.height + 20);
cv::rectangle(frame, text_box, color, cv::FILLED);
cv::putText(frame, class_string, cv::Point(boxes[i].x + 5, boxes[i].y - 10), cv::FONT_HERSHEY_DUPLEX, 1, cv::Scalar(0, 0, 0), 2, 0);
}
cv::imshow("Inference", frame);
cv::waitKey(-1);
std::string path(result_dir);
path += "/" + name;
cv::imwrite(path, frame);
}
float letter_box(const cv::Mat& src, cv::Mat& dst, const std::vector<int>& imgsz)
{
if (src.cols == imgsz[1] && src.rows == imgsz[0]) {
if (src.data == dst.data) {
return 1.;
} else {
dst = src.clone();
return 1.;
}
}
auto resize_scale = std::min(imgsz[0] * 1. / src.rows, imgsz[1] * 1. / src.cols);
int new_shape_w = std::round(src.cols * resize_scale);
int new_shape_h = std::round(src.rows * resize_scale);
float padw = (imgsz[1] - new_shape_w) / 2.;
float padh = (imgsz[0] - new_shape_h) / 2.;
int top = std::round(padh - 0.1);
int bottom = std::round(padh + 0.1);
int left = std::round(padw - 0.1);
int right = std::round(padw + 0.1);
cv::resize(src, dst, cv::Size(new_shape_w, new_shape_h), 0, 0, cv::INTER_AREA);
cv::copyMakeBorder(dst, dst, top, bottom, left, right, cv::BORDER_CONSTANT, cv::Scalar(114.));
return resize_scale;
}
torch::Tensor xywh2xyxy(const torch::Tensor& x)
{
auto y = torch::empty_like(x);
auto dw = x.index({ "...", 2 }).div(2);
auto dh = x.index({ "...", 3 }).div(2);
y.index_put_({ "...", 0 }, x.index({ "...", 0 }) - dw);
y.index_put_({ "...", 1 }, x.index({ "...", 1 }) - dh);
y.index_put_({ "...", 2 }, x.index({ "...", 0 }) + dw);
y.index_put_({ "...", 3 }, x.index({ "...", 1 }) + dh);
return y;
}
// reference: https://github.com/pytorch/vision/blob/main/torchvision/csrc/ops/cpu/nms_kernel.cpp
torch::Tensor nms(const torch::Tensor& bboxes, const torch::Tensor& scores, float iou_threshold)
{
if (bboxes.numel() == 0)
return torch::empty({ 0 }, bboxes.options().dtype(torch::kLong));
auto x1_t = bboxes.select(1, 0).contiguous();
auto y1_t = bboxes.select(1, 1).contiguous();
auto x2_t = bboxes.select(1, 2).contiguous();
auto y2_t = bboxes.select(1, 3).contiguous();
torch::Tensor areas_t = (x2_t - x1_t) * (y2_t - y1_t);
auto order_t = std::get<1>(scores.sort(/*stable=*/true, /*dim=*/0, /* descending=*/true));
auto ndets = bboxes.size(0);
torch::Tensor suppressed_t = torch::zeros({ ndets }, bboxes.options().dtype(torch::kByte));
torch::Tensor keep_t = torch::zeros({ ndets }, bboxes.options().dtype(torch::kLong));
auto suppressed = suppressed_t.data_ptr<uint8_t>();
auto keep = keep_t.data_ptr<int64_t>();
auto order = order_t.data_ptr<int64_t>();
auto x1 = x1_t.data_ptr<float>();
auto y1 = y1_t.data_ptr<float>();
auto x2 = x2_t.data_ptr<float>();
auto y2 = y2_t.data_ptr<float>();
auto areas = areas_t.data_ptr<float>();
int64_t num_to_keep = 0;
for (int64_t _i = 0; _i < ndets; _i++) {
auto i = order[_i];
if (suppressed[i] == 1)
continue;
keep[num_to_keep++] = i;
auto ix1 = x1[i];
auto iy1 = y1[i];
auto ix2 = x2[i];
auto iy2 = y2[i];
auto iarea = areas[i];
for (int64_t _j = _i + 1; _j < ndets; _j++) {
auto j = order[_j];
if (suppressed[j] == 1)
continue;
auto xx1 = std::max(ix1, x1[j]);
auto yy1 = std::max(iy1, y1[j]);
auto xx2 = std::min(ix2, x2[j]);
auto yy2 = std::min(iy2, y2[j]);
auto w = std::max(static_cast<float>(0), xx2 - xx1);
auto h = std::max(static_cast<float>(0), yy2 - yy1);
auto inter = w * h;
auto ovr = inter / (iarea + areas[j] - inter);
if (ovr > iou_threshold)
suppressed[j] = 1;
}
}
return keep_t.narrow(0, 0, num_to_keep);
}
torch::Tensor non_max_suppression(torch::Tensor& prediction, float conf_thres = 0.25, float iou_thres = 0.45, int max_det = 300)
{
using torch::indexing::Slice;
using torch::indexing::None;
auto bs = prediction.size(0);
auto nc = prediction.size(1) - 4;
auto nm = prediction.size(1) - nc - 4;
auto mi = 4 + nc;
auto xc = prediction.index({ Slice(), Slice(4, mi) }).amax(1) > conf_thres;
prediction = prediction.transpose(-1, -2);
prediction.index_put_({ "...", Slice({None, 4}) }, xywh2xyxy(prediction.index({ "...", Slice(None, 4) })));
std::vector<torch::Tensor> output;
for (int i = 0; i < bs; i++) {
output.push_back(torch::zeros({ 0, 6 + nm }, prediction.device()));
}
for (int xi = 0; xi < prediction.size(0); xi++) {
auto x = prediction[xi];
x = x.index({ xc[xi] });
auto x_split = x.split({ 4, nc, nm }, 1);
auto box = x_split[0], cls = x_split[1], mask = x_split[2];
auto [conf, j] = cls.max(1, true);
x = torch::cat({ box, conf, j.toType(torch::kFloat), mask }, 1);
x = x.index({ conf.view(-1) > conf_thres });
int n = x.size(0);
if (!n) { continue; }
// NMS
auto c = x.index({ Slice(), Slice{5, 6} }) * 7680;
auto boxes = x.index({ Slice(), Slice(None, 4) }) + c;
auto scores = x.index({ Slice(), 4 });
auto i = nms(boxes, scores, iou_thres);
i = i.index({ Slice(None, max_det) });
output[xi] = x.index({ i });
}
return torch::stack(output);
}
} // namespace
int test_yolov8_detect_libtorch()
{
// reference: ultralytics/examples/YOLOv8-LibTorch-CPP-Inference
if (auto flag = torch::cuda::is_available(); flag == true)
std::cout << "cuda is available" << std::endl;
else
std::cout << "cuda is not available" << std::endl;
torch::Device device(torch::cuda::is_available() ? torch::kCUDA : torch::kCPU);
auto classes = parse_classes_file(classes_file);
if (classes.size() == 0) {
std::cerr << "Error: fail to parse classes file: " << classes_file << std::endl;
return -1;
}
std::cout << "classes: ";
for (const auto& val : classes) {
std::cout << val << " ";
}
std::cout << std::endl;
try {
// load model
torch::jit::script::Module model;
if (torch::cuda::is_available() == true)
model = torch::jit::load(torchscript_file, torch::kCUDA);
else
model = torch::jit::load(torchscript_file, torch::kCPU);
model.eval();
// note: cpu is normal; gpu is abnormal: the model may not be fully placed on the gpu
// model = torch::jit::load(file); model.to(torch::kCUDA) ==> model = torch::jit::load(file, torch::kCUDA)
// model.to(device, torch::kFloat32);
for (const auto& [key, val] : get_dir_images(images_dir)) {
// load image and preprocess
cv::Mat frame = cv::imread(val, cv::IMREAD_COLOR);
if (frame.empty()) {
std::cerr << "Warning: unable to load image: " << val << std::endl;
continue;
}
cv::Mat bgr;
letter_box(frame, bgr, {image_size[0], image_size[1]});
torch::Tensor tensor = torch::from_blob(bgr.data, { bgr.rows, bgr.cols, 3 }, torch::kByte).to(device);
tensor = tensor.toType(torch::kFloat32).div(255);
tensor = tensor.permute({ 2, 0, 1 });
tensor = tensor.unsqueeze(0);
std::vector<torch::jit::IValue> inputs{ tensor };
// inference
torch::Tensor output = model.forward(inputs).toTensor().cpu();
// NMS
auto keep = non_max_suppression(output, 0.1f, 0.1f, 300)[0];
std::vector<int> ids;
std::vector<float> confidences;
std::vector<cv::Rect> boxes;
for (auto i = 0; i < keep.size(0); ++i) {
int x1 = keep[i][0].item().toFloat();
int y1 = keep[i][1].item().toFloat();
int x2 = keep[i][2].item().toFloat();
int y2 = keep[i][3].item().toFloat();
boxes.emplace_back(cv::Rect(x1, y1, x2 - x1, y2 - y1));
confidences.emplace_back(keep[i][4].item().toFloat());
ids.emplace_back(keep[i][5].item().toInt());
}
draw_boxes(classes, ids, confidences, boxes, key, bgr);
}
} catch (const c10::Error& e) {
std::cerr << "Error: " << e.msg() << std::endl;
}
return 0;
}labels.txt文件内容如下:仅2类
watermelon 0
wintermelon 1说明:
1.这里使用的libtorch版本为2.2.2;
2.通过函数torch::cuda::is_available()判断执行cpu还是gpu
3.通过非cmake构建项目时,调用torch::cuda::is_available()时即使在gpu下也会返回false,解决方法:项目属性:链接器 --> 命令行:其他选项中添加如下语句:
/INCLUDE:?warp_size@cuda@at@@YAHXZ4.gpu下,语句model.to(torch::kCUDA)有问题,好像并不能将模型全部放置在gpu上,应调整为如下语句:
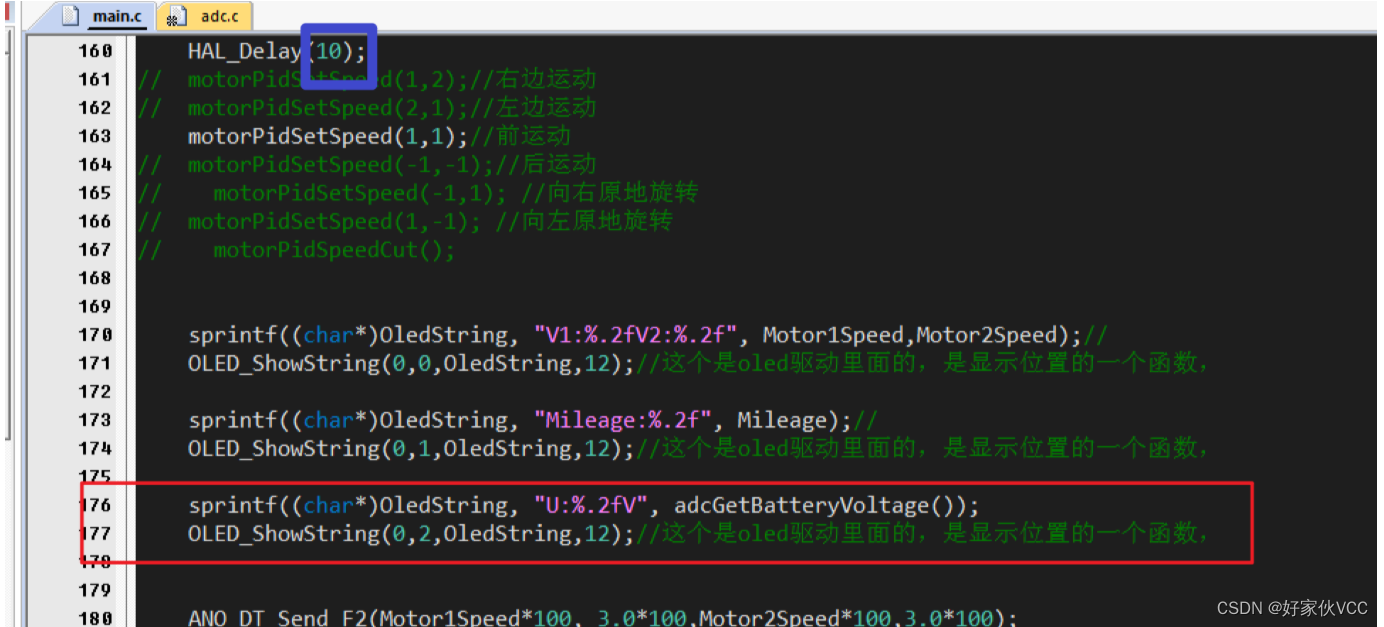
model = torch::jit::load(torchscript_file, torch::kCUDA);执行结果如下图所示:同样的预测图像集,结果不如使用 opencv dnn 方法好,它们的前处理和后处理方式不同

其中一幅图像的检测结果如下图所示:

GitHub:https://github.com/fengbingchun/NN_Test










![[Linux]文件/文件描述符fd](https://img-blog.csdnimg.cn/direct/ca447cc59d524d118e5ace21d3ca194f.png)