🎬个人简介:一个全栈工程师的升级之路!
📋个人专栏:pytorch深度学习
🎀CSDN主页 发狂的小花
🌄人生秘诀:学习的本质就是极致重复!
《PyTorch深度学习实践》完结合集_哔哩哔哩_bilibili
目录
1 Logistic Regression
2 整体流程
3 Softmax 多分类
4 交叉熵crossEntropy
5 Logistic Regression 代码
1 Logistic Regression
区别于Linear Regression,加入了激活函数,引入非线性。
一个二分类问题:
给定学习时长x,y为考试是否可以通过,通过为1,不通过为0
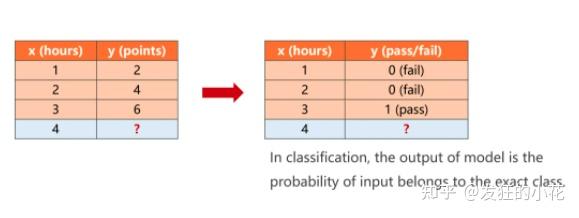
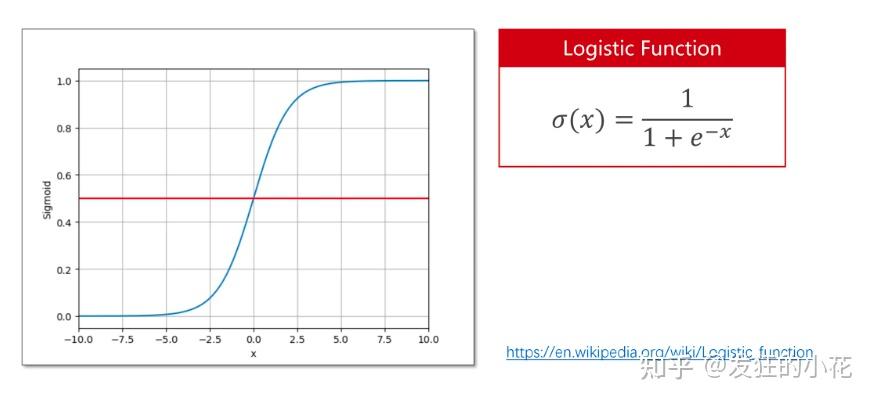
使用二分类激活函数sigmod,softmax多分类在只有两个分类时,也可以变成sigmoid
2 整体流程
- 数据准备:

- 模型建立:

- Loss建立

- mini-Batch Loss for Binary Classification

3 Softmax 多分类
一文彻底搞懂 Softmax 函数,数学原理分析和 PyTorch 验证
softmax就是将一些大的数字拉伸到0~1之间,而且使得大的数所占的比例更大,小的数所占的比例更小,这样如果每一个原始的数据代表score的话,将其总分控制在0~1之间,可以进一步使用交叉熵函数来计算loss。
这里Softmax会带来一些数据上溢和下溢问题,上溢问题可以减去max(y),下溢问题可以使用log(y)等手段来解决。

一个简单的softmax的例子:
#include <stdio.h>
#include <stdlib.h>
#include <stdint.h>
#include <math.h>
#define SIZE (4)
void softMax(double *src,double *dst,const int N)
{
double exp_score[N];
double sum = 0.f;
for (int i = 0;i < N;i++)
{
exp_score[i] = exp(src[i]);
sum += exp_score[i];
}
for (int i = 0;i < N;i++)
{
dst[i] = exp_score[i] / sum;
}
}
int main(int argc, char *argv[])
{
double score[SIZE] = {2.1,2.0,0.1,3.7};
double probability[SIZE] = {0.f};
softMax(score,probability,SIZE);
printf("Probability:[");
for (int i = 0;i < SIZE;i++)
{
printf(" %f ",probability[i]);
}
printf(" ]\n");
return 0;
}
4 交叉熵crossEntropy
计算两个概率分布之间的差异的,由于Softmax和Sigmod都将score转化为了概率分布,因此可以将交叉熵作为损失函数来计算y_true和y_pred之间的差异。
softmax分类器和交叉熵损失函数

一个多分类的交叉熵例子:
#include <stdio.h>
#include <stdlib.h>
#include <stdint.h>
#include <math.h>
#define M (3)
#define N (4)
double crossEntropy(double *y_true,double *y_pred,int m,int n)
{
// 防止log(0)的情况,对预测概率分布进行微小的修正
for (int i = 0;i < m;i++)
{
for (int j = 0;j < n;j++)
{
y_pred[i*n+j] = y_pred[i*n+j] <= 0 ? (1e-7) : (y_pred[i*n+j] > 1 ? (1) : y_pred[i*n+j]);
}
}
double sum = 0.f;
for (int i = 0;i < m;i++)
{
for (int j = 0;j < n;j++)
{
sum += -y_true[i*n+j] * log2(y_pred[i*n+j]);
}
}
return (sum / (double)m);
}
int main(int argc, char *argv[])
{
// one-hot 编码 代表标签分类 例如: 猫 狗 鸟 猪
// 真实概率分布
double probability[M][N] = {{1,0,0,0},{0,1,0,0},{0,0,1,0}};
// double y_pred[M][N] = {{0.7,0.2,0.05,0.05},{0,1,0,0},{0.1,0.1,0.8,0}};
double y_pred[M][N] = {{0.98,0.02,0,0},{0,1,0,0},{0,0,1,0}};
double loss = crossEntropy(&probability[0][0],&y_pred[0][0],M,N);
printf("loss: % .6lf \n",loss);
return 0;
}
5 Logistic Regression 代码
pytorch nn.BCELoss()详解
torch.empty()和torch.Tensor.random_()的使用举例-CSDN博客
import torch
# prepare dataset
# 0 1 为分类标签
# x_data 输入 学习的时间
# y_data 输出 考试通过与否(0 or 1)
x_data = torch.Tensor([[1.0], [2.0], [3.0],[1.1],[2.1],[1.5],[2.3],[4.1]])
y_data = torch.Tensor([[0], [0], [1],[0],[0],[0],[0],[1]])
class LogisticRegressionModel(torch.nn.Module):
def __init__(self):
super(LogisticRegressionModel, self).__init__()
self.linear = torch.nn.Linear(1,1)
def forward(self, x):
y_pred = torch.sigmoid(self.linear(x))
return y_pred
model = LogisticRegressionModel()
# construct loss and optimizer
criterion = torch.nn.BCELoss(size_average = True)
optimizer = torch.optim.Adam(model.parameters(), lr = 0.05)
# training cycle forward, backward, update
for epoch in range(10000):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(epoch, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (loss < 1e-7):
break
print('w = ', model.linear.weight.item())
print('b = ', model.linear.bias.item())
# test dataset
x_test = torch.Tensor([[4.0],[5.0],[1.5],[2.5],[2.9],[3.0]])
y_test = model(x_test)
print('y_pred = ', y_test.data)
🌈我的分享也就到此结束啦🌈
如果我的分享也能对你有帮助,那就太好了!
若有不足,还请大家多多指正,我们一起学习交流!
📢未来的富豪们:点赞👍→收藏⭐→关注🔍,如果能评论下就太惊喜了!
感谢大家的观看和支持!最后,☺祝愿大家每天有钱赚!!!欢迎关注、关注!