今天,为大家整理了C语言中几种常用的排序,以及他们在实际中的运用(有Bug请在下方评论):
一.桶排序
#include <stdio.h>
int main()
{
int book[1001],i,j,t,n;
for(i=0;i<=1000;i++)
book[i]=0;
scanf("%d",&n);
for(i=1;i<=n;i++)
{
scanf("%d",&t);
book[t]++;
}
for(i=1000;i>=0;i--)
for(j=1;j<=book[i];j++)
printf("%d ",i);
getchar();getchar();
return 0;
}桶排序是一种快速简单的排序,但实用性不强。工作的原理是将数组分到有限数量的桶子里。每个桶子再个别排序(有可能再使用别的排序算法或是以递归方式继续使用桶排序进行排序)。
二.冒泡排序
void bubblesort(int arr[], int sz)
{
int i = 0;
for (i = 0; i < sz-1;i++)
{
int j = 0;
for (j = 0; j < sz - 1 - i; j++)
{
if (arr[j] > arr[j + 1])
{
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
}
}
}
}
void print_arr(int arr[], int sz)
{
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
}
int main()
{
int arr[10] = { 9,8,7,6,5,4,3,2,1,0 };
int sz = sizeof(arr) / sizeof(arr[0]);
bubble_sort(arr, sz);
print_arr(arr, sz);
}
*冒泡排序核心部分是双重for循环,故空间占用较大。
冒泡排序的原理是:从左到右,相邻元素进行比较。每次比较一轮,就会找到序列中最大的一个或最小的一个。这个数就会从序列的最右边冒出来。
三.快速排序
#define _CRT_SECURE_NO_WARNINGS 1
#include <stdio.h>
void Quick_Sort(int a[], int l, int r) {
if (l < r) {
int i, j, x;
i = l;
j = r;
x = a[i];
while(i<j) {
while (i<j && a[j]>x) {
j--;
}
if (i < j) {
a[i++] = a[j];
}
while (i < j && a[i] < x) {
i++;
}
if (i < j) {
a[j--] = a[i];
}
}
a[i] = x;
Quick_Sort(a, l, i - 1);
Quick_Sort(a, i+1, r);
}
}
int main() {
int arr[] = { 9,5,1,6,2,3,0,4,8,7 };
Quick_Sort(arr, 0, 9);
for (int i = 0; i < 10; i++) {
printf("%d ", arr[i]);
}
printf("\n");
return 0;
}快速排序是最常用的一种排序,其思路为:
假设一个数组,我们可以用一种办法分成小数块和大数块,然后递归继续分成小数块和大数块,最后每一块都只有1个(或者0个)的时候,排序就完成了
四.计数排序
//注:引用自DYson~的博客
#include<stdio.h>
#include<assert.h>
#include<stdlib.h>
//计数排序
void CountSort(int *a, int len)
{
assert(a);
//通过max和min计算出临时数组所需要开辟的空间大小
int max = a[0], min = a[0];
for (int i = 0; i < len; i++){
if (a[i] > max)
max = a[i];
if (a[i] < min)
min = a[i];
}
//使用calloc将数组都初始化为0
int range = max - min + 1;
int *b = (int *)calloc(range, sizeof(int));
//使用临时数组记录原始数组中每个数的个数
for (int i = 0; i < len; i++){
//注意:这里在存储上要在原始数组数值上减去min才不会出现越界问题
b[a[i] - min] += 1;
}
int j = 0;
//根据统计结果,重新对元素进行回收
for (int i = 0; i < range; i++){
while (b[i]--){
//注意:要将i的值加上min才能还原到原始数据
a[j++] = i + min;
}
}
//释放临时数组
free(b);
b = NULL;
}
//打印数组
void PrintArray(int *a, int len)
{
for (int i = 0; i < len; i++){
printf("%d ", a[i]);
}
printf("\n");
}
int main()
{
int a[] = { 3, 4, 3, 2, 1, 2, 6, 5, 4, 7 };
printf("排序前:");
PrintArray(a, sizeof(a) / sizeof(int));
CountSort(a, sizeof(a) / sizeof(int));
printf("排序后:");
PrintArray(a, sizeof(a) / sizeof(int));
system("pause");
return 0;
}计数排序的基本思想是对于给定的输入序列中的每一个元素 x,确定该序列中值小于 x 的元素的个数(此处并非比较各元素的大小,而是通过对元素值的计数和计数值的累加来确定)。一旦有了这个信息,就可以将 x 直接存放到最终的输出序列的正确位置上。例如,如果输入序列中只有 17 个元素的值小于 x 的值,则 x 可以直接存放在输出序列的第 18 个位置上。当然,如果有多个元素具有相同的值时,我们不能将这些元素放在输出序列的同一个位置上,因此,上述方案还要作适当的修改。
五.基数排序
#include <stdio.h>
#include <assert.h>
#include <math.h>
#include <stdlib.h>
typedef struct Node
{
int data;
struct Node *next;
}Node,*List;
void InitList(Node *plist)
{
assert(plist != NULL);
plist->next = NULL;
}
Node *GetNode(int val)
{
Node *pGet = (Node *)malloc(sizeof(Node));
assert(pGet !=NULL);
pGet->data = val;
pGet->next = NULL;
return pGet;
}
void Insert_tail(Node *plist,int val)
{
assert(plist != NULL);
Node *p = plist;
while (p->next != NULL)
{
p = p->next;
}
Node *pGet = GetNode(val);
p->next = pGet;
}
bool DelHeadNode(Node *plist,int *res)
{
assert(plist != NULL);
Node *pDel = plist->next;
if (pDel == NULL)
{
return false;
}
*res = pDel->data;
plist->next = pDel->next;
free(pDel);
pDel = NULL;
return true;
}
int GetMaxBit(int *arr, int length)
{
assert(arr != NULL);
int max = INT_MIN;
for (int i = 0; i < length; i++)
{
if (arr[i] > max)
{
max = arr[i];
}
}
int digit = 0;
while (max != 0)
{
digit++;
max /= 10;
}
return digit;
}
int GetNum(int num, int figures) // 123 123 / 1 % 10 == 3 123 / 10 % 10 == 2 123 / 100 % 10 == 1
{
int base = pow((double)10,(figures));
return num / base % 10;
}
//figures --> 从右往左数第figures位的数字
void Radix(int *arr,int length,int figures)
{
Node head[10];
for (int i = 0; i < 10; i++)
{
InitList(&head[i]); // 初始化10个桶
}
int tmp = 0;
// 1、入桶 == 》 拿到数字,判断第figures位的数字为多少,并入相应的桶
int i = 0;
for (; i < length; i++)
{
tmp = GetNum(arr[i],figures); // 第figures位的数字为tmp
Insert_tail(&head[tmp],arr[i]); // 将 arr[i] 出到 tmp桶中
}
// 2、出桶
i = 0; // i 代表数组下标
int j = 0;
while (j < 10) // j 代表桶的个数
{
while (DelHeadNode(&head[j],&arr[i]))
{
i++;
}
j++;
}
}
void RadixSort(int *arr, int length)
{
int count = GetMaxBit(arr ,length);
for (int i = 0; i < count; i++)
{
Radix(arr,length,i);
}
}
void Show(int *arr, int length)
{
for (int i = 0; i < length; i++)
{
printf("%d ",arr[i]);
}
printf("\n");
}
void test(int *arr, int length)
{
RadixSort(arr,length);
Show(arr,length);
}
void test1()
{
int arr[] ={1,2,3,4,12,4444,2222,1112,11};
int length = sizeof(arr)/sizeof(arr[0]);
test(arr,length);
}
void test2()
{
int arr[] ={336,719,329,170,66,511,36,519,200,504};
int length = sizeof(arr)/sizeof(arr[0]);
test(arr,length);
}
int main()
{
test1();
test2();
return 0;
}基数排序与桶排序思路相仿,但优化了许多(也麻烦了许多,不太建议日常使用)
六.插入排序
示意图:
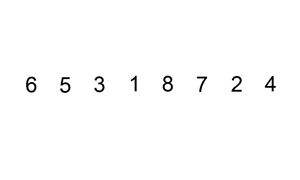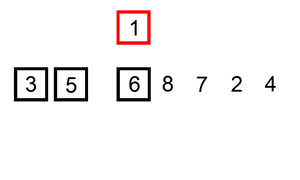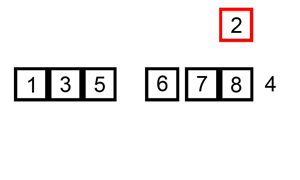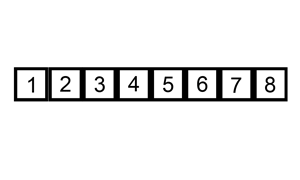
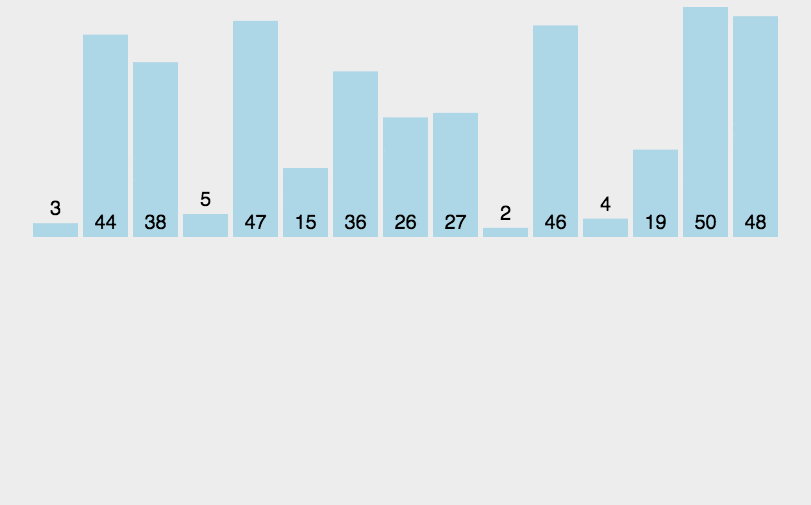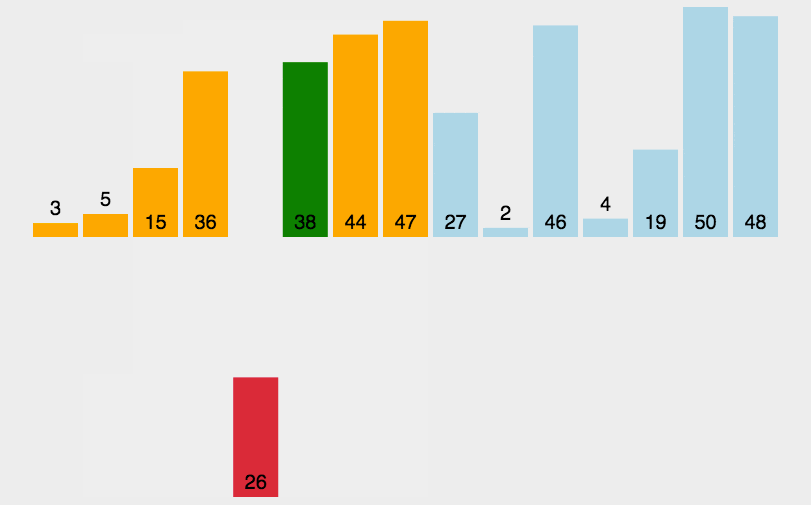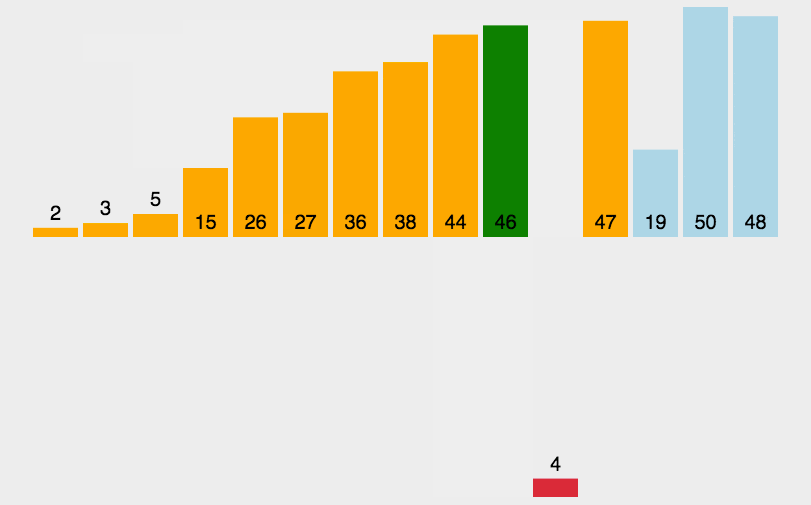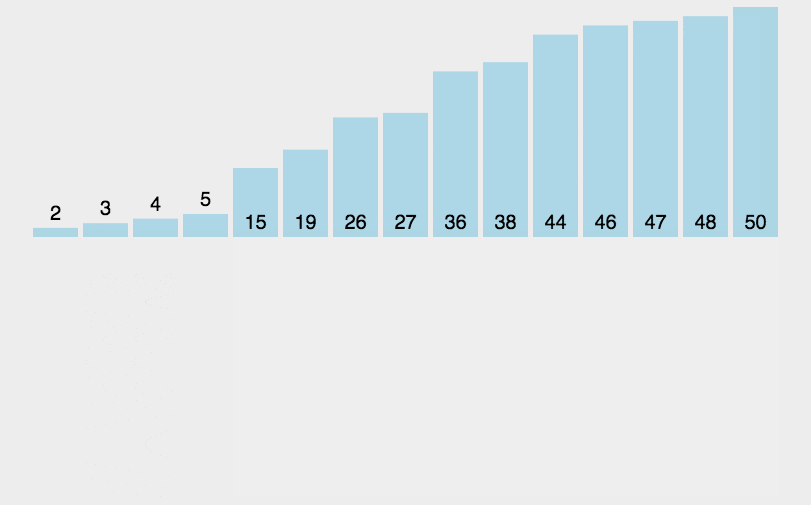
//插入排序(从小到大)
#include<stdio.h>
#include<stdlib.h>
int number[100000000]; //定义数组
void insertion_sort(int *number,int n) //定义一个插入函数"insertion_sort"
{
int i,t,temp;
for(i=1;i<n;i++) //外层循环遍历 (需要插入n个数)
{
temp=number[i]; //取未排序列的元素,有n个,从第一个开始取
for(t=i;t>0&&number[t-1]>temp;t--);
{
number[t]=number[t-1];//依次比较并右移
number[t]=temp;//放进合适位置
}
}
}
int main()
{
int i=0,n,j=0;
printf("输入数字个数:\n");
scanf("%d",&n); //输入要排序的数字的个数
printf("输入%d个数:\n",n);
for(j=0;j<n;j++) //将所有数全放入number数组中
scanf("%d",&number[j]) ;
insertion_sort(number,n); //引用插入函数
for(i=0;i<n-1;i++) //循环输出
printf("%d ",number[i]); //格式需要
printf("%d\n",number[i]);
system("pause");
return 0;
}
插入排序其实就是拿未排序数组中的第一个值,插入到已排序完中的数组的合适位置,来完成排序
七.堆排序
#include <stdio.h>
#include <malloc.h>
void HeapAdjust(int a[],int s,int m)//一次筛选的过程
{
int rc,j;
rc=a[s];
for(j=2*s;j<=m;j=j*2)//通过循环沿较大的孩子结点向下筛选
{
if(j<m&&a[j]<a[j+1]) j++;//j为较大的记录的下标
if(rc>a[j]) break;
a[s]=a[j];s=j;
}
a[s]=rc;//插入
}
void HeapSort(int a[],int n)
{
int temp,i,j;
for(i=n/2;i>0;i--)//通过循环初始化顶堆
{
HeapAdjust(a,i,n);
}
for(i=n;i>0;i--)
{
temp=a[1];
a[1]=a[i];
a[i]=temp;//将堆顶记录与未排序的最后一个记录交换
HeapAdjust(a,1,i-1);//重新调整为顶堆
}
}
int main()
{
int n,i;
scanf("%d",&n);
int a[n+1];
for(i=1;i<=n;i++)
{
scanf("%d",&a[i]);
}
HeapSort(a,n);
}堆排序的思想基于二叉树,比较麻烦
堆排序方法对记录较少的文件并不值得提倡,但对n较大的文件还是很有效的。