目录
前言
MySQL的数据结构
索引是一把双刃剑
索引创建原则
如何给一个列挑选索引?
索引列的基数, 要尽量小
索引列的类型尽量小
索引长字符串的前缀
不要对索引列进行计算操作或者函数计算.
不要老想着查询, 想想插入该怎么办?
避免索引冗余和重复
前言
今天在滴滴的2022后端开发的面试题里面看到了这个面试题:

但是下面网友发表的观点实在让人难以释怀 ....
这种:

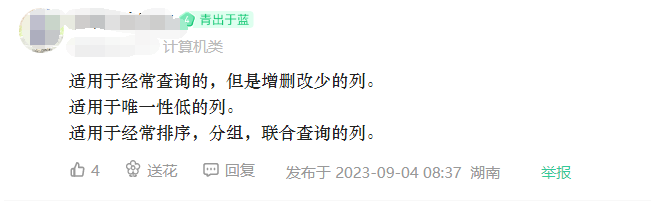
还有这种:

他们这些回答, 都达到点子上了, 但是也会遗漏一些基本的概念, 和索引使用原则. 或者是答得不太严谨, 例如 : 唯一性低的, 就不能加索引了吗? 数据量大, 就不能加索引了吗? 还有三楼这位电子科技大学的老哥, 什么交覆盖索引(聚簇索引)? 覆盖索引后面打了一个小括号解释, 覆盖索引就是聚簇索引?
看到这里, 本楼主倍感伤心, 看到这个回复时间, 也才离我现在不到半年吧. 本楼主接下来就会来解救大家.
首先我们来回顾一下MySQL的索引结构到底是怎么样的.
MySQL的数据结构
首先你得了解什么是二叉树吧, 这个概念希望你能自己去弄明白.
大家可以思考一下, mysql底层是通过磁盘 + 内存的形式存储数据的.
磁盘存储数据文件我当然知道, 那内存怎么也会存储数据? 别忘了, MySQL是具备查询缓存功能的, 也就是创建tcp连接之后的查询, 每次查询都会先去MySQL的内存缓存中查询是否存在对应的数据集, 如果有, 就直接返回, 减少了MySQL的运行压力, 如果没有, 那么就去innodb中查找.
如下, 这是我存储在磁盘下的一张表:

此表是通过innodb的存储引擎的形式存储的. 我们知道, innodb存储的表, 是通过两个文件来存储的, 如果你创建一个名为test的数据库, sql为:
create database test; 那么就会在你当前所使用的data目录底下创建一个test子文件夹:
里面存放着这个test数据库的所有数据, 然后我在这个test中创建表, 那么这个表的数据就会被存放在这个test文件夹中:
例如我创建一个名为t_car的表, MySQL就会为我创建下面两个文件:

- 其中.frm是存储的表结构, 一个表中有很多个列, 这个.frm文件就是存储的每个列的数据类型是什么呀, 有啥约束条件和索引呀, 以及他们的字符集和比较规则等等信息, 是以二进制文件存储的.
- ibd为后缀的文件, 就是我们存储实际数据的地方了, 也称之为独立表空间文件. 这个ibd文件比较特殊, 我们稍后讲解.
除了独立表空间之外, 我们在安装MySQL之后, 系统会为我们维护一些数据, 例如当前MySQL系统的状态之类的, 这些数据被存放在系统表空间之中.
首先这个独立表空间就是我们自己创建的表存放的文件, 既然一个表只存在两个文件, ,frm文件存放存储的表的结构, .ibd存放数据记录, 那么索引存放在哪? 那到底什么是索引?
首先回答第一个, MySQL在设计的时候, 针对于innodb搜索引引擎来说, 是将表的结构和数据分开存储在两个文件之中, 既然.frm存放表的结构, MySQL中的ibd文件就是用来存放数据和索引结构的. 当然你也可以说, 数据是需要有组织的存放的, 不是一条一条的存放成链表这种简单的形式.
我们可能是需要把这些数据维护成一种特殊的查询数据结构, 才可以很快的进行查询操作.

上图中的每一个蓝色或者浅蓝色的就为一个数据页或者索引页, 索引页只存放当前索引列和页号, 数据页则存放索引列和主键id.
我们都知道, MySQL存在聚簇索引和非聚簇索引两大类, 那么什么是聚簇索引?
innodb会自动为主键创建全列索引, 也就是以b+树的形式创建索引, 叶子结点存放的是全部列的数据, 如果没有主键, 那么MySQL就会为当前表中unique索引创建聚簇索引, 如果你都未指定, 那么MySQL会隐式的帮你维护一个主键并以此创建聚簇索引, 无论以哪种方式创建, 其都会为你以全列的形式进行排序. 也就是说, 我们通过聚簇索引, 就可以找到这种表中的任何信息.
那非聚簇索引呢?
非聚簇索引就是指的二级索引(没有被用来创建聚簇索引的索引, 例如unique, index), 此时MySQL也会创建一个b+树来进行维护, 只不过此时叶子结点存放的事主键+ 索引列的数据, 然后对索引列进行排序的一个数据结构.
上述两个索引, 都是存放在ibd这个后缀的文件之中的.
如果是利用二级索引来查找, 那么就是根据二级索引列的b+树结构, 快速找到对应的数据页, 然后再数据页中进行查找, 找到对应的数据记录, 只不过现在的二级索引数据记录只存放了索引列和对应数据的id, 如果你仅仅只是查找当前这个索引列和id这一个数据, 那么就会触发回表操作, 但是如果你还存放别的数据, 是当前索引列中没有的, 那么就会触发回表, 到聚簇索引中根据主键id来查询数据.
索引是一把双刃剑
既然可以让查询变快, 那么我给每一列创建一个索引就完事了. 真的完事了吗?
在空间上, 显而易见, 你每给一个列创建索引, 就会在ibd后缀的文件中创建一个b+树, b+树的每一个数据页和索引页, 都会占用一定的磁盘空间,
在时间上, 红黑树你总应该了解吧, 我每次删除一个红黑树结点, 就不得不去旋转, 以此来平衡树的高度, 每次对表中的数据进行增、删、改操作时,都需要去修改各个B+ 树索引。而且我们讲过, B+ 树每层节点都是按照索引列的值从小到大的顺序排序而组成了双向链表。不论是叶子节点中的记录,还是内节点中的记录(也就是不论是用户记录还是目录项记录)都是按照索引列的值从小到大的顺序而形成了一个单向链表。而增、删、改操作可能会对节点和记录的排序造成破坏,所以存储引擎需要额外的时间进行一些记录移位,页面分裂、页面回收啥的操作来维护好节点和记录的排序。如果我们建了许多索引,每个索引对应的B+ 树都要进行相关的维护操作,这还能不给性能拖后腿么?
说了这么多, 既然索引创建有这么多坏处, 那我到底该什么时候创建索引?
索引创建原则
我们创建一个索引, 除了考虑时间和空间上的差异, 还要了解, 索引是怎么生效的, 其实索引就是讲对应的索引列进行排序, 然后将其分为很多个数据页, 一个数据页(16kb)可能存放很多个记录, 然后通过类似于查字典的形式(你想想, 英语词典里面的单词, 是乱序的嘛, 肯定不是啊, 是通过首字母进行总体的排序, 基于第一个字母排序的原则, 然后根据第二个字母排序, 以此类推), 通过不断的缩小数据所在的区间, 然后到了最小的数据页级别的时候, 就采用二分查找等高效的查询方式, 快速定位到数据记录.
如果你在使用索引的时候, 没有使用到原本索引列就是有序的这个原则, 那么索引就会实效.
就拿我们的多列索引来举例子, 下面有一个表为:
CREATE TABLE `t_car` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增主键',
`car_num` varchar(255) DEFAULT NULL COMMENT '汽车编号',
`brand` varchar(255) DEFAULT NULL,
`produce_time` char(10) DEFAULT NULL,
PRIMARY KEY (`id`),
index idx_carnum_brand_pt(car_num, brand, produce_time)
) ENGINE=InnoDB AUTO_INCREMENT=27 DEFAULT CHARSET=latin1这个表有四个字段:
- 主键id
- car_num : 汽车编号
- brand : 汽车品牌
- produce_time: 汽车生产时间
拥有两个索引:
- 一个是主键的聚簇索引
- 一个是关于car_num, brand, produce_time, 并依次为顺序的多列索引.
分析:
上面所述的多列索引, 就是通过carnum先排序, 然后在carnum的有序的基础上, 然后再通过brand排序, 然后在前面两个都有序的情况下, 然后再通过produce_time来进行排序.
为什么说, 多列排序需要遵循最左前列 或者是 最左匹配原则?
其原因就是因为排序的问题, 我有下面几个记录:

如果我要查找produce_time = 15:06:52的这个记录, 那么请问我可以用到索引吗? 当然不行, 因为你以上来就是掺杂后produce_time, 但是我们的produce_time不是有序排列的, 首先你的得确认car_num = 1481389857的记录的位置, 然后才能根据brand来查找吧, 因为brand是有序的, 所以你也能很快的确认brand的位置. 然后再去在相同的brand中查找produce_time.
如何给一个列挑选索引?
基于索引的数据结构和 创建原则, 这里有如下几点:
索引列的基数, 要尽量小
基数:
- 在数学和集合论中,基数用来表示集合中元素的数量。两个能够建立元素间一一对应的集合称为互相对等集合,它们的基数相等。例如,一个包含三个元素的集合和另一个也包含三个元素的集合,无论这两个集合中的元素是什么,它们的基数都是三
- 在数据库中: 某一列的唯一键(distinct Keys)的数量叫作基数。例如,性别列只有男女之分,那么这一列的基数就是2。而主键列的基数等于表的总行数。选择性是列的基数与表中总行数的比值,它可以衡量数据库索引能够帮助缩小对表中特定值的搜索范围的程度。
所以说, 基数值越大, 一个索引列的重复性就越小, 那么此索引性能就越高 .
有人肯定要问, 不是哥们, 这跟基数有什么关系啊. 不是排好序的嘛, 对没错, 正是因为排序, 才导致数据重复性过高, 不能通过索引列快速的接近真正的我们需要的记录项. 我举个例子
有一个多列索引为 index(sex, age, name), 然后我想通过sex和age和name来找一个人, 假设叫张三, 那么就是用这个索引, 首先索引是先根据sex来排序, 然后才是age进行排序, 然后再是name, 那么我要使用索引, 就需要首先进行sex字段的搜索, 但是你想一下, sex只有两种可能, 那么基于sex的排序就只有男和女, 因此就相当于你要在男生中去找张三. 这样效率肯定低.
假设你是100个班的班主任, 假设一个班50个人, 每个班平均男女25人你要在这一百个班中找到张三, 那么你喜欢现根据性别筛选出男女, 然后找到张三, 还是说先通过班级, 然后通过性别, 然后通过名字来找到张三? 无疑是后一种吧. 那么你就直接定位到张三所在的班, 然后通过性别, 筛选出25人, 然后通过这25人里面确认张三的名字即可.
但是如果你筛选出男女, 那就是2500个人中找到张三. 这效率显然是不一样的.
索引列的类型尽量小
这个类型, 就是指的所谓的数据类型, 例如int, tinyint, bigint, 等, 还有字符串类型, 例如varchar, char类型等.
尽量小的意思就是: 能使用tinyint, 就尽量不要使用int类型来作为索引列的类型, 能使用char(2), 就尽量不要使用char(10).
为什么? 这是因为:
- 数据类型越小, 在查询的时候, 进行比较的操作就越快
- 数据类型越小, 索引建立的所占用的空间就更少. io成本也就越少.
我尝试来解释一下为什么这会比较操作更快以及为什么io成本就越少:
- 首先对于整数来说, 在进行比较大小的时候, 是通过做减法, 然后进行标记来判断大小的, 就要涉及到计算机组成原理了, 我们知道计算机组成原理中, 两个int类型做减法, 可以看做是一个数加上另外一个数的相反数, 是需要先将减数转换为补码, 然后与被减数做相加操作. 然后根据得到的数, 来判断大小, 因此来进行排序或者比较, 因此, 数位越低, 转化为补码, 进行减法操作的效率就越高.
如果是字符串, 在mysql中进行查找的时候, 是进行字符串的比较, 两个字符串从第一个字符开始, 依次往后比较其字段顺序. 你想像, 如果你的字符串越短, 是不是存储的数据就更少, 两个字符串长度为5的比较所消耗的cpu资源肯定是比两个长度为10的字符串比较要少的. - 那么io成本呢? 我们知道,mysqlio的单位是数据页, 也就是更短的数据类型, 一个数据页可以存放更多的数据, 此时, 每次io的成本也就越小.
索引长字符串的前缀
字面意思就是给比较长的字符串加索引的时候, 如果你给他这一列所有的内容都加索引的花, 那么存储的开销就太大了. 一个字符串可能太长了, 一个数据页都装不下这种, 那么就可能会出现这几种情况:
- 占用大量的空间, B+树索引中的记录, 需要把该列的完整字符串存储起来, 那么假设我一个字符串有几mb或者是gb呢? 那么本来聚簇索引中就存在这个数据了, 我还要在非聚簇索引中存一份相同大小的数据, 那么是不是太浪费空间了.
- 其次我们上面提到, 字符串在索引中进行比较的时候, 是从第一个字符开始, 一个一个往后比较, 那么此时, 使用索引将会带来更大的字符串比较的成本.
其实我们也知道, 我们没必要让所有的字符都参与到索引中, 我们可以给这一个字符串的前缀建立索引. 这样, 虽然重复的概率提升了, 虽然不能直接进行精准的找到想要的长字符串, 但是我们可以通过前缀索引, 找到符合前缀索引的id集合, 然后根据id到主键回表去找到对应的完整的长字符串即可.
这种前缀索引, 比起直接索引长字符串, 有几个好处:
- 占用空间小, 我的索引列只存放部分字符串, 而不是所有的字符串
- 字符串的存放的长度变小了, 使用索引进行字符串比较的位数就少了, 效率更高了.
提一嘴, 如何使用建立前缀索引:
CREATE TABLE person_info(
name VARCHAR(100) NOT NULL,
birthday DATE NOT NULL,
phone_number CHAR(11) NOT NULL,
country varchar(100) NOT NULL,
KEY idx_name_birthday_phone_number (name(10), birthday, phone_number)
);name(10)
注意 :
我们知道前缀索引是基于索引列的字符串的前几个字符进行排序的(前几个取决于我们规定是前几个字符). 此时如果你有如下语句:
select * from person_info order by name limit 10;那么会带啦什么问题? 我们知道此时的name索引里面存储的部分字符串, 此时, 如果我设置name(10), 也就是将name的前10个字符作为索引列. 此时, 如果我排序的前10个数据的前10个字符都是一样的, 那么这10个字符后面剩余的字符该如何排序? 我们不知道呀, 因为只存放了前10个数据, 所以我们无法判断, 哪个索引列对应的完全长字符串是排在前面的, 此时就不能使用到这个name索引了.
此时的索引本身满足表不了这个排序的需求, 此时想要排序, 就只能通过文档排序, 也就是file sort, 通过磁盘的方式进行排序.
不要对索引列进行计算操作或者函数计算.
下面有连个例子, 假设where中字段(key 不一定是int或者是字符串)都是非聚簇索引:
- where key * 2 < 4;
- where lower(key) = 'example@example.com';
第一个例子是对key 乘以 2, 然后去和4进行比较, 第二个是将key转化为小写, 然后去和后面的邮箱字符串进行比较. 这样做, 会让存储引擎会识别不了, 因为他们不知道key * 2 是否比当前的4小, 也不知道当前的字符串全部转化为小写之后, 是否就等于'example@example.com', 因此存储引擎会对索引进行全列扫描, 然后每一条记录都去做计算, 然后跟后面的内容进行比较.
当然如果你对非索引列进行计算, 查询优化器会自动帮你算出来, 或者说是化简.
例如: where key < 4 / 2 -> where key < 2;
不要老想着查询, 想想插入该怎么办?
我们知道, 向一个表中插入数据是由聚簇索引来维护的, 聚簇索引是根据主键排序的, 此时, 如果你插入的主键不是依次递增的话, 那么就会额外的消耗性能, 为什么这么说?
我们存储数据的部分是数据页, 一个数据页是16kb, 可以存放的数据是有限的, 此时假设我现在拥有一个数据页, 里面存放着主键为 1 , 3 , 4 , 5, 6, 8, 9的数据, 就这么几条, 假设我现在此数据页的空间已经吃满了, 已经无法存放任何的记录了, 那此时, 如果我要插入一个主键为7的数据, 该怎么办啊. 数据页又装不满, 这个时候, 就只能把这个数据页给拆成两份了, 这个拆分的过程就代表性能消耗啊.
所以在创建主键的时候, 应该让主键自增, 也就是auto_increment
避免索引冗余和重复
经过前面的探讨, 我们已经知道, 索引并不是越多越好, 索引会占据额外的磁盘空间, 在插入的时候, 会消耗额外的性能资源, 所以我们应该避免重复的索引, 这个重复, 具体体现在什么地方?
例如:
- 你拥有一个表, 其中又name字段, age字段和birth字段, 这三个字段, 其中你建立了一个多列随你和单列索引. 单列索引以name为索引列, 多列索引以name, age, birth为索引列, 此时, 如果你不是用使用age和birth这两个字段的话, 那么多列索引就是多余的. 因为不管是单列还是多列的name都是再起各自的b+树中排好序的, 除非你要使用到age和birth.
这里总结的差不多了, 各位老哥还有什么要补充的? 欢迎留言, 我会听取您的留言并对本文做出改正!! 感谢!!