目录
在Windows上配置环境
在Ubuntu上配置环境
装虚拟机
全屏问题
中文输入 --- 搜狗输入法
将Windows上文件传输给ubuntu --- winscp
分配内存给根目录
深夜惊魂,ubuntu根目录空间不足 - 知乎
给conda或者pip换源
安装anaconda+python+pycharm
下载安装anaconda
下载安装pycharm
配环境
pytorch
pycocotools
VOC2007数据集
组织结构
Annotations
ImageSets
JPEGImages
SegmentationClass
SegmentationObject
跑faster-rcnn
在Windows上配置环境
因为在这个作者的代码里有resource库,它不支持windows上的运行,并且我看的另外一个作者基于faster-rcnn论文的代码也是建议在Ubuntu或者是Centos上跑,所以在耗了一个下午之后我还是决定搬到Ubuntu上跑faster-rcnn了
解决 No module named 'resource' 问题_yeverwen的博客-CSDN博客

转战Ubuntu了
耗时一个下午主要是在配置过程里出现很多奇奇怪怪的问题,有一个就是torchnet一直安装不成功。
试过多次坑之后总结win10安装torchnet的方法_torchnet怎么导入_在西湖雾雨中起舞的博客-CSDN博客
这是一篇详细的功课博,但最后我的解决方法兜兜转转,在pycharm里面pip install torchnet成功了
在Ubuntu上配置环境
在这里出现了很多悲惨的事情,因为Ubuntu内存不够我直接拓展了磁盘内存,把Ubuntu搞崩了
只能把原来的虚拟机卸载了重新来
装虚拟机
阿里云的ubuntu20.04镜像网站
ubuntu-releases-20.04安装包下载_开源镜像站-阿里云
装虚拟机过程还是比较简单哒,不多赘述了~
还有一些鸡零狗碎的小问题,解决方法记录如下
全屏问题
Ubuntu无法全屏问题完美解决(超简便的方法)_青山青的博客-CSDN博客_ubuntu安装屏幕太小无法全屏
中文输入 --- 搜狗输入法
搜狗输入法官网有教程
搜狗输入法linux-安装指导
唯一一个可能要注意的就是最后装完,要在右上角的键盘设置那里把搜狗输入法提到最上面面
将Windows上文件传输给ubuntu --- winscp
使用WinSCP连接虚拟机主机,提示“网络错误拒绝连接”_winscp网络错误_Jianzhugong_的博客-CSDN博客
分配内存给根目录
深夜惊魂,ubuntu根目录空间不足 - 知乎
ubuntu 16.04根目录磁盘空间扩容(亲测!!)_fire_lgh的博客-CSDN博客_乌班图根目录扩容
不过我在划分给根内存的时候一开始一直划不过去,看了很多文章划了很多次之后,我顿悟,是我一直都扩容的是盘中盘
给conda或者pip换源
用本身的conda源下载安装真的真的非常慢,而且一慢就经常超时出错,换源之后速度起飞
Linux下安装、配置、使用conda环境(教程详细,亲测无误)_linux安装conda_6uv!6!Hz的博客-CSDN博客
安装anaconda+python+pycharm
下载安装anaconda
在anaconda官网下载linux版本
Linux系统新手指南: 7. Python环境搭建, Anaconda安装, IPython, Jupyter Notebook使用。_哔哩哔哩_bilibili
且anaconda在linux下创建环境使用
注:激活环境使用source activate env_name
Linux系统 conda 创建python虚拟环境_wldong_9012的博客-CSDN博客
下载安装pycharm
在 Linux 环境下安装 Pycharm_Echo.斜杠青年的博客-CSDN博客_linux安装pycharm
注:在把pycharm安装到桌面的时候,会报错提示没有权限
需要把下面这个命令
gedit /usr/share/applications/Pycharm.desktop
改成
sudo gedit /usr/share/applications/Pycharm.desktop
装完这俩就跟Windows一样配好虚拟环境
配环境
pytorch
在Anaconda下安装Pytorch的超详细步骤_伏城无嗔的博客-CSDN博客_anaconda pytorch
其他都是一样的pip install
除了这个skimage 应该是 scikit-image
pycocotools
安装pycocotools烦死了 - 知乎
VOC2007数据集
VOC数据集简介与制作_AI路上的小白的博客-CSDN博客_voc数据集
目标检测数据集PASCAL VOC详解 - 知乎
PASCAL VOC 2007数据集的简单介绍 - 知乎
VOC2007数据集详细分析_51CTO博客_voc2007数据集
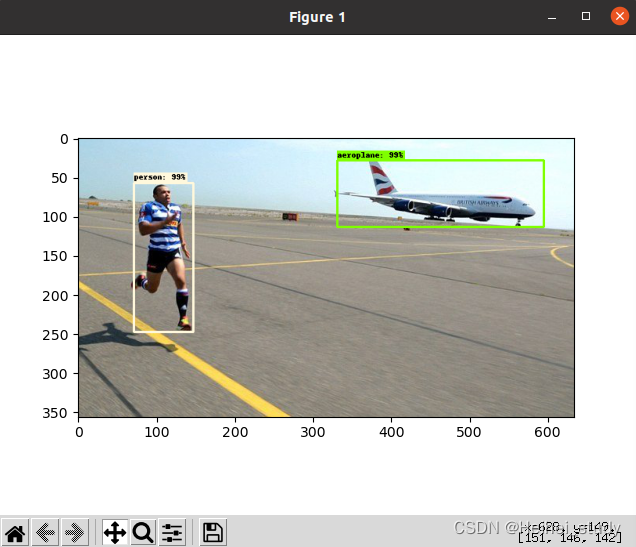
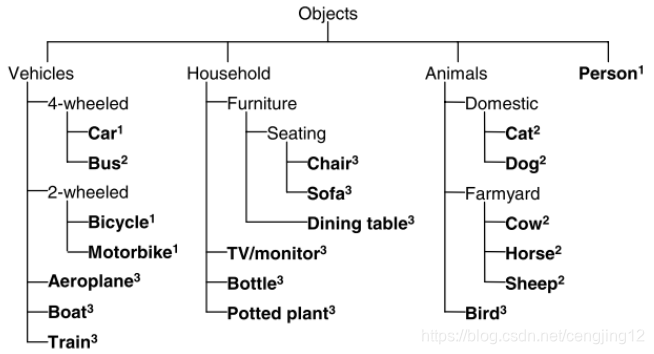
PASCAL VOC 2007 和 2012 数据集总共分 4 个大类:vehicle、household、animal、person,总共 20 个小类(加背景 21 类),预测的时候是只输出下图中黑色粗体的类别。
组织结构
└── VOC2007 #不同年份的数据集
├── Annotations #存放xml文件,与JPEGImages中的图片一一对应,解释图片的内容等等
├── ImageSets #该目录下存放的都是txt文件,txt文件中每一行包含一个图片的名称,末尾会加上±1表示正负样本
│ ├── Action
│ ├── Layout
│ ├── Main #存放的是分类和检测的数据集分割文件
│ └── Segmentation
├── JPEGImages #存放源图片
├── SegmentationClass #存放的是图片,语义(class)分割相关
└── SegmentationObject #存放的是图片,实例(object)分割相关Annotations
这个文件夹里都是.xml文件,文件名是图像名称,如下图所示。每个文件里面保存的是每张图像的标注信息,训练时要用的label信息其实就来源于此文件夹。
比如在JPEGImages文件下这个000001.jpg图像
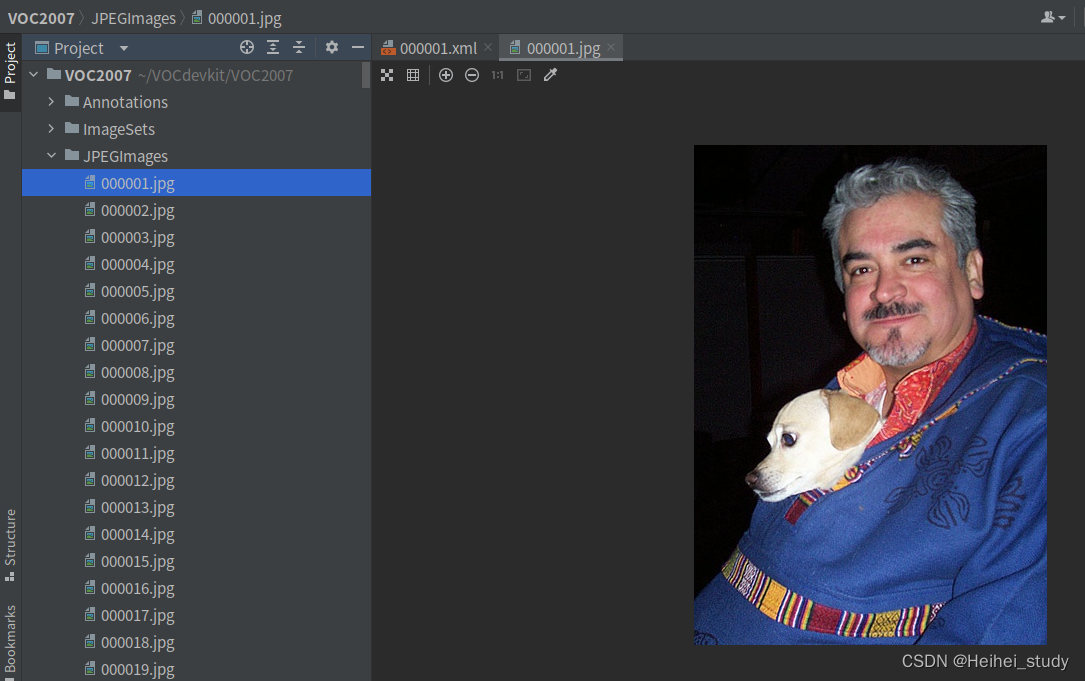
对应Annotations里的000001.xml文件
可以看见在这个xml文件里检测出的object分类就是dog和person

ImageSets
这个文件夹里面是图像集合 ,打开之后有3个文件夹:Layout 、 Main、 Segmentation,这3个文件夹对应的是 VOC challenge 3类不同的任务。
其中Main文件夹存放的是用于分类和检测的数据集分割文件,Layout文件夹用于 person layout任务,Segmentation用于分割任务。
Main:每一类别在train或val或test中的ground truth,这个ground truth是为了方便classification 任务而提供的;如果是detection的话,使用的是上面的xml标签文件。
例如aeroplane这个类别
├── Main
│ ├── aeroplane_test.txt 写着用于训练的图片名称 共2501个,指定正负样本
│ ├── aeroplane_train.txt 写着用于验证的图片名称 共2510个,指定正负样本
│ ├── aeroplane_trainval.txt train与val的合集 共5011个,指定正负样本
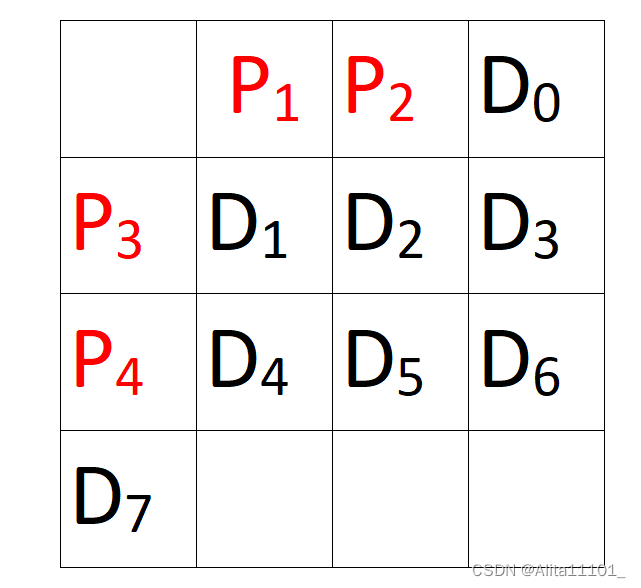
│ ├── aeroplane_val.txt 写着用于测试的图片名称 共4952个,指定正负样本里面文件是这样的(以aeroplane_train.txt为例):
000012 -1
000017 -1
000023 -1
000026 -1
000032 1
000033 1
000034 -1
000035 -1
000036 -1
000042 -1
……
……
009949 -1
009959 -1
009961 -1前面一列是训练集中的图片名称,这一列跟train.txt文件中的内容是一样的,后面一列是标签,即训练集中这张图片是不是aeroplane,是的话为1,否则为-1。
- 0 表示图像中包含aeroplane对象但是难识别样本
- 1 表示图像中包含aeroplane
- -1 表示图像中不包含aeroplane
JPEGImages
所有的原始图像文件,格式必须是JPG格式
SegmentationClass
这个文件夹里面保存的是专门针对Segmentation任务做的图像,里面存放的是Segmentation任务的label信息。
SegmentationObject
这个任务叫做Instance Segmentation(样例分割),就同一图像中的同一类别的不同个体要分别标出来,也是单独给的label信息,因为每个像素点要有一个label信息。
跑faster-rcnn
因为第一个跑的代码visdom显示不出来,我也还不会用tensorboard,所以就换了一个代码
deep-learning-for-image-processing/pytorch_object_detection/faster_rcnn at master · WZMIAOMIAO/deep-learning-for-image-processing · GitHub
各项库装完之后,跑train.py会闪退
所以就用了作者训练好权重直接跑predict.py文件