文章目录
- 一.概述
- 二.Cache与主存的映射方式
- 1.直接映射
- 2.全相联映射
- 3.组相联映射
- 三.Cache中主存块的替换算法
- 1.随机算法RAND
- 2.先进先出算法FIFO
- 3.最近最少使用算法LRU
- 4.最不经常使用算法LFU
- 四.Cache写策略
- 1.写命中
- 2.写不命中
一.概述
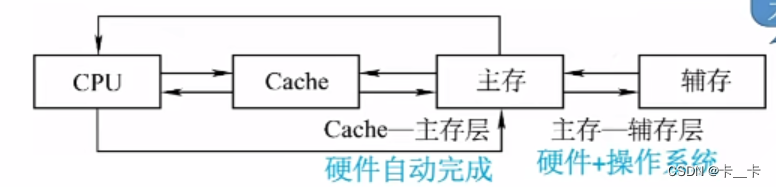
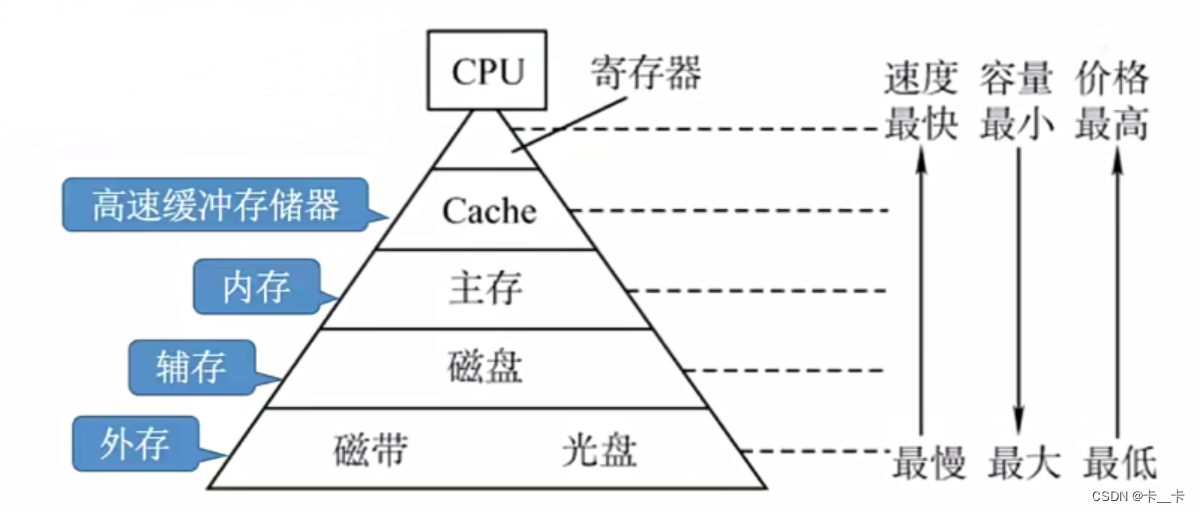
高速缓冲存储器(Cache):介于主存和CPU之间,用来存放正在执行的程序段和数据,以便CPU能高速地使用它们。
Cache的存取速度和CPU的速度相匹配。容量小,价格高,速度介于主存和CPU之间。现代计算机通常将其制作在CPU中。
1.局部性原理
(1)空间局部性
在最近的未来要用到的信息(指令和数据),很可能与现在正在使用的信息在存储空间上是邻近的。如数组元素、顺序执行的指令代码
(2)时间局部性
时间局部性:在最近的未来要用到的信息,很可能是现在正在使用的信息。如循环结构的指令代码
2.平均访问时间
设访问一次Cache所需时间为A,访问一次主存所需时间为B;欲访问信息在Cache中的比率(命中率)为P,未命中率(缺失率)为1-P
①先访问Cache,未命中再访问主存:Cache-主存系统的平均访问时间=AP+(1-P)(A+B)
②同时访问Cache和主存:平均访问时间=AP+B(1-P)
3.基于局部性原理,可以把主存的存储空间分块(如1KB),主存和Cache间以块为单位进行数据交换。当访问某一地址时,将整个块的信息调入Cache(每次被访问的主存块,一定会被立即调入Cache)
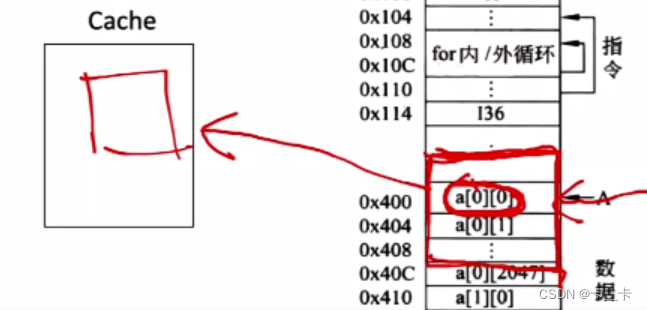
将主存空间分块,Cache也分为大小相同的块
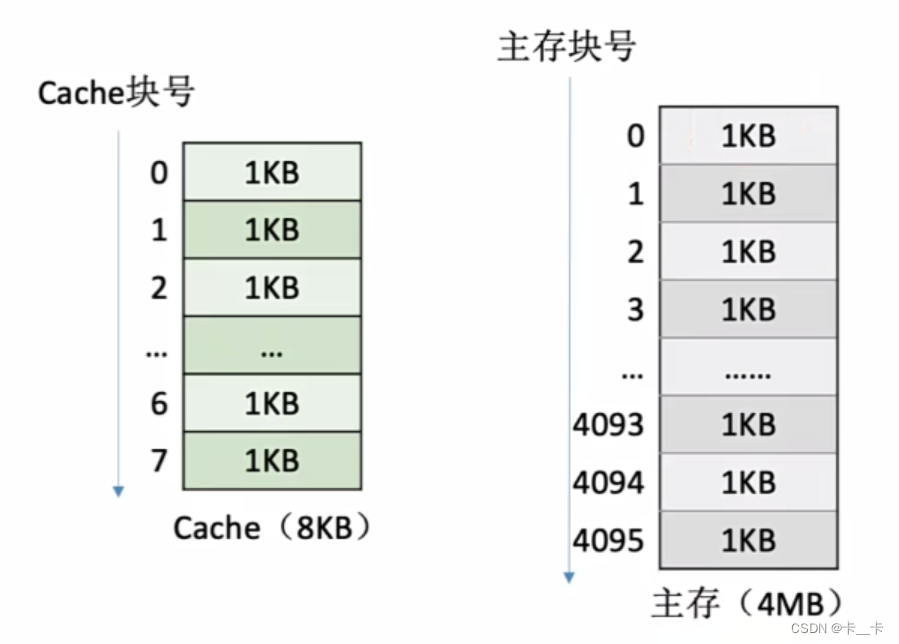
主存地址可以用(块号,块内地址)表示
主存的“块”又叫“页/页框/页面”;Cache的“块”又叫“行”
二.Cache与主存的映射方式
解决主存和Cache数据块的映射关系(对应关系)。
1.直接映射
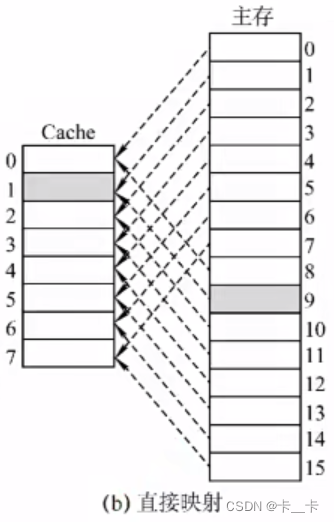
主存中的每一个块只能装入Cache中的唯一(特定)位置。若该位置有内容,则替换出去。
优点:实现简单
缺点:不够灵活,可能造成冲突且冲突概率高,即使后面有空间也可能不用,空间利用率低
装入位置(Cache块号)=主存块号%Cache总块数
地址结构(标记,Cache行号,块内地址)
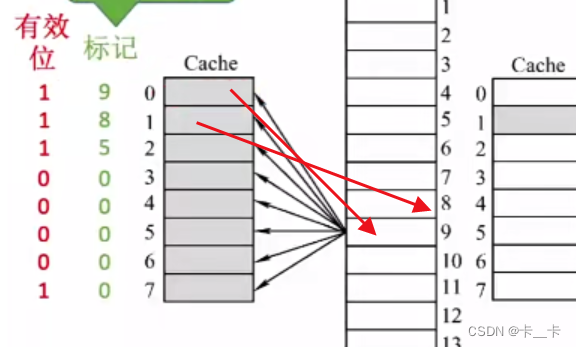
①标记:用来记录当前Cache块存放的数据来自于哪个主存块,若当前空闲标记记录为0(为防止看成是来自于0号主存块,需要增加有效位表示是否有效。如有效位1,标记0,表示当前来自于0号主存块;有效位0标记0表示当前块空闲)。
注:标记用二进制位表示,位数与主存块号位数相同。一般Cache的行数是2的整数次幂,即Cache行数=2n,即主存块号末尾的n位表示存储在Cache的行数(如n=3,主存块号末尾3位表示存储在Cache的哪一行,对于0、8…的末尾3位都是0,都存储在第0号Cache块)。可以看出,主存块号末尾的n位直接反应了它在Cache中的位置,因此为节省存储空间,标记可不存储主存块号的末尾n位,将其余位作为标记即可
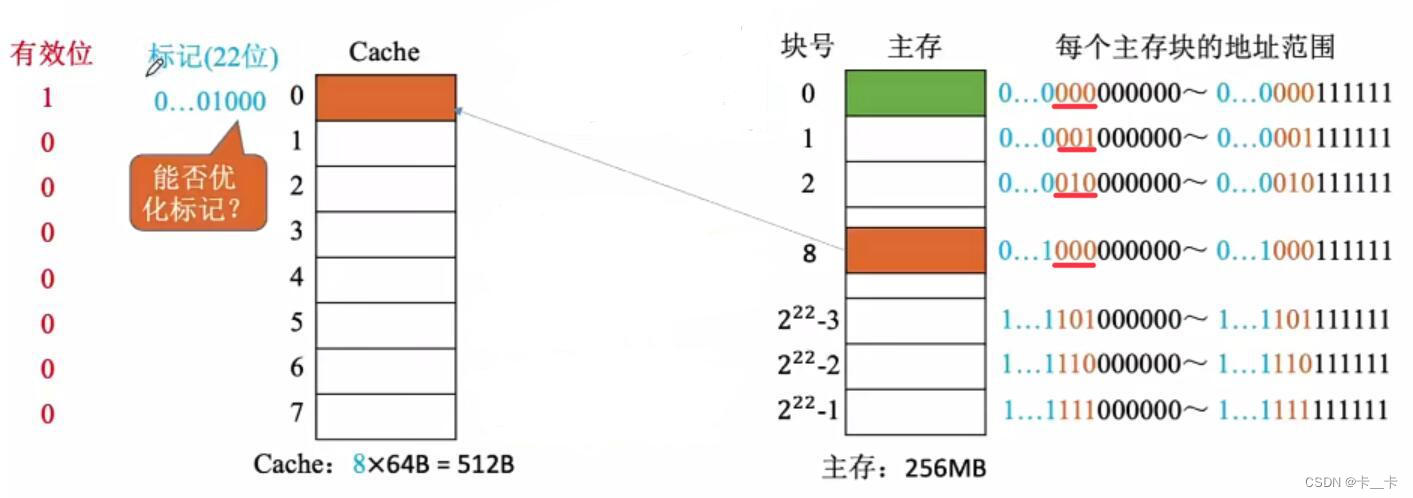
在此例中将地址结构进一步划分
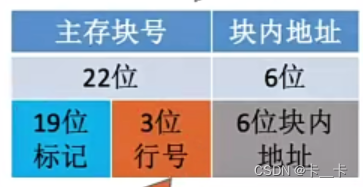
②Cache行号:对Cache各块从0开始编号。主存的第0、1、2、3号块依次映射到Cache块的第0、1、2、3行
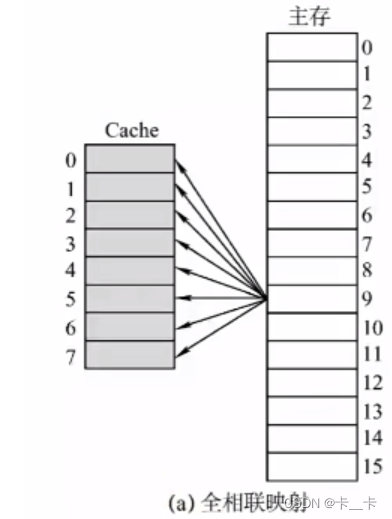
2.全相联映射
主存中的每一块可以装入Cache中的任何位置,每行的标记用于指出取自主存的哪一块,所以CPU访存时需要与所有Cache行的标记进行比较。如:主存块号22位,块内地址6位。当CPU访问某主存地址时,将前22位和Cache的标记对比,若相同,再检查有效位,若有效即可访问块内地址指定的地址单元。若Cache未命中,则正常访问主存查找。
优点:比较灵活,Cache块的冲突概率低,空间利用率高,命中率高
缺点:标记比较的速度较慢,实现成本高。通常需要采用按内容寻址的相联存储器进行地址映射
地址结构:(标记,块内地址)
3.组相联映射
将Cache空间分成大小相同的组,主存的一个数据块可以装入一组内的任何位置,即组间采用直接映射(指定),组内采取全相联映射(任意)。
组号=主存块号%分组数
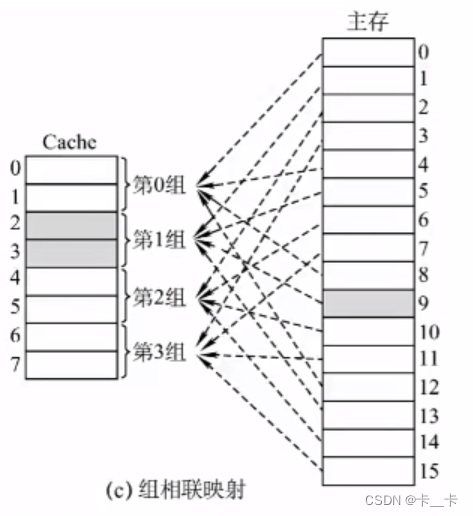
2路组相联映射:两个Cache块为一组,在此例中Cache被分为四组,即22,因此可以通过主存块号的最后两位判断属于哪个分组
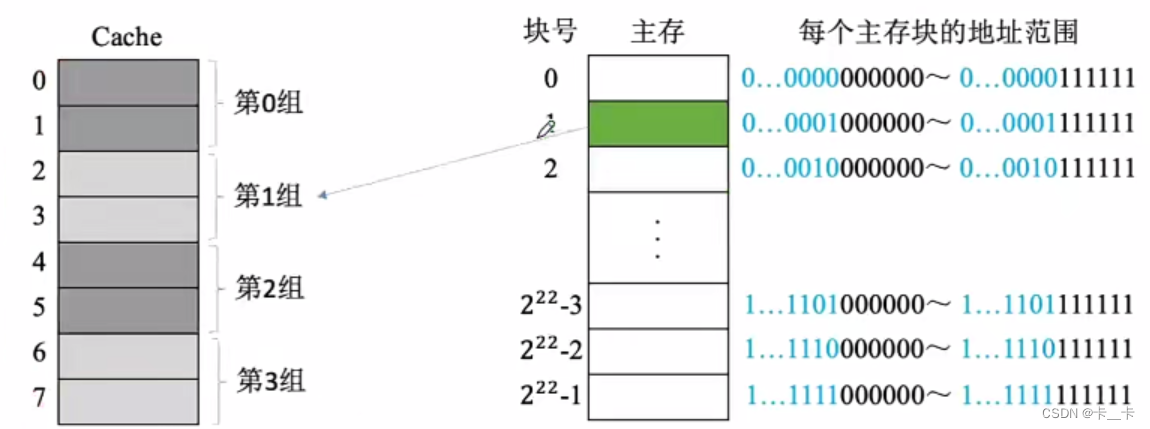
CPU访存时,先找属于哪个分组(根据主存块号后n位判断),然后在指定分组中逐块对比,找到后检查有效位,若有效,即可访问块内地址指向的存储单元。若未命中则正常访问主存
三.Cache中主存块的替换算法
Cache很小,主存很大。如果Cache满了,需要使用替换算法换入和换出。直接映射不需要考虑替换算法,全相联映射当Cache全满时才需要替换(全局替换),组相联映射当组满时才需要替换(组内替换)。
分为随机算法RAND、先进先出算法FIFO、最近最少使用算法LRU、最不经常使用算法LFU
对比操作系统的页面置换算法:最佳置换算法OPT、先进先出页面置换算法FIFO、最近最久未使用置换算法LRU、时钟置换算法CLOCK / 最近未用算法NRU、改进型时钟置换算法
操作系统的页面置换算法见:3-2内存管理-虚拟内存
1.随机算法RAND
随机确定替换的Cache块。实现简单,可能命中率较低。
2.先进先出算法FIFO
选择最早调入的行进行替换。实现容易,但最早调入的主存块可能也是最经常使用的
抖动现象:频繁的换入换出现象(刚被替换的块很快又被调入)
3.最近最少使用算法LRU
Least Recently Used
往前找最近未使用过的块(手算)。选择近期内长久未访问过的Cache行作为替换的行。命中率比FIFO高,遵循了局部性原理,是堆栈类算法。若频繁访问主存块的数量大于Cache行的数量,也会产生抖动现象。
也可每行设置一个计数器(初始为0)(机器计算方式)
优势:Cache块的总数=2n,则计数器只需n位。且Cache装满后所有计数器的值一定不重复
规则:
①命中时,所命中的行的计数器清零,比其低的计数器加1,其余不变
②未命中且还有空闲行时,新装入的行的计数器置0,其余非空闲行全加1
③未命中且无空闲行时,计数器值最大的行的信息块被淘汰,新装行的块的计数器置0,其余全加1
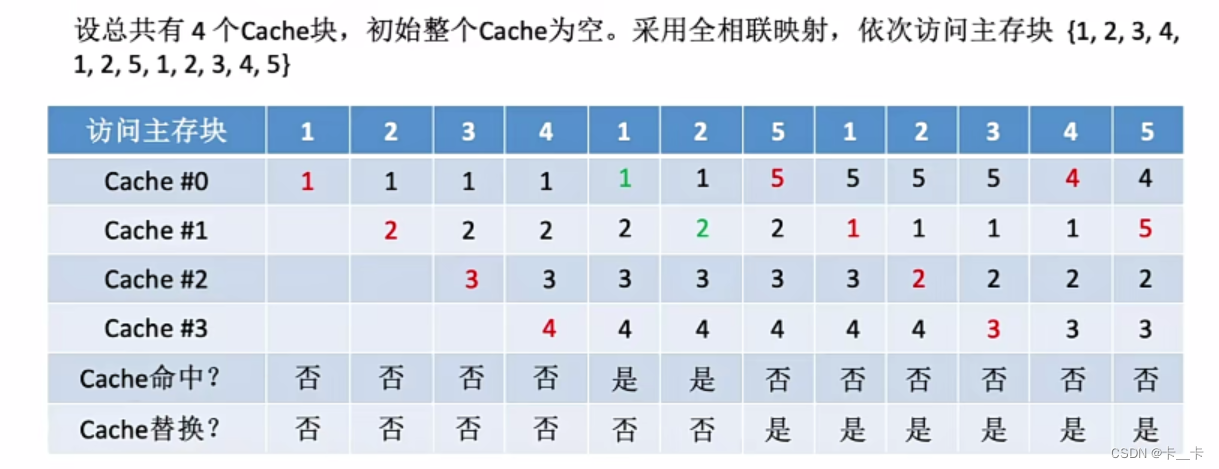
[例] 设总共有4个Cache块,初始整个Cache为空。采用全相联映射,依次访问主存块{1,2,3,4,1,2,5,1,2,3,4,5}
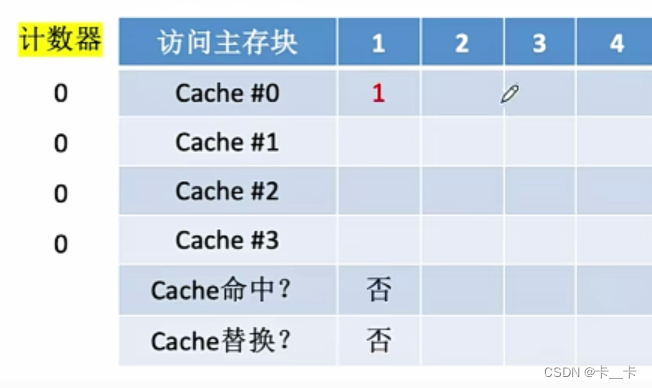
①访问1号主存块,未命中。当前还有空闲行,新装入的行的计数器置0(Cache #0的计数器)。无其他非空闲行,不做处理
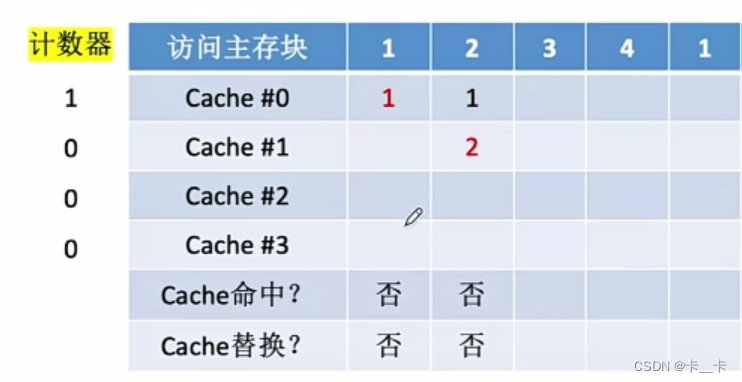
②访问2号主存块,未命中。当前还有空闲行,新装入的行的计数器置0。其余非空闲行全加1,Cache#0的计数器由0改1
③访问3号主存块,未命中。当前还有空闲行,新装入的行的计数器置0。其余非空闲行全加1,Cache#0的计数器由1改2,Cache#1的计数器由0改1
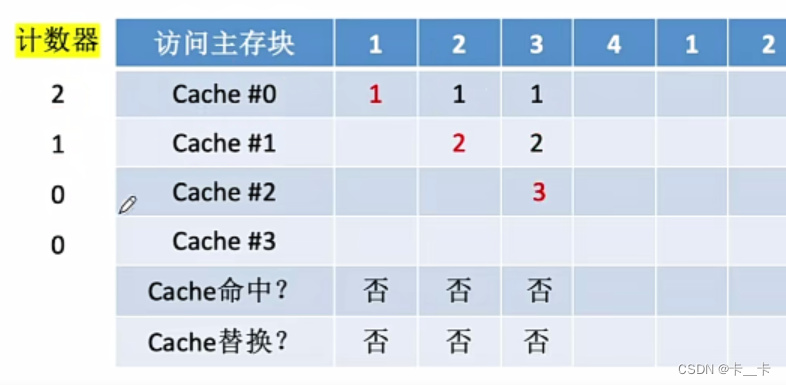
④访问4号主存块,未命中。当前还有空闲行,新装入的行的计数器置0。其余非空闲行全加1,Cache#0的计数器由2改3,Cache#1的计数器由1改2,Cache#2的计数器由0改1
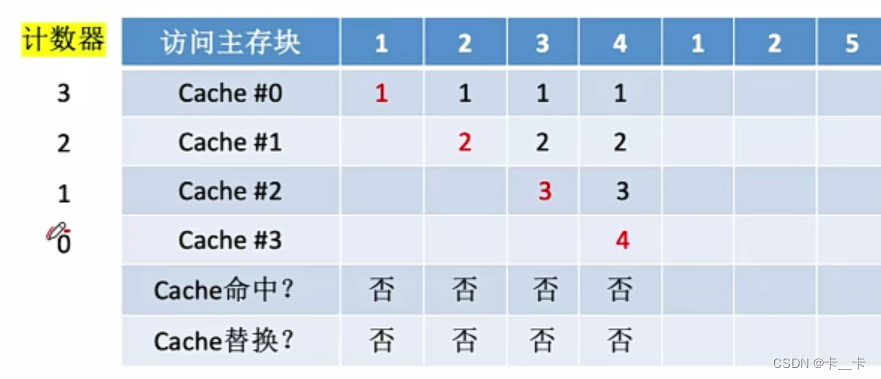
⑤访问1号主存块,命中。所命中的行的计数器清零(Cache#0),比其低的计数器加1(Cache#123的计数器分别为321),其余不变
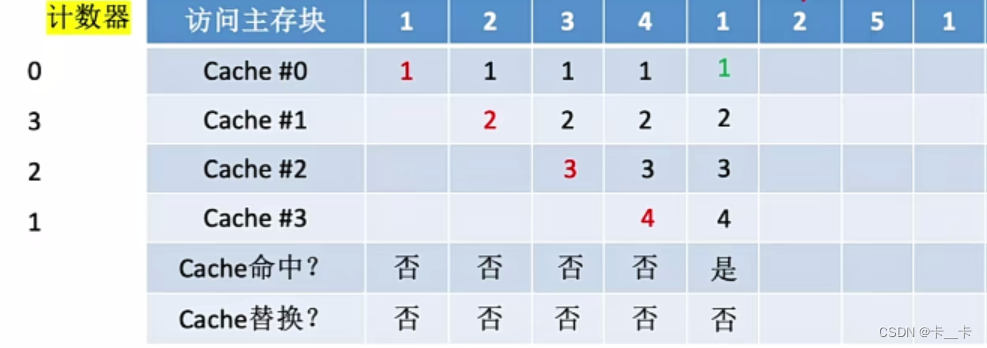
⑥访问2号主存块,命中。所命中的行的计数器清零(Cache#1),比其低的计数器加1(Cache#023的计数器分别为132),其余不变
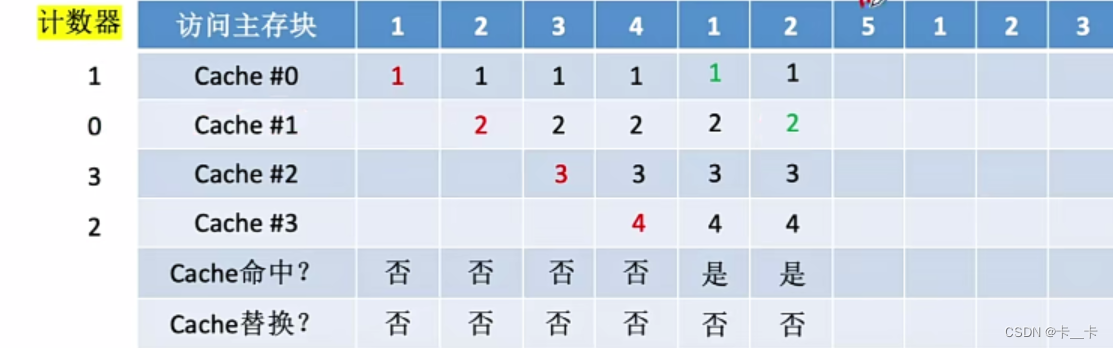
⑦访问5号主存块,未命中,且无空闲行。计数器值最大的行的信息块被淘汰(Cache#2),新装行的块的计数器置0,其余全加1(Cache#013的计数器分别为213)
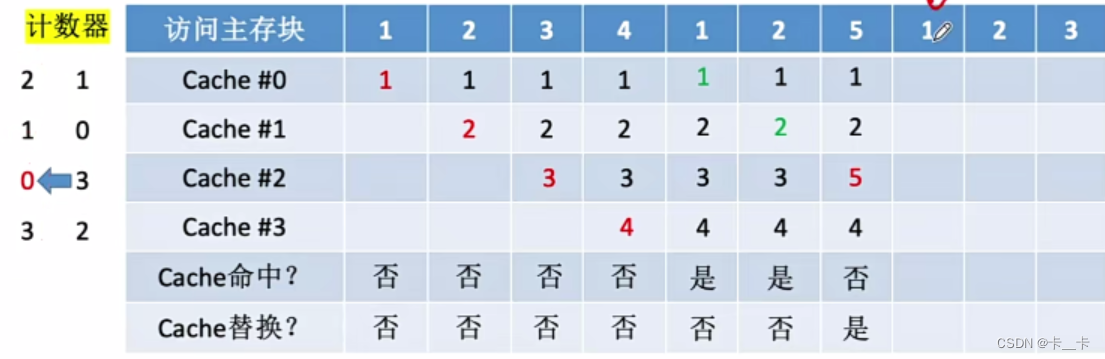
⑧访问1号主存块,命中。所命中的行的计数器清零(Cache#0),比其低的计数器加1(Cache#12的计数器分别为21),其余不变(Cache#3)
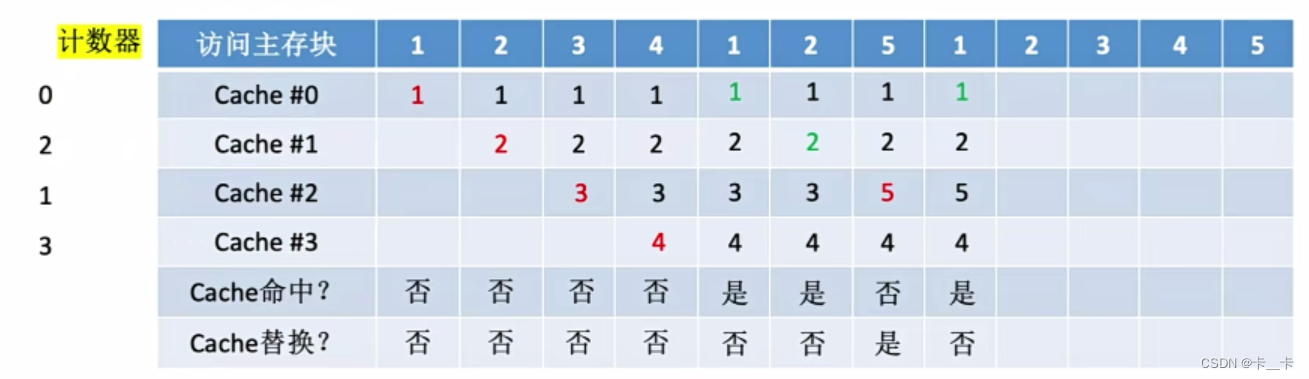
⑨访问2号主存块,命中。所命中的行的计数器清零(Cache#1),比其低的计数器加1(Cache#02的计数器分别为12),其余不变(Cache#3)
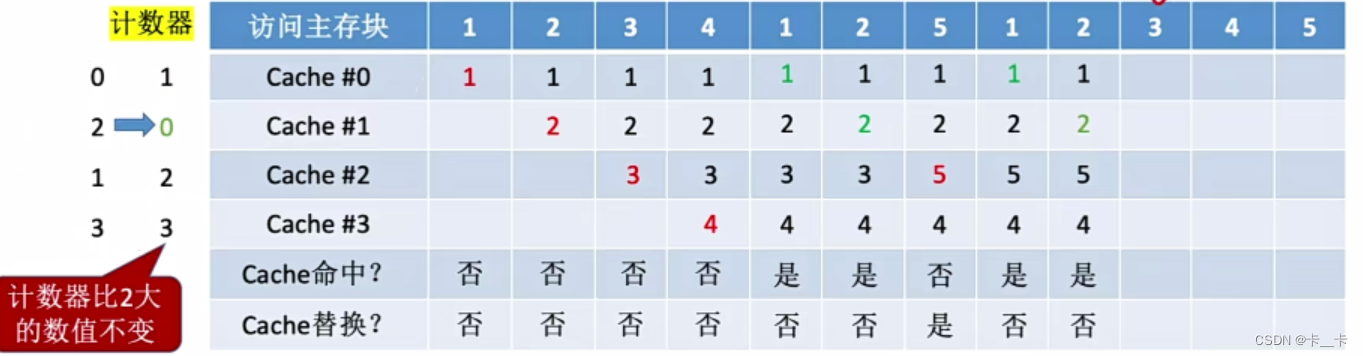
⑩访问3号主存块,未命中,且无空闲行。计数器值最大的行的信息块被淘汰(Cache#3),新装行的块的计数器置0,其余全加1(Cache#012的计数器分别为213)
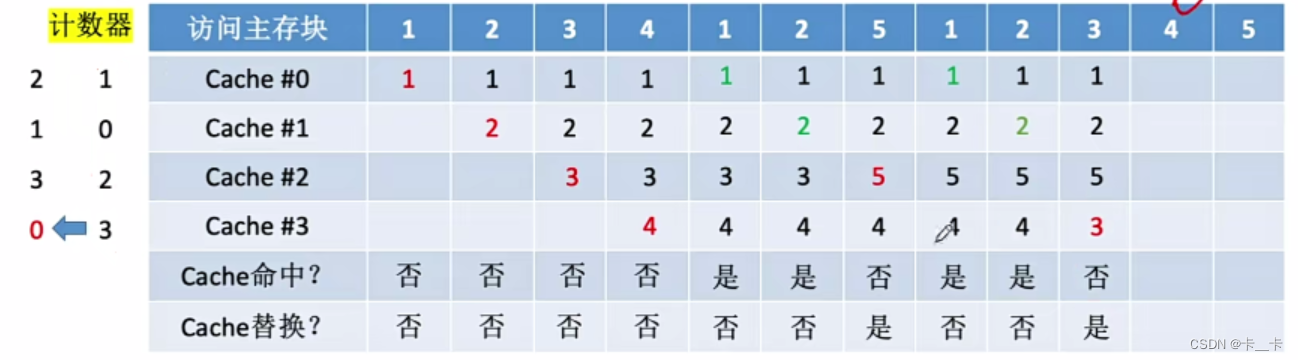
⑪访问4号主存块,未命中,且无空闲行。计数器值最大的行的信息被淘汰(Cache#2),新装行的块的计数器置0,其余全加1(Cache#013的计数器分别为321)
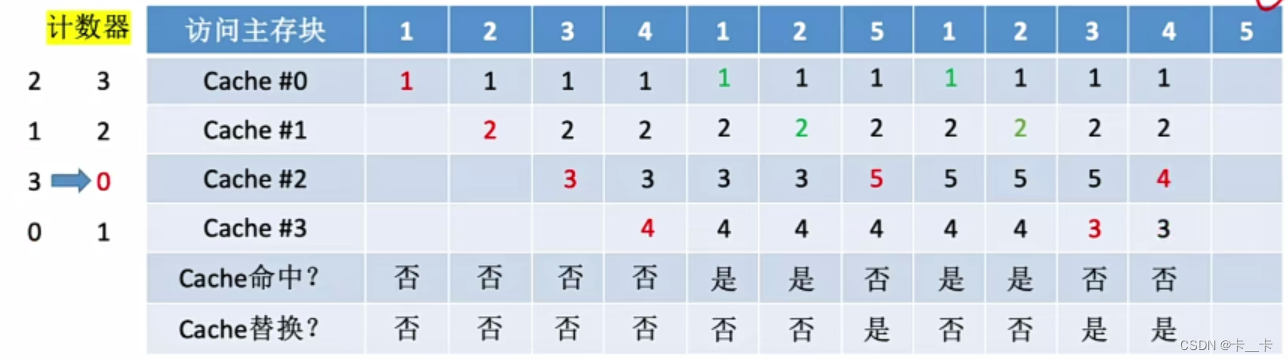
⑫访问5号主存块,未命中。计数器值最大的行的信息被淘汰(Cache#0),新装行的块的计数器置0,其余全加1(Cache#123的计数器分别为312)
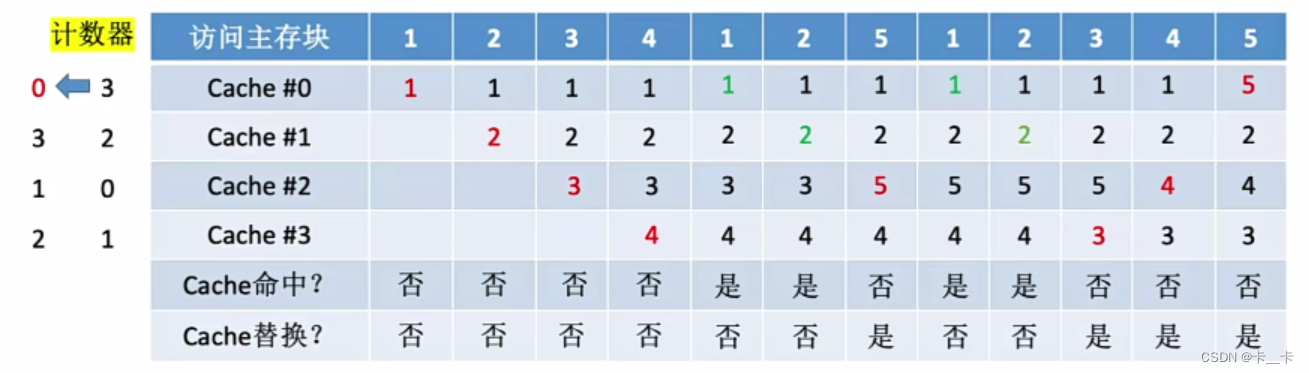
4.最不经常使用算法LFU
Least Frequently Used
将一段时间内被访问次数最少的存储行换出。每行设置计数器(初始为0),每访问一次计算器加1,选择计数器最小的换出。可能导致计数器的值过大,且曾经被经常访问的主存块在未来不一定会用到(LFU属于全局考虑,并非局部性考虑),因此实际中不如LRU
当两个同时(相等)最小时,可以按照FIFO算法换出,也可选择行号较小的先换出
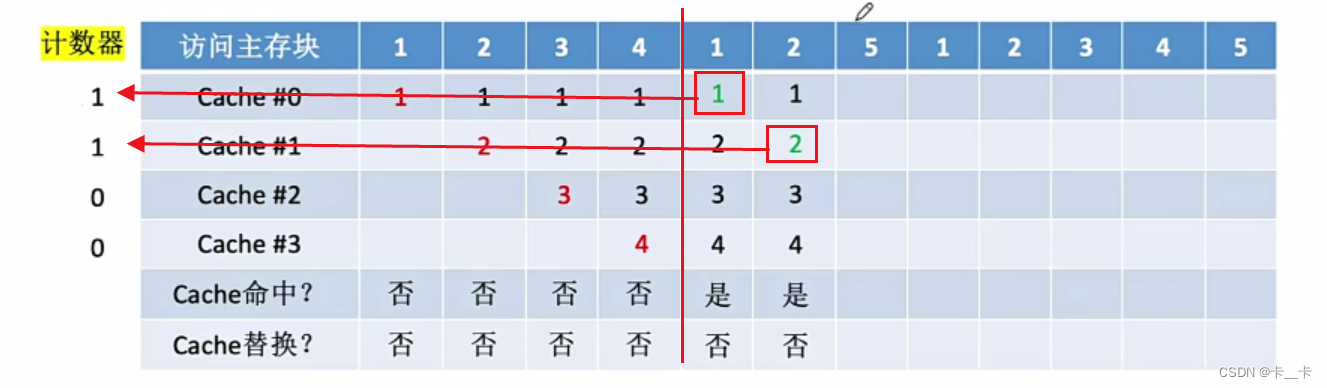
【LRU与LFU对比】
(1)最近最少使用算法LRU(Least Recently Used):考察的是从页面最后一次被使用 到发生替换的时间长短,时间越长,页面就会被置换。LRU是(往前看)淘汰最长时间没有被使用的页面。
(2)最不经常使用算法LFU(Least Frequently Used):考察在一段时间内,使用次数(访问频率)最少的页面淘汰。
四.Cache写策略
Cache中的数据只是主存数据的副本,当Cache内容更新时,需选用写操作策略使Cache内容和主存内容保持一致。
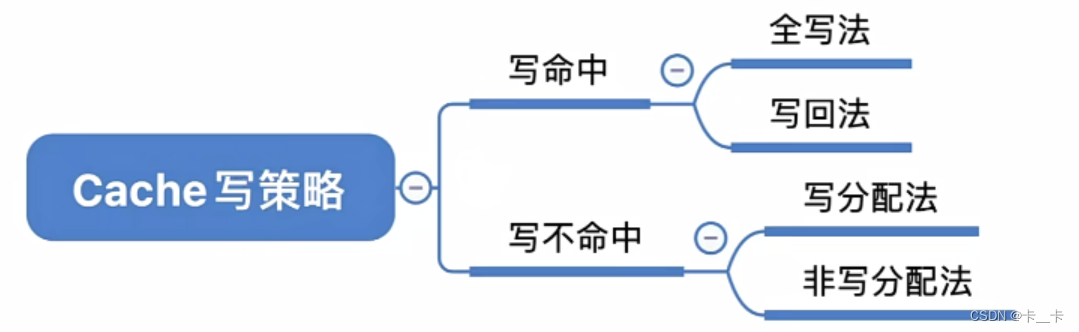
在写策略中,一定对数据进行了修改
1.写命中
在磁盘/内存的存储区域上写过数据,且此次还要在相同地方写入数据。在此情况下,CPU要写入数据的主存块副本已经存在于Cache中,即待修改的内容可在Cache中直接找到,修改时不需要再访问主存
(1)全写法/写直通法
当CPU对Cache写命中时,必须把数据同时写入Cache和“主存”,一般使用写缓冲。当Cache块被换出时,也不需要将其再写回主存。
此方法实现简单,能随时保持主存数据的正确性。但增加了访存次数,降低了Cache的效率。
写缓冲:为减少全写法直接写入主存的时间损耗,在Cache和主存之间增加了一个写缓冲。CPU同时写数据到Cache和写缓冲中,写缓冲再控制将内容写入主存。写缓冲是一个FIFO队列,可以解决速度不匹配的问题,但可能存在写缓冲饱和导致阻塞。
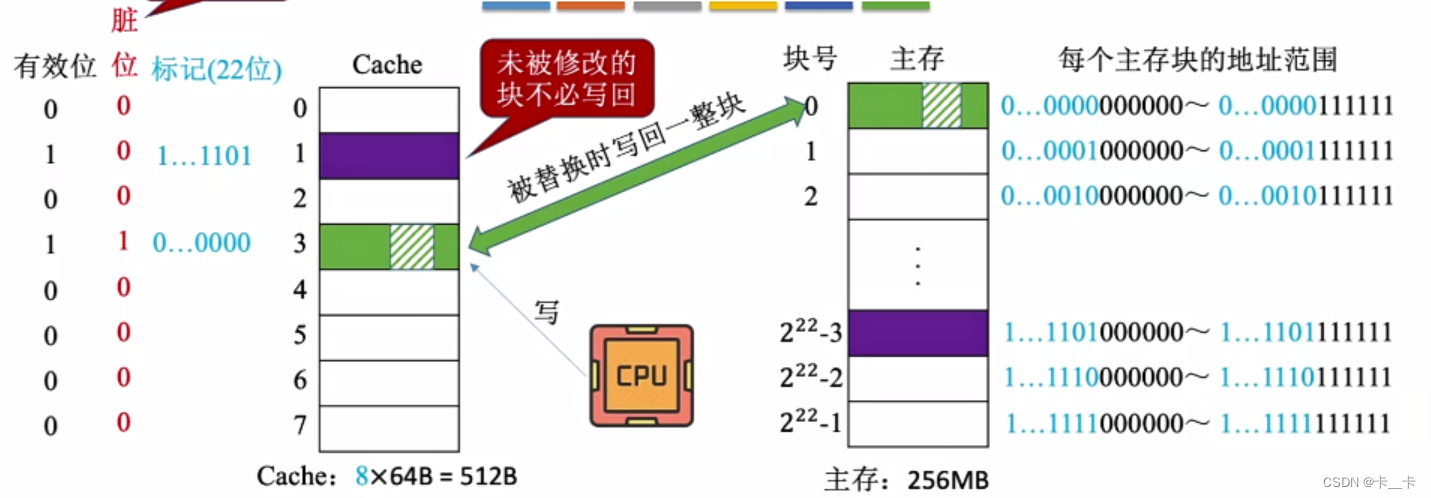
(2)写回法
当CPU对Cache写命中时,只修改Cache的内容,而不立即写入主存,只有当此块被换出时才写回主存。若未命中,则不需要写回主存。
使用此方法可以减少CPU的访存次数,但可能存在数据不一致的情况(不立即写回主存)。
需要给每一个Cache块增加一个“脏位”,若修改过,脏位置1,否则置0。标记决定了写回到主存的什么位置。
2.写不命中
在磁盘/内存的存储区域的相同位置没有写过数据。在此情况下,CPU要写入数据的主存块不在Cache中,即待修改的内容在Cache中找不到,需要去主存中查找
(1)写分配法
当CPU对Cache写不命中时,把主存中的块调入Cache,在Cache中修改,再搭配写回法,当Cache块被换出时将其写回主存
(2)非写分配法
当CPU对Cache写不命中时,不调入Cache,直接往主存中写入数据。通常搭配全写法。在此方式下,仅读未命中时,才将其调入Cache
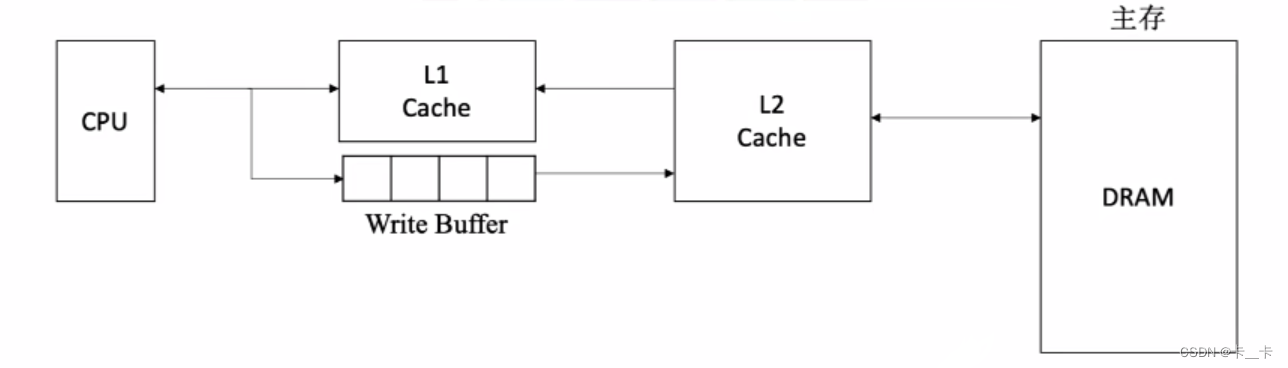
【多级Cache】
离CPU越近的速度越快,容量越小
离CPU越远的速度越慢,容量越大
Cache-主存之间常采用“写回法+写分配法”
各级Cache之间常采用“全写法+非写分配法”
- 什么是Cache
Cache用到的是利用程序访问的局部性原理的高速缓冲技术,我们将程序中正在使用的部分存放在一个高速的、容量较小的Cache中,使CPU的访存操作大多数针对Cache进行,从而大大提高程序的执行速度。 - 简述Cache的映射方式
Cache映射方式分为直接映射、全相联映射和组相连映射。
①直接映射是每个主存块只能装入Cache中的唯一位置,若这个位置已经有内容则会替换掉原来的块。虽然实现简单,但是不够灵活,而且冲突概率最高,空间利用率最低。
②全相联映射可以把主存块装入Cache中的任何位置。优点是比较灵活,而且冲突概率地低,空间利用率高,命中率也高。缺点是地址变换速度慢,因为用到昂贵的按内容寻址的相联存储器进行地址映射,所以实现成本高。
③组相连映射是把Cache空间分为大小相同的组,主存的一个数据块可以装入一组内任何一个位置。即组间采取直接映射,组内采取全相联映射。其综合了直接映射和全相联映的优点 - 简述Cache替换算法
Cache替换算法分为随机算法RAND、先进先出算法FIFO、最近最少使用算法LRU、最不经常使用算法LFU
①随机算法是随机确定替换的Cache块,实现简单,但是命中率也很低。
②先进先出算法选择最早调入的行进行替换。比较容易实现,但是不遵循局部性原理。
③近期最少使用算法LRU依据局部性原理来替换近期内长久未访问过的存储行,是堆栈类算法。
④最不经常使用算法将一段时间内被访问次数最少的存储行换出。 - 简述Cache写策略
Cache写策略分为写命中和写不命中的情况
①写命中有两种处理方法:全写法和写回法。全写法是当CPU对Cache写命中时,必须把数据同时写入Cache和主存。写回法是当CPU对Cache写命中时,只修改Cache内容,而不立即写入主存,只有当此块被换出时才写回主存。因此每个Cache行必须设置一个标志位(脏位)用来确定Cache块是否被修改,是否需要写回主存。
②写不命中有两种处理方法:写分配法和非写分配法。当CPU对Cache写不命中时,把主存中的块调入Cache,在Cache中修改,通常搭配写回法。非写分配法当CPU对Cache写不命中时,不调入Cache,直接往主存中写入数据,通常搭配全写法。 - Cache的换入换出和存储器的换入换出有什么区别?
Cache的换入换出和存储区的换入换出主要集中在替换算法和写策略上。
①Cache的替换算法有随机算法、先进先出算法、最近最少使用算法、最不经常使用算法。
②存储区的替换算法有最佳置换算法、先进先出置换算法、最近最久未使用置换算法、时钟置换算法、改进型时钟置换算法。
③因为Cache需要和主存保持数据一致性,所以只有Cache有写策略。写策略分为写命中和写不命中。写命中有全写法和写回法。写不命中有写分配法和非写分配法。