HYPERNETWORKS
这篇文章来自谷歌的一篇文章
Introduction
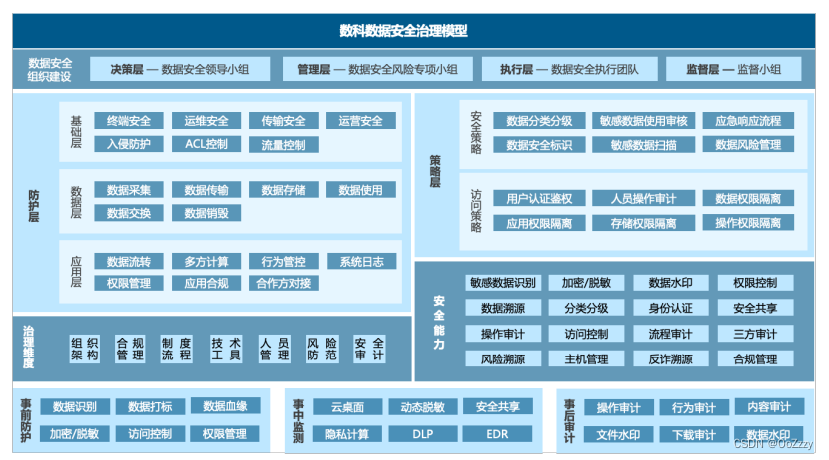
这篇文章中提出了一种方法:使用一个小网络(hypernetwork),小网络的作用是给一个larger network(main network)来生成权重,这个main network和其他文章的模型是一样的,即将一些原始的输入映射到一个期望的目标上。
hypernetwork的输入是权重的结构信息,注意这并没有原始数据的信息。
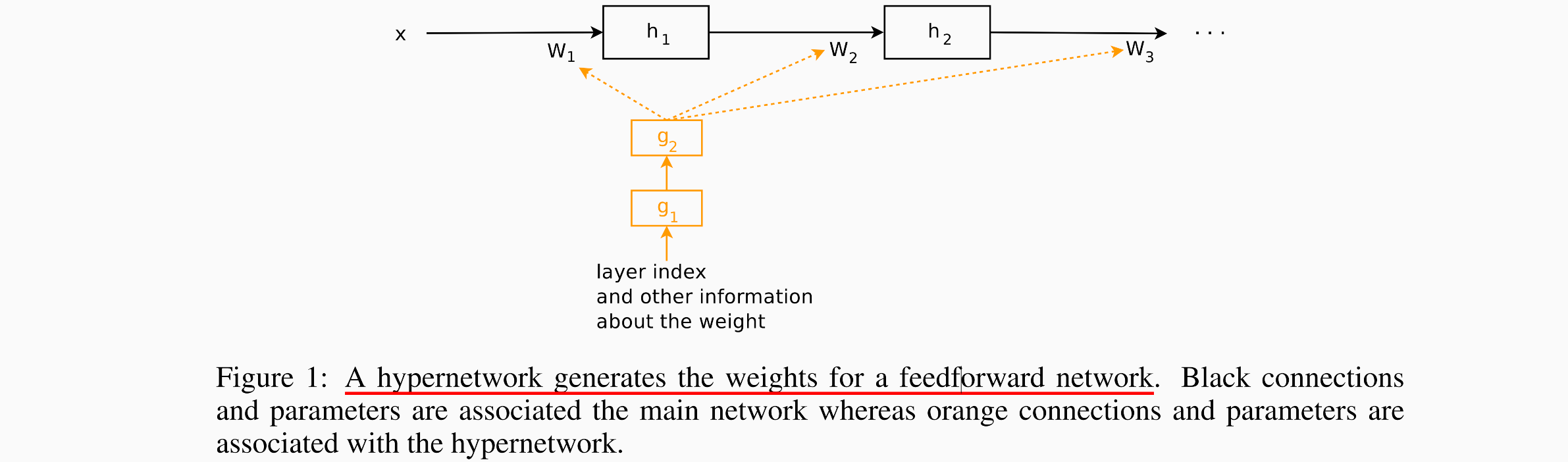
这篇文章与HyperNEAT不一样
- 在HyperNEAT中,hypernetworks的输入是每一个权重对应的虚拟位置(virtual coordinates);而在这篇文章中, 输入是用来描述整个给定层weights的embedding vector,the input is an embedding vector that describes the entire weights of a given layer。
Our embedding vectors can be fifixed parameters that are also learned during end-to-end training, allowing approximate weight-sharing within a layer and across layers of the main network.
- embedding vector 可以是静态的,也同样可以进行学习,权重更新的方式是通过在一个layer中进行权重共享,或者main network中进行跨层的权重共享。
- embedding vector 还可以动态地生成,允许循环神经网络中的权重能够根据时间戳、输入序列而自适应。
- 这篇文章的方法使用end-to-end的方法进行训练,要更有效率:Most reported results using these methods, however, are in small scales, perhaps because they are both slow to train and require heuristics to be effificient. The main difference between our approach and HyperNEAT is that hypernetworks in our approach are trained end-to-end with gradient descent together with the main network, and therefore are more effificient.
Hypernetwork能够给LSTM生成非共享的参数,在一些LSTM的任务上超过了标准的LSTM;在一些图片分类的任务上,hypernet也能用来生成卷积神经网络中的参数,这个参数信息
MOTIVATION AND RELATED WORK
作者的motivation是这样的:
evolutionary computing: It is diffificult to directly operate in large search spaces consisting of millions of weight parameters, a more effificient method is to evolve a smaller network to generate the structure of weights for a larger network, so that the search is constrained within the much smaller weight space.
这篇文章的相关工作有三类:
- HyperNEAT
- Most reported results using these methods, however, are in small scales, perhaps because they are both slow to train and require heuristics to be effificient. The main difference between our approach and HyperNEAT is that hypernetworks in our approach are trained end-to-end with gradient descent together with the main network, and therefore are more effificient.
- fast weights
- Even before the work on HyperNEAT and DCT, Schmidhuber (1992; 1993) has suggested the concept of fast weights in which one network can produce context-dependent weight changes for a second network.
- 作者强调,沿着fast weight的一些文章的主要贡献在于卷积神经网络,而这篇文章中的贡献在于循环神经网络:These studies however did not explore the use of this approach to recurrent networks, which is a main contribution of our work.
Methods
循环神经网络可以看做在层之间加上了一个权重共享,这使得LSTM不灵活、因为梯度消失变得难以学习。而卷积神经网络因为不需要在层之间贡献权重,所以更加灵活,只不过通过丢弃一些参数来实现了更高的深度。
在卷积神经网络中的设计
作者将为CNN设计的hypernet称为STATIC HYPERNETWORK
可以看下图的(2)等式,可以看到对于卷积神经网络,作者是通过2层的线性网络来实现的hypernet。第一层的作用是用来生成对应数量的卷积核(本质上是一些随机投影),第二层的作用是根据前面的投影来生成卷积核。

相比于main network,这篇文章的方法具有更好的可学习参数。

作者解释了一下,为啥使用two-layered hypernetwork:
- 前人使用了two-layered
- 使用two-layered要比one-layered的参数量要小

如何解决在实践中,卷积核的大小不一致所产生的问题:
比如说在残差网络中,不同层的卷积核大小是不一致的,这篇文章所用的方法是「合成」

在循环神经网络中设计的Hypernet
不同于CNN,循环神经网络的目的 the weights can vary across many timesteps.
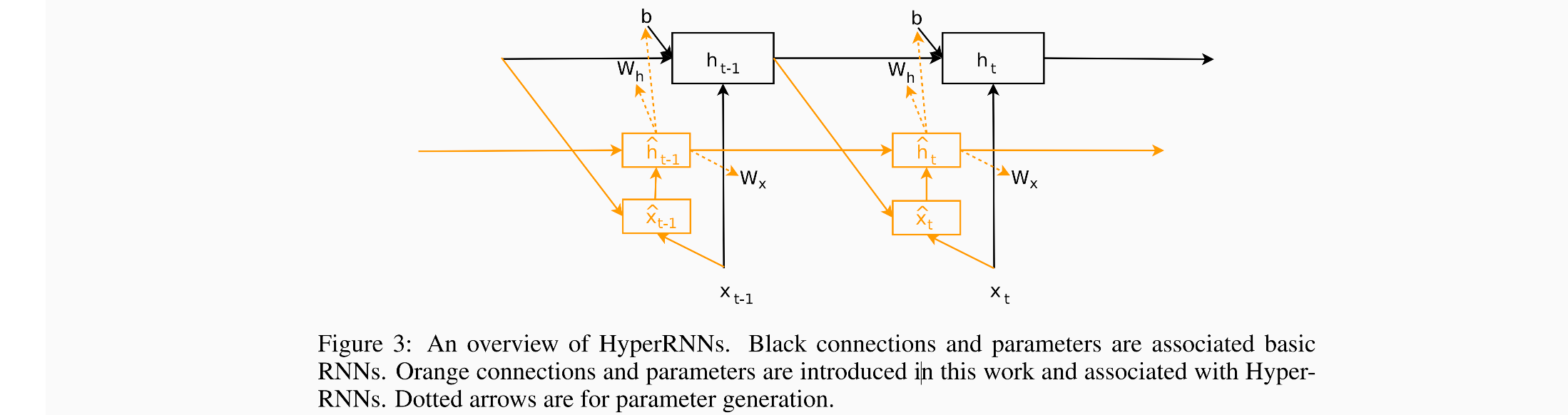
当hypernet用于生成RNN的weights的时候,我们将这种方法称为HyperRNN,然后在每个时间步上,HyperRNN将输入input x t x_t xt, main RNN的hidden_state,然后生成一个向量 h ^ \hat{h} h^,这个向量用来生成同一个时间步上main RNN的参数 W h 和 b W_h和b Wh和b。
下面红线划上的三个参数是需要HyperRNN生成的参数:
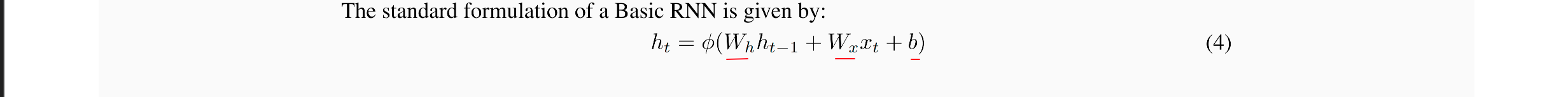
可以看下面这张图片,其中橘色虚线部分表示的是通过 h ^ \hat{h} h^生成的RNN中参数的过程,因为在每个时间步上都进行了生成,所以实际上在RNN中,每一层的参数都不一样,即non-shared。
在实际中,内存的使用会变得特别大,需要对上述方法进行一些修改: