文章目录
- 一. 为什么现在要强调数据湖
- 1. 大数据架构发展历史
- 2. Lambda架构与kappa架构
- 3. 数据湖所具备的能力
- 二. iceberg是数据湖吗
- 1. iceberg的诞生
- 2. iceberg设计之table format
- 从如上iceberg的数据结构可以知道,iceberg在数据查询时,1.查找文件的时间复杂度至少是O(1),2. 加上列统计信息,能够很好的实现物理层面的文件裁剪。
- 3. iceberg 特性
- 4. 其他数据湖框架的对比
- 三. iceberg实战
- 1. 集成iceberg到flink
- 2. 管理iceberg元数据
- 2.1. java api管理iceberg的catalog
- 2.2. 通过flink sql操作iceberg的元数据
- 3. 通过flink将数据入湖--集成到chunjun
- 4. 通过flink 对数据湖进行数据分析--集成到chunjun
- 5. 小结
- 6. flink with iceberg 未来的规划
- 7. 接下来的探索
一. 为什么现在要强调数据湖
1. 大数据架构发展历史
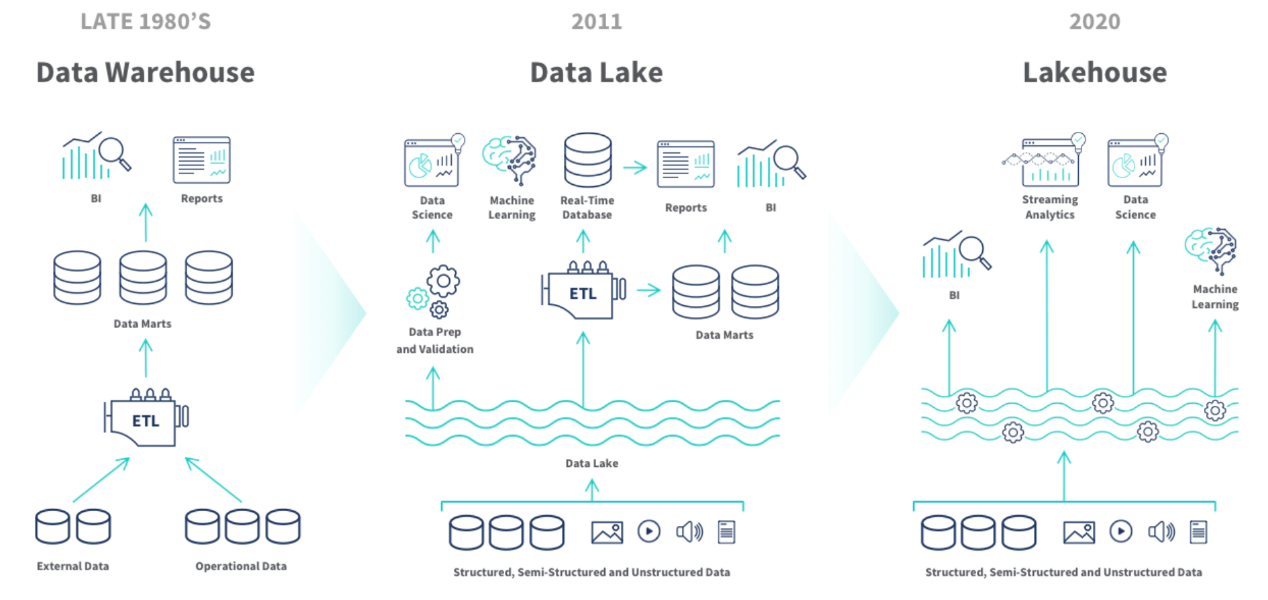
- 数据仓库:加载各个数据源到HIVE、HBASE等;
- 数据湖:数据入湖->再建仓(多中数据源)、或ETL;
- 湖仓一体:数据入湖、湖上建仓。离线实时数据使用同一批数据。
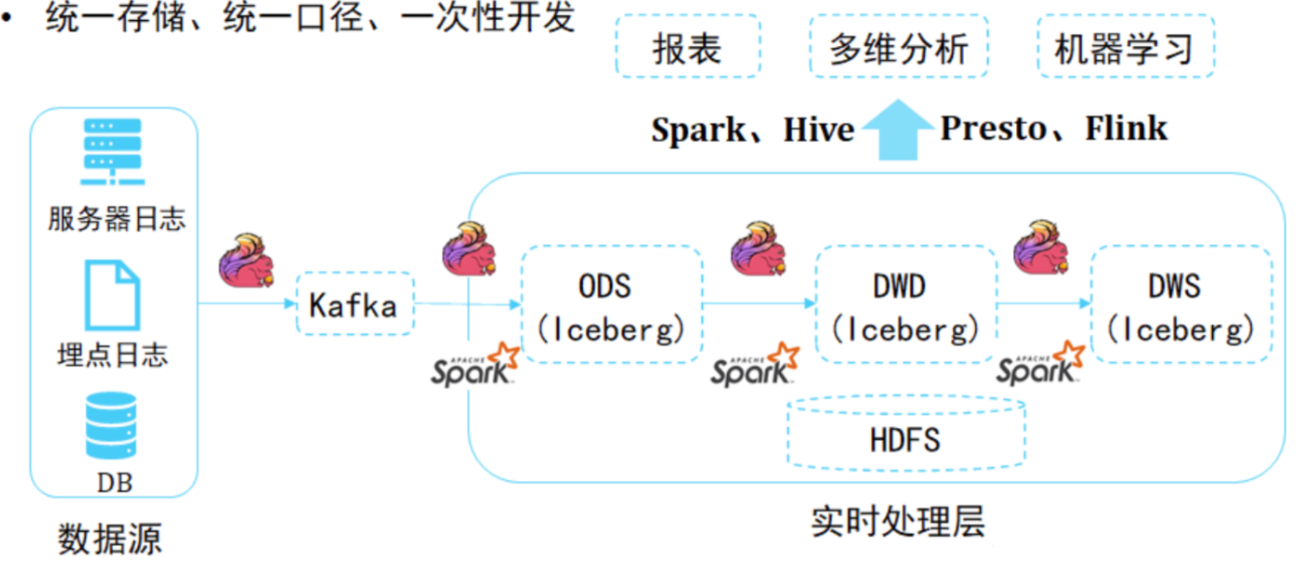
大数据整体的发展路径是:
向着统一存储、统一口径、一次性开发。
统一存储:只有一个存储,消除数据冗余,提高数据质量,更低的存储成本。
统一口径:离线、实时、ad-hoc、机器学习都可以使用同一个数据源,数据治理简单。
一次性开发:多次使用,节约计算成本。
注意:
缺点:将传统数据仓库迁移到湖仓的过程是耗时且昂贵的。
2. Lambda架构与kappa架构
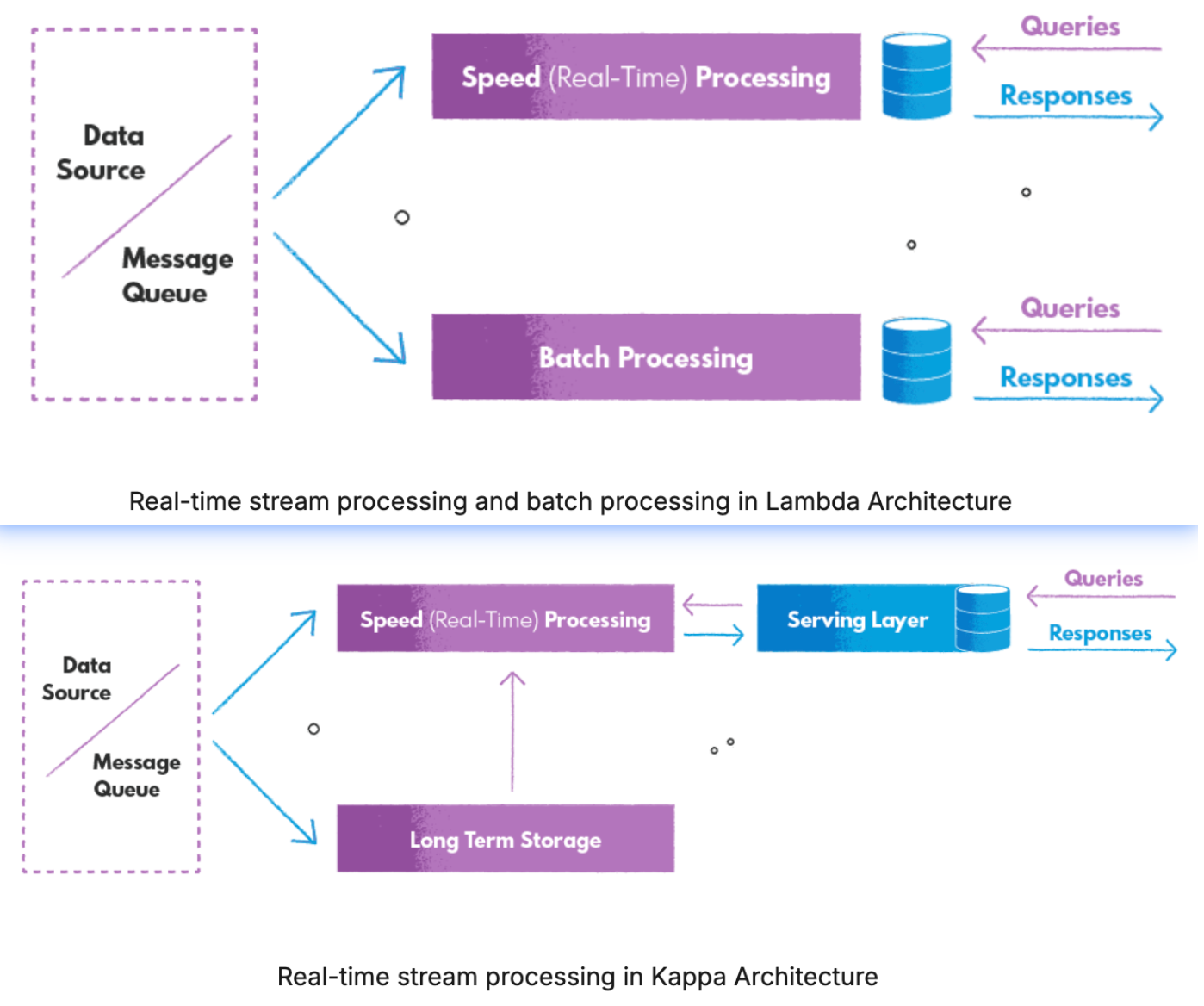
lambda架构:
- 复杂性:分为速度层批层;流批不同的技术,维护两套不同的代码库、工具,维护成本很高
- 流、批分离:处理相同数据出现不一致的结果;
- 延迟:流等批,增加延迟。(CDC可以解决)
kappa架构:流批一体(典型的kafka实时数仓)
- 数据回溯能力弱:面对更复杂的数据分析时,要将DWD和DWS层的数据写入到ClickHouse、ES、MySQL或者是Hive里做进一步分析,这无疑带来了链路的复杂性。
- OLAP分析能力弱:Kafka是一个顺序存储的系统,顺序存储系统是没有办法直接在其上进行OLAP分析的,例如谓词下推这类的优化策略,在顺序存储平台(Kafka)上实现是比较困难的事情。
- 数据时序性受到挑战:Kappa架构是严重依赖于消息队列的,我们知道消息队列本身的准确性严格依赖它上游数据的顺序,但是,消息队列的数据分层越多,发生乱序的可能性越大。
这里可以将kafka改为将starrocks或doris作为实时数仓的存储层以及olap分析层。
提供存储的同时,具备强大的olap分析,以及运行的实时性。
那么:
- 是否存在一种存储技术
既能够支持数据高效的回溯能力,支持数据的更新(ACID),又能够实现数据的批流读写,并且还能够实现分钟级到秒级的数据接入?
- 有没有这样一个架构
既能够满足实时性的需求,又能够满足离线计算的要求,而且还能够减轻开发运维的成本,解决通过消息队列方式构建的Kappa架构中遇到的痛点?
3. 数据湖所具备的能力
数据湖要具备的能力:
- 流批数据处理的统一与能力
- 数据入湖后,支持对数据的修正、数据质量管理的能力。
- 数据的一致性与正确性:ACID事务的能力,元数据的可拓展性。
- 计算引擎与存储引擎的解耦:这样数据湖中间件可以在多个地方应用,即在不同计算引擎(spark、flink、trino、hive、starrocks…)、存储引擎(hdfs、s3)上应用。
二. iceberg是数据湖吗
1. iceberg的诞生

Iceberg是一个面向海量数据分析场景的表格式(Table Format)。
该项目最初是由Netflix公司开发的,目的是解决他们使用巨大的PB级表的长期问题。它于2018年作为Apache孵化器项目开源,并于2020年5月19日从孵化器中毕业。
表格式(Table Format):是对元数据以及数据文件的一种组织方式,处于计算框架(Flink,Spark…)之下,数据文件之上。
我们先回到Netflix 的 Ryan Blue创建Iceberg的原因。
举个hive的窘境:hive表分区天改成小时。
需要如下操作:
- 不能在原表之上直接修改,只能新建一个按小时分区的表,
- 再把数据Insert到新的小时分区表。
- 因为分区字段修改,导致需要修改原表上层的应用的sql,即使通过Rename的命令把新表的名字改为原表。
以上操作上任何一步操作,都会冒着其他地方出现错误的风险。
所以数据的组织方式(表格式)是许多数据基础设施面临挫折和问题的共同原因。
[! Apache Iceberg设计的一个关键考虑是解决各种数据一致性和性能问题,这些问题是Hive在使用大数据时所面临的问题。]
- hive的table state存储在两个地方:分区存储在hive元数据、文件存储在文件系统。
- bucketing(分桶)是由hive的hash实现,(效率不高吗)
- 非 ACID 布局的
唯一原子操作是添加分区- 需要在文件系统中原子地移动对象 ing
- 需要dir_list来plan作业,这会导致 :
- 效率:O(n) 的列表调用,其中 n 是匹配分区的数量。
- 正确性:最终一致性会破坏正确性。
2. iceberg设计之table format
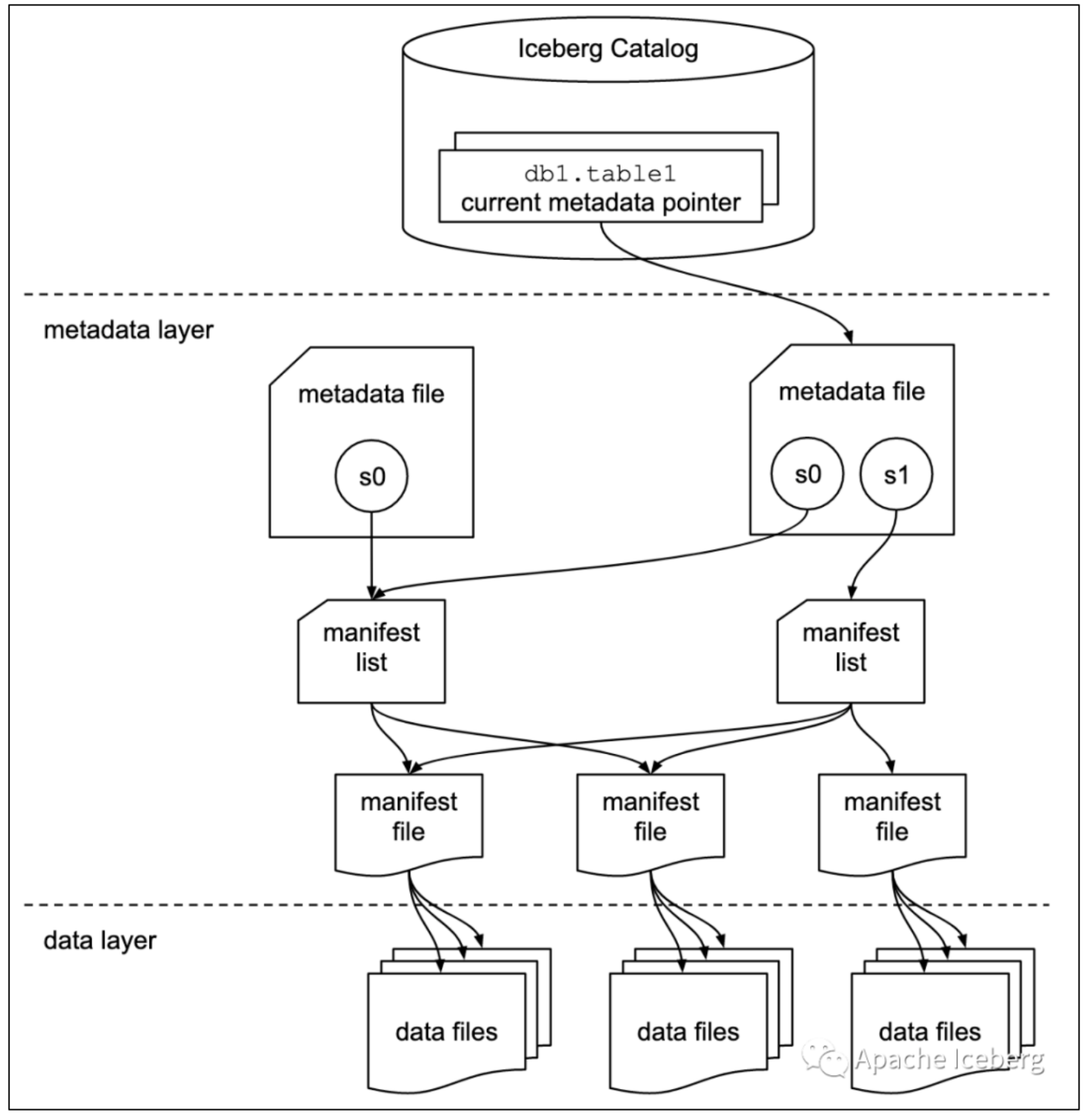
有关存储格式方面,Apache Iceberg 中的一些概念如下:
数据文件 data files
数据文件是Apache Iceberg表真实存储数据的文件,一般是在表的数据存储目录的data目录下,iceberg支持三种格式(parquet、avro、orc)的文件存储。
Iceberg每次更新会产生多个数据文件(data files)。
表快照 Snapshot
快照代表一张表在某个时刻下表的状态。每个快照里面会列出表在某个时刻的所有 data files 列表。
- data files是存储在不同的manifest files里面
- manifest files是存储在一个Manifest list文件里面
- 一个Manifest list文件代表一个Snapshot。
清单列表 Manifest list
manifest list是一个元数据文件,它列出构建表快照(Snapshot)的清单(Manifest file)。
- manifest list中记录了Manifest file列表,其中每个Manifest file信息占据一行。
- 每行中存储了
- Manifest file的路径、
- 数据文件(data files)的分区范围,
- 增加了几个数文件、删除了几个数据文件等信息,
这些信息可以用来在查询时提供过滤,加快速度。
清单文件 Manifest file
Manifest file也是一个元数据文件,
- 存储了数据文件(data files)的列表信息。
- 每行都是每个数据文件的详细描述,包括
- 数据文件的状态、文件路径、
- 分区信息、
- 列级别的统计信息(比如每列的最大最小值、空值数等)、
- 文件的大小以及文件里面数据行数等信息。
其中列级别的统计信息可以在扫描表数据时过滤掉不必要的文件。
从如上iceberg的数据结构可以知道,iceberg在数据查询时,1.查找文件的时间复杂度至少是O(1),2. 加上列统计信息,能够很好的实现物理层面的文件裁剪。
3. iceberg 特性
| 序号 | 特性 | 说明 |
|---|---|---|
| 1 | 统一存储 | 统一性:数据都统一存储到hdfs、s3中。 - 数据湖中可以存储结构化、半结构化、非结构化数据,我们可以通过iceberg来摄取这些数据。 - 但要注意:数据湖存储例如图片等非结构化数据并不是强项。 |
| 2 | 插件化 | 灵活性:Iceberg不和特定的数据存储、计算引擎绑定。常见数据存储(HDFS、S3…),计算引擎(Flink、Spark…)都可以接入Iceberg。 |
| 3 | 模式演化 | 演化能力:支持table、schema、Partition的添加、删除、更新或重命名,简化表修改成本。 |
| 4 | 隐藏分区 | 分区信息并不需要人工维护:会自动计算。 由于Iceberg的分区信息和表数据存储目录是独立的,使得Iceberg的表分区可以被修改,而且不涉及到数据迁移。 |
| 5 | Time Travel | 镜像数据查询:允许用户通过将表重置为之前某一时刻的状态来快速纠正问题。 |
| 6 | 乐观锁的并发支持 | 提供了多个程序并发写入的能力并且保证数据线性一致。 |
| 7 | 支持事务 | upsert与读写分离: - 提供事务(ACID)的机制,使其具备了upsert的能力并且使得边写边读成为可能,从而数据可以更快的被下游组件消费。 - 通过事务保证了下游组件只能消费已commit的数据,而不会读到部分甚至未提交的数据。 |
| 8 | 文件级数据剪裁 | 文件级谓词下推: - Iceberg的元数据里面提供了每个数据文件的一些统计信息,比如最大值,最小值,Count计数等等。 - 查询SQL的过滤条件除了常规的分区,列过滤,甚至可以下推到文件级别,大大加快了查询效率。 |
4. 其他数据湖框架的对比

- iceberg不支持自动文件合并,历史数据也需要自己手动清洗
- 文件格式支持的最多:parquet、avro、orc
- 存储引擎支持hdfs、S3
- 不支持索引
三. iceberg实战
1. 集成iceberg到flink
iceberg独立于计算引擎和存储引擎
...
# 1.16 or above has a regression in loading external jar via -j option.
# See FLINK-30035 for details.
put iceberg-flink-runtime-1.16-1.5.2.jar in flink/lib dir
./bin/sql-client.sh embedded shell
2. 管理iceberg元数据
https://iceberg.apache.org/docs/latest/java-api-quickstart/
2.1. java api管理iceberg的catalog
使用iceberg native api去管理iceberg的catalog
/**
* 数据湖元数据操作
*/
public interface DatalakeMetaAPI {
// Catalog操作
<A> A createCatalog();
void dropCatalog(String catalogName);
Catalog getCatalog(String catalogName);
// Namespace操作:就是数据库
void createNamespace(String namespaceName);
void dropNamespace(String namespaceName);
Namespace getNamespace(String namespaceName);
List<Namespace> getAllNamespaces();
// Table操作
Table createTable();
void dropTable(String namespaceName, String tableName);
Table alterTable(String catalogName, String namespaceName, String tableName);
List<TableIdentifier> getAllTables(String namespaceName);
<T> T setConf();
}
/**
* hadoopCatalog的实现方法
*/
public class IcebergMetaAPI implements DatalakeMetaAPI {
private HadoopCatalog hadoopCatalog;
private String warehousePath;
public IcebergMetaAPI(String warehousePath) {
Configuration hadoopConf = setConf();
hadoopCatalog = new HadoopCatalog(hadoopConf, warehousePath);
}
@Override
public HadoopCatalog createCatalog() {
Configuration hadoopConf = setConf();
return new HadoopCatalog(hadoopConf, warehousePath);
}
@Override
public void dropCatalog(String catalogName) {
}
@Override
public Catalog getCatalog(String catalogName) {
return null;
}
@Override
public void createNamespace(String namespaceName) {
hadoopCatalog.createNamespace(Namespace.of(namespaceName));
System.out.println("创建Namespace成功");
}
@Override
public void dropNamespace(String namespaceName) {
hadoopCatalog.dropNamespace(Namespace.of(namespaceName));
System.out.println("删除Namespace成功");
}
@Override
public Namespace getNamespace(String namespaceName) {
if (hadoopCatalog.namespaceExists(Namespace.of(namespaceName))) {
// todo:是否正确
return hadoopCatalog.listNamespaces(Namespace.of(namespaceName)).get(0);
}
return Namespace.empty();
}
@Override
public List<Namespace> getAllNamespaces() {
return hadoopCatalog.listNamespaces();
}
@Override
public Table createTable() {
TableIdentifier spaceAndTableName = TableIdentifier.of("logging", "logs2");
/** typeid是需要的, 从其他模式格式(如Spark、Avro和Parquet)进行转换时,将自动分配新的ID */
Schema schema = new Schema(Types.NestedField.required(1, "level", Types.StringType.get()),
Types.NestedField.required(2, "event_time", Types.TimestampType.withZone()),
Types.NestedField.required(3, "message", Types.StringType.get()),
Types.NestedField.optional(4, "call_stack",
Types.ListType.ofRequired(5, Types.StringType.get())));
/**
* 分区规范描述了Iceberg如何将记录分组成数据文件。分区规范是使用构建器为表的模式创建的。
*
* <p>以下是按照日志事件的时间戳的小时和日志级别进行分区:
*/
PartitionSpec partition = PartitionSpec.builderFor(schema).hour("event_time")
.identity("level").build();
// namespace就是数据库
Table table = hadoopCatalog.createTable(spaceAndTableName, schema, partition);
System.out.println("创建表" + table + "成功");
return table;
}
@Override
public void dropTable(String namespaceName, String tableName) {
hadoopCatalog.dropTable(TableIdentifier.of("namespaceName", "tableName"));
}
@Override
public Table alterTable(String catalogName, String namespaceName, String tableName) {
//todo:修改表操作
return null;
}
@Override
public List<TableIdentifier> getAllTables(String namespaceName) {
return hadoopCatalog.listTables(Namespace.of(namespaceName));
}
@Override
public Configuration setConf() {
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS", "hdfs://localhost:9000");
// configuration.addResource(new
// Path("/Users/lianggao/MyWorkSpace/001-360/001project-360/datalake-metadata-api/datalake-metadata-iceberg/src/main/resources/core-site.xml"));
// configuration.addResource(new
// Path("/Users/lianggao/MyWorkSpace/001-360/001project-360/datalake-metadata-api/datalake-metadata-iceberg/src/main/resources/hdfs-site.xml"));
// configuration.addResource(new
// Path("/usr/hdp/current/hive-client/conf/hdfs-site.xml"));
configuration.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
// configuration.setBoolean("fs.hdfs.impl.disable.cache", true);
// configuration.set("hadoop.job.ugi", "logsget");
// UserGroupInformation.setConfiguration(configuration);
// try {
// Subject subject = new Subject();
// subject.getPrincipals().add(new UserPrincipal("logsget"));
// UserGroupInformation.loginUserFromSubject(null);
// } catch (IOException e) {
// e.printStackTrace();
// }
return configuration;
}
}
2.2. 通过flink sql操作iceberg的元数据
本文采用的是flink client sql (在flink standalone集群)去提交iceberg表相关操作,如下创建catalog,我们看到创建的catalog持久化到了s3存储中。
表操作
# 创建catalog
CREATE CATALOG hadoop_catalog WITH ( 'type'='iceberg', 'catalog-type'='hadoop', 'warehouse'='hdfs://iceberg1v.middle.bjmd.qihoo.net:9000/warehouse/iceberg-hadoop', 'property-version'='1' );
# 使用catalog
use catalog hadoop_catalog;
# 创建表,默认数据库为default
CREATE TABLE `sample` (
city_name STRING ,
category_name STRING,
province_name STRING,
order_amount_daily_category_city decimal(20,2)
);
# 插入数据
INSERT INTO `sample` VALUES (1, 'a');
# 创建带有主键的表
CREATE TABLE `sample5` (
`id` INT UNIQUE COMMENT 'unique id',
`data` STRING NOT NULL,
PRIMARY KEY(`id`) NOT ENFORCED
) with (
'format-version'='2',
'write.upsert.enabled'='true'
);
注意:flink sql只允许修改表的属性,并不支持对于列、分区的修改。
官网: https://iceberg.apache.org/docs/nightly/flink/
查找表的相关元数据
-- 表历史
SELECT * FROM spotify$history;
--
SELECT * FROM spotify$metadata_log_entries;
-- snapshots
SELECT * FROM spotify$snapshots;
产品结合:我们运行的flink是在 yarn 下运行的,交互慢,费资源,所以不推荐使用flink对catalog进行管理,而是使用native api管理。
3. 通过flink将数据入湖–集成到chunjun
自己搭建的集群与现有系统部环境暂不统一,使用系统部的hadoop作为数据湖的存储
Flink SQL> CREATE CATALOG hadoop_catalog WITH ( 'type'='iceberg', 'catalog-type'='hadoop', 'warehouse'='hdfs://iceberg1v.middle.bjmd.qihoo.net:9000/warehouse/iceberg-hadoop',
'property-version'='1' );
[ERROR] Could not execute SQL statement. Reason:
java.io.IOException: ViewFs: Cannot initialize: Empty Mount table in config for viewfs://iceberg1v.middle.bjmd.qihoo.net:9000/
Flink SQL> CREATE CATALOG hadoop_catalog WITH ( 'type'='iceberg', 'catalog-type'='hadoop', 'warehouse'='hdfs://namenode.dfs.shbt.qihoo.net:9000/home/logsget/warehouse/iceberg-hadoop', 'property-version'='1' );
[INFO] Execute statement succeed.
Flink SQL> use catalog hadoop_catalog;
[INFO] Execute statement succeed.
Flink SQL> CREATE TABLE `sample` (city_name STRING , category_name STRING, province_name STRING, order_amount_daily_category_city decimal(20,2));
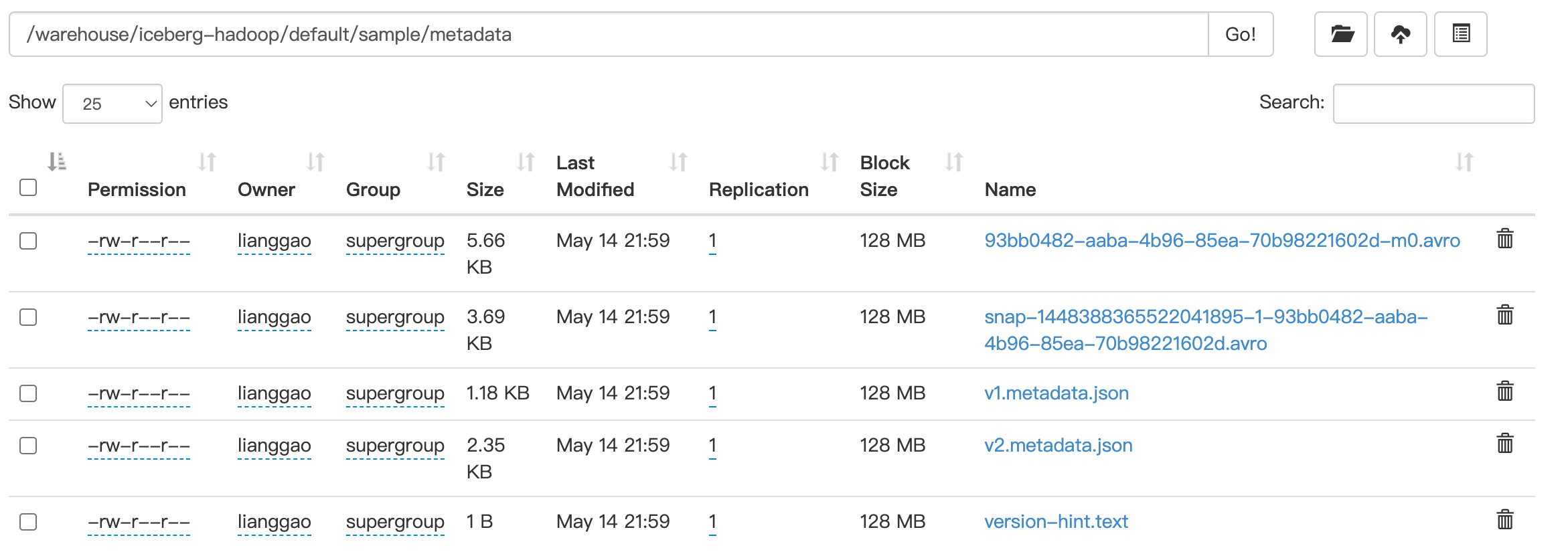
2024-05-17 00:47:21,945 WARN org.apache.hadoop.hdfs.DFSClient [] - Cannot remove /home/logsget/warehouse/iceberg-hadoop/default/sample/metadata/version-hint.text: No such file or directory.
[INFO] Execute statement succeed.
CREATE CATALOG hadoop_catalog WITH ( 'type'='iceberg', 'catalog-type'='hadoop', 'warehouse'='hdfs://namenode.dfs.shbt.qihoo.net:9000/home/logsget/warehouse/iceberg-hadoop', 'property-version'='1' );
--use catalog hadoop_catalog;
CREATE TABLE `aaa_b` (
city_name STRING , category_name STRING, province_name STRING, order_amount_daily_category_city decimal(20,2)
)
WITH (
'password' = 'a87fc6992a96de56',
'connector' = 'starrocks-x',
'sink.max-retries' = '3',
'schema-name' = 'dp_test',
'sink.buffer-flush.interval-ms' = '5000',
'fe-nodes' = 'db01.doris.shyc2.qihoo.net:8030',
'table-name' = 'ads_product_citycategoryamount_di',
'url' = 'jdbc:mysql://10.192.197.134:9030/dp_test?useUnicode=true&characterEncoding=utf-8&useSSL=false&connectTimeout=3000&useUnicode=true&characterEncoding=utf8&useSSL=false&rewriteBatchedStatements=true&&serverTimezone=Asia/Shanghai&sessionVariables=query_timeout=86400',
'username' = 'dfs_shbt_logsget'
);
insert into hadoop_catalog.`default`.sample select * from aaa_b;
/data01/chunjun-master-dev/bin/run-ri-test.sh /data01/chunjun-master-dev/conf/ice-w.sql \
offline logsget '' '' 3 '' '' '' '' '' logsget 1 '' '' '' '' '' \
radar_1_2187_9270_4058632_test '' '' '' local
4. 通过flink 对数据湖进行数据分析–集成到chunjun
CREATE CATALOG hadoop_catalog WITH ( 'type'='iceberg', 'catalog-type'='hadoop', 'warehouse'='hdfs://namenode.dfs.shbt.qihoo.net:9000/home/logsget/warehouse/iceberg-hadoop', 'property-version'='1' );
--use catalog hadoop_catalog;
CREATE TABLE `aaa_b` (
city_name STRING , category_name STRING, province_name STRING, order_amount_daily_category_city decimal(20,2)
)
WITH (
'connector' = 'print'
);
insert into aaa_b select * from hadoop_catalog.`default`.sample ;
/data01/chunjun-master-dev/bin/run-ri-test.sh /data01/chunjun-master-dev/conf/ice-w.sql \
offline logsget '' '' 3 '' '' '' '' '' logsget 1 '' '' '' '' '' \
radar_1_2187_9270_4058632_test '' '' '' local
5. 小结
虽然iceberg当初是为了解决hive表格式的问题,但实际上iceberg的种种能力,使得他配得上作为数据湖中间件,这里再回顾下iceberg的能力:
- 流批数据处理的统一与能力
- 数据入湖后,支持对数据的修正、数据质量管理的能力。
- 数据的一致性与正确性:ACID事务的能力,元数据的可拓展性。
- 计算引擎与存储引擎的解耦:这样数据湖中间件可以在多个地方应用,即在不同计算引擎(spark、flink、trino、hive、starrocks…)、存储引擎(hdfs、s3)上应用。
我们可以借助iceberg搭建存储统一、计算口径统一的数据湖仓。
具体地,我们可以
- 使用iceberg native api进行元数据管理;
- 使用flink进行数据入湖;湖仓建设;
- 使用flink、spark、trino、hive等进行数据分析。
6. flink with iceberg 未来的规划
There are some features that are do not yet supported in the current Flink Iceberg integration work:
- Don’t support creating iceberg table with hidden partitioning. Discussion in flink mail list.
- Don’t support creating iceberg table with computed column.
- Don’t support creating iceberg table with watermark.
- Don’t support adding columns, removing columns, renaming columns, changing columns. FLINK-19062 is tracking this.
7. 接下来的探索
- iceberg数据入湖的事务能力验证
- iceberg修改表结构对任务的影响
- iceberg批数据分批写完,下游数据立马能消费的验证,以及相关原理
- iceberg数据合并的逻辑验证。
- iceberg处理非结构数据与半结构数据的实践