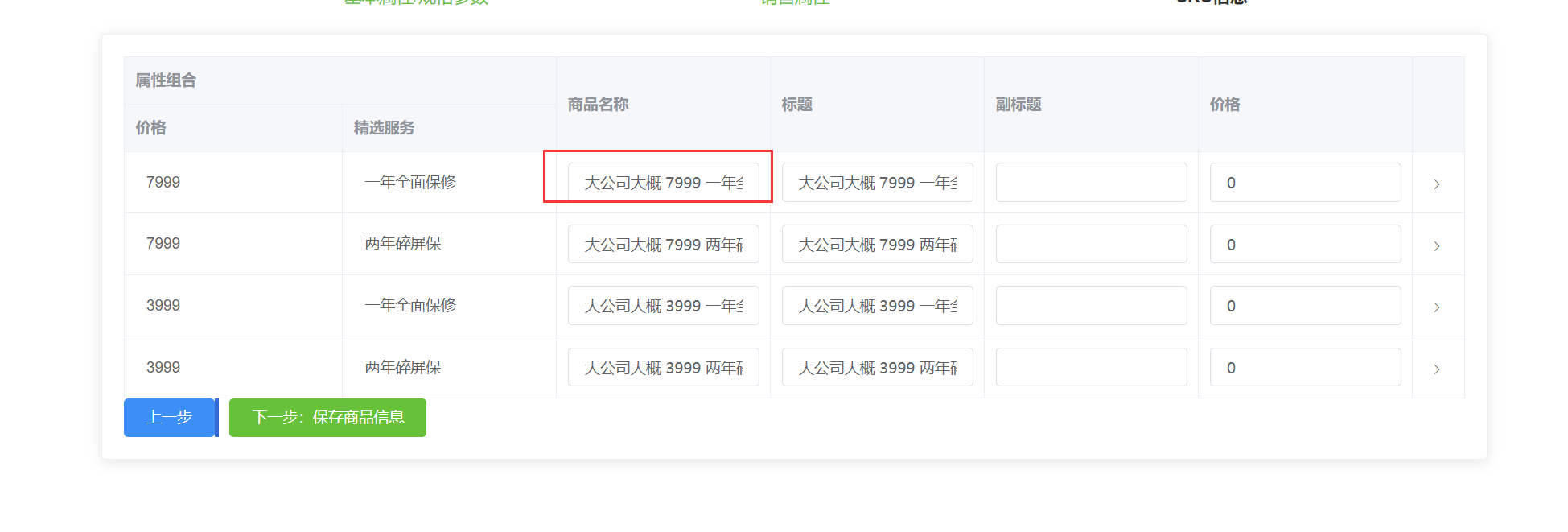
简单来讲,FIFO-Diffusion先通过一些模型如VideoCraft2、zeroscope、Opem-Sora Plan等与FIFO-Diffusion的组合生成短视频,然后取结尾的帧(也可以取多帧),再用这一帧的图片生成另一段短视频,然后拼接起来。FIFO-Diffusion对如何取帧、生成新视频的时候引用往前的多少帧,以及如何去噪加噪做了算法优化。
相关链接
论文:arxiv.org/abs/2405.11473
项目:jjihwan.github.io/projects/FIFO-Diffusion
代码:github.com/jjihwan/FIFO-Diffusion_public
论文阅读

FIFO-Diffusion:无需训练即可从文本生成无限视频
摘要
我们提出了一种基于预训练扩散模型的新颖推理技术,用于文本条件视频生成。我们的方法称为 FIFO-Diffusion,从概念上讲,无需训练即可生成无限长的视频。这是通过迭代执行对角去噪来实现的,该去噪同时处理队列中噪声级别不断增加的一系列连续帧;
我们的方法在头部将完全去噪的帧出队,同时在尾部将新的随机噪声帧入队。然而,对角去噪是一把双刃剑,因为靠近尾部的帧可以通过前向参考利用更干净的帧,但这种策略会导致训练和推理之间的差异。因此,我们引入潜在分区来减少训练与推理之间的差距,并引入前向降噪来利用前向引用的优势。
我们已经在现有的文本到视频生成基线上展示了所提出的方法的有希望的结果和有效性。
方法
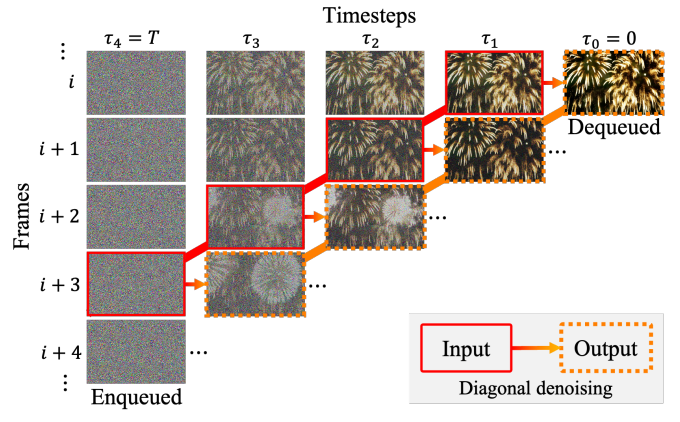
f = 4对角去噪示意图。被实线包围的框架是 被虚线包围的帧是模型输入的去噪版本。去噪后 当随机噪声进入队列时,右上角完全去噪的实例被退出队列。
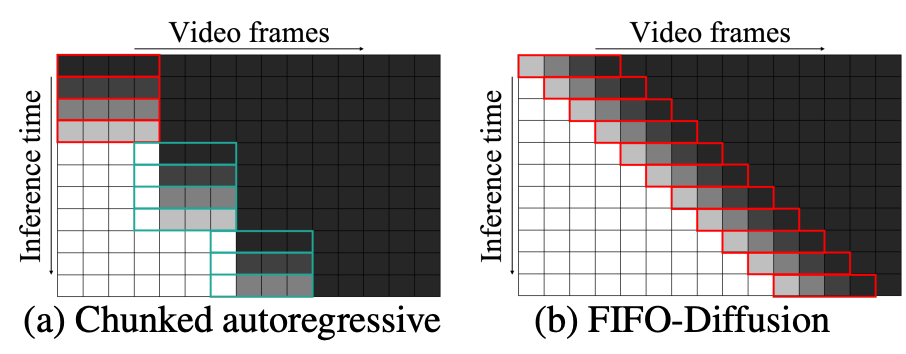
长视频生成的分块自回归方法与FIFO-Diffusion方法的比较。随机噪声(黑色)被迭代去噪到图像中模型的潜势(白色)。红色的盒子指出预训练中的去噪网络基本模型,绿框表示通过额外训练得到的预测网络。
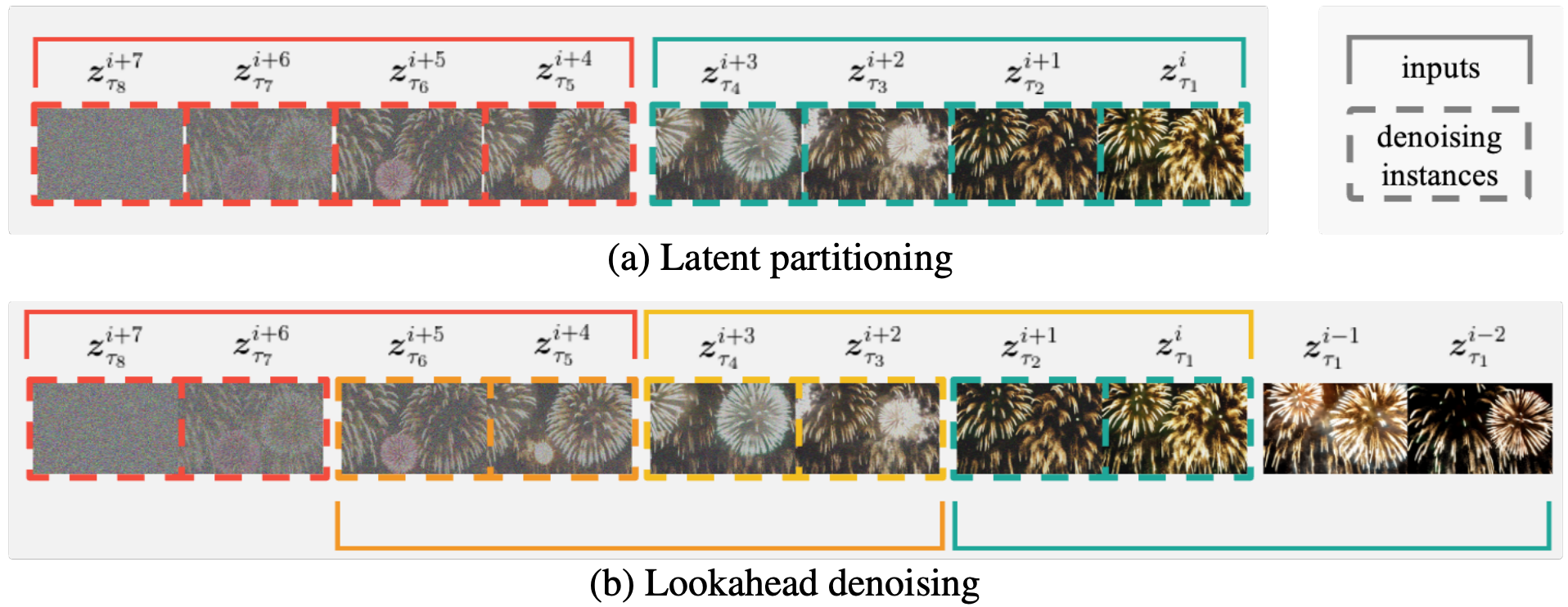
上图为f = 4, n = 2时的潜在分区和前向去噪示意图。
-
(a)潜在分区将扩散过程划分为n个部分,以减少最大噪声水平差异。
-
(b)在(a)上lookahead denoings使所有框架都能用足够数量的以前框架来代替所有帧,而计算的计算是(a)的两倍。
实验
基于(a) Open-Sora计划的FIFO-Diffusion生成的长视频插图。(b) VideoCrafter2,(c)基于VideoCrafter2的多个提示。电话上的号码每个帧的左上角表示帧索引。

(a)森林里宁静的冬日景色。森林被一层厚厚的雪覆盖着,这……”

(b)“一个充满活力的水下场景,一个潜水者探索沉船,2K,逼真的。”

(c)“一只老虎在草原上行走→站立→休息,逼真,4k,高清”

“一个漂浮在太空中的宇航员,高质量,4K分辨率。”
不同基线结果比较
VideoCrafter2

视频生成的FIFO扩散与VideoCrafter2。左上角的数字每一帧表示帧索引。
VideoCrafter1

视频生成的FIFO扩散与VideoCrafter1。左上角的数字 每一帧表示帧索引。
zeroscope

用zeroscope的FIFO扩散产生的视频。
Open-Sora Plan

使用Open-Sora计划的fifo扩散生成的视频。
长视频生成方法比较
与其他长视频生成技术,Gen-L-Video, FreeNoise和LaVie SEINE。

(一)“一个充满活力的水下场景,一个潜水者探索沉船,2K,逼真的。”

(二)“宁静禅宗花园的全景,高品质,4K分辨率。”
结论
我们介绍了一种新颖的推理算法,即FIFO扩散,该算法允许从文本中生成无限长的视频,而无需在短视频片段上预测的视频扩散模型。 我们的方法是通过进行对角线降解来实现的,后者以第一次出局的方式处理潜在的噪声水平的增加。
在每一步中,一个完全去噪的实例被去排队,而一个新的随机实例被去排队噪音是排队的。虽然对角去噪具有关键的权衡,但我们提出了潜在分区克服其固有的局限性,前瞻性去噪,发挥其优势。 把它们结合在一起,FIFO-Diffusion成功地生成了高质量的长视频,展示了上下文一致性的精彩的场景和动态运动表达。











094:素数回文095:活动安排096:合唱团](https://img-blog.csdnimg.cn/direct/f7384f757a4a4800bf884ac0d20cf1d2.png)