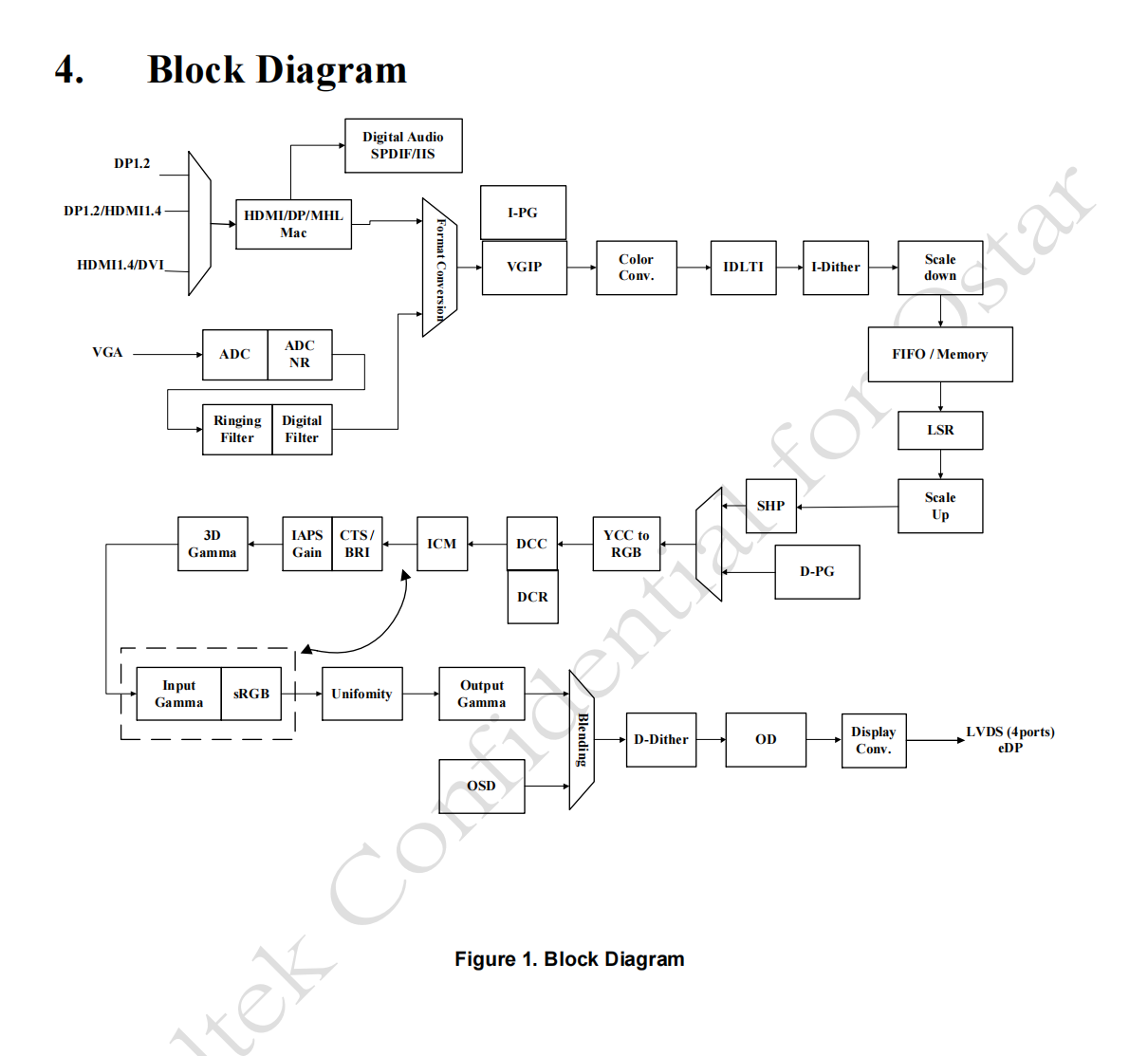
案例亮点
-
部署低功耗、高密度飞速(FS)以太网交换机,紧凑机身设计节省70%机房空间,冗余电源和智能风扇确保系统高可用性,有效优化散热和降低能耗。
-
支持25G/40G/100G多速率自适应交换架构,构建超低时延企业AI高性能计算网络,实现算力密度与能效比双提升,为客户提供“零瓶颈”传输通道,满足AI企业算力线性增长需求。
-
采用Airware云管理平台,直观Web GUI界面,可实时监测设备运行状态,灵活管理和自动配置,降低客户跨境管理难度,提高运维效率并降低人力操作成本,显著提升客户业务连续性。
关键信息
-
网络带宽提升10倍,GPU集群通信延迟降至3μs,AI模型训练周期缩短40%。
-
优化总拥有成本,节省70%机柜空间,降低15%能耗;
-
网络架构支持横向扩展至10,000节点,满足AI企业未来3~5年算力增长需求;
-
统一网络管理平台实现跨境设备状态监控,故障定位时间缩短90%;
-
全球智能仓储系统,90%以上订单能当日发货,确保快速交付;
-
飞速(FS)专业技术团队12h内快速定位故障,线上解决80%技术配置问题,提高运维效率。
案例概况
客户是一家提供服务器及相关技术解决方案的系统集成商,可针对企业行业应用场景提供定制化的服务器解决方案,主要为AI行业企业定制CPU计算设备,如自动驾驶、人工智能翻译,车载算力设备、整车厂仿真集群等,涉及人工智能、云计算、互联网、安防、政府、金融、交通、教育、医疗等行业及领域。
为解决企业网络性能瓶颈、机房环境适应性低、多速率组网复杂度过高、运维管理难等问题,客户采用飞速(FS)AI高性能计算网络解决方案,部署100G/25G无阻塞网络架构与紧凑型以太网交换机,实现AI计算节点间微秒级时延通信,同步整合多速率设备统一接入以简化网络拓扑,结合可视化智能运维工具优化跨境管理部署,为AI算力网络弹性扩展提供高可靠、高可用的基础设施支撑。
业务挑战
客户在部署AI训练基础设施时,面临的核心挑战集中于网络性能与资源协调失衡。传统网络架构的带宽限制无法支撑TB级数据的实时传输需求,频繁出现的数据拥塞直接导致GPU集群的实际有效算力输出被压缩至理论值的60%以下,模型训练周期大幅延长,更使得算法团队在模型结构调整、超参数优化等迭代环节陷入低效循环,最终导致AI产品化进程滞后于市场竞争窗口期。
同时香港机房空间进一步加剧部署难度。受限于机架电力配额和散热系统设计,客户现有设备的高功率密度难以在有限空间内满足计算需求,跨机架通信延迟显著增加,网络拓扑复杂度呈指数级上升,不利于企业网络未来扩展,甚至形成硬件部署与网络性能间的负向增强循环。
另一方面,混合组网场景下的多速率协同也会影响组网复杂度。客户需同时连接100G GPU集群、10G/25G存储节点及管理网络,传统分层架构难以实现协议优化与流量隔离,网络抖动直接影响分布式训练的同步精度,甚至可能引发训练中断风险,关键AI产品的交付周期因训练效率下降被迫延长6-8周,直接导致企业市场竞争份额降低,影响业务连续性。
此外,客户现有网络管理系统缺乏自动化平台支持,导致运营团队面临显著的运维管理压力。跨境远程人工操作不仅降低配置效率,还间接增加了纠错成本,并且大幅延长故障定位与恢复时间,远超业务容忍阈值。运维成本持续攀升的同时,还会造成服务质量下降,降低用户满意度和信任度,对企业信誉造成负面影响。
因此,企业亟需构建100G/25G AI高性能计算网络,通过弹性带宽、协议优化与自动化运维实现全局资源效率跃升,以支撑AI业务的可持续发展。
解决方案
为满足在AI计算、跨境设备管理及快速部署方面的核心需求,客户基于飞速(FS)高性能计算网络解决方案,从硬件架构到服务交付进行全方位优化,实现高效、稳定且可扩展的AI高性能计算网络。
核心层:突破带宽瓶颈,提升AI训练效率
为应对GPU集群间高并发数据传输需求,客户部署飞速(FS)N8560-32C数据中心交换机。该设备基于12.8Tbps无阻塞交换架构,提供32个100G QSFP28端口(支持40G/25G速率自适应),结合线速转发能力和智能流量调度,显著降低AI训练、模型推理等场景的网络延迟,缓解大规模计算任务中的带宽压力。
依托CLOS架构无损转发和RoCEv2技术,AI训练数据传输延迟降低至微秒级,实现零丢包传输。此外,该核心层低功耗交换机凭借紧凑型外形和多速率端口设计,配合12芯MTP® OM4光纤跳线进行高密度布线,节省70%机柜空间,大幅减少布线复杂度和维护成本,优化散热与能耗。
汇聚层:智能调度,高可靠组网保障业务连续性
在存储资源池化与跨层数据交互场景下,客户采用S3900-48T6S-R汇聚层交换机,通过8个25G自适应端口连接分布式存储节点,并借助6个100G上行链路(搭配QSFP-SR4-100G光模块)实现核心互联,构建分级带宽适配架构,提高了整体网络的高可靠性和高可用性。
此外,该48口千兆以太网交换机支持智能流量分级,可动态识别AI训练数据包并优先调度,避免非关键流量抢占带宽,保障AI训练数据完整性。
接入层:灵活扩展,提升运维效率
针对AI训练边缘接入场景,客户选用S3410-24TS-P交换机,其24个千兆电口为IP摄像头、无线AP等终端提供数据与电力传输,降低独立供电布线成本。同时该设备的4个万兆SFP+光口通过独立硬件通道构建带外管理网络,而其内置PoE+功能不仅简化IPMI设备供电,还可通过远程管控实现设备一键重启与状态监控,运维效率提升50%。
此外,客户搭配Cat6a网线连接终端设备,确保网络稳定传输,并且通过S3410-24TS-P接入层交换机配备集成Airware云管理平台,能够对跨境设备进行远程统一部署和管理,支持高达百万级以上设备运行维护,故障定位效率提升90%。基于大数据和管理平台云原生架构,该解决方案为未来企业算力网络提供弹性扩容基础,支持横向扩展至10,000节点,满足企业AI业务快速增长需求。

供应链保障:本地化仓储,极速交付
依托飞速(FS)本地化仓储网络,实现当天发货,客户有效规避跨境运输风险,不仅提高项目交付效率,还为客户提供了更灵活、可靠的供应链保障。
通过高性能交换机、智能化流量调度与跨境交付能力的深度融合,客户成功克服了带宽瓶颈、跨境管理复杂度及项目交付挑战,为AI训练、边缘计算等场景构建了可持续扩展的未来网络架构,实现企业数字化转型。
客户收益
突破AI训练网络瓶颈,实现性能跃升
客户通过N8560-32C核心交换机的32个100G QSFP28端口与CLOS架构,将网络带宽提升至传统方案的10倍,使得GPU集群通信延迟降低至3μs以下,AI模型训练周期缩短40%,显著提升计算资源利用率与任务完成时间。
高密度交换机部署,降低总拥有成本
客户利用高密度核心层交换机,节省70%机柜空间,优化企业数据中心资源利用率。此外,其采用S3410-24TS-P的接入层交换机搭载智能功耗管理功能,可根据PoE负载动态调整供电曲线,减少15%,有效降低长期运营成本。
弹性网络架构扩展设计,支撑未来AI算力增长
该AI网络架构支持横向扩展至10,000节点,满足客户未来3-5年的算力增长需求,为企业的AI训练、大数据分析及高性能计算提供坚实支撑。
统一管理平台配置,提升运维效率
客户部署的汇聚层交换机通过Airware云管理平台可实时状态监控与智能分析功能,支持跨境设备的一体化管理,确保故障定位时间缩短90%,运维团队能够快速响应问题,减少业务中断时间,提升整体网络可用性。
90%订单当日发货,确保业务连续性
客户通过飞速(FS)智能化仓储系统,可享受90%订单当天发货服务,大幅缩短项目部署周期,为业务连续性提供坚实保障。
客户证言
"飞速(FS)提供的解决方案充分满足AI算力网络的高标准需求,从核心到边缘的端到端设计,让我们在香港复杂环境下顺利完成交付。特别是N8560交换机的无损转发能力,提高了我们网络的整体传输速率。"
*文章来源于飞速(FS)官网