文章目录
- 零、Linux简介
- 1.配置环境
- 2.Linux历史
- 3.Linux模型
- 一、vim
- 二、Linux命令行 (shell命令)
- 1.常用命令与快捷键
- (1)常用命令
- ①man命令:查看帮助手册
- (2)快捷键
- 2.用户子系统
- (1)Linux用户
- (2)用户命令
- 3.文件子系统命令
- (1)目录命令
- 1.创建文件:mkdir
- 2.删除目录:rmdir
- 3.打印当前工作目录:pwd
- 4.切换当前工作目录:cd
- 5.复制:cp
- 6.重命名/移动文件:mv
- 7.删除文件和目录:rm
- 8.查看文件的目录项:ls
- 9.查看文件和目录所占用的磁盘空间:du
- 10.列出文件目录项结构:tree
- 11.别名:alias
- (2)文件命令
- 1.创建文件:echo、touch、vim
- 2.查找文件:which
- 3.查找文件:find
- 4.查看文件内容/拼接文件:cat
- 5.查看文件的前几行:head
- 6.查看文件的后几行:tail
- 7.分页浏览:more、less
- 8.搜索文件内容:grep
- 9.单词统计:wc (word count)
- 10.命令的组合:3种
- (1)多命令 `;`
- (2)管道(pipe) `|`
- (3)xargs:将cmd1输出的每一行,作为cmd2的命令行参数
- 11.文件的权限:`chmod` (change mode)
- 12.文件创建掩码:umask
- 13.链接:硬链接和符号链接
- 14.远程复制:`scp`
- 15.打包和压缩:`tar` (text archive)
- (3)通配符、正则表达式、重定向
- 三、编译工具链
- 1.编译
- (1)下生成可执行程序的整个过程
- (2)对应的 gcc 命令如下
- (3)条件编译
- 2.GDB调试
- (1)调试程序
- (2)coredump文件 (核心转储)
- 3.Makefile
- 6.完整的Makefile / makefile
- 7.非常通用的Makefile模板
- 4.库文件
- (1)静态库
- (2)动态库
- (3)库的生成
- 四、其他
- 1.修改代码模板:snippet.c
- 2.小知识储备
零、Linux简介
1.配置环境
0.安装unbuntu
1.静态IP地址:手动设置ip地址
instal net-tools
2.设置远程连接
网络协议SSH
sudo apt install ssh
3.安装vimplus
4.关闭主机前,先关闭虚拟机。否则会虚拟机损坏。
5.设置快照
6.daemon 守护进程 / 也是虚拟光驱软件
7.Linux哲学:
①一切皆文件
②没有消息就是最好的消息 (一般显示的消息是报错)
2.Linux历史
Unix → M → Linux
3.Linux模型
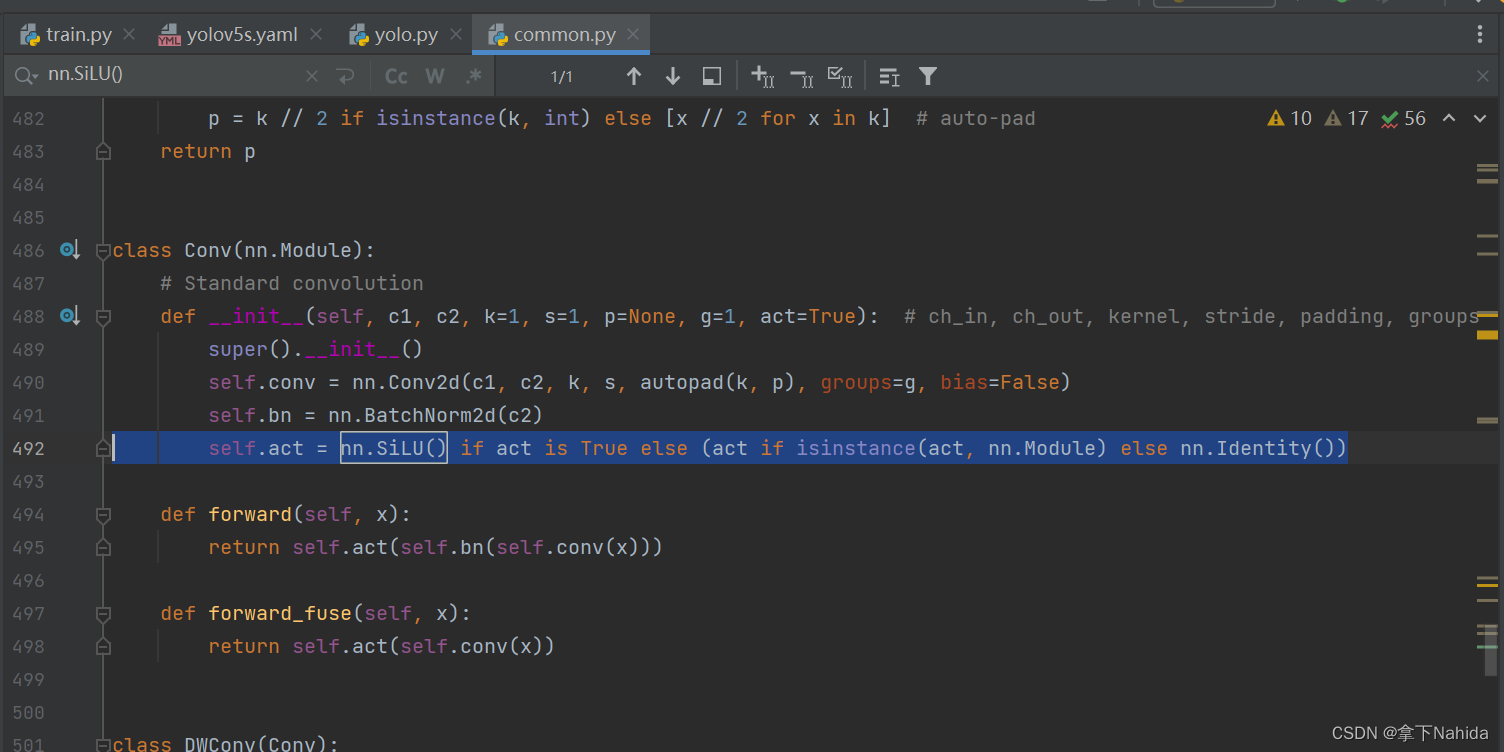
1.内核(Kernel):
①管理硬件资源:CPU(进程调度)、内存(内存管理)、外部设备(文件管理、网络通信、设备驱动)
②对上层应用程序提供接口(API),即系统调用
2.系统调用(System calls):内核给上层应用程序提供的接口
3.库函数(library function):对系统调用的包装,①方便使用 ②可移植性(不同操作系统的底层系统调用是不同的)
4.shell:命令行解释器
shell 是一个命令行解释器,它读取用户输入,然后执行命令,然后等待用户的下一
次输入
for(;;) {
read(cmd);
execute(cmd);
}
命令:一般来说,就是一些简单的可执行程序。
脚本:命令的集合
一、vim
1.理念:
①组合
②简单、快捷
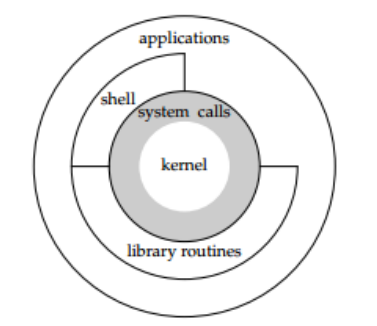
2.vim是多模式编辑器
①普通模式/命令模式 (NORMAL):查看代码,最常待的模式
②编辑模式/插入模式 (INSERT):编辑文本
③视图模式 (VISUAL / V-BLOCK):v 行选,crtl + v 列选
3.NORMAL模式命令
①短命令:a,i,A,I,o,O,v, crtl+v
②底部命令:以:开头,以[Enter]结尾, :wq
③其他模式按[Esc]返回NORMAL模式
4.移动光标 (motion)
| 命令 | 含义 |
|---|---|
| j | 下 |
| k | 上 |
| h | 左 |
| l | 右 |
| i | 在光标前面插入 |
| I | 在行首插入 |
| a | 在光标后面插入 |
| A | 在行尾插入 |
| o | 下面另起一行,在行首插入 |
| O | 上面另起一行,在行首插入 |
| [n]- | 上移n行 |
| [n]+ | 下移n行 |
| [n]G | 移动到第n行 |
| :n | 移动到第n行 |
| gg | 文首 |
| G | 文末 |
| 0 | 跳到行首 |
| ^ | 本行第一个非空白字符 |
| $ | 行尾 |
| w | 下一个单词的词首 |
| W | 下一个词的词首,以空白字符分割 |
| b | 上一个单词的词首 |
| B | 上一个词的词首,以空白字符分割 |
| t | 往后查找,光标置于该字符的前一个字符 |
| T | 往上查找,光标置于该字符的后一个字符 |
| f | 向后查找,光标置于该字符 |
| F | 向前查找,光标置于该字符 |
| x | 删除一个字符 |
| X | 删除前一个字符 |
| r | 替换一个字符 |
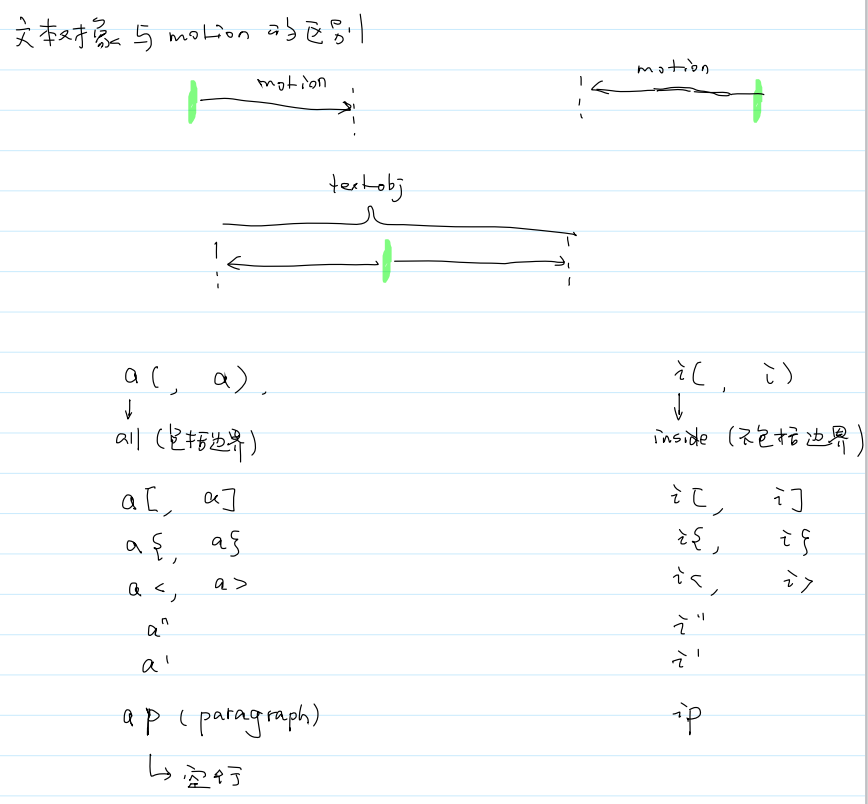
5.文本对象 (text object)
删除双引号内:ci"“,ca”"
ap (paragraph):整段,以空行为分割
①复制整段:yap
②删除整段:dap、cip
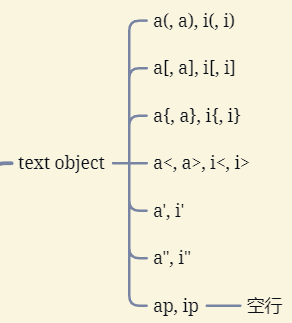
a (all):包括边界
i (inside):不包括边界
6.动作 (action)
d (delete) 删除
y (yank) 复制
c (change) 删除并进入编辑模式
c change模式,直接进入插入模式
gcc:注释/取消注释
7.组合
(1)action + motion
dw、d$、d0
cgg:光标删除到文首,并进入插入模式
cw:删除后面的单词,并进入插入模式
(2)n命令:某个命令做n次
(3)action + text object
8.撤销与恢复
u (undo):撤销
[crtl] + r (recovery):恢复
p:向后粘贴
P:向前粘贴
yy:复制
多个历史版本,两个栈实现前进后退
9.查找与替换



10.视图模式
选择范围,为了后面复制或删除
批量注释:ctrl + v ,选择范围,按gc
11.最小前缀原则:唯一识别,只写部分前缀即可。或者别名。
:w 就是 :write的缩写,保存(内存写回磁盘)。也可写:wri
:q 就是 :q的缩写,:q!是强制退出
:wq 是 保存并退出
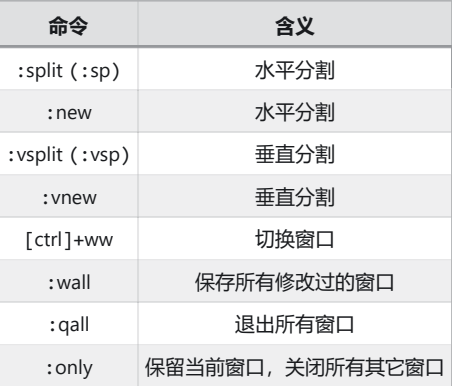
12.多窗口 / 分屏
:sp:水平分屏
:vsp:垂直分屏
:q 退出当前窗口
:only 除了当前窗口,退出其他窗口
:w 保存
13.配置vim
①配置文件:.vimrc (是一个脚本,rc是running command)
②安装vimplus
③再单独装ycm (you complete me)
rm -rf ~/.vim/plugged/YouCompleteMe
sudo apt install vim-youcompleteme
vim-addons install youcompleteme
二、Linux命令行 (shell命令)
1.常用命令与快捷键
(1)常用命令
| 命令 | 含义 |
|---|---|
| clear | 清屏 |
| touch | 创建文件 |
| ls -a | 全部显示,包括.开头的隐藏文件 |
| rm | 清除,rm * -rf |
| echo “I love xixi”> b.txt | 写入文件 |
| cat 文件名 (cat main.c) | 查看文件内容 |
| 执行程序 | gcc main.c -o main ./main |
| shutdown命令 | 关机命令 |
| reboot | 重启 |
| man 命令名 | manual手册,解释该命令 (be a man!) |
| gg = G | 全文对齐 |
| env | 查看环境变量 |
gcc:gnu c compiler
①man命令:查看帮助手册
1.man手册看哪些部分? (一手资料):

2.man手册的快捷键:
(1)翻页
↑、↓、f、b、d、u
↓:往下一行
d(down):往下翻半页
f(forward):往下翻一页
↑:往上一行
u(up):往上翻半页
b(backward):往上翻一页
(2)查找:/内容
查找下一个:n
查找上一个:N
(3)退出:q
3.man手册的数值的含义
①shell命令
②系统调用
③库函数

man 3 rmdir
4.man手册 (manual)
短选项:命令行
长选项:shell脚本
(2)快捷键
| 快捷键 | 功能 |
|---|---|
| Tab | 联想,命令补全 |
| ↑ | 上一条命令 |
| Ctrl + A | 将光标移动到最前面 |
| Ctrl + E | 将光标移动到最后面 |
2.用户子系统
(1)Linux用户
(1)root:根用户,超级用户
(2)sudoers:管理员用户。安装ubuntu时,创建的用户默认为sudoers。sudoers可以使用sudo命令临时提升权限为root
(3)普通用户
(2)用户命令
(1)创建用户 useradd
(2)删除用户 userdel
sudo userdel 用户名 -r #加-r,不仅删除用户,还将用户主目录中的文件和用户邮箱一起删除
(3)设置密码、修改用户密码 passwd
sudo passwd 用户名
(4)切换用户 su
(5)退出切换 exit
例题:
(填写执行的命令即可)
a. 创建 test1 用户,指定 test1 用户的 login shell 为 /bin/bash, 并给他创建家目录。
b. 将 test1 用户的密码修改为 123456 (或其它任意密码)
c. 切换到 test1 用户
d. 退出切换
e. 将 test1 用户删除,家目录也一起删除
a.sudo useradd test1 -m -s /bin/bash
b.sudo passwd test1123123
c.sudo su test1
d.exit
e.sudo userdel test1 -r
3.文件子系统命令
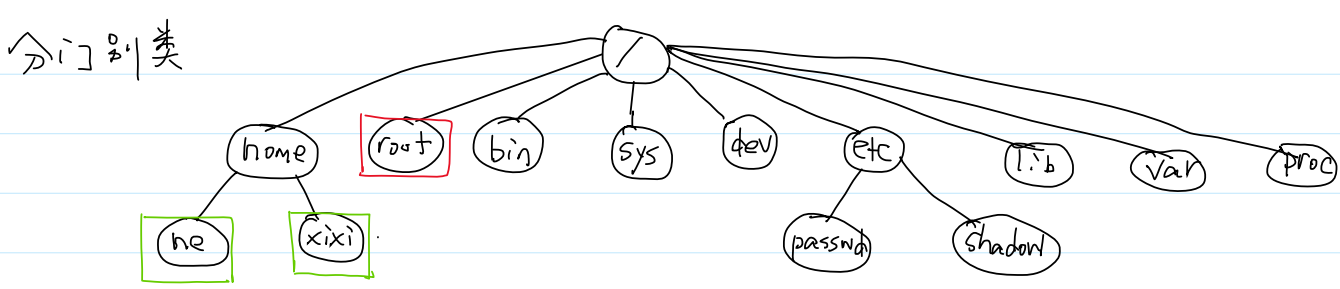
1.目录结构
根目录 /
bin:binary,可执行程序或脚本文件
sys:system,系统相关文件
dev:device,设备文件
proc:process,进程相关的数据
var:variable,经常发生变化的文件,比如日志文件
lib:库文件
root:超级用户
home:家目录,下面是普通用户
etc:存放配置文件和启动脚本
①passwd:man 5 passwd
②shadow:man 5 shadow
etc/passwd:存放账号
etc/shadow:存放密码

(1)目录命令
1.创建文件:mkdir
mkdir - p 创建文件 (-p是级联创建)

2.删除目录:rmdir
rmdir -p 删除空目录 (-p是级联删除)
3.打印当前工作目录:pwd
4.切换当前工作目录:cd
①. 当前目录
②… 上级目录
③/ 根目录
④~ 家目录
⑤- 上次目录,环境变量 OLDPWD
cd 是 change directory
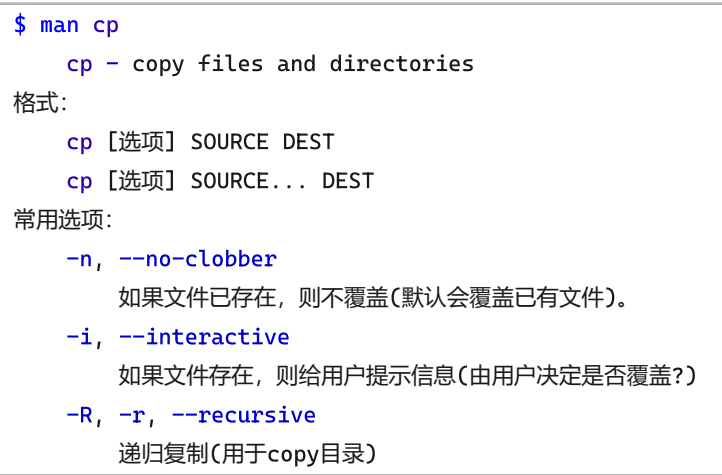
5.复制:cp
(1)常用格式
cp src des #复制文件
cp -r src des #递归复制目录
cp src1 src2 .. des #拷贝多个文件到目标目录
(2)常用选项
-r:递归
-n:不覆盖 (des不存在,则创建。若存在,则不复制)
-i :交互询问

6.重命名/移动文件:mv
(1)常用格式
①重命名
mv会默认覆盖同名文件,
mv 文件名1 文件名2
inode不变
虚拟文件系统

②移动文件
mv 文件名 目录名
(2)常用选项
-n:不覆盖
-i:交互式
7.删除文件和目录:rm
rm(remove)命令可以删除文件和目录。
rm -rf dir
①rm -r 递归删除 (-r 是recursively,递归地)
②-i:交互式
③-f:force,强制执行,不给提示。-f 强制,不给消息。有些用户不想看消息,不想交互,就用-f,默默地强制执行。
8.查看文件的目录项:ls
ls -l:查看目录项
(1)常用选项
①-l:长格式,详细信息
②ls -a:显示所有内容,包括 .和…、隐藏文件
③-h:人类可读的
④-i:物理inode编号
(2)读写权限
①可执行程序:775 rwx rwx r-x (八进制,r w x 分别值为4 2 1 )
②普通文件:664 rw- rw- r–
③7列:九个字符(三组)表示权限、硬链接数、拥有者、拥有组、文件大小、最近修改时间、文件名

ls 目录名 #显示指定目录的内容
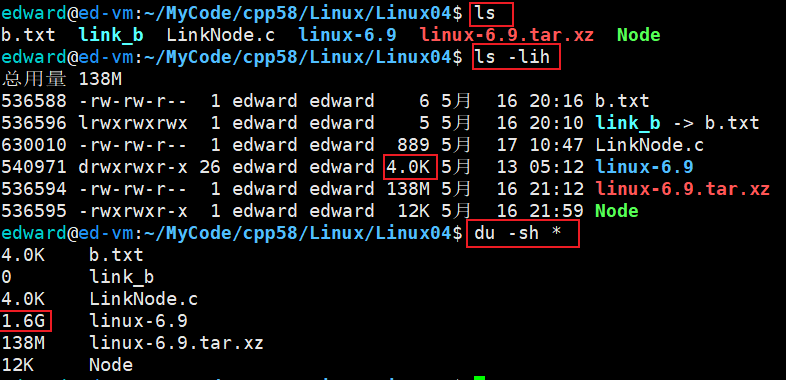
9.查看文件和目录所占用的磁盘空间:du
du是 disk usage 的缩写。
当使用ls -lih时,目录大小永远只显示4K,而无法递归地显示目录的真实大小,这时候就要使用du命令。
du -sh 路径
10.列出文件目录项结构:tree
11.别名:alias
①查看别名:alias
②设置别名:alias h=‘history’

(2)文件命令
1.创建文件:echo、touch、vim
①echo:输入简短内容,不存在则创建,已存在则覆盖。echo "hello Linus" > a.txt"
②touch:文件存在,修改时间戳;文件不存在,创建空文件
③vim:编辑文件

2.查找文件:which
which:查找文件 (查找可执行程序,即查找命令)
which 可执行程序名
which 可执行程序名 -a (遍历完PATH)
which是通过PATH环境变量,查找目录路径
3.查找文件:find
3.find:查找文件 (在目录中递归地查找)
find . -name "a.txt"



根据时间查找
-mtime 1 #1到2天内
-mtime +1 #2天前
-mtime -1 #0到1天内


4.查看文件内容/拼接文件:cat
4.cat
①看文件内容
cat -n 带行号
②拼接文件: cat text1 text2 > text3
5.查看文件的前几行:head
head -n 5 #只查看前5行
head -n -5 #除了后5行,都显示
6.查看文件的后几行:tail
tail -n 5
tail -n +5
tail -F #实时显示文件追加的内容(如日志文件)
7.分页浏览:more、less
1.more:分页浏览
b、f或空格翻页
2.less:分页浏览 (more的升级版)
可以上下滚轮
8.搜索文件内容:grep
grep (globally search for a regular expression)命令可以用于搜索文件内容
grep -nE "pattern" 文件名
①-E:扩展功能(建议都加)
②-n:行号
③-i:忽略大小写
④-c:显示匹配了多少行的数量

例题:
搜索 Linux 内核源码中,包含调用 exit 函数的所有行。
grep -nE "\<exit\(.*\)" linux-6.9 -r #问题: *会多匹配内容,遇到)不结束
grep -nE "\<exit\([^)]*\)" linux-6.9 -r #问题:[^)]在遇到第一个)就结束。但是 exit() 的()中可能还有()
9.单词统计:wc (word count)
wc 文件名
行数 单词数 字节数 文件名
①wc -l :统计行数
10.命令的组合:3种
(1)多命令 ;
cmd1 ; cmd2
先执行cmd1,再执行cmd2。如:mkdir dir ; cd dir
(2)管道(pipe) |
1.管道:cmd1的输出 作为 cmd2的输入
cmd1 | cmd2
2.原理:将cmd1的stdout 重定向 到 管道的写端,将cmd2的stdin 重定向 到 管道的读端

3.示例
history | wc -l #得到1000

(3)xargs:将cmd1输出的每一行,作为cmd2的命令行参数
(1)格式
cmd1 | xargs cmd2
(2)原理:
①将cmd1的stdout 重定向 到 管道的写端,将cmd2的stdin 重定向 到 管道的读端
②xargs将stdin里的每一行 作为 命令行参数

(3)示例
find . -name "*.c" | xargs grep -nE "\<main\("

11.文件的权限:chmod (change mode)
目录:
r:查看目录项 (ls、tree)
w:添加和删除目录项
x:目录最基本的权限。若没有x权限,则不能r和w。不能cd到该目录。

(1)模型
目录文件的模型:
目录项以链表互相连接

(2)命令
①文字设定法: chmod [ugoa][±-][rwx] filename
②数字设定法: chmod mode filename
chmod 755 client //数字设定法
chmod 664 a.txt //数字设定法
chmod a+x hello.py //文字设定法

12.文件创建掩码:umask
想去掉的权限

13.链接:硬链接和符号链接
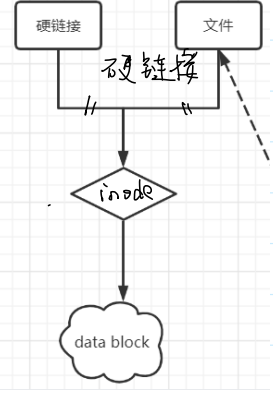
(1)硬链接 (hard link):
①原理:
i.共享inode结点
ii.引用计数。每增加一个硬链接,引用计数+1,引用计数为0才会真正删除文件。修改任意一个文件的内容,所有共享引用计数的文件内容都会改变。
②命令:ln (link)
③格式也是 - ,普通文件
ln a.txt link_a
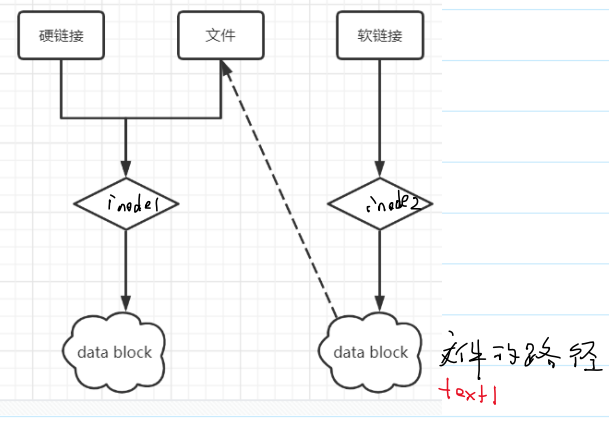
(2)符号链接 /软连接 (symbolic link):
①命令:ln -s
②可以指向一个不存在的文件,大小为指向的路径名
③格式是 l
④类似C语言的指针、Windows的快捷方式。除了rm命令,符号链接可以解引用,修改软连接的内容,原内容也会修改。
ln -s b.txt link_b

14.远程复制:scp
上传:将本地的文件复制到远程
下载:将远程的文件复制到本地
远程路径:用户名@IP:绝对路径
递归复制目录要加 -r

scp ./file edward@192.168.248.136:~/MyCode/cpp58/Linux/Linux04

非常实用,以后互相传文件不需要通过微信了。windows给ubuntu传文件也不需要通过WinSCP了。
15.打包和压缩:tar (text archive)
(1)选项,不加- (vf常用)
c:打包(创建包裹),默认包裹名结尾 .tar
r:追加
tvf 查看包裹内容
x:解打包
加z,即使用gzip算法进行压缩或解压缩。默认文件结尾 .tar.gz
tar xvf linux-6.9.tar.xz #解压命令


若是.zip,需要使用
unzip 包裹名命令
(3)通配符、正则表达式、重定向
1.通配符:匹配文件名字
*:匹配任意多个字符 (0-n个)
?:匹配任意一个字符
集合/类:[cha]匹配集合内任意一个字符,[!cha]匹配集合外任意一个字符
例如:[abc]、[0-9]、[0-9a-zA-z_]、[!0-9a-zA-z_]
2.正则表达式:匹配文件内容
(1)基本单位:
①普通字符
②转义字符
③.:匹配任意一个字符
④集合:[abc]
⑤group:(abc)

(2)基本操作:
①连接:

②重复:前一个基本单位重复的次数


(3)指定基本单位出现的位置
①^:行首,“^abc”
②$:行尾,“xyz$”
③\<:词首
④\>:词尾
[^abc]:匹配除了 “a”、“b”、和 “c” 之外的任何单个字符
.*:任意字符,重复任意次
3.重定向 >

三、编译工具链
前面我们写程序的时候用的都是集成开发环境 (IDE: Integrated Development
Environment),集成开发环境可以极大地方便我们程序员编写程序,但是配置起来也
相对麻烦。在 Linux 环境下,我们用的是编译工具链,又叫软件开发工具包(SDK:
Software Development Kit)。Linux 环境下常见的编译工具链有:GCC 和 Clang,我
们使用的是 GCC。
1.编译
gcc、g++分别是 gnu 下的 c 和 c++ 编译器。
$ sudo apt install gcc gdb g++ #安装gcc和gdb
$ gcc -v #查看gcc的版本
(1)下生成可执行程序的整个过程
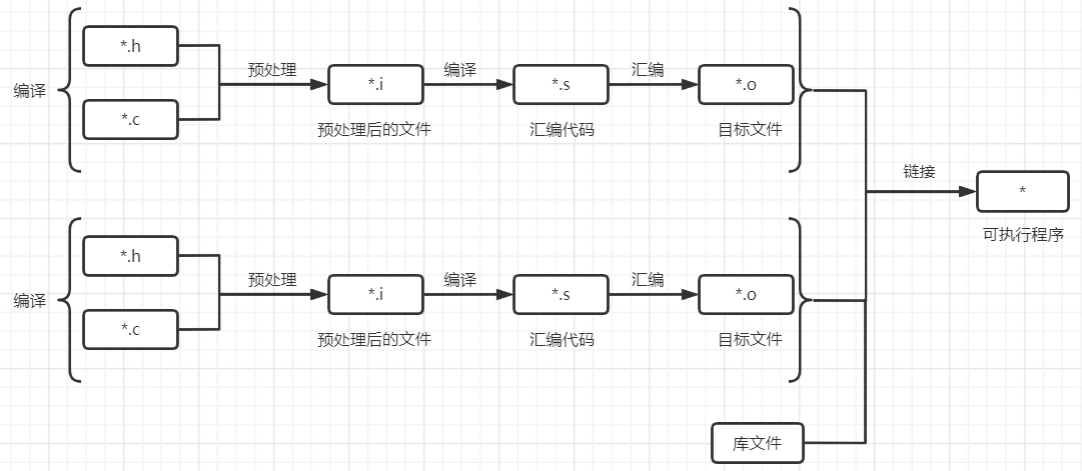
(2)对应的 gcc 命令如下
gcc -E hello.c -o hello.i #-E 预处理,生成 预处理后的文件
gcc -S hello.c -o hello.s #-S 预处理+编译,生成 汇编代码
gcc -c hello.c -o hello.o #-c 预处理+编译+汇编,生成 目标文件
gcc hello.c -o hello #什么都不加,生成 可执行程序
gcc hello.c -o hello -l库名 #-l 链接库
| 选项 | 含义 |
|---|---|
| -Wall | 生成所有警告信息 (warning all) |
| -g | 调试 |
| -Dmacro | 相当于在文件开头加上了 #define macro |
| -Dmacro=value | 相当于在文件开头加上了 #define macro value |
| Idir | 指定#include头文件的优先查找的目录,找不到再到当前目录、系统的include目录查找 |
| -O0,-O1,-O2,-O3 | -O0不优化(开发环境),-O1和-O2(生产环境),-O3是激进的优化策略(一般不使用),Optimize |
(3)条件编译
1.条件编译的3种预处理指令:

①#if
#if 常量表达式
...
#endif
(2)#if defined(macro)
#if defined(DEBUG)
...
#endif
②#ifdef (是上文的语法糖)
#ifdef DEBUG
...
#endif
③#ifndef
#ifndef 标识符
...
#endif
2.条件编译的作用/适用场景:
(1)编写可移植的代码:
#ifdef WIN32
...Windows的代码块
#elif MAC_OS
...
#elif LINUX
...
#endif

(2)为宏提供默认定义
我们可以检测一个宏是否被定义了,如果没有,则提供一个默认的定义:
#ifndef MAXSIZE
#define MAXSIZE 4096
...
#endif
(3)避免头文件重复包含
第一次碰到该宏,会定义该宏,并执行代码块。
第二次碰到该宏,因为已经定义过该宏,会跳过代码块。
宏的命名就是为了标识该头文件。
#ifndef __WD_FOO_H //若没有定义过该宏,则定义该宏
#define __WD_FOO_H //下次再碰到,就已经定义了该宏,会直接跳过
...
#endif
#ifndef _HELLO_H_
#define _HELLO_H_
...
#endif
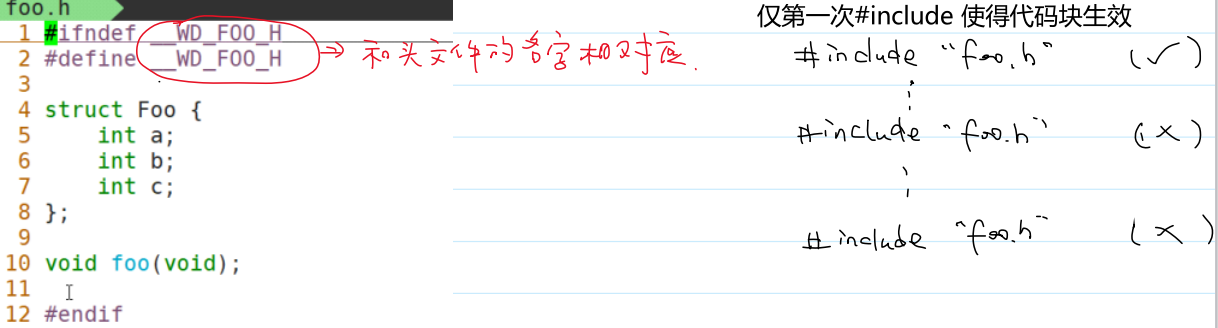
(4)调试程序:临时屏蔽包含注释的代码

2.GDB调试
1.观念:调试程序的难度是写程序的两倍
2.调试程序的步骤:调试程序要 [走一走,停一停,看一看]。看程序的状态是否和预期的一致。(调试程序之前,一定要有预期)
若不一致:
i.预期错了:加深对问题的理解
ii.程序错了:线索,指向真正出错的地方
(1)调试程序
0.记得加-g选项,才能gdb。否则会显示没有符号表(no symbol table)被读取。请使用 "file" 命令。
gcc hello.c -o hello -g [-Wall]
1.进入GDB调试界面的两种方式
gdb executable_name #不设置任何命令行参数
gdb --args executable_name arg1 arg2 ... #设置命令行参数
2.查看源代码 list,但是更建议再开一个窗口用vim
2.设置命令行参数
(gdb) set args arg1 arg2 ...
3.打断点:break/b n
(gdb) break 20 # 在第20行设置断点
(gdb) break main # 在main函数的开头设置断点
(gdb) break scanner.c:20 # 在scanner.c文件的第20行设置断点
(gdb) break scanner.c:scanToken # 在scanner.c文件的scanToken函数开头设置断点
4.查看断点:info break/ i b
5.删除断点:delete 断点编号
(gdb) delete 2 #删除2号断点
(gdb) d #删除所有断点
6.执行程序:run/r
7.逐过程/步过:next/n
遇到函数调用,它不会进入函数,而是把函数调用看作一条语句。
8.单步调试 (逐语句/步入):step/s
遇到函数调用,会进入函数里面
9.跳出函数(步出):finish
执行完当前被调函数,回到主调函数。(原理:执行完栈顶的栈帧,并出栈,然后停下)
10.继续:continue/c
执行到逻辑上的下一个断点
11.忽略断点:ignore
我们可以用 ignore 命令来指定忽略某个断点多少次,这在调试循环的时候非常有用:
格式: ignore N COUNT
常见用法: ignore 1 10 #忽略1号断点10次

12.退出GDB界面:qiut/q
看一看 [查看程序的状态]:print EXP、display EXP、info display、undisplay 编号、backtrace、frame 栈帧编号、info args、info locals、info registers
13.监视
(1)打印表达式的值:print/p 表达式
print/p EXP
print/p EXP=value
(2)自动展示表达式的值:display
display EXP #自动展示EXP
info display #显示所有自动展示的表达式信息
undisplay [n] #删除所有或[n]号自动展示的表达式
14.查看内存
x/4xb arr+5
x/1dw arr+5 #查看值
x/10dw arr #数组的值
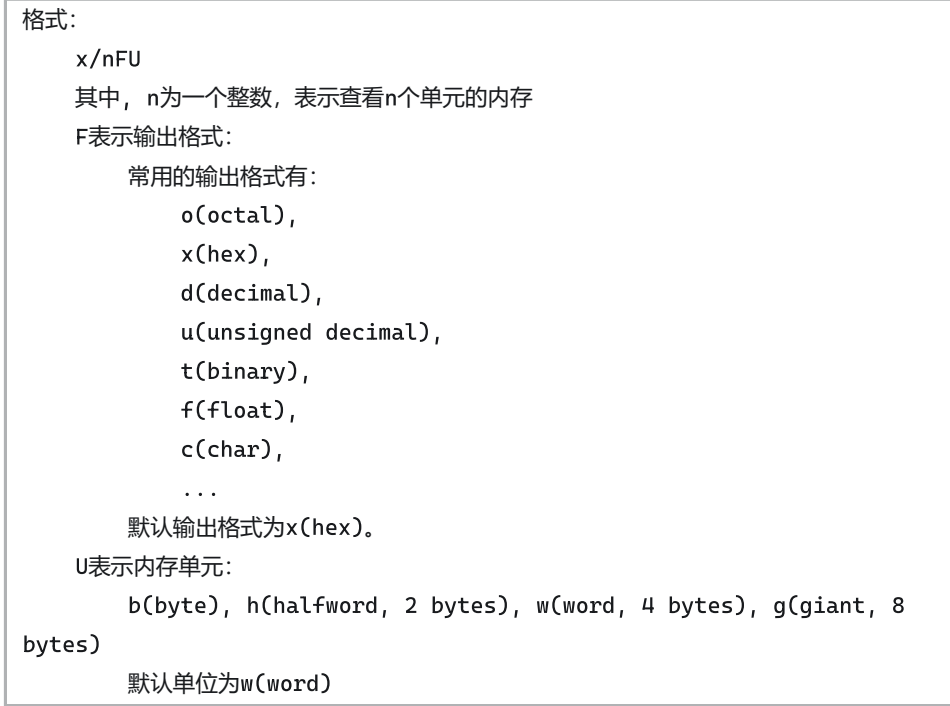
15.GDB帮助手册:help 要查看的命令
(2)coredump文件 (核心转储)
1.core文件:
(1)是什么:程序异常终止时的运行状态的快照 (程序及内存)
(2)为什么需要,作用:一定能实现错误复现,因为core文件保存了当时内存崩溃的场景,core文件可以恢复场景。
多线程的错误很难还原,在生产环境下的程序,可能每次运行结果都不同。不一定能复现,而core文件就可以用来复现错误
2.开启生成core文件
(1)查看系统是否允许生成Coredump文件
$ ulimit -a #查看
...
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
...
$ ulimit -c unlimited #将core文件的大小临时设置为不受限制
(2)设置Coredump文件的格式
$ sudo vim /etc/sysctl.conf
kernel.core_pattern = %e_core_%s_%t #%e:executable-name,%s:signal,%t:timestamp
$ sudo sysctl -p #让配置生效
(3)使用Coredump文件调试程序
①查看信号异常终止的数字对应的宏:kill -l (list)
②用GDB查看core文件,复现错误
$ gcc test.c -o test -g # 生成可执行程序test
$ ./test # 运行test
#报错了,并生成了core文件,可使用ls命令查看生产的core文件名
$ gdb test test_core_8_1679196427 # 使用Coredump文件调试程序:gdb 可执行程序名 core文件名
③查看栈:backtrace/bt

④查看栈帧:frame n
⑤查看传递的参数的值:info args
⑥查看局部变量的值:lnfo locals
⑦查看寄存器的 值:info registers
普通GDB也可以查看 info args、info locals,并不一定需要有core文件
3.Makefile
1.Makefile是什么 (what)
Makefile:脚本文件
make工具:解释并执行Makefile

2.Makefile的作用 (why)
(1)自动编译:写好 Makefile 之后,输入一个 make命令就可以构建整个项目了,自动进行编译。
(2)增量编译:Makefile只编译新增的和修改过的.c文件 (-c生成.o文件)
不需要全量编译,全量编译需要若干个小时。
编译很慢,链接很快。核心是.o目标文件
3.书写Makefile (how)
特点:Makefile的语法要求非常严格
main: main.o add.o sub.o mul.o div.o
gcc main.o add.o sub.o mul.o div.o -o main
main.o: main.c algs.h
gcc -c main.c -Wall -g
add.o: add.c algs.h
gcc -c add.c -Wall -g
sub.o: sub.c algs.h
gcc -c sub.c -Wall -g
mul.o: mul.c algs.h
gcc -c mul.c -Wall -g
div.o: div.c algs.h
gcc -c div.c -Wall -g
规则:目标,依赖,命令
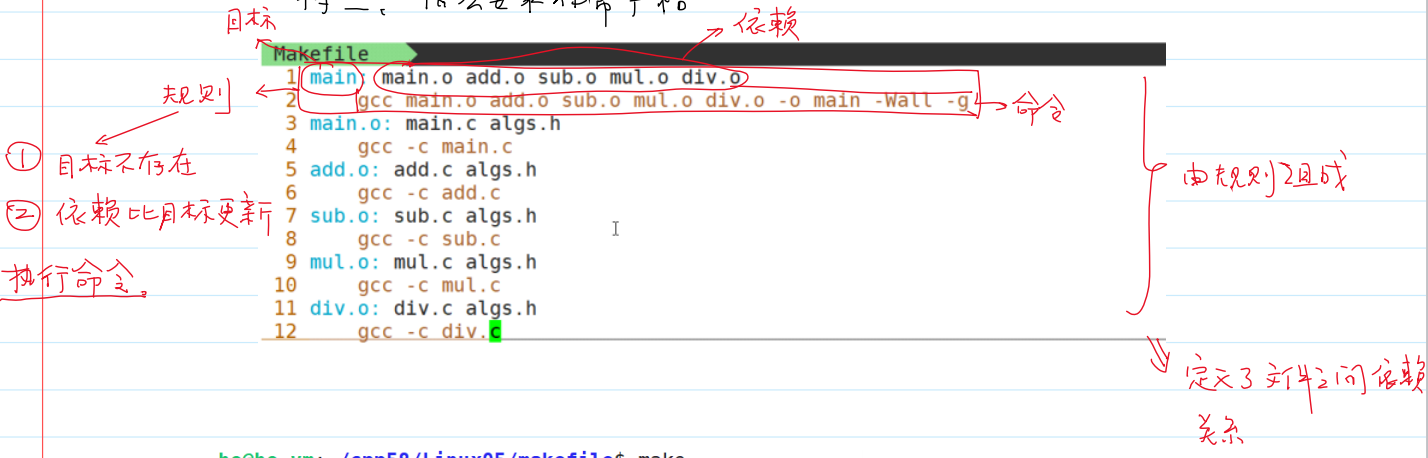
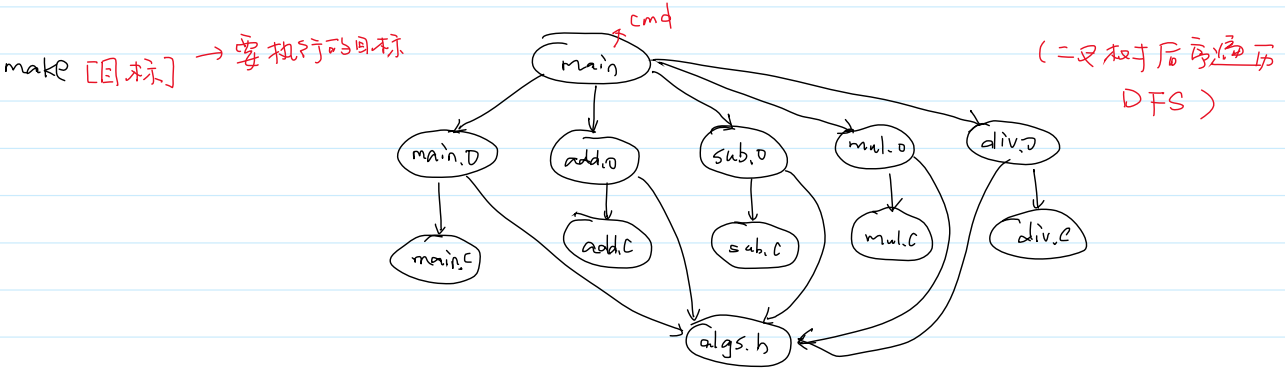
4.Makefile的工作原理:
(1)通过有向无环图(DAG)来管理依赖
make [目标],若不指定目标,则自动选择第一个target作为目标。
make 伪目标,才会走.PHONY里的

(2)拓扑排序
①保证了依赖关系
②使用DFS,对DAG进行拓扑排序
5.伪目标
每次都能执行的命令,但不生成文件
.PHONY: clean rebuild #一定执行
clean:
rm -rf *.o amin
rebuild: clean main
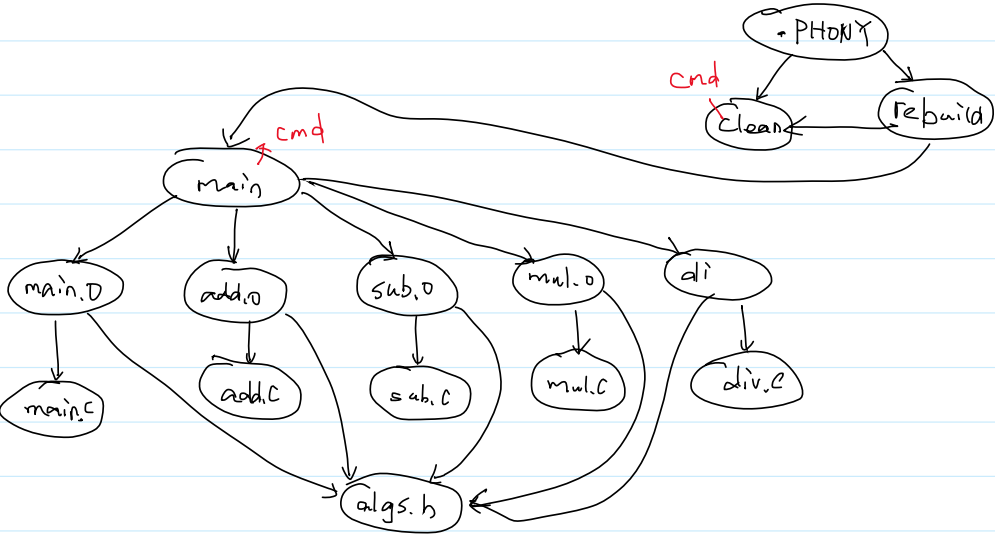
6.完整的Makefile / makefile
main: main.o add.o sub.o mul.o div.o
gcc main.o add.o sub.o mul.o div.o -o main
main.o: main.c algs.h
gcc -c main.c -Wall -g
add.o: add.c algs.h
gcc -c add.c -Wall -g
sub.o: sub.c algs.h
gcc -c sub.c -Wall -g
mul.o: mul.c algs.h
gcc -c mul.c -Wall -g
div.o: div.c algs.h
gcc -c div.c -Wall -g
.PHONY: clean rebuild
clean:
rm -f main main.o add.o sub.o mul.o div.o
rebuild: clean main
其对应的源码:
// algs.h
#ifndef __WD_ALGS_H
#define __WD_ALGS_H
int add(int, int);
int sub(int, int);
int mul(int, int);
int div(int, int);
#endif
// add.c
#include "algs.h"
int add(int a, int b) {
return a + b;
}
// sub.c
#include "algs.h"
int sub(int a, int b) {
return a - b;
}
// mul.c
#include "algs.h"
int mul(int a, int b) {
return a * b;
}
// div.c
#include "algs.h"
int div(int a, int b) {
return a / b;
}
// main.c
#include "algs.h"
#include <stdio.h>
int main(int argc, char* argv[])
{
printf("add(7,3) = %d\n", add(7,3));
printf("sub(7,3) = %d\n", sub(7,3));
printf("mul(7,3) = %d\n", mul(7,3));
printf("div(7,3) = %d\n", div(7,3));
return 0;
}
使用Makefile编写shell脚本:
make、make clean、make build
test: test.o
gcc test.c -o test #编译链接
./test #执行程序
.PHONY: clean rebuild
clean:
rm test test.o
rebuild: clean test
7.非常通用的Makefile模板
Srcs := $(wildcard *.c)
Outs := $(patsubst %.c, %, $(Srcs))
CC := gcc
CFLAGS = -Wall -g -pthread
ALL: $(Outs)
%: %.c
$(CC) $< -o $@ $(CFLAGS)
.PHONY: clean rebuild ALL
clean:
$(RM) $(Outs)
rebuild: clean ALL
8.变量
(1)变量在声明时需要赋初始值;使用时,需要给在变量名前加上$符号,如果变量名包含
多个字符,我们应该用小括号 () 或大括号 {} 把变量括起来。
(2)使用变量,改写上文的Makefile
Objs := main.o add.o sub.o mul.o div.o
Out := main
$(Out): $(Objs)
gcc $(Objs) -o $(Out)
main.o: main.c algs.h
gcc -c main.c -Wall -g
add.o: add.c algs.h
gcc -c add.c -Wall -g
sub.o: sub.c algs.h
gcc -c sub.c -Wall -g
mul.o: mul.c algs.h
gcc -c mul.c -Wall -g
div.o: div.c algs.h
gcc -c div.c -Wall -g
.PHONY: clean rebuild
clean:
rm -f $(Out) $(Objs)
rebuild: clean $(Out)
(3)预定义变量
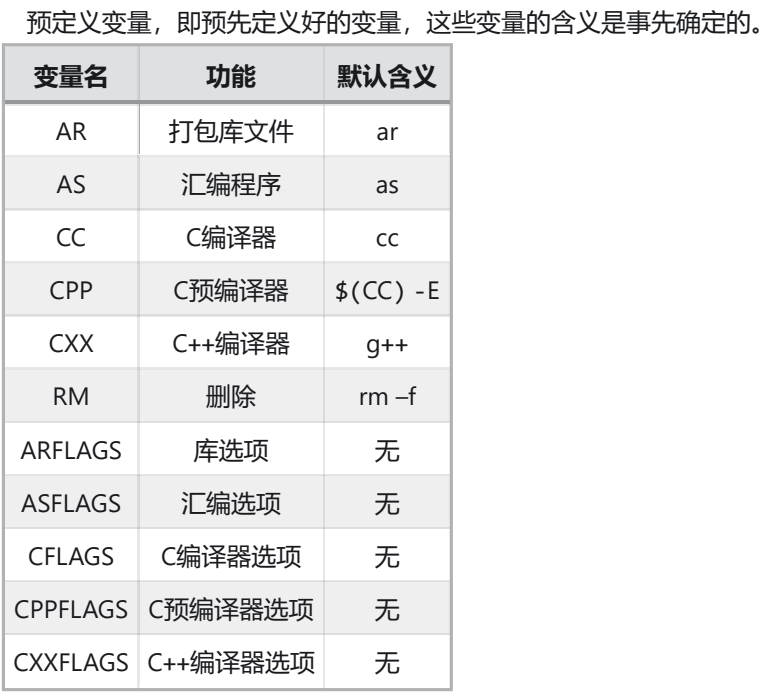
使用预定义变量,改写上文的Makefile
Objs := main.o add.o sub.o mul.o div.o
Out := main
CC := gcc
CFLAGS := -Wall -g
$(Out): $(Objs)
$(CC) $(Objs) -o $(Out)
main.o: main.c algs.h
$(CC) -c main.c $(CFLAGS)
add.o: add.c algs.h
$(CC) -c add.c $(CFLAGS)
sub.o: sub.c algs.h
$(CC) -c sub.c $(CFLAGS)
mul.o: mul.c algs.h
$(CC) -c mul.c $(CFLAGS)
div.o: div.c algs.h
$(CC) -c div.c $(CFLAGS)
.PHONY: clean rebuild
clean:
$(RM) $(Out) $(Objs)
rebuild: clean $(Out)
(4)规则中的特殊变量

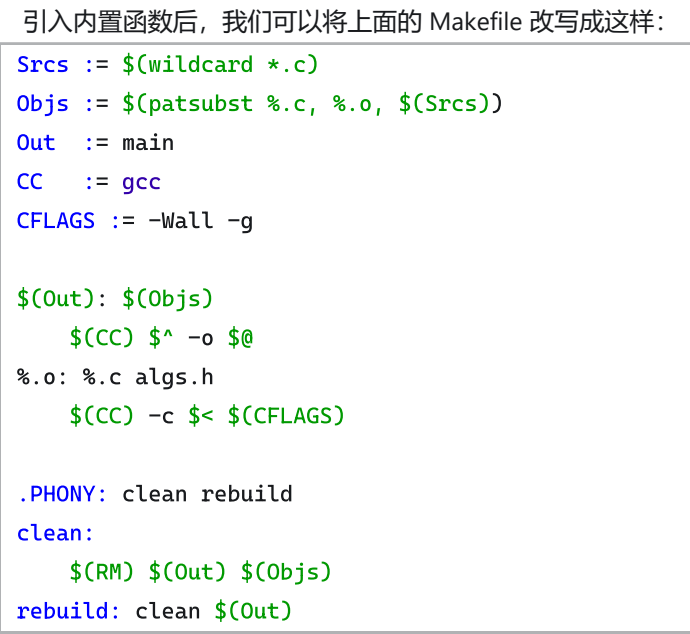
引入自动变量后,我们可以将上面的 Makefile 改写成:
Objs := main.o add.o sub.o mul.o div.o
Out := main
CC := gcc
CFLAGS := -Wall -g
$(Out): $(Objs)
$(CC) $^ -o $@
main.o: main.c algs.h
$(CC) -c $< $(CFLAGS)
add.o: add.c algs.h
$(CC) -c $< $(CFLAGS)
sub.o: sub.c algs.h
$(CC) -c $< $(CFLAGS)
mul.o: mul.c algs.h
$(CC) -c $< $(CFLAGS)
div.o: div.c algs.h
$(CC) -c $< $(CFLAGS)
.PHONY: clean rebuild
clean:
$(RM) $(Out) $(Objs)
rebuild: clean $(Out)
9.模式规则
模式规则"%.o : %.c",表示的含义是:所有的.o文件依赖于对应的.c文件。
下面示例就是 Makefile 的一个模式规则,由所有的.c文件生成对应的.o文件:
%.o: %.c
$(CC) -c $< -o $@
有了模式规则后,我们可以这样写 Makefile:
Objs := main.o add.o sub.o mul.o div.o
Out := main
CC := gcc
CFLAGS := -Wall -g
$(Out): $(Objs) #Objs := main.o add.o sub.o mul.o
div.o
$(CC) $^ -o $@
%.o: %.c algs.h #这里应用了Makefile的隐式推导,%.o是与上一个规则的依赖进行匹配,即$(Objs)
$(CC) -c $< $(CFLAGS)
.PHONY: clean rebuild
clean:
$(RM) $(Out) $(Objs)
rebuild: clean $(Out)
10.内置函数
(1)通配符函数

(2)模式替换函数

4.库文件
库文件是目标文件(*.o)的集合
| 静态库 | 动态库 | |
|---|---|---|
| Windows | .lib | .dll |
| Linux | .a | .so |
(1)静态库
静态库:链接阶段,将库代码嵌入可执行程序,合为一体
优点:移植方便,程序运行时与静态库再无瓜葛。当链接好静态库后,即使静态库坏了、没了,依然不影响已生成的程序的执行。
缺点:①浪费空间,每个进程都有一份静态库的副本 ②对程序更新,部署,发布不友好,当静态库更新时,所有用户都需要重新下载安装的可执行程序。
(2)动态库
动态库:对函数的链接,是在运行时完成的
优点:①节省内存空间,动态库可以被多个进程共享 ,动态库(dynamic library)又称为共享库(shared library) ②对程序的更新,部署,发布友好,只需要更新动态库就好了
缺点:程序运行时,依赖动态库,移植不方便
(3)库的生成
1.生成静态库
ar crsv lib库名.a add.o sub.o mul.o div.o #静态库打包,用archive
sudo mv lib库名.a /usr/lib
gcc main.c -o main -l库名 #需要加-l选项,链接库
2.生成动态库
gcc -c *.c -fpic #生成动态库的目标文件,要加-fpic
gcc -shared *.o -o libalgs.so #打包生成共享库,用gcc
sudo mv libalgs.so /usr/lib #移动到系统的库目录下
gcc main.c -o main -l库名 #同名的静态库和动态库都存在时,默认加载动态库
3.修改版本
libalgs.so当作一个符号链接,其他的带版本号是真的动态库
sudo ln -s libalgs.so.001 libalgs.so #这样libalgs.so就仅仅只是一个符号链接
四、其他
1.修改代码模板:snippet.c
vim ~/.vim/plugged/prepare-code/snippet/snippet.c
2.小知识储备
1.字段与字段之间,以冒号:分隔
2.Windows回收站
其实是一个文件夹,Windows的删除其实是mv操作。Linux没有回收站。
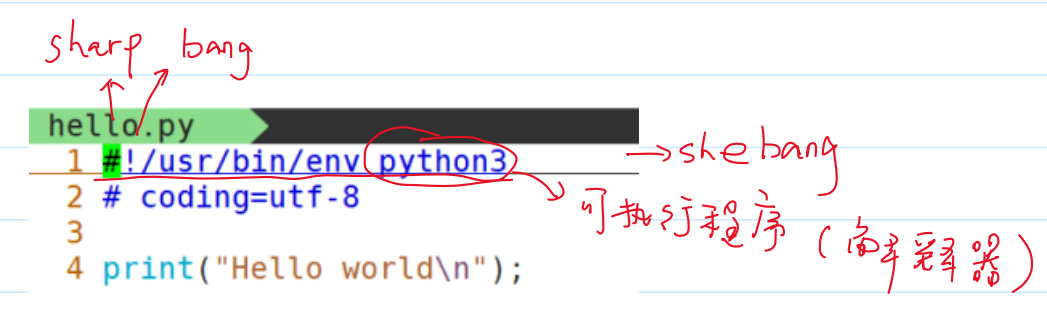
3.脚本
Python脚本




094:素数回文095:活动安排096:合唱团](https://img-blog.csdnimg.cn/direct/f7384f757a4a4800bf884ac0d20cf1d2.png)