目录
1.优化一:减小锁粒度
2.优化二:只针对写操作加锁
3.优化三:CAS
4.优化四:扩容方式
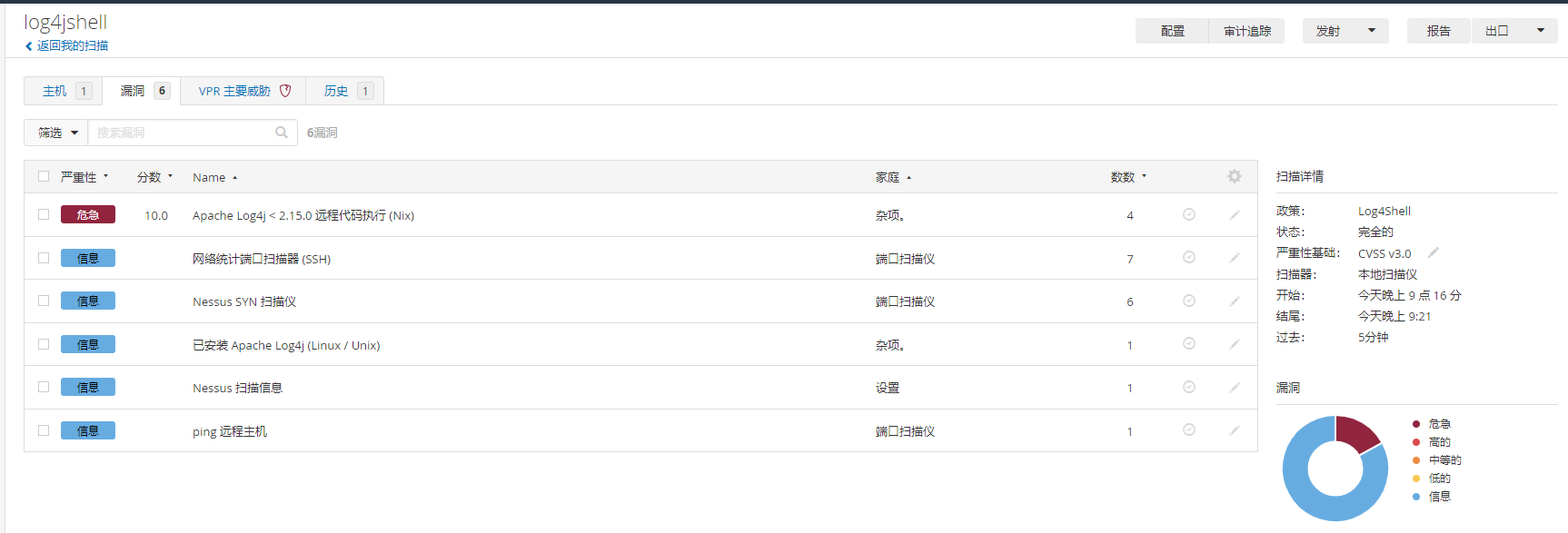
HashMap是线程不安全的,HashTable是线程安全的,关键方法加锁了.我们更推荐的是ConcurrentHashMap ,更优化的线程安全哈希表
接下来我们总结一下ConcurrentHashMap 进行了哪些优化,比HashTable好在哪里
1.优化一:减小锁粒度
最关键的优化:ConcurrentHashMap 相比于HashTable大大缩小了所冲突的概率,将一把大锁转换成多把小锁了
Hash Table做法是直接在方法上加synchronized,相当于给this加锁,只要操作哈希表上的任意元素,都会产生加锁,也就都可能发生锁冲突!
实际上不难发现,基于哈希表的结构特点,有些元素并发操作的时候,是不会产生线程安全问题的,也不需要锁控制!我们看看哈希表的结构
 如果此时,元素12在同一个链表上,线程A修改元素1,线程B修改元素2,是否有线程安全问题呢??
如果此时,元素12在同一个链表上,线程A修改元素1,线程B修改元素2,是否有线程安全问题呢??
修改(包括增删改),很明显是会有线程安全问题的,如果元素相邻,并发的删除/插入时,就需要修改两个节点的next的指向,这个情况是需要加锁的!再来看这种情况:

如果元素3和元素4 没有在相同的链表上,此时多线程并发操作34就不会有线程安全问题 ,也就相当于多个线程并发修改不同的变量,是没有线程安全问题的,也就不需要加锁
但是哈希表时直接加了个大锁
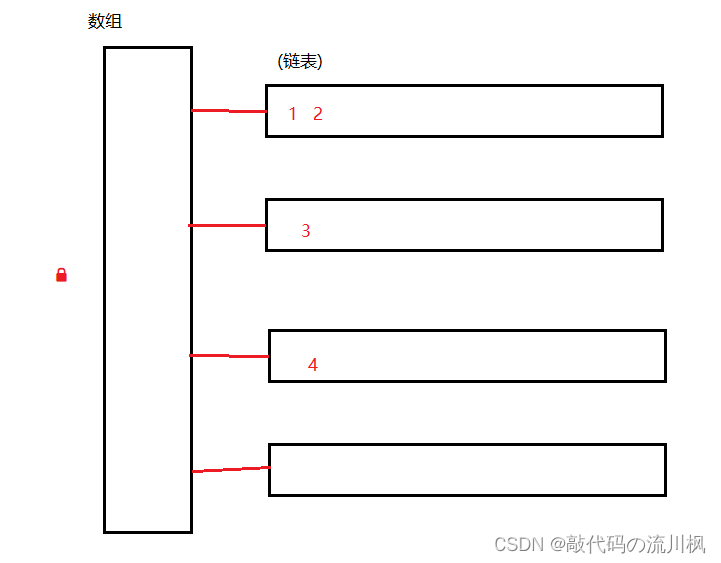
无论是12还是34这种情况,都是直接加锁,串行化了,那么就大大提高了锁冲突的概率,任何两个元素都会有锁冲突,即使是不在同一个链表上的,这也是不用哈希表的最主要原因!!
那么ConcurrentHashMap又是如何优化的呢?
ConcurrentHashMap的做法是:每个链表都有各自的锁,而不是整个哈希表只用一把锁了,具体来说,就是使用每个链表的头节点,作为锁对象.
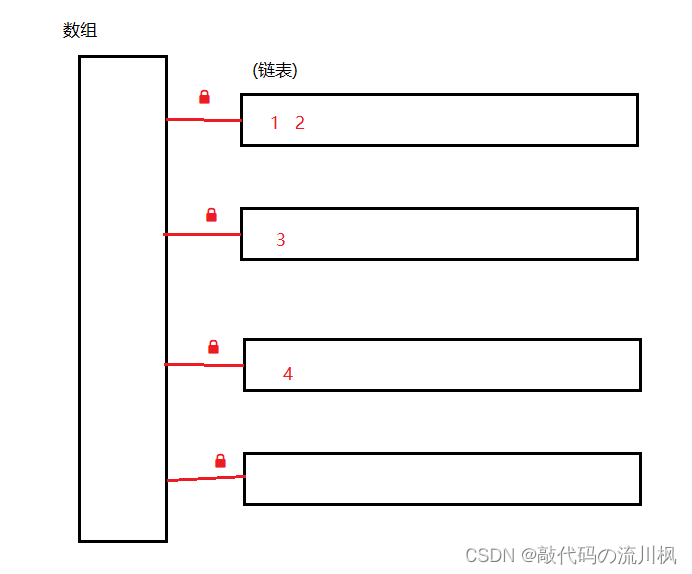
两个线程针对同一个锁对象加锁才会产生锁竞争,才发生阻塞等待,针对不同的锁对象时不会有锁冲突的,所以就从哈希表的两个任意元素之间都有锁冲突转化为了只有同一链表上的任意元素之间才有锁冲突!!
此时是把锁的粒度变小了,针对12情况,是同一个链表上的元素,是针对相同的锁对象进行加锁,会有锁竞争,会保证线程安全.针对34情况,是针对不同的锁对象进行加锁,不会有锁竞争,没有阻塞等待,程序运行也会更快.
上述情况是jdk1.8及其以后的情况,1.7之前ConcurrentHashMap采用的是"分段锁"大概意思是让几个链表使用同一把锁.
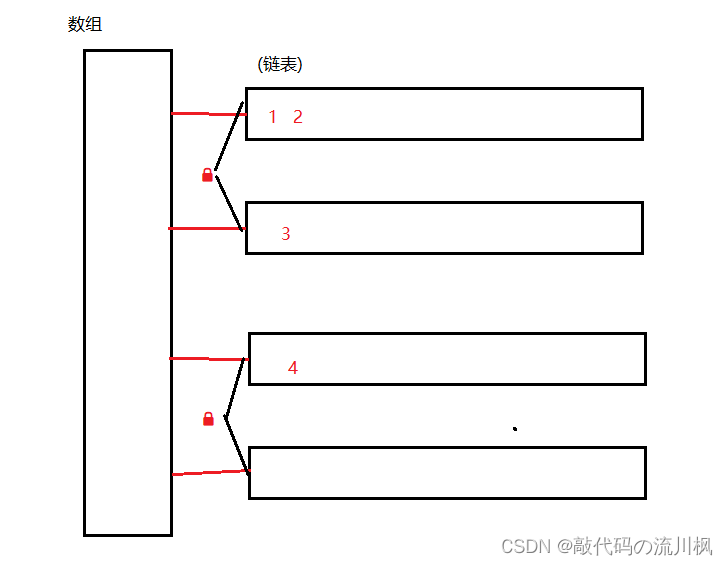
分段锁,本质上也是缩小锁的范围,从而降低锁冲突的概率,但是这种做法不够合理,粒度切分的不够细,代码实现也更繁琐.
2.优化二:只针对写操作加锁
ConcurrentHashMap做了一个激进的优化操作,针对读操作,不加锁,只针对写操作加锁!
读和读之间没有冲突,写和写之间有冲突,读和写之间也没有冲突...其实很多场景下,读写之间不加锁控制,可能会读到写了一半的数据,相当于脏读了.写操作不是原子的(ConcurrentHashMap使用了volatile+原子的写操作维护线程安全)
3.优化三:CAS
ConcurrentHashMap内部充分使用了CAS,通过这个进一步的削减加锁操作的数目,比如维护元素个数..
4.优化四:扩容方式
针对扩容采取了"化整为零"的方式
Hash Map/HashTable扩容:
是创建一个更大的数组空间,把旧的数组上的链表上的每个元素搬运到新的数组上(删除加插入)
这个扩容操作会在某次put(插入后超过负载因子了)后触发,如果元素个数特别多,那么就会导致搬运操作太多,比较耗时,就会出现某次put比平常put卡很多倍,时间是用来搬运了
ConcurrentHashMap中的扩容是采取每次搬运一小部分元素.创建新的数组,旧数组也保留,每次put操作,都往新的数组添加,同时进行一部分搬运,把一小部分旧的元素搬运到新的数组上.
每次get的时候旧数组和新数组都查询,每次remove的时候,只是把元素删了就行,经过一段时间,所有的数据都搬运好了,最终再释放旧数组