随着国内量化金融的高速发展,行情数据所包含的微观交易结构信息越来越受到券商自营团队、资管团队以及各类基金的重视。这些交易团队迫切希望拥有一个与生产环境类似的投研仿真环境,提升研发的效率和质量。
作为国内领先的高性能时序数据库厂商,DolphinDB 在服务众多券商、私募、公募、资管和交易所客户的过程中,持续总结和吸收行情中心项目建设的经验,并不断融入到 DolphinDB 数据库系统中,最终归纳形成了一套新型行情中心解决方案。
本文将为大家分享基于 DolphinDB 的行情中心解决方案——一个低延时、超高速的实时行情数据的指标计算以及基于历史行情数据的投研和仿真系统。
1. 概述

图 1:以行情为中心的券商交易(生产)系统和投研(仿真)系统
传统的券商行情系统主要指实时行情解码系统或行情转发系统,如上图右栏所示,其目标是将交易所实时行情(快照、逐笔委托和成交)以最低的延时传输给行情计算系统和交易执行系统。为了降低延时,实时行情的供应商甚至启用FPGA为解码提速。一些新兴的供应商还推出低延时的分布式消息总线服务,让实时行情快速地传递到更多的用户系统中。但这些技术手段没有离开行情原始数据服务的范畴,而且进一步提升的空间越来越小。
与实时行情解码系统或行情转发系统处于激烈的竞争不同,基于实时行情数据的指标计算以及基于历史行情数据的投研和仿真系统建设则刚刚开始——它是券商现有实时行情系统的延伸,包括:数据获取,指标计算,数据存储和数据分发,亦即图1左栏部分。下文中将统一称为“行情中心”。
1.1 行情中心的定位
行情中心建设通常是由IT部门或者数据部门主导,其他业务部门提出业务和技术需求为辅的系统建设项目,行情中心也常会和大数据平台、数据中台等项目紧密配合或互为补充。最终使用行情中心的用户可以通过两种维度划分:(1)面向个人用户或机构用户,(2)面向内部用户或外部用户。

表 1:行情中心用户分类
从用户服务角度,行情中心的核心服务如下图所示,自上而下可以概括为:(1)数据获取,(2)指标计算,(3)数据存储,和(4)数据分发。

图2:行情中心核心服务
(1)数据获取主要是对接多个数据源厂商,以及对接多种格式的数据类型用于后续计算和处理。在这一层中需要对原始数据进行解析、校验、清洗和处理。行情中心必须有足够的扩展性和灵活性,能快速对接不同类型不同来源的数据。
(2)指标计算是对清洗后的数据进行计算,并将结果反馈给下游用户。数据的计算主要涵盖批量计算、实时计算和汇总计算。不同频率不同类型的数据,计算的复杂程度和处理的方式不一样,需要行情中心有不同的计算引擎来分别应对。投研(仿真)环境和交易(生产)环境需要完全一致的计算结果,支持批流一体的计算引擎可以缩减开发成本,加快交易策略和模型上线。
(3)数据存储是将原始数据和加工计算后的各类指标数据存储到数据库,并提供高效的数据检索能力。行情中心数据量大,例如沪深交易所每天产生的行情、订单和成交数据在3~5G,全量历史数据大概在百T级;对源数据加工处理后,也会生产海量的数据。快照、订单、成交、指标等数据都有准确的时间戳,是典型的时序数据。由于数据量大,行情中心对时延也有较高要求,文件IO极易成为性能瓶颈,分布式时序数据库是理想的存储选择。同时,行情中心对可靠性要求高,需要完善的高可用方案。
(4)数据分发指行情中心推送实时和历史数据到下游系统。实时数据的推送对数据分发的时延和稳定性有较高要求,消息中间件、内存数据库、跨进程的共享内存是常用的技术方案。历史数据的推送可以通过数据库的在线查询,也可以通过离线的数据下载来完成。数据回放是行情中心里最特殊的重要功能,在实际应用中需要多表关联回放,例如委托和成交关联,同时要求严格按照时间序列回放。
1.2 行情中心发展趋势
在业务层面上,行情中心从简单地为下游系统提供行情原始数据的查询和下载服务,向交易和投研系统提供更多数据衍生服务演进:
Level 2和逐笔行情数据的重要性日益凸显。这些数据中包含的市场微观结构信息可能为投资带来更为稳定的回报。
行情中心需要提供更多品类的数据,能够为周边的资管、交易、风险、估值和研究等多个应用方向和业务条线服务。
除了作为原始行情数据的存储和查询工具,更需要在业务层面上提供更多样的计算指标,提升增值服务能力。这些指标或作为策略和交易系统的基准输入,或作为机器学习系统的特征工程输入。随着机器学习在量化交易中的应用越来越深入,计算指标越来越成为行情中心的一个基础需求。
行情系统除了满足常规的交易需求,越来越展现出在投研(仿真)系统中的价值。产研一体化可以大大提升基金尤其是私募基金的投研效率和质量。
在技术层面上,行情中心也从一个简单的数据存储和查询系统,正在往一个存查算一体化的系统演化:
数据量极为庞大。除了原始的行情数据,还要保存计算得到的指标结果,需要具备海量数据的存储能力。
对行情数据的实时流式处理能力较为迫切。
行情中心处于整个业务链条的上游,对计算性能有较高要求。
产研一体化的业务要求需要批流一体的计算技术来保障。
1.3 行情中心业务框架
行情中心业务5层逻辑架构是一种较为清晰和简单的拆分方式,如下图所示具体包括接入层、计算层、存储层、应用层和分发层。

图3:行情中心业务框架
这里重点介绍行情中心计算层的业务需求。计算层是对原始行情数据以及其它辅助数据的再加工。大量实践表明,行情中心非常适合计算市场中一些具有共性诉求的中间指标或直接可参与交易决策的部分指标,主要有四个原因:(1)行情中心离源数据更近综合时延更低;
(2)行情中心的数据种类更丰富可计算的维度更广;
(3)行情中心开发一次指标,计算一次指标后即可被下游多个系统多个用户重复使用,整体上更经济;
(4)带有计算功能的行情中心,可以部署在基金、资管等机构本地,作为投研(仿真)系统的重要组成部分。
数据转发主要实现L1/L2行情的直接转发,通常适用于普通行情服务;价源优选是行情中心较为特色的功能,通过多路行情选出最快的行情为下游客户提供低延时行情服务;行情中心也需要提供其他源数据的直接转发服务。
基于交易价格和交易量等行情信息构建技术类指标,是行情中心的重要计算业务之一。TA-LIB、MyTT、WorldQuant 101 Alpha Factor是典型的技术类指标。技术指标是基于机器学习、深度学习的量化交易模型的主要特征输入。在其它量化交易模型中,技术指标也可以和其它类型的因子一起作为模型的输入,优化模型。
分时K线、VWAP、相关性计算、资金流分析、ETF和指数的IOPV计算、波动率预测、Value at Risk(VaR)、衍生品定价、订单簿合成等量化金融中常用的计算是很多策略模型必须要用到中间指标。这些中间指标模型的开发和计算有较高的复杂度和难度,行情中心提供标准化的实现可以赋能基金、资管等机构。
2. 行情中心的技术需求
为实现2.2中行情中心的业务框架,需要相应的技术储备,主要包括存储层和计算层功能所必须满足的技术要求。
2.1 存储层
行情数据的存取是一个行情中心最基本的需求。行情中心的大部分数据是典型的时间序列数据,时序数据库是最典型的存储解决方案。但是与物联网、APM等时序应用场景相比,行情中心具有明显的金融的细分领域特点。
交易数据的不唯一性
在时序数据库的一个表中,多个 tag 的组合构成唯一的时间序列。一个序列在不同时间戳上通常具有唯一值,例如一个物联网传感器,在某一个时间点上具有唯一采样值。但是金融市场的交易规则决定了同一个股票在同一时间戳上可以形成多笔交易(不同的对手盘导致)。很显然,对手盘的订单号、成交价格不适合作为新的tag,来确保唯一性。通常以物联网为主要应用场景的时序数据库都有这个限制,例如InfluxDB和TDengine都要求一个时间序列在一个时间戳上具有唯一值。
多档报价数据的存储
行情中心的 level 2 快照数据在一个时间截面上存在多档的报价数据(买一,买二,卖一,卖二等)。当档数固定且不多的情况下,可以进行扁平化处理,即用多个字段表示不同的档位。但是档位比较多,或者档数可变的情况下,用一个数组来表示多档数据是一种更通用更高效的解决方案。因此数据库支持数组类型,对于解决行情中心的存储问题非常有帮助。
宽表存储
物联网应用通常只关心单个时间序列的数据。金融应用在关心单个标的的时间序列的同时,更关注一个时间截面上多个标的的关系,亦即面板数据分析。为了支持面板数据分析,通常需要数据库能支持数据透视(Pivoting)或直接支持宽表存储(每列代表一个标的,每行代表一个时间戳)。
委托和成交的关联
逐笔的委托和成交数据是行情中心数据库中最基础的两个大表。因为数据量很大,只能采用分布式表来存储。这样委托和成交表关联时的效率很低。分布式数据库中,分片的co-location存储是提升分布式表关联性能的最有效手段。
时序建模 + 关系建模
行情中心数据库中的大部分基础数据都可以用时序建模。但是部分基础数据和计算结果仍然需要关系模型的支持。例如,股票的参考数据(reference data)不能用时序建模。又譬如因子计算结果表,虽然也是时间序列,但是包含了证券和因子两个实体,实质上是证券和因子随着时间变化的一个关系,方便按照因子和证券两个维度来进行快速的查询。
高可用
一个行情中心需要7 x 24为内部或外部用户提供行情数据及计算服务。分布式存储引擎必须满足高可用的要求。
2.2 计算层
一个行情中心,除了满足最基本的原始数据查询和下载的需求外,还需要支持常用的计算业务,这样可以大幅提升数据的使用率,简化行情中心客户端应用的开发。
多表数据回放
行情中心的一个重大需求是在研发环境仿真交易所的数据流,在此基础上实现策略和交易仿真。对逐笔委托和成交数据以及快照数据的回放,是实现仿真的关键技术之一。回放除了性能上越快越好之外,功能上一般有三个需求: (1)多个表的数据能严格按照时间顺序回放,(2)能选择不同的时间字段(例如事件发生的时间戳或接收数据的时间戳)进行回放,(3)能按指定的速率进行回放。
窗口函数和面板数据处理
技术指标分析、相关性计算、VWAP计算以及分时K线的处理都离不开最基本的窗口函数。窗口函数除了能用增量算法实现提升性能外,功能上的要求通常包括:(1)能实现滑动、滚动、累计以及任意定制的窗口类型,(2)能按行数和时间两种度量来推进窗口,(3)多个窗口函数能嵌套执行完成复杂的指标计算。窗口函数通常在一个时间序列上执行,但在行情数据处理时,时间截面分析也非常常用,这就形成了所谓的面板数据处理。
数据透视
金融数据分析通常会把原始数据转化成矩阵(面板数据)的形式,譬如每一列是一个证券,每一行是一个时间点。转换成矩阵后,计算更简单、更高效。截面指标计算、相关性计算、ETF的IOPV计算等都可以通过矩阵计算来完成。行情中心的原始数据存储通常不是矩阵形式,需要通过数据透视(pivoting)来转换。
非同步关联
行情中心存储的委托、交易和快照等数据在计算时经常需要按股票和时间进行关联。当按时间关联时,通常两个表中的时间不是相等的,而是满足某种关系,譬如最近的一条记录,某个时间窗口内的记录等。这种关联,我们称之为非同步关联,asof join和window join是最常用的非同步关联。噪音平滑、交易成本分析等计算都会用到上述非同步关联的方法。
流式计算和批流一体
行情中心既要处理研发环境中的历史数据,又要处理生产环境中的实时数据。研发环境中的历史数据是全量数据,可以用批处理的计算方法。生产环境中实时数据是逐条进来的,只能采用更为高效的流式增量计算。两个环境的计算实现方法如果完全独立,则意味着要开发两次,大幅增加了一个机构的时间成本和资源成本。批流一体的技术需求应运而生。
多范式脚本编程
要满足行情中心的计算需求,光有SQL是不够的。最好能有一门在SQL基础上扩展的脚本语言来支撑复杂的计算需求。对于行情中心的计算需求,函数式编程和向量式编程可以提升开发的效率和运行的效率。对于一部分性能要求特别高的计算需求,如衍生品定价,脚本语言如能支持即时编译(JIT),会是一个很大的优势。
分布式计算
行情中心通常服务于多个并发用户,部分计算任务又会涉及大量数据,需要具备分布式计算的能力。分布式计算需要解决三个问题:(1)当计算资源不足时,可以通过增加计算节点来扩展资源,(2)当部分计算节点宕机时,可以将计算任务转移到其他节点,(3)可以通过多个节点和多个CPU核的并行处理,降低一个复杂任务的计算时延。
3. DolphinDB 的行情中心解决方案
DolphinDB 是一款高性能分布式时序数据库,集成了功能强大的编程语言和高容量高速度的流数据分析引擎,为海量数据(特别是时间序列数据)的快速存储、检索、分析及计算提供一站式解决方案。DolphinDB操作简单,可扩展性强,具有良好的容错能力及优异的并发访问能力。DolphinDB 可以在Linux或Windows系统、单个节点或集群、本地或云服务器中部署。

图 4:DolphinDB 三位一体融合设计
DolphinDB采用三位一体的融合设计架构,强调数据库、编程语言和分布式计算三者的融合。这突出了数字时代用户对数据挖掘的需求。DolphinDB数据库不再只是一个存储中心,更是一个计算和服务中心。用户希望通过深挖数据的价值,让数据(库)从一个成本中心转化为一个利润中心。DolphinDB的用户除了DBA和IT人员, 更包括公司的业务和研发人员,他们可以使用DolphinDB内置的脚本语言以及丰富的函数库,快速展开业务上的二次开发。

图 5:DolphinDB 主要计算和存储能力
DolphinDB 对金融行业做了大量的针对性功能和优化,在行情中心业务场景中,通过其强大的存储和计算核心能力赋能行情中心技术建设:
3.1 存储能力
1、同一时间戳存储(交易数据的不唯一性)

表 2:交易数据不唯一
表2为深交所开盘集合竞价Level 2订单簿行情,存在多笔订单的SecurityID和TransactTime完全一致的情形。其他数据库存储技术会把这两个字段作为主键提高查询速度,但由于主键必须唯一,导致这些数据库无法原生存储不唯一数据,只能在应用层或数据库层做特殊处理,这会导致数据错误或性能下降等诸多问题。

图 6:DolphinDB 原生支持不唯一数据存储
DolphinDB区别于其他类型数据库,在底层架构上原生支持不唯一数据存储,同时TSDB存储引擎还能保证计算低延时。
2、数组存储(多档报价数据的存储)

表 3:10档行情数据示例
表3为10档行情原始数据,每一档包含买价、卖价、买量和卖量4列数据,因此需要40列。

表 4:Array Vector 10 档行情存储
DolphinDB支持数组(array)类型的列,在array vector中可以同时存10档数据。如表4所示,只需要OfrPXs、BidPXs、OfrSizes和BidSizes 4列即可存储10档行情。数据压缩比可从4倍提高至10倍,间接提高了查询速度。另外,array vector支持不定长存储,可以用于原始行情和因子存储。
在量化程序开发过程中,array vector通过index进行数据遍历,而传统存储方式需要硬编码处理每个字段,大大增加了代码复杂度并容易出错。
3、宽表存储
横截面计算在时序数据处理中极为常见,交易中经常需要存储多个标的甚至全部标的在同一横截面上的因子,并且需要对横截面进行面板数据分析。宽表存储天然适合面板数据,并能减少数据冗余,提高查询速度。

表 5:DolphinDB 宽表存储
如表5所示,在一张宽表中存储4500只股票的1098个因子。DolphinDB支持32767列大宽表。一部分时序数据库不支持大宽表或者存在明显的性能问题。例如ClickHouse会把每列数据都存为一个文件,在大宽表中多列数据文件读写就会遇到显著的性能下降。DolphinDB自研的TSDB存储引擎能够保证大宽表下的高性能读写。
4、co-location存储(委托和成交的关联)

图 7:co-location 与非co-location 存储方案对比
在量化交易中,需要关联逐笔委托和逐笔成交用于微观结构分析、因子生成和交易策略。DolphinDB的co-location存储架构会强行将同一交易日的订单表和成交表存储在同一数据节点中,在关联计算时只需要读取同一节点数据,如图7左侧所示。这样的存储架构可以避免节点间的数据传输,大幅提高计算速度。
图7右侧是非co-location存储方案,2022.06.15日的trade数据在DataNode1节点上,order数据在DataNode2上,只能通过网络传输把两表数据汇集后再进行关联计算,这样会大大增加网络开销,降低计算速度。非co-location数据库存储在历史数据回测时,网络传输量将呈指数级上升,甚至发生网络阻塞,导致整个集群不可用。通常一个交易日的逐笔委托和逐笔成交量大约在5GB左右,2张表这样就需要10GB的网络传输,当处理跨年数据时,极易打满整个集群的网络。
5、多模数据库(时序建模+关系建模)
除需支持时序模型外,金融业务还需要支持关系模型。时序模型主要存储如行情、订单、委托和指标因子等具有时序特征的大数据;在实际业务中,如计算期权面值需要用到合约乘数,又比如对组合需要根据行业分类进行估值、因子、归因和风险计算,这些场景都是典型的关系模型。
DolphinDB 是一个多模数据库,同时支持时序数据模型和关系数据模型。支持as of join, window join, cross join, equal join, full join, inner join, left join和prefix join等多种数据关联方式。时序模型支持非同步关联,关系模型支持等值关联。
6、高可用

图 8:DolphinDB 高可用架构
DolphinDB是一个分布式数据库,自上而下具有完善的高可用方案。
应用层高可用
应用程序可以直连到任意计算节点,保证应用层高可用;也可以采用HTTP经过负载均衡节点,再把请求发送到计算节点。
计算节点高可用
DolphinDB支持计算和存储节点分离,支持多计算节点部署,只要有一个计算节点可用,整个集群仍然可用。
元数据高可用
存储数据时会产生大量元数据,元数据是数据的基本信息,计算节点会首先读取元数据,然后再从数据节点中读取源数据。在元数据管理上,DolphinDB采用了Raft协议保证高可用。
数据节点高可用
DolphinDB采用了自研的分布式文件管理系统(DFS),支持数据多副本存储,两阶段提交协议保证数据的强一致性。
多级存储
DolphinDB支持多级存储,可以将最常用的热数据存储到SSD固态硬盘中提高数据的读写速度,较冷的数据存储到HDD机械硬盘中,不太使用的历史数据存储到S3中。
多集群数据同步
不同机房间可以通过异步复制或定时任务实现数据的同步。
3.2 计算能力
除了数据存储,行情中心的计算同样极为重要。大多数时序数据库更侧重于数据存储和较为简单的计算,DolphinDB 在设计理念上将计算置于了和存储同等重要的位置。以下计算能力可以很好地应用在行情中心建设上。
1、多表数据回放
DolphinDB 支持历史数据回放。交易所提供的Level 2行情有3大类数据,分别是快照类数据、逐笔成交类数据和逐笔委托类数据。在回测中,我们常需要将这三种不同类型的数据关联回放,使回测过程尽量模拟生产。
1.orderDS = replayDS(sqlObj=<select * from loadTable("dfs://order", "order") where Date = 2020.12.31>, dateColumn=`Date, timeColumn=`Time)
2.tradeDS = replayDS(sqlObj=<select * from loadTable("dfs://trade", "trade") where Date = 2020.12.31>, dateColumn=`Date, timeColumn=`Time)
3.snapshotDS = replayDS(sqlObj=<select * from loadTable("dfs://snapshot", "snapshot") where Date =2020.12.31>, dateColumn=`Date, timeColumn=`Time)
4.inputDict = dict(["order", "trade", "snapshot"], [orderDS, tradeDS, snapshotDS])
replay(inputTables=inputDict, outputTables=messageStream, dateColumn=`Date, timeColumn=`Time, replayRate=10000, absoluteRate=true)上述示例代码:首先,能同时回放order,trade和snapshot这三张表;其次,交易逻辑是投资者先下交易订单(order),交易所撮合匹配成交(trade),最后每3秒向全市场发布快照行情(snapshot),DolphinDB的异构回放会把这三张表“组合成一张关联的大表”,并严格按照时间序列模拟生产回放;最后,可以指定回放速度,如10000笔每秒。
2、窗口函数

表 6:DolphinDB 窗口函数
DolphinDB 支持数十种复杂的滑动、滚动和累计窗口计算函数。支持均值、最大、最小、中间值等较为简单的窗口计算;也支持最小二乘数估计、person 相关性、协方差、标准差、移动加权平均等较为复杂的函数。满足技术指标中的各类复杂计算。
DolphinDB 包含1400多个内置函数,适用于多种数据类型(数值、时间、字符串)、数据结构(向量、矩阵、集合、字典、表),函数类别包括:数学函数、统计函数、逻辑函数、字符串函数、时间函数、数据操作函数、窗口函数、连接函数、高阶函数、元编程/分布式计算函数、文件/路径函数、数据库函数、流计算函数、系统管理函数、批处理作业函数、定时任务函数、性能监控函数和用户权限管理函数。
3、数据透视和面板数据
DolphinDB 特有的 pivot by 数据透视功能,能够把原始数据转化成矩阵(数据面板)。以 IOPV(基金净值)计算为例。
1.timeSeriesValue = select tradetime, SecurityID, price * portfolio[SecurityID]/1000 as constituentValue from loadTable("dfs://LEVEL2_SZ","Trade") where SecurityID in portfolio.keys(), tradedate = 2020.12.01, price > 0
2.// 利用Pivot by数据透视汇总(rowSum)所有成分券在某一时刻的价值,即IOPV;如果当前时刻没有成交价格,利用ffill函数使用前一笔成交价格。
3.iopvHist = select rowSum(ffill(constituentValue)) as IOPV from timeSeriesValue pivot by tradetime, SecurityID图9展示了上述代码中 timeSeriesValue 表的数据格式,该表共有3个字段,分别是 tradetime、SecurityID 和 constituentValue,其中 constituentValue 是当前时刻股票的价值(price*qty)。

图 9:股票在时间序列上的价值
计算一只 ETF 的 IOPV,则需要把篮子中所有股票当前时刻的价值进行汇总,在这种场景下,可以使用 pivot by 生成矩阵(面板数据)。执行代码3可以看到 pivot by 后的面板数据。
tmp = selectconstituentValue from timeSeriesValue pivot by tradetime, SecurityID代码 3:pivot by生成矩阵(面板数据)
tmp 表数据如图10,行对应当前时刻,列对应各只股票。在 tmp 表的基础上只要执行 rowSum 就能汇总得到该只基金的 IOPV。

图 10:pivot by生成的股票价值矩阵(面板数据)
4、非同步关联
asof join
asof join 能够关联距离当前时刻最近的数据,如图11箭头所示,trade 总是关联距离他最近时刻的 order 数据。
asojTable = select * from aj(trades, orders,`Symbol`Time)代码 4:asof join 非同步关联

图 11:asof join 非同步关联逻辑
asof join 关联后的结果如下:

表 7:asof join 关联结果
window join
Window join 可以对某一段时间范围的数据进行聚合,例如计算100毫秒内的均价。
winjTable = select * from pwj(trades, orders, - 100000000:0, <[avg(Bid_Price) as Avg_Bid_Price, avg(Offer_Price) as Avg_Offer_Price]> ,`Symbol`Time) 代码 5:window join 非同步关联
Window join 关联后的结果如下:
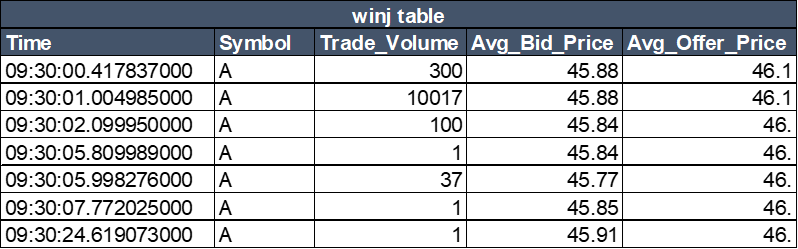
表 8:window join 关联结果
5、流式计算和流批一体
八种流计算引擎
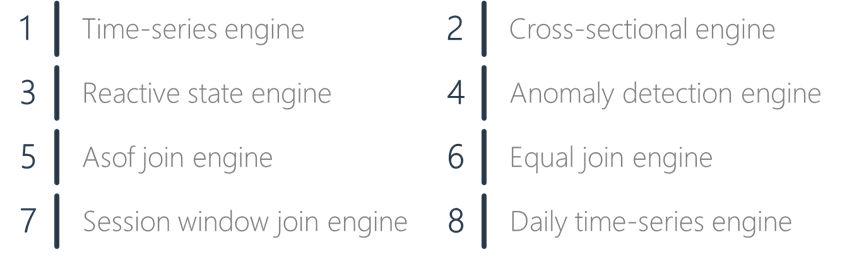
图 12:DolphinDB 流计算引擎
DolphinDB 支持多种流计算引擎,包括时间序列引擎、横截面引擎、响应式状态引擎、会话窗口引擎、异常检查引擎和多种关联引擎。多样的流计算引擎能够满足实盘交易中的各种计算场景。
增量计算
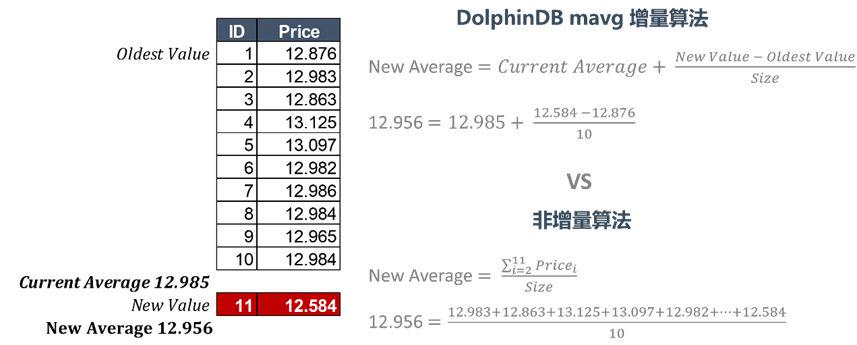
图 13:DolphinDB 增量算法
在流数据计算中,有大量的计算需要随着时间窗口移动,例如上图13所示的 moving average,会计算最新10笔数据的均价。DolphinDB 的增量算法计算步骤更少,计算时延更低。
流批一体

图 14:DolphinDB 实现了流批一体架构
流批一体是指历史批量数据建模分析使用的代码和实时流式计算使用的代码一致,并保证流式计算和批量计算的结果完全一致,被称之为“流批一体”。批流一体的优势在于只需要写一套投研阶段使用的代码就能在实时生产中复用,可以大幅减少开发工作量,并确保两个环境计算结果的一致性。
流批一体能够极大降低产研一体化技术架构的复杂度。
6、多编程范式
SQL和脚本语言融合
在DolphinDB中,脚本语言与SQL语言是无缝融合在一起的。这种融合主要体现在几个方面:(1)SQL语句是DolphinDB语言的一个子集,一种表达式。SQL语句可以直接赋给一个变量或作为一个函数的参数;(2)SQL语句中可以使用上下文创建的变量和函数。如果SQL语句涉及到分布式表,这些变量和函数会自动序列化到相应的节点;(3)SQL语句不再是一个简单的字符串,而是可以动态生成的代码;(4)SQL语句不仅可以对数据表(table)进行操作,也可对其它数据结构如scalar, vector, matrix, set, dictionary进行操作。
向量化编程
向量化编程是DolphinDB中最基本的编程范式。DolphinDB 中绝大部分函数支持向量作为函数的入参。函数返回值一般为两种,一种是标量(scalar),这类函数称为聚合函数(aggregated function)。另一种返回与输入向量等长的向量,称之为向量函数。向量化操作有三个主要优点:(1)代码简洁;(2)降低脚本语言的解释成本;(3)可对算法优化,提升性能。
函数化编程
DolphinDB支持函数式编程,包括纯函数(pure function)、自定义函数(user-defined function)、匿名函数(lambda function)、高阶函数(higher order function)、部分应用(partial application)和闭包(closure)。
即时编译(JIT)
即时编译,又称及时编译或实时编译,是动态编译的一种形式,可提高程序运行效率。解释执行是由解释器对程序逐句解释并执行,灵活性较强,但是执行效率较低,以Python为代表。即时编译融合了两者的优点,在运行时将代码翻译为机器码,可以达到与静态编译语言相近的执行效率。DolphinDB中的即时编译功能显著提高了for循环,while循环和if-else等语句的运行速度,特别适合于无法使用向量化运算但又对运行速度有极高要求的场景。使用即时编译在某些场景下性能会有几百倍的提升。

4. DolphinDB 行情相关客户案例
DolphinDB 已成为了国内外众多券商、私募、资管、对冲基金和金融信息服务商的长期合作伙伴。客户的使用场景包括但不限于:
实时行情接入
历史行情的导入
实时和历史行情落库
实时行情流式指标和因子计算
历史行情批量指标和因子计算
为内部和外部用户提供行情的查询和计算服务
利用行情数据开发交易策略
利用行情回放功能进行策略回测
将 DolphinDB 作为行情的存储和计算平台,为下游交易系统提供指标和因子信号
使用流批一体实现产研一体化
4.1 券商和信息服务商行情中心项目
(1)某券商行情资讯中心,之前和某系统供应商合作,供应商推荐 ClickHouse,但是为了能够更方便地做数据二次加工,同时符合信创要求使用国产芯片的服务器,更换为 DolphinDB 来存储 level2 的高频数据。
(2)某台湾券商原先使用 Python+HDF5 做K线的计算,随着台湾交易所行情频率的提高,数据量激增,原有系统无法满足需求,遂使用 DolphinDB 生成不同频率的K线输出至 python 供C端查询。
(3)国内最大的 FICC 领域信息提供商,用 DolphinDB 搭建行情数据平台,为外部应用提供数据查询和计算服务。
4.2 某头部券商
证券投资部门做实时行情的处理,定制开发了行情插件,把股票快照、指数快照、股票逐笔实时行情接入 DolphinDB。通过流表的订阅,数据实时落库与实时因子计算同时进行,对开盘高峰期数据计算多个指标,亚毫秒级完成了全部计算,性能提高100多倍。计算结果写入 RabbitMQ,供下级的业务消费。之前使用Java,开发周期长、计算速度慢,预计3个月开发工作量;使用 DolphinDB 后,采用 DolphinDB 流式计算框架,1周完成开发工作,计算速度提高百倍。
4.3 某知名私募
主要使用场景是海量数据下因子挖掘和策略研发,需要使用历史行情和实时行情,数据接入用 DolphinDB 进行数据的计算和存储。原先采用 Python 用于投研环境策略研发、C++用于生产环境代码开发,因此导致投研环境和生产环境割裂,需要极大的开发工作量,投研生产代码逻辑不一致需要进行大量测试。客户使用 DolphinDB 后,采用流批一体实现了投研环境和生产环境代码一致性;同时因子的计算速度要比原来提高上百倍,因子开发工作量也大幅度降低。最终实现产研一体化。



![[oeasy]python0052_ raw格式字符串_单引号_双引号_反引号_ 退格键](https://img-blog.csdnimg.cn/img_convert/cce5958864a3a2f40b72f3350a0613ee.png)