TCP的可靠传输实现
以下区别:
1、可靠传输(有序,保证对方一定接受到)
2、流量控制
这两个功能都是依靠滑动窗口来实现的
TCP实现可靠传输依靠的有 序列号、自动重传、滑动窗口、确认应答等机制。
序列号
首先我们说下序列号,TCP中将要发送的数据包的每个字节都分配了序列号,用来唯一标识一个字节。序列号随着数据包的发送而增加。
只有为每个字节分配一个序列号,每个数据包都对应着一个序列号区间,才能确定哪个数据包发送出现意外了。
序列号的初始化是由操作系统分配的,是一个32位的数字。
TCP初始化序列号不能设置为一个固定值,因为这样容易被攻击者猜出后续序列号,从而遭到攻击。
RFC1948中提出了一个较好的初始化序列号ISN随机生成算法。
ISN = M + F(localhost, localport, remotehost, remoteport).
M是一个计时器,这个计时器每隔4us加1。
F是一个随机算法,根据源IP、目的IP、源端口、目的端口生成一个随机数值。
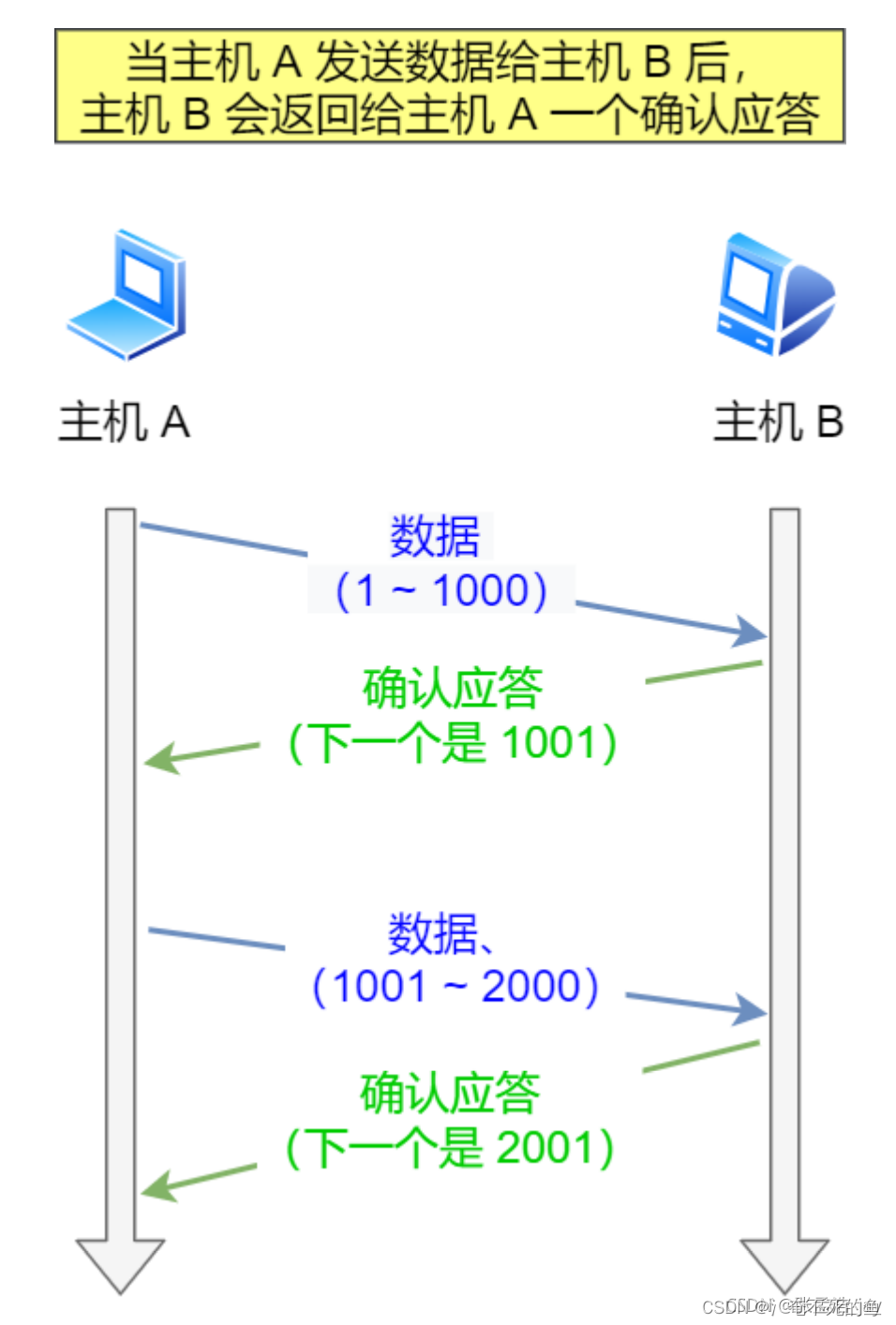
确认应答
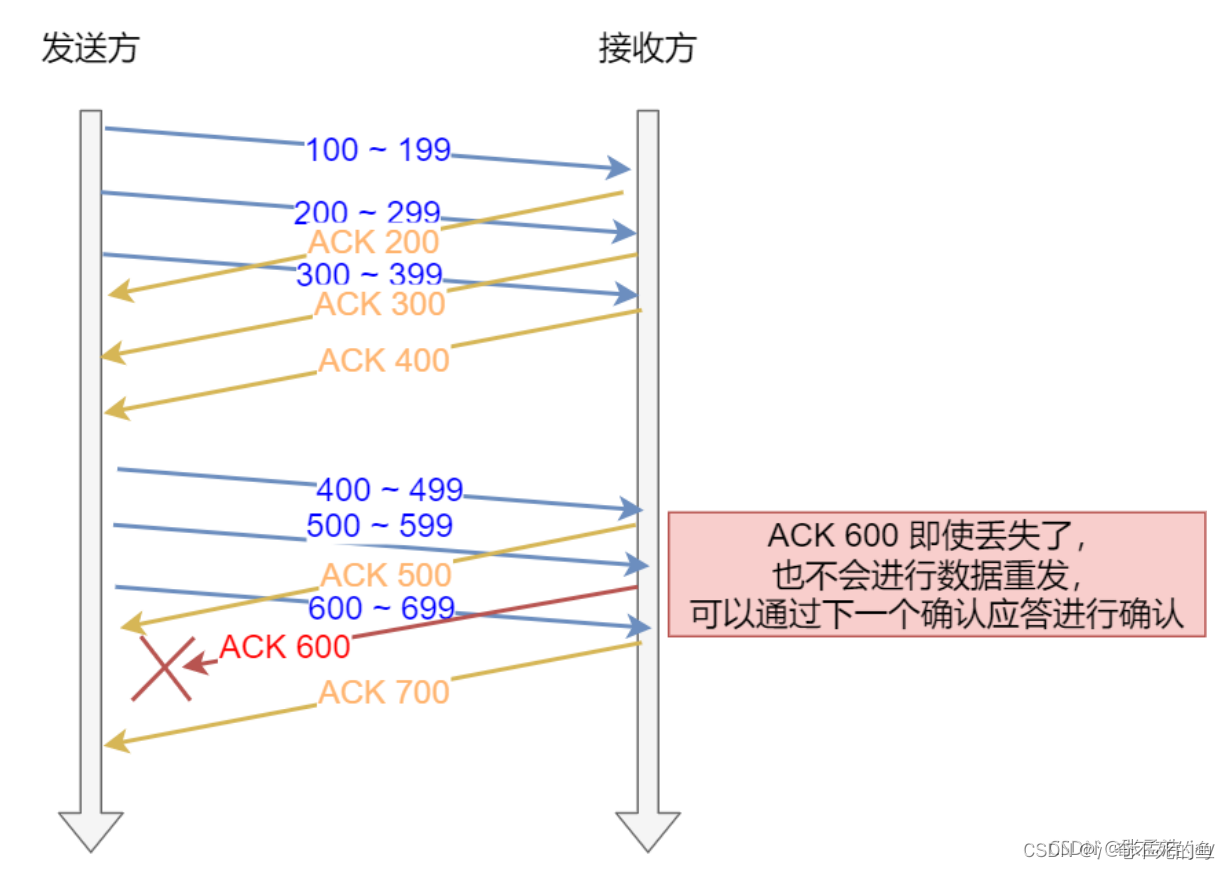
当接收方收到一个数据包后,会直接返回一个ACK包,或者延迟一段时间返回一个ACK包,一次性确认多个数据包。
ACK包中有一个ack字段,代表着seq小于ack的数据包都已经被接收完毕。
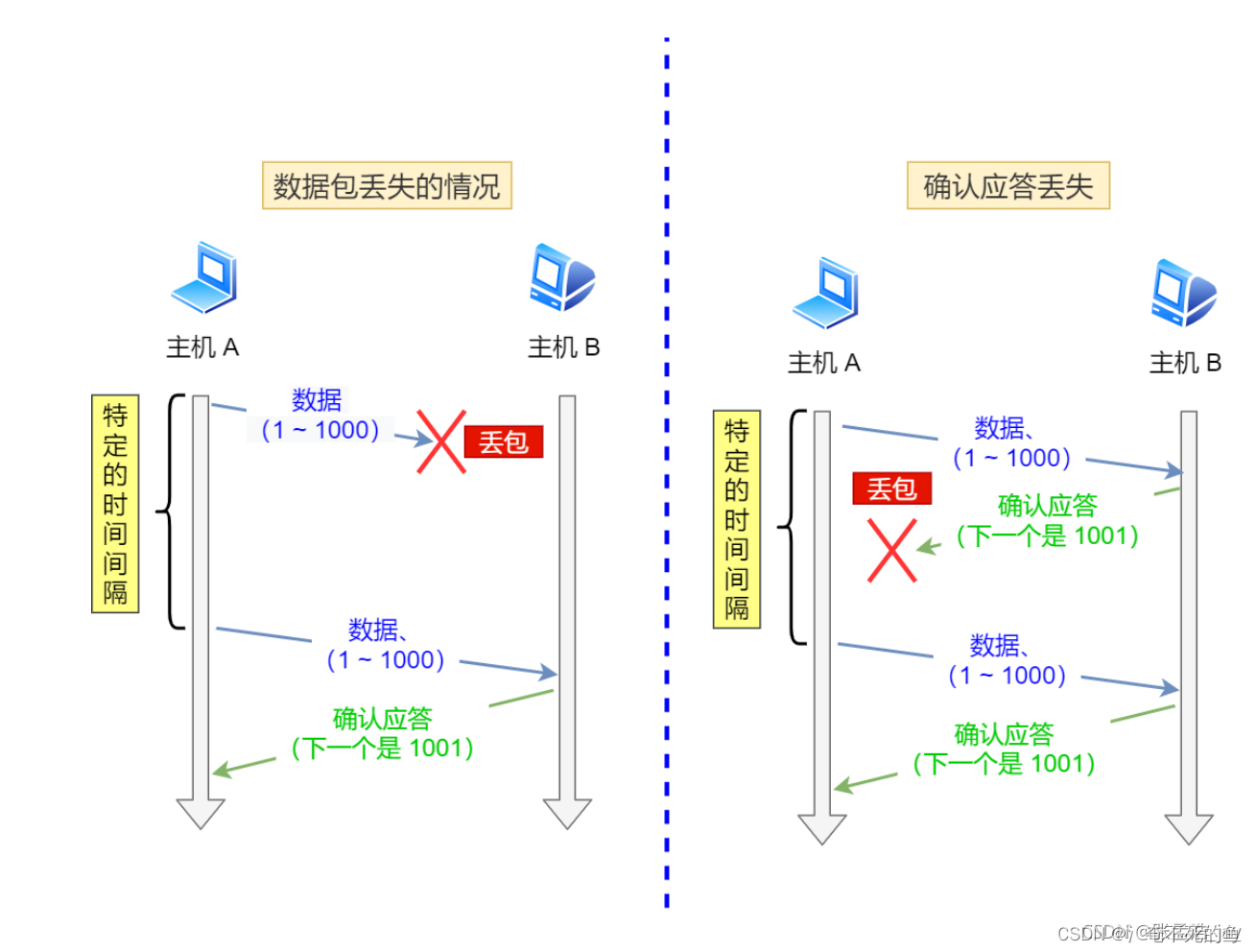
自动重传 ARQ
当TCP发送端发送了一个TCP数据包的时候,会设置一个定时器,如果在定时器期间没有收到接收方对这个数据包的确认应答包,也成为ACK包,就会重新发送对应的TCP数据包。
自动重传有以下两个原因:
1、数据包丢失
2、ack数据包丢失
超时时间的选择
超时时间既不能太长,又不能太短。
超时时间过长存在的问题:
当发生丢包的时候,需要等待好长时间才会重新发送,这个时候TCP就处于等待时期,什么也干不了,浪费资源,发送效率低下。
超时时间过短存在的问题:
如果超时时间太短,会发生多次发送重复包的情况。当ACK包还在路上的时候,由于超时时间太短而导致发送端重复的发送不必要的数据包。会加重网络的负担,导致网络阻塞等问题。网络发生阻塞的话,会进一步正反馈导致更多的重传。
重传超时时间简称为RTO
RTO是略大于RTT的。
RTT指的是一个数据包从发送到接收到ACK确认包的花费时间,RTT是会随着网络的变化而变化,是会波动的。
TCP缓冲区
什么是tcp缓冲区?每个 socket 被创建后,都会分配两个缓冲区,输入缓冲区和输出缓冲区。
二、缓冲区的意义
write()/send() 并不立即向网络中传输数据,而是先将数据写入缓冲区中,再由TCP协议将数据从缓冲区发送到目标机器。一旦将数据写入到缓冲区,函数就可以成功返回,不管它们有没有到达目标机器,也不管它们何时被发送到网络,这些都是TCP协议负责的事情。
TCP协议独立于 write()/send() 函数,数据有可能刚被写入缓冲区就发送到网络,也可能在缓冲区中不断积压,多次写入的数据被一次性发送到网络,比如nagle算法,这取决于当时的网络情况、当前线程是否空闲等诸多因素,不由程序员控制。
read()/recv() 函数也是如此,也从输入缓冲区中读取数据,而不是直接从网络中读取。
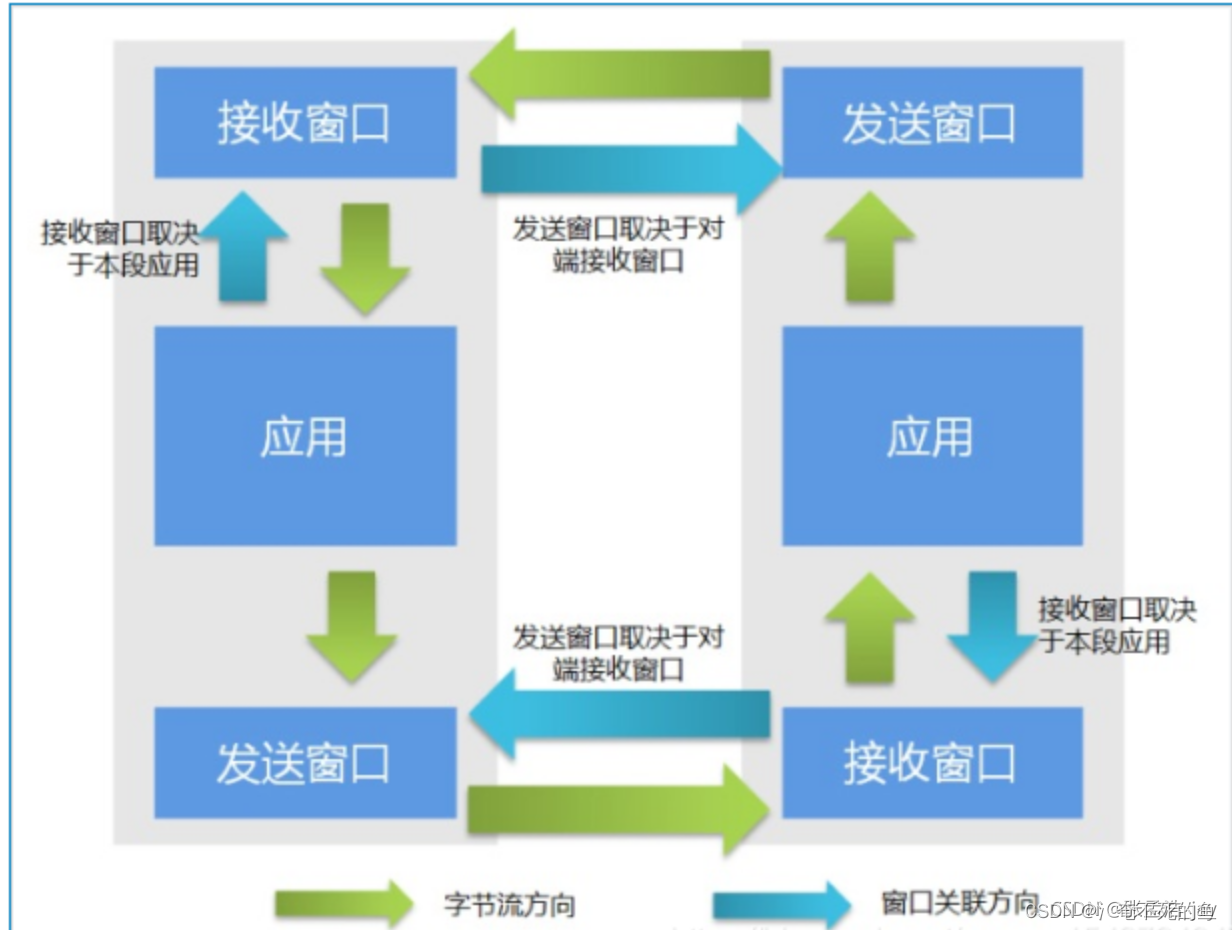
滑动窗口的出现原因
滑动窗口 分为 发送窗口 和 接收窗口。
发送窗口 用来 发送数据。
接收窗口 用来 接收数据。
客户端和服务器端 都有一个 发送窗口 和 接收窗口。
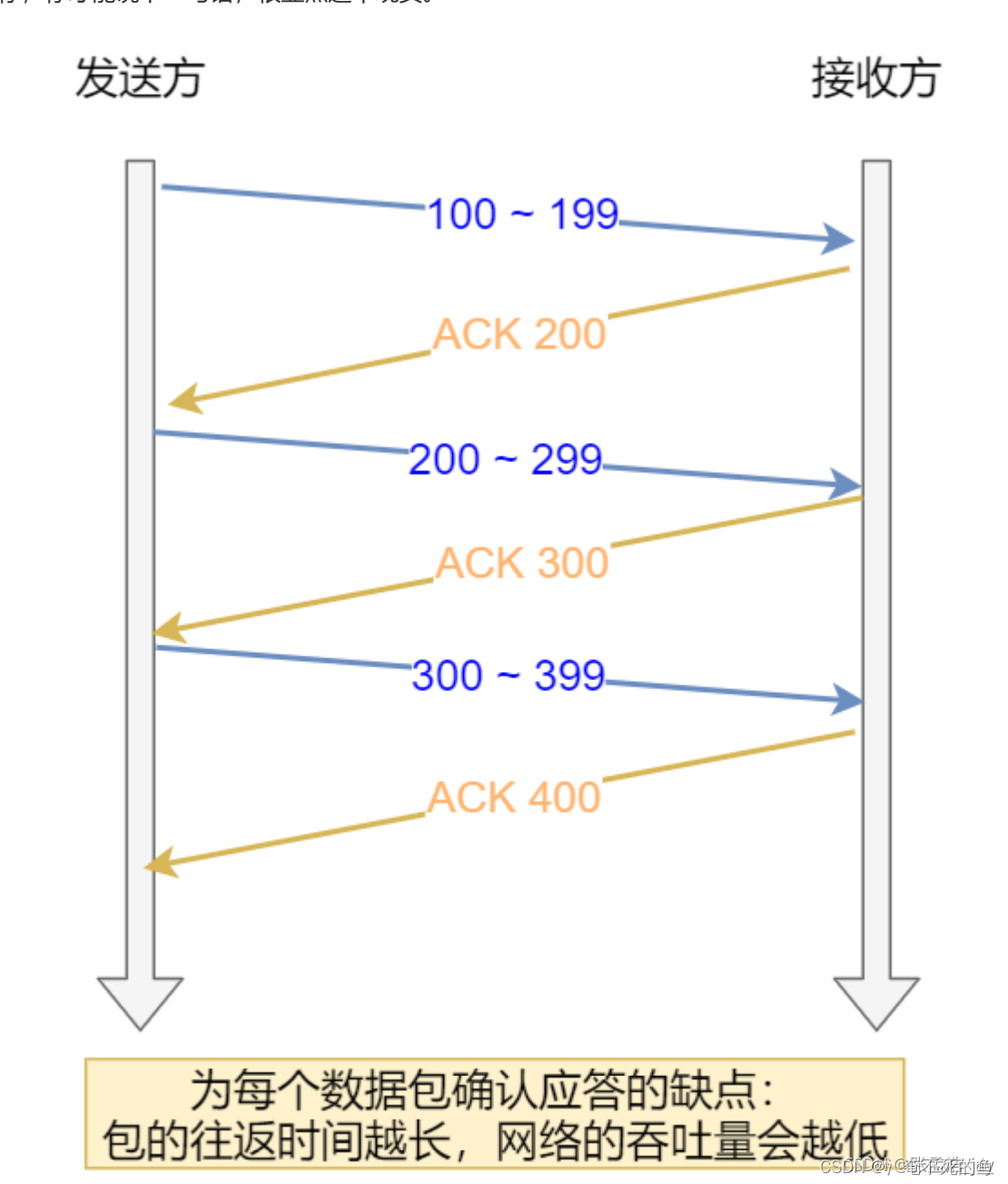
为什么会引入滑动窗口呢?
如果不存在发送窗口的话,TCP发送一个数据包后会等待ACK包,因为必须要保存对应的数据包,数据包很有可能需要重新发送。
这样的话发送效率会很慢。大部分时间都在等待。
引入了发送窗口,发送窗口的做法是:
只要处于发送窗口范围中的数据包都可以被发送,不需要等待前面数据包的ack包。
如果发送窗口的大小为3个TCP数据包,那么发送方就可以连续发送3个TCP数据包,而不用等待前2个数据包的ack包。
滑动窗口详解
发送窗口
发送窗口存在于操作系统中开辟的一块缓冲区,用来存放当前需要发送的数据。本质是一个循环数组的实现。利用三个指针来维护相关的区域。
发送窗口就是一个循环利用的缓冲区,应用层发送数据,就是往缓冲区中写入数据。收到ACK后,就相当于从缓冲区中移除数据,不过并不会真正移除数据,只需要后移对应的指针就可以了。
应用层会将数据写入到缓冲区中,当超过缓冲区的最大地址后,就循环利用头部,覆盖头部的数据。
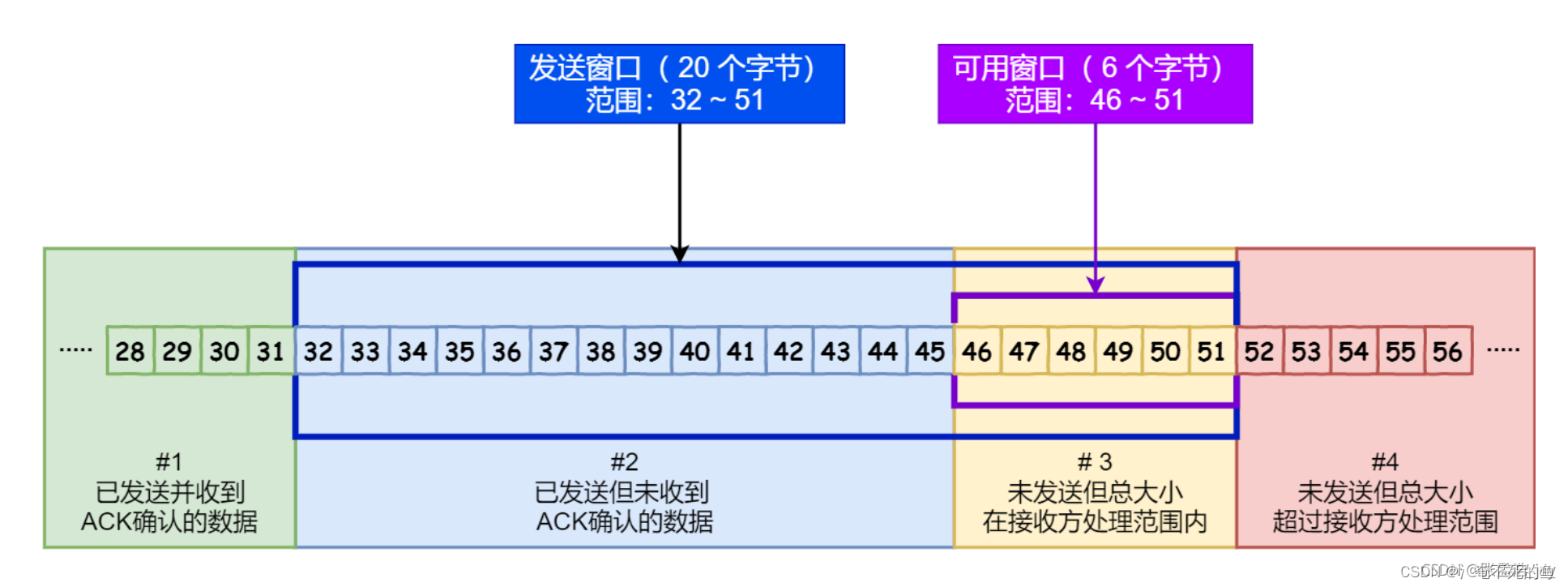
发送缓冲区分为四个部分:
1、已经收到ack包的数据
已经收到ack包的数据,代表接收窗口已经接收了对应的数据,可以被新数据覆盖。
2、已经发送还未接收到ack包的数据
已经发送出去,但是还未收到接收方对应的ack包
3、允许发送但是还未发送的数据
允许发送但是还未发送的数据。
4、不允许发送的数据。
发送窗口之外的数据,排队等待后续发送。
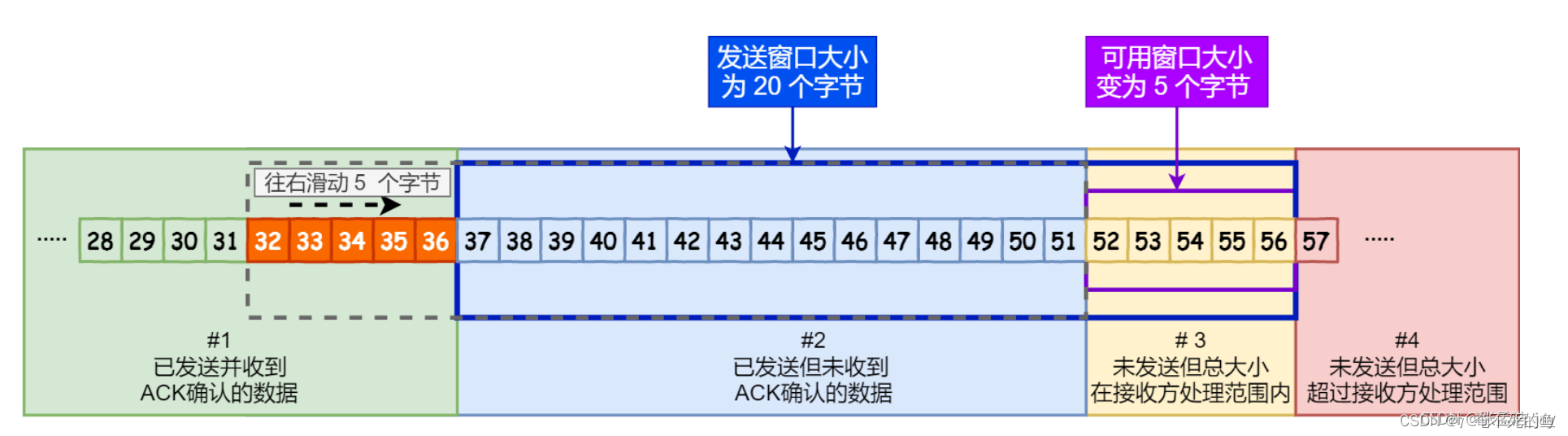
区间2 和 区间3 构成了发送窗口,两个区间的大小总和对应着发送窗口的大小
TCP中用三个指针来区分这个四个部分
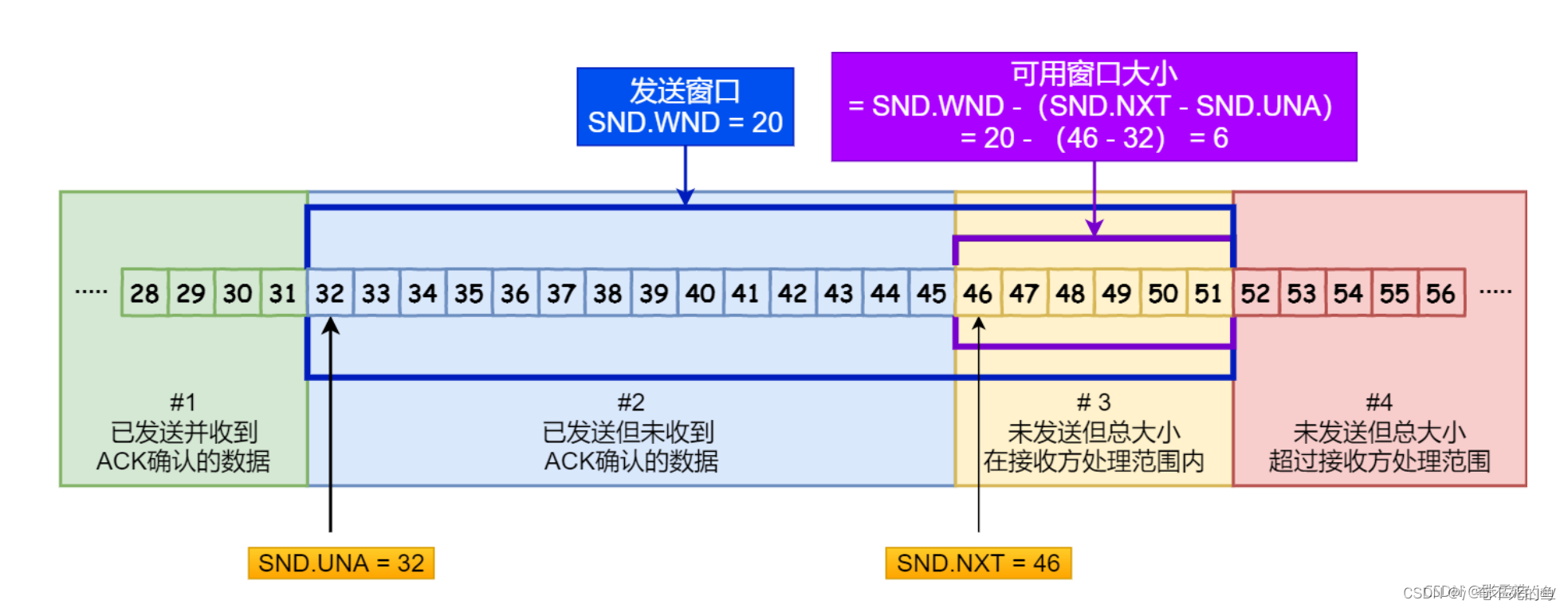
指针1: 指向第一个已发送但是未接收到ack的字节
指针2: 指向第一个允许发送但是还未发送的字节
指针3: 发送窗口的大小
这时还允许发送数据,就会将可用窗口中的数据发送给接收窗口。
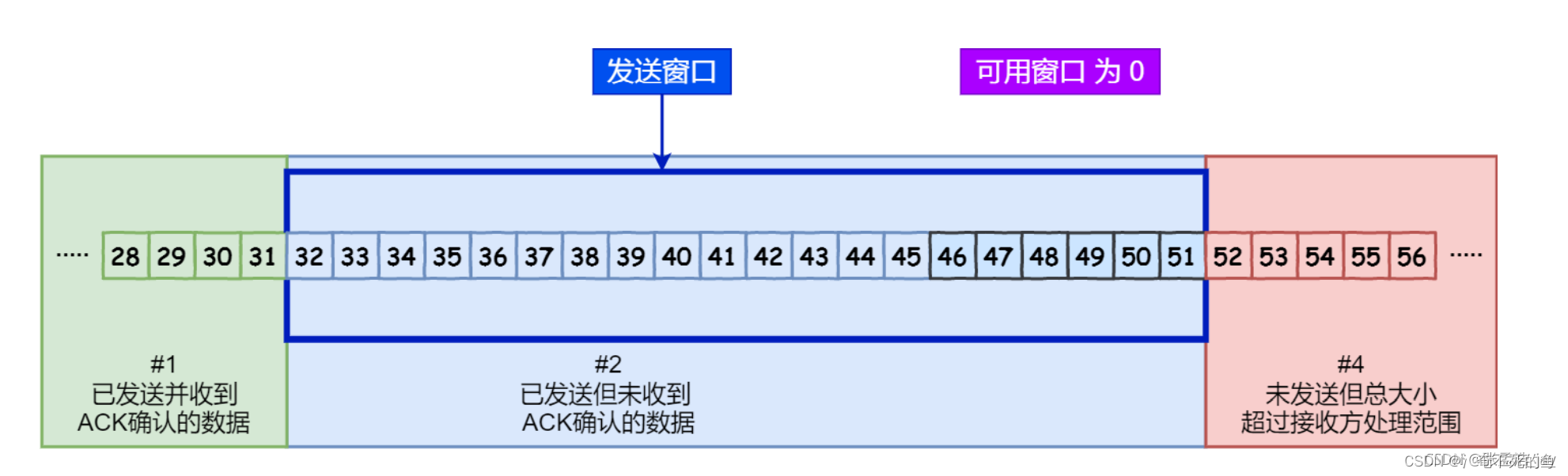
这个时候,可用窗口大小为0,这个时候会等待接收方发送ack包。
如果这个时候如果接收一个ack包为37,这个时候发送窗口会向右边移动5位,52-56会变成可用窗口。
接收窗口
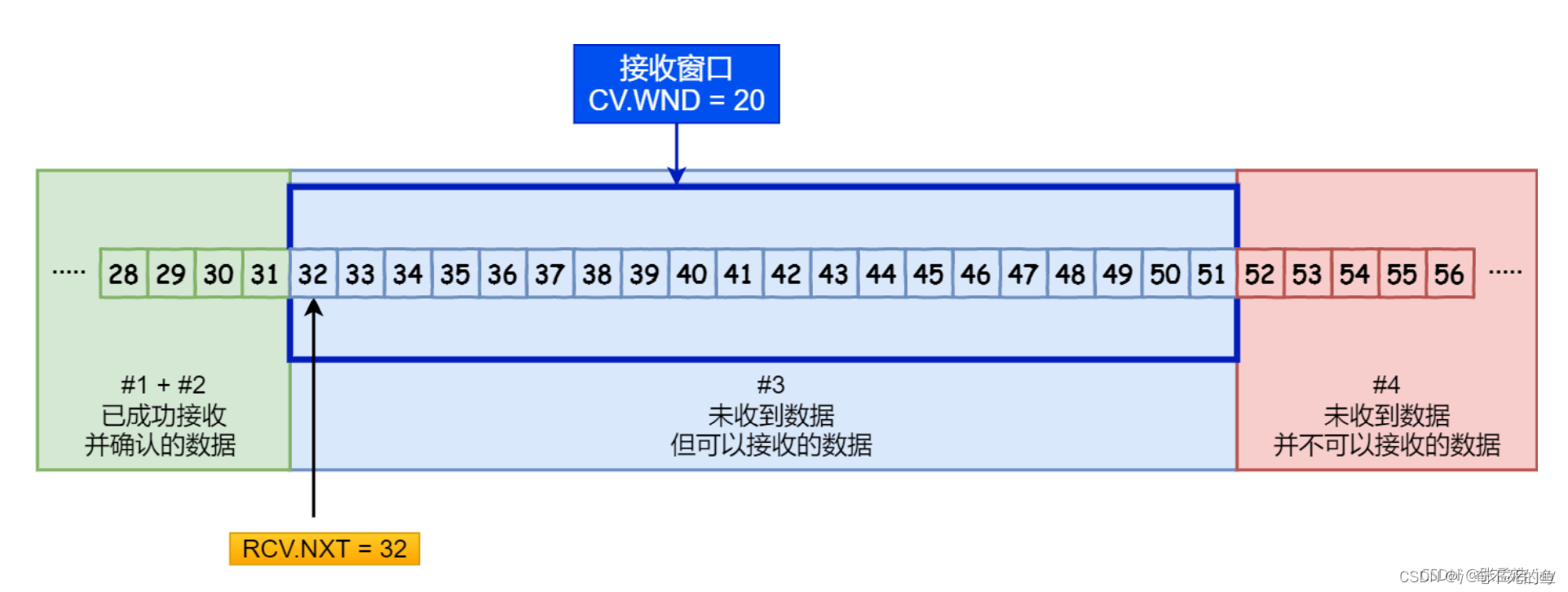
接收窗口中的字节序列号都是与发送窗口一一对应的。
接收窗口也是存在于操作系统中开辟的一块缓冲区,用于接收数据。缓冲区本质是一个循环数组的实现。利用两个指针来维护相关的区域。
接收窗口存在于一个循环利用的缓冲区,接收数据 就是往缓冲区中写入数据。应用层读取数据后,就相当于从缓冲区中移除数据,不过并不会真正移除数据,只需要后移对应的指针就可以了。
当数据写入超过缓冲区的最大地址后,就循环利用头部,覆盖头部的数据。
缓冲区分为三部分:
1、应用层已经读取的数据
已经接收到的数据,并且已经发送了ack包,并且已经被应用层读取。
2、接收窗口中的数据
接收窗口中存储的是当前允许被接收的数据。
接收窗口允许无序接收数据包,所以接收窗口中有一部分数据接收到了,一部分没接收到,将无序的数据包直接缓存到接收窗口中。接收窗口允许无序接收数据包,所以接收窗口中有一部分数据接收到了,一部分没接收到,将无序的数据包直接缓存到接收窗口中。
因为无序的接收数据包,接收窗口中是存在空隙的,因为先发送的数据包由于网络原因,反而可能会后到接收方。
当数据包缓存到接收窗口中,就会返回ack包,ack包中会携带SACK信息,也就是选择重选信息。
3、还未收到的数据
还不能接收数据的区域,也就是接收窗口之外的数据。
接收窗口由一个RCV_NEXT和接收窗口大小WND来维护。
RCV_NEXT
下一个希望接收的数据包的序列号,当接收到对应的数据包后,会将RCV_NEXT右移,右移到缓冲区中第一个为空的位置。
同时将WND 减去 移动的个数
WND
接收窗口的大小。
WND有以下两种变化:
1、接收窗口 有序的接收到对应的数据包,WND会减去对应的数据包长度。
2、应用程序读取了数据包 必须连续读,不能跳过间隙读取,会将WDN增加对应的数据包的长度
接受缓冲区的wind只有被应用程序读取后才会 变大右移。否则只会不断变小
接收窗口详情
接收窗口接收数据包后,即使应用程序没有读取对应的数据包,也会立马返回ack应答包,ack应答包中会携带当前接收窗口的大小WND和接收窗口的数据包缓存信息。
1、当数据包的seq == RCV_NEXT的数据包的时候,将接收窗口的RCV_NEXT右移到缓冲区中第一个为空的位置,WND减去对应的移动字节数 RCV_NEXT移动会发送对应的ACK数据包;
2、当数据包的seq > RCV_NEXT 并且 seq < RCV_NEXT+ WND的时候,会将其加入到滑动窗口中对应的位置。
3、如果数据包的seq < RCV_NEXT,说明该数据包已经被接收了,但是对应的ack包因为阻塞或者异常没有发送到发送方。那么这个包会被丢弃,这时接收方会利用其发送窗口发送一个ack包。
4、当应用程序将接收到的数据包读取之后,会将WND加上对应的读取数据包的大小。
滑动窗口的大小
发送窗口的大小要取决于接收窗口,如果发送窗口大于接收窗口的大小,会导致接收窗口无法完全接收数据包,导致一些数据包被丢弃,导致发送窗口的超时重传,浪费资源。
tcp报文头部中有一个window字段,代表着接收窗口的接收数据能力,发送窗口会根据window字段来调整发送窗口大小,保证接收窗口正常接收数据包。
滑动窗口的大小
发送窗口的大小要取决于接收窗口,如果发送窗口大于接收窗口的大小,会导致接收窗口无法完全接收数据包,导致一些数据包被丢弃,导致发送窗口的超时重传,浪费资源。
tcp报文头部中有一个window字段,代表着接收窗口的接收数据能力,发送窗口会根据window字段来调整发送窗口大小,保证接收窗口正常接收数据包。
发送窗口的大小不能超过接收窗口的大小,否则接收窗口不能正常接收数据。
总结
客户端和服务器都各自维护一个发送窗口和发送窗口,用来流水线模式的发送和接收数据。
发送窗口和接收窗口的本质是在操作系统中开辟的一块循环利用的缓冲区,用于存储要发送和接收数据。本质是一个循环数组的实现。利用若干指针来维护相关的区域。当数据写入超过缓冲区的最大地址后,就循环利用头部,覆盖头部的数据。
发送窗口就是一个循环利用的缓冲区,应用层发送数据,就是往缓冲区中写入数据。收到ACK后,就相当于从缓冲区中移除数据,不过并不会真正移除数据,只需要后移对应的指针就可以了。
发送缓冲区分为四个部分:
1、已经收到ack包的数据
已经收到ack包的数据,代表接收窗口已经接收了对应的数据,可以被新数据覆盖。
2、已经发送还未接收到ack包的数据
已经发送出去,但是还未收到接收方对应的ack包
3、允许发送但是还未发送的数据
允许发送但是还未发送的数据。
4、不允许发送的数据。
发送窗口之外的数据,排队等待后续发送。
区间2 和 区间3 构成了发送窗口,两个区间的大小总和对应着发送窗口的大小
接收窗口接收数据包后,会立马返回ack应答包(有序接受的情况),即使应用程序没有读取对应的数据包。
接收窗口也是一个循环利用的缓冲区,接收数据 就是往缓冲区中写入数据。应用层读取数据后,就相当于从缓冲区中移除数据,不过并不会真正移除数据,只需要后移对应的指针就可以了。
接收窗口详情
接收窗口接收数据包后,即使应用程序没有读取对应的数据包,也会立马返回ack应答包,ack应答包中会携带当前接收窗口的大小WND和接收窗口的数据包缓存信息。
1、当数据包的seq == RCV_NEXT的数据包的时候,将接收窗口的RCV_NEXT右移到缓冲区中第一个为空的位置,WND减去对应的移动字节数;
2、当数包的seq > RCV_NEXT 并且 seq < RCV_NEXT+ WND的时候,会将其加入到滑动窗口中对应的位置。
3、如果数据包的seq < RCV_NEXT,说明该数据包已经被接收了,但是对应的ack包因为阻塞或者异常没有发送到发送方。
这时接收方会利用其发送窗口发送一个ack包。
当应用程序将接收到的数据包读取之后,会将WND加上对应的读取数据包的大小。
拥塞控制
在某段时间,若对网络中某一资源的需求超过了该资源所能提供的可用部分,网络性能就要变坏,这种情况就叫做网络拥塞。
为什么需要拥塞控制
TCP通过滑动窗口来做流量控制,但是TCP觉得这还不够,因为滑动窗口需要依赖于连接的发送端和接收端,其并不知道网络中间发生了什么。具体一点,我们知道TCP通过一个timer采样了RTT并计算RTO,但是,如果网络上的延时突然增加,那么,TCP对这个事做出的应对只有重传数据,但是,重传会导致网络的负担更重,于是会导致更大的延迟以及更多的丢包,于是,这个情况就会进入恶性循环被不断地放大。试想一下,如果一个网络内有成千上万的TCP连接都这么行事,那么马上就会形成“网络风暴”,TCP这个协议就会拖垮整个网络。这是一个灾难。
所以,TCP不能忽略网络上发生的事情,而无脑地一个劲地重发数据,对网络造成更大的伤害。对此TCP的设计理念是:TCP不是一个自私的协议,当拥塞发生的时候,要做自我牺牲。就像交通阻塞一样,每个车都应该把路让出来,而不要再去抢路了。
拥塞窗口
发送方维持一个拥塞窗口cwnd的状态变量。拥塞窗口的大小取决于网络的拥塞程度,并且动态地在变化。同时,发送方让自己的发送窗口等于拥塞窗口。只要网络没有出现拥塞,拥塞窗口就再增大一些,以便把更多的分组发送出去。但只要网络出现拥塞,拥塞窗口就减少一些,以减少注入到网络中的分组数。
拥塞控制和流量控制的区别
拥塞控制:防止过多的数据注入到网络中,这样可以使网络中的路由器或链路不致过载。拥塞控制所要做的都有一个前提:网络能够承受现有的网络负荷。拥塞控制是一个全局性的过程,涉及到所有的主机、路由器,以及与降低网络传输性能有关的所有因素。
流量控制(滑动窗口就是一种流量控制):指点对点通信量的控制,是端到端的问题。流量控制所要做的就是抑制发送端发送数据的速率,以便使接收端来得及接收
TCP如此可靠,为什么应用层还需要确认机制
在基于进行网络编程时,为了保证消息被对方正常处理 ,会做一个确认机制,那么问题来了,TCP已经有这么多的保证可靠性的操作,为什么我们需要在应用层实现确认机制?
首先明确,在正常情况下,经过调用write方法后,tcp一定能够保证对端能够成功接受到这条TCP消息,但是并不能保证对端的应用层能够正常处理这条消息,也许因为对端应用层的一些逻辑出错,或者其他的一些错误,可能导致这条消息没能被正确处理
因此 TCP的可靠保证的是传输层可靠,至于传输层之上的应用能否正常处理数据包,TCP就无法保证了。需要应用层进行保证。









![[oeasy]python0052_ raw格式字符串_单引号_双引号_反引号_ 退格键](https://img-blog.csdnimg.cn/img_convert/cce5958864a3a2f40b72f3350a0613ee.png)
