文章目录
- 第一种解释
- 1、基本用法
- 2、指定值收集器
- 3、多级分组
- 4、常见应用场景和用处
- 第二种解释
- 1、基本语法
- 2、示例
- 3、更复杂的用法
第一种解释
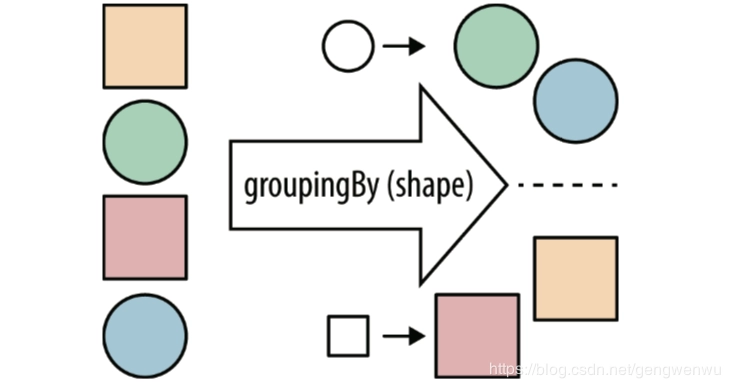
Collectors.groupingBy 是 Java 8 引入的 Stream API 中的一个收集器(Collector),它用于将流(Stream)中的元素根据某个分类函数收集到 Map 中。这个 Map 的键是分类函数的返回值,值是流中对应键的所有元素的列表(List)。
Collectors.groupingBy 有几个重载版本,允许你指定如何映射键以及如何收集值。
1、基本用法
import java.util.*;
import java.util.stream.Collectors;
List<String> fruits = Arrays.asList("apple", "banana", "apple", "orange", "banana");
Map<String, List<String>> fruitCountMap = fruits.stream()
.collect(Collectors.groupingBy(fruit -> fruit));
System.out.println(fruitCountMap);
// 输出: {apple=[apple, apple], banana=[banana, banana], orange=[orange]}
2、指定值收集器
你还可以指定一个下游收集器(downstream collector)来收集每个键对应的值。例如,如果你想计算每个水果的数量而不是收集到一个列表中,你可以这样做:
Map<String, Long> fruitCountMap = fruits.stream()
.collect(Collectors.groupingBy(fruit -> fruit, Collectors.counting()));
System.out.println(fruitCountMap);
// 输出: {apple=2, banana=2, orange=1}
3、多级分组
你还可以使用 groupingBy 进行多级分组。这通常是通过 Collectors.groupingBy 的嵌套使用来实现的。例如,假设你有一个 Person 类,你想先按性别分组,然后按年龄分组:
List<Person> people = ... // 假设这里有一个 Person 对象的列表
Map<Gender, Map<Integer, List<Person>>> groupedByGenderAndAge = people.stream()
.collect(Collectors.groupingBy(Person::getGender,
Collectors.groupingBy(Person::getAge)));
在这个例子中,groupedByGenderAndAge 是一个 Map,其键是 Gender 枚举类型,值是另一个 Map,该 Map 的键是年龄(Integer),值是符合这两个条件的 Person 对象的列表。
4、常见应用场景和用处
Collectors.groupingBy 在 Java 中是一个非常有用的工具,它允许你以简洁且声明式的方式 对流中的元素进行 分组 。这在处理大量数据并希望以某种方式对它们进行分类时特别有用。以下是 Collectors.groupingBy 的一些常见应用场景和用处:
-
数据聚合:当你有一组数据并希望根据某个或多个属性将它们分组以进行进一步分析或处理时,
groupingBy是一个很好的选择。例如,你可能有一个订单列表,并希望按客户或产品类型对它们进行分组。 -
统计和报告:在处理大量数据时,经常需要生成各种统计报告。使用
groupingBy可以很容易地根据某个或多个属性对数据进行分组,并计算每个组的数量、总和、平均值等。 -
优化和性能:通过将数据分组,你可以更容易地识别出异常值、模式或趋势,从而优化系统性能或业务决策。
-
数据可视化:在数据可视化中,经常需要将数据分组以创建有意义的图表和图形。使用
groupingBy可以简化将数据准备成可视化工具所需格式的过程。 -
多级分组:通过嵌套使用
groupingBy,你可以对数据进行多级分组。这在处理具有多个维度或属性的数据时特别有用,例如地理位置(国家/地区、州/省、城市)或产品分类(部门、类别、子类别)。 -
简化代码:与传统的循环和条件语句相比,使用
groupingBy可以使代码更简洁、更易读。它还允许你以声明式方式表达你的意图,而不是编写冗长的过程式代码。 -
扩展性:
groupingBy是一个灵活的工具,可以与其他 Stream API 方法和收集器(如filtering、mapping、counting、summingInt等)一起使用,以创建复杂的数据处理管道。
总之,Collectors.groupingBy 是 Java 8 Stream API 中的一个强大工具,它可以帮助你以简洁、高效和可维护的方式处理大量数据。
第二种解释
在Java中,stream().collect(Collectors.groupingBy()) 是一个常用的函数式编程方法,用于将流中的元素根据指定的分类器函数分组,并收集到一个Map中。这里是一个基本的使用示例和解释:
1、基本语法
Map<K, List<T>> result = stream.collect(Collectors.groupingBy(keyExtractor));
stream:是一个流对象,包含了你想要分组的数据。Collectors.groupingBy(keyExtractor):这是关键部分,它接受一个函数(通常是一个 lambda 表达式或者方法引用),这个函数被称为keyExtractor,用于从流中的每个元素提取一个键(K类型),用来决定如何分组。result:是一个Map,其中的键是keyExtractor产生的值,值是列表,列表中包含所有拥有相同键的元素。
2、示例
假设我们有一个Person类,包含属性name和age,并且有一个List<Person>,我们想要按照年龄分组:
class Person {
String name;
int age;
// 构造函数、getter和setter省略...
}
List<Person> people = ... // 初始化人员列表
Map<Integer, List<Person>> peopleByAge = people.stream()
.collect(Collectors.groupingBy(Person::getAge));
// 打印结果
peopleByAge.forEach((ageGroup, persons) ->
System.out.println("Age " + ageGroup + ": " + persons));
在这个例子中,Person::getAge是一个方法引用,作为keyExtractor,它将人按年龄分组。结果是一个映射,其中键是年龄,值是具有相同年龄的Person对象列表。
3、更复杂的用法
Collectors.groupingBy还支持更复杂的分组操作,比如分组后进一步收集操作(如求和、平均值、计数等):
Map<Integer, Double> averageAgeByAgeGroup = people.stream()
.collect(Collectors.groupingBy(Person::getAge,
Collectors.averagingInt(Person::getAge)));
在这个变体中,我们不仅按年龄分组,还在每个分组内计算平均年龄。
记住,Collectors.groupingBy非常灵活,可以根据具体需求进行各种定制。