目录
🧾 1、数据集(部分数据)
✏️ 2、导入数据集与必要模块
1️⃣ 2.1 导入库以及字体包
2️⃣ 2.2 读取数据集
3️⃣ 2.3 查看数据集基本信息
⌨️ 3、数据预处理
1️⃣ 3.1删除无关字段
2️⃣ 3.2对各字段进行中文标识
3️⃣ 3.3 用条形图展示字段类型个数
📍 df.rename(index=None,columns=None,axis=None,inplace=False)
📍 value_counts(sort,ascending,normalize,bins,dropna)
📊 4、使用量影响因素可视化分析
1️⃣ 4.1 利用直方图、箱线图观察单车使用量的分布
📍 直方图
📍 箱线图
2️⃣ 4.2 利用条形图、饼图对比两年的单车使用量
📍 分组聚合dataframe.groupby(by=None,axis=0,level=None,as_index=True,sort=True,group_keys=True,squeeze=NoDefault.no_default,observed=False,dropna=True)
📍 条形图
📍 饼图
🧾 1、数据集(部分数据)
- day数据集

| 字段名称 | 含义说明 |
| instant | 行数编码 |
| dteday | 日期变量 |
| season | 季节变量,编码1-4分别表示1-3月、4-6月、6-9月,10-12月 |
| yr | 年份变量,编码0代表2011年,1代表2012年 |
| mnth | 月份编码,范围为1-12,代表1-12月 |
| holiday | 是否为节假日,0代表不是,1代表是 |
| weekday | 一周的第几天,范围为0-6 |
| workingday | 是否为工作日,0代表不是,1代表是 |
| weathersit | 天气类型,1代表晴朗少云,2代表多云雾,3代表小雨/小雪/雷电 |
| temp | 以摄氏度表示的标准化温度,值被除以41(最大值) |
| atemp | 以摄氏度表示的标准化感觉温度,值被除以50(最大值) |
| hum | 标准化湿度,值被除以100(最大值) |
| windspeed | 标准化风速,值被除以67(最大值) |
| casual | 未注册用户单车使用量 |
| registered | 注册用户单车使用量 |
| cnt | 所有用户单车使用量,包括未注册用户和注册用户 |
- tree数据集

✏️ 2、导入数据集与必要模块
1️⃣ 2.1 导入库以及字体包
# 导入pandas模块和numpy模块
import pandas as pd
import numpy as np
# 3.# 导入matplotlib.pyolot模块
import matplotlib.pyplot as plt
from plotnine import *
%matplotlib inline
# 3.设置绘图时的中文字体
from matplotlib.font_manager import FontProperties
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus']=False
# 4.字体包的存放路劲、设置字体的大小为15
myfont = FontProperties(fname = 'C:/XXX/xxx/Desktop/实验五——共享单车可视化/FangSong_GB2312.ttf', size = 15) 2️⃣ 2.2 读取数据集
# 1.读取数据
data_old = pd.read_csv('C:/XXX/xxx/Desktop/实验五——共享单车可视化/day.csv')
# 2.查看数据的前5行
data_old.head()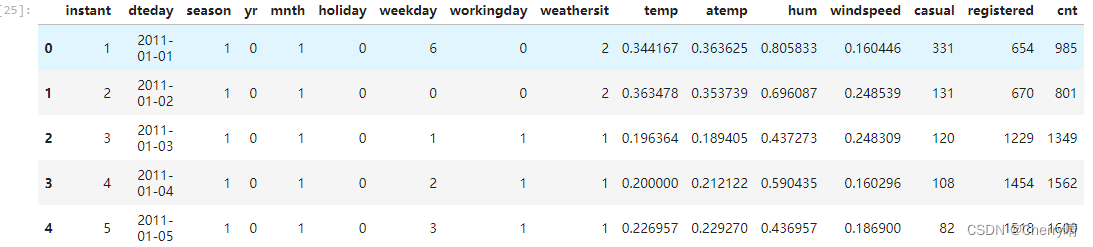
3️⃣ 2.3 查看数据集基本信息
# 1.查看数据集基本信息
data_old.info()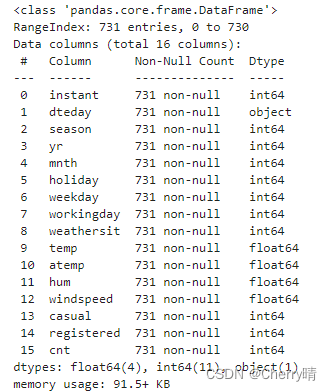
- 从结果中可以看出,数据集中共包含731条数据,没有缺失数据 。
⌨️ 3、数据预处理
1️⃣ 3.1删除无关字段
-
有些字段与数据分析无关,例如:字段instant表示行数编码,可以直接删除。
-
有些字段的含义较为接近,保留其一即可,例如:字段atemp和temp都表示温度,留下一个就可以。
# 1.使用drop方法来删除字段
data = data_old.drop(['instant', 'atemp', 'casual', 'registered'], axis=1) 2️⃣ 3.2对各字段进行中文标识
# 1.字段名称
chs_name = {'dteday': '日期', # {'新列名':'旧列名'}
'season': '季节',
'yr': '年份',
'mnth': '月份',
'holiday': '节假日',
'weekday': '星期',
'workingday': '工作日',
'weathersit': '天气类型',
'temp': '温度',
'hum': '湿度',
'windspeed': '风速',
'cnt': '使用量'}
# 2.使用rename方法对列明进行修改,是直接在元数据进行修改
data.rename(columns=chs_name, inplace=True)
# 3.标识后的结果
data.head()
3️⃣ 3.3 用条形图展示字段类型个数
📍 df.rename(index=None,columns=None,axis=None,inplace=False)
| 字段 | 数据类型 | 含义 |
| index | list 或 dict 或 series | 用于重命名行索引的标签或映射的字典,如{ 0 : “第一行”} |
| columns | list 或 dict 或 series | 用于重命名列名的标签或映射的字典,如{ A : “第一列”} |
| axis | int 或 str | 要重命名的轴 |
| inplace | bool | 是否在原地修改 DataFrame,如果为True,则直接在原 DataFrame 上进行修改,不返回新的 DataFrame,如果为False(默认值),则返回一个新的 DataFrame,原 DataFrame 保持不变 |
📍 value_counts(sort,ascending,normalize,bins,dropna)
| 字段 | 数据类型 | 含义 |
| sort | bool | 默认为True,如果为True,则对结果进行降序排序(从最常见的值到最不常见的值),如果为False,则不会进行排序 |
| ascending | bool | 默认值为 False,如果为False,则结果按降序排序(最常见的值在最前面),如果为True,则结果按升序排序(最不常见的值在最前面) |
| normalize | bool | 默认值为False,如果为True,则返回每个值出现的频率(即每个值出现的次数除以总数),如果为False,则返回每个值出现的次数 |
| bins | int 或 array | 可以用来对数据进行分箱,并将结果作为类别计数返回,如果指定了bins,则normalize 必须为False |
| dropna | bool | 默认值为True,如果为True,则不在结果中包含缺失值(NaN),如果为False,则会在结果中包含缺失值,并计算它们的出现次数 |
🔷 data_type_df = pd.DataFrame(data.dtypes.value_counts()).rename(columns={0: 'count'})
- data.dtypes:这个操作会返回一个Series,其中包含data DataFrame中每列的数据类型
- data.dtypes.value_counts():使用value_counts()方法,我们计算data DataFrame中每种数据 类型的出现次数。这将返回一个Series,其中索引是数据类型,值是相应的计数
- pd.DataFrame(data.dtypes.value_counts()):我们将上一步得到的Series转换为一个新的 DataFrame。默认情况下,Series的索引将成为新DataFrame的索引,而Series的值将成为新 DataFrame的唯一一列,列名为0
- .rename(columns={0: 'count'}):使用rename()方法,我们将新DataFrame中列名0更改为count。这里,columns={0: 'count'}是一个字典,指定了列名的映射关系
📍 绘制图形xxx.plot(kind,x,y,ax,subplots,sharex, sharey,layout,figsize,title,xlabel, ylabel,legend,style,logx, logy,xticks, yticks,grid,use_index,colormap,colorbar)
| 字段 | 数据类型 | 含义 |
| kind | str | 定义了图形的类型,如 'line', 'bar', 'barh', 'hist', 'box', 'kde', 'density', 'area', 'pie', 'scatter', 'hexbin' 等 |
| x,y | str 或 array-like | 定义了用于绘图的数据列。x 是 x 轴的数据,y 是 y 轴的数据。如果是 str 类型,则代表 DataFrame 中的列名;如果是 array-like 类型,则代表具体的数值 |
| ax | matplotlib.axes.Axes 或 None | 一个 matplotlib axes 对象,绘图将在这个对象上进行。如果为 None,则会创建一个新的 axes 对象 |
| subplots | bool | 如果为 True,则创建子图进行绘图 |
| sharex,sharey | bool | 如果创建子图(subplots=True),这些参数决定了 x 轴或 y 轴是否共享 |
| layout | tuple | 用于子图的布局,格式为 (rows, columns) |
| figsize | tuple | 定义图形的尺寸,格式为 (width, height) |
| title | str | 图形的标题 |
| xlabel, ylabel | str | x 轴和 y 轴的标签 |
| legend | bool 或 ‘reverse’ | 是否显示图例,或者是否反转图例的顺序 |
| style | list 或 array | 用于线条的样式列表或数组 |
| logx, logy | bool | 是否对 x 轴或 y 轴使用对数刻度 |
| xticks, yticks | list 或 array | x 轴或 y 轴的刻度位置 |
| grid | bool | 是否显示网格线 |
| use_index | bool | 是否将 DataFrame 的索引用作 x 轴的值 |
| colormap | str 或 matplotlib.colors.Colorma | 用于绘制图形的颜色映射 |
| colorbar | bool | 是否显示颜色条 |
# 1.统计数据以及对字段进行重命名
data_type_df = pd.DataFrame(data.dtypes.value_counts()).rename(columns={0: 'count'})
# 2.绘制条形图
data_type_df.plot(kind='bar', # 绘制图的类型
title='字段类型个数条形图', # 设置标题
legend=False, # 子图的图例
rot=360, # 设置轴标签的旋转度数
figsize=(8, 6)) # 图片的尺寸大小
📊 4、使用量影响因素可视化分析
1️⃣ 4.1 利用直方图、箱线图观察单车使用量的分布
📍 直方图
plt.hist( x, bins=10, range=None, normed=False, weights=None, cumulative=False, bottom=None, histtype=u'bar', align=u'mid', orientation=u'vertical', rwidth=None, log=False, color=None, label=None, stacked=False, hold=None, **kwargs)
| 字段 | 数据类型 | 含义 |
| x | array | 输入数组或序列的数组,用于计算直方图。它应该是一维的,或者如果是一个序列,序列中的每个数组都应该是一维的 |
| bins | int or sequence or str | 指定直方图的箱子数量或箱子边界。如果是一个整数,则它定义了等宽的箱子的数量。如果是一个序列,则它定义了箱子边界,包括右边界但不包括左边界,串 'auto'、'sturges'、'fd'、'doane'、'rice'、'sturges'、'sqrt' 可以自动选择箱子数量 |
| range | float | 直方图的范围 (xmin, xmax),即 x 轴的最小值和最大值。如果 None,则使用 x 的范围 |
| normed | bool | 如果为 True,则返回的直方图值将显示为密度,即每个箱子的计数将除以所有箱子的计数之和(从而总和为 1)。注意:normed 参数在较新的 Matplotlib 版本中已被重命名为 density |
| weights | array | 与 x 形状相同的权重数组,用于对直方图中的每个元素进行加权 |
| cumulative | bool | 如果为 True,则绘制累积直方图 |
| histtype | str | {'bar', 'barstacked', 'step', 'stepfilled'}, optional直方图的类型 |
| align | str | {'left', 'mid', 'right'}控制直方图条形的对齐方式 |
| orientation | str | {'horizontal', 'vertical'}设置直方图的方向 |
| rwidth | scalar or array | 条形宽度(以箱子宽度的百分比表示) |
| log | bool | 如果为 True,则对直方图使用对数刻度 |
| color | array | 直方图的颜色 |
| label | str | 直方图的标签,用于图例 |
| stacked | bool | 如果为 True,则绘制堆叠的直方图 |
📍 箱线图
plt.boxplot(x, notch=None,sym=None, vert=None, whis=None, positions=None, widths=None, patch_artist=None, bootstrap=None, usermedians=None, conf_intervals=None, meanline=None, showmeans=None, showcaps=None, showbox=None, showfliers=None, boxprops=None, labels=None, flierprops=None, medianprops=None, meanprops=None, capprops=None, whiskerprops=None, manage_xticks=True, autorange=False, zorder=None, hold=None, data=None)
| 字段 | 数据类型 | 含义 |
| x | array or list of arrays | 输入数据。如果 x 是一个一维数组或列表,则绘制一个箱线图。如果 x 是一个二维数组或列表的列表,则每一列都将绘制为一个独立的箱线图,并可以通过 positions 参数来指定它们在 x 轴上的位置 |
| notch | bool or None | 是否创建一个缩进的表示中位数的记号。如果为 None,则默认由 bootstrap 参数决定 |
| sym | str | 用于超出上下四分位距的点的符号。默认为 '+' |
| vert | bool | 如果为 True(默认值),则创建垂直箱线图。如果为 False,则创建水平箱线图 |
| whis | float sequence or string | 定义上下四分位距之外异常值的范围。可以是 0 到 1 之间的浮点数,表示相对于四分位距的倍数;也可以是一个包含两个浮点数的序列,分别定义下限和上限;或者是一个包含字符串 'range' 的序列,用来指定一个固定的范围 |
| positions | array of floats | 用于绘制箱线图的 x 轴位置。当 x 是一个二维数组时,positions 定义了每一列箱线图在 x 轴上的位置 |
| widths | scalar sequence | 箱体的宽度。可以是单个数值,用于所有箱体;也可以是一个序列,用于指定每个箱体的宽度 |
| patch_artist | bool | 是否填充箱体的颜色 |
| bootstrap | int | 指定用于计算置信区间的自举样本的数量。如果为 0,则不进行自举,并且箱体的记号不会缩进 |
| labels | array of strings | 箱线图的标签 |
| boxprops | dict | 用于设置箱体属性的字典,例如颜色、线宽 |
| flierprops | dict | 用于设置超出范围的点(flyers)属性的字典 |
| medianprops | dict | 用于设置中位数线属性的字典 |
| capprops | dict | 用于设置箱线图顶部和底部“帽子”线属性的字典 |
| whiskerprops | dict | 用于设置箱线图“胡须”线(即连接中位数和四分位数的线)属性的字典 |
| manage_xticks | bool | 如果为 True,则调整 x 轴刻度位置以适合箱线图的位置 |
| autorange | bool | 是否自动调整箱线图的范围以包含所有数据点 |
| zorder | float | 控制绘图元素的堆叠顺序 |
# 1.绘制直方图
plt.figure(figsize = (14,6)) # 图片的尺寸大小
plt.subplot(1, 2, 1) # 生成一行两列两个子图,现在将画在第一个位置
plt.hist(data['使用量'], # 选取data中'使用量'这一列的数据画图
bins=8, # 直方图的柱数,默认值为10
facecolor='green', # 直方图的颜色
alpha=0.5, # 透明度
edgecolor='black') # 直方图的边框颜色
# 2.设置标题、x轴、y轴的标题,以及字体的大小
plt.title('使用量直方图', fontsize=15)
plt.xlabel('使用量', fontsize=15)
plt.ylabel('频数', fontsize=15)
# 3.绘制箱线图
plt.subplot(1, 2, 2) # 生成一行两列两个子图,现在将画在第二个位置
plt.boxplot(data['使用量'], # 选取data中'使用量'这一列的数据画图
labels=['使用量'], # 添加标签
patch_artist = True, # 表示填充箱体颜色
boxprops = {'color':'black','facecolor':'yellow'}, # 设置箱子外框的颜色和箱子内部填充的颜色
flierprops = {'markerfacecolor':'red','color':'black'}) # 设置异常值的颜色为黑色,中位数为红色
# 4.设置标题
plt.title('使用量箱线图', fontsize=15)
# 5.设置x轴的标签的字体大小
plt.xticks(fontsize=12) 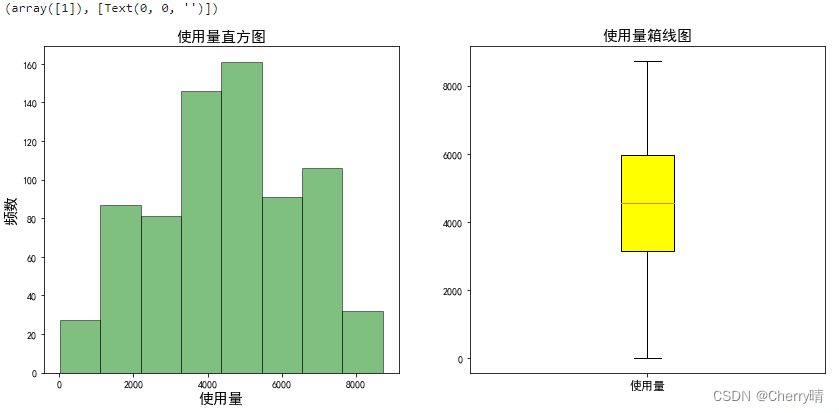
2️⃣ 4.2 利用条形图、饼图对比两年的单车使用量
📍 分组聚合dataframe.groupby(by=None,axis=0,level=None,as_index=True,sort=True,group_keys=True,squeeze=NoDefault.no_default,observed=False,dropna=True)
| 字段 | 数据类型 | 含义 |
| by | str dict series | 用于确定分组依据的列名、列名列表、字典、Series 或函数。如果传递的是函数,它将应用于每一列,并返回用于分组的值 |
| axis | int | 分组的轴。0 或 'index' 表示按行分组(这是默认的),1 或 'columns' 表示按列分组。 |
| level | int | 如果轴是一个 MultiIndex(多级索引),则用于分组的级别或级别序列 |
| as_index | bool | 对于聚合操作,返回对象是否应有其分组作为索引。设置为 False 会将分组标签作为普通列返回在结果 DataFrame 中 |
| sort | bool | 是否对分组键进行排序。设置为 False 将加快操作速度,尤其是在已经排序的数据上 |
| group_keys | bool | 当调用 apply 时,是否将分组键添加到索引中。如果为 False,则不会添加 |
| squeeze | bool | 如果可能的话,返回标量、Series 或 DataFrame。这在分组只产生一个唯一值时特别有用 |
🔹 groupby函数通常涉及1-3个操作步骤:
(1) Splitting 分割:根据一些准则,将数据框分割为多个子集;
(2) Applying 应用:
(1)对某个子集应用某个函数,比如计算每个组的汇总信息(总和、均值、计数);
(2)转换;
(3)筛选。
(3) Combing 组合:将应用函数后的结果,组合起来形成新的数据框。
注意:(1) 分组函数返回的是一个 DataFrameGroupBy对象(比如 gp = df.groupby(‘col1’, ‘col2’), gp是groupby函数返回的对象),可以通过 gp.get_group(‘col1val1’, ‘col2val2’) 检索对象中的子集。
(2) 在分组、应用函数(比如计数、求均值)之后,返回的是一个DataFrame,很方便做表、画图等进一步处理,比如gp.count()是一个DataFrame,然后接着画图:gp.count().plot.bar(‘col3’)
📍 条形图
plt.bar(x, height, width=0.8, bottom=None, align='center', data=None, **kwargs)
| 字段 | 数据类型 | 含义 |
| x | float or array | x坐标的位置。可以是单个数字、长度为N的数组或标量序列。对于水平条形图,它表示条形的y坐标位置 |
| height | float or array | 条形的高度。对于水平条形图,这个参数表示条形的宽度 |
| width | scalar or array | 条形的宽度。默认值为0.8,表示每个条形宽度的相对大小。如果指定为数组,则数组长度应与x或height的长度相同 |
| bottom | float or array | y坐标的基线位置,即条形图底部的y坐标。如果指定为数组,则数组长度应与x或height的长度相同。默认为None,表示基线位置为0 |
| align | str | 条形对齐方式。'center'表示条形以x位置为中心,'edge'表示条形左边缘位于x位置。默认为'center' |
| data | indexable object | 可选参数,用于传递包含变量的对象。通常用于pandas DataFrame或Series |
| kwarg | - | 其他关键字参数。例如,color 参数用于设置条形的颜色,edgecolor 参数用于设置条形边缘的颜色,label 参数用于设置图例标签等 |
📍 饼图
plt.pie(x ,labels,autopct = '%3.2f%%',shadow = True ,labeldistance = 1.1,startangle = 90,pctdistance = 0.7)
| 字段 | 数据类型 | 含义 |
| x | array or list | 包含每个扇区的数值大小 |
| labels | array or list | 与 x 参数的长度相同,用于每个扇区的标签。labels 是一个包含字符串的序列,每个字符串是饼图中对应扇区的标签 |
| autopct | str | 用于控制每个扇区百分比标签的显示格式。'%3.2f%%' 表示每个百分比标签将显示为固定点格式,保留两位小数 |
| shadow | bool | 控制饼图是否应该有阴影效果。设置为 True 将添加阴影效果 |
| labeldistance | float | 控制标签距离圆心的距离,单位是半径的比例。1.1 表示标签距离圆心的距离是饼图半径的 1.1 倍 |
| startangle | float | 控制饼图的起始角度,以度为单位。90 表示饼图从水平方向开始 |
| pctdistanc | float | 控制百分比标签距离圆心的距离,单位是半径的比例。0.7 表示百分比标签距离圆心的距离是饼图半径的 0.7 倍 |
# 1.绘制条形图
### 分组聚合
count_grouped = data['使用量'].groupby(data['年份']).sum() # 选取data数据中'使用量'这列的数据,根据'年份'进行分组,并统计总数
count_grouped_df = count_grouped.reset_index() # reset_index()主要用于重置索引,在获得新的index,原来的index会变成数据列,保存在数据框中
count_grouped_df['年份'] = count_grouped_df['年份'].map({0:'2011', 1:'2012'}) # 使用map()方法,将值为0映射成2011,值为1映射成2012
# 2.绘图
plt.figure(figsize = (14,6))
plt.subplot(1, 2, 1)
plt.bar(count_grouped_df['年份'],
count_grouped_df['使用量'],
width=0.5, # 设置柱状图的宽度,正常值在0-1之间,默认值是0.8
color=['blue', 'orange']) # 设置柱状图内部填充的颜色
plt.title('两年使用总量对比条形图', fontsize=15)
plt.xlabel('年份', fontsize=15)
plt.ylabel('使用量', fontsize=15)
# 3.绘制饼状图
### 计算百分比
count_grouped_df['百分比'] = count_grouped_df['使用量']/count_grouped_df['使用量'].sum()
### 绘图
plt.subplot(1, 2, 2)
plt.pie(count_grouped_df['百分比'],
labels=['2011', '2012'], # 设置饼图内各部分的标签
autopct = '%1.1f') # 设置饼图内的文本
plt.title('两年使用总量对比饼状图', fontsize=15)
plt.legend(loc='upper right', fontsize=10)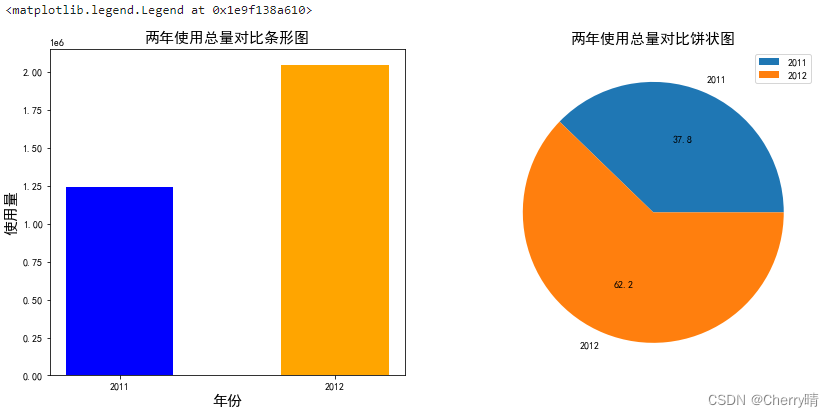
注意:本文中数据以及内容若有侵权,请第一时间联系删除。
本文未经作者授权,禁止转载,谢谢配合。