一 RDD
1.1 RDD的概述
1.RDD(Resilient Distributed Dataset,弹性分布式数据集)是Apache Spark中的一个核心概念。它是Spark中用于表示不可变、可分区、里面的元素可并行计算的集合。RDD提供了一种高度受限的共享内存模型,即RDD是只读的记录集的分区集合,只能通过在其他RDD执行确定的转换操作(如map、filter、join等)来创建新的RDD。
1.2 RDD的五大特性
-
不可变性(Immutable):RDD 的内容不可修改,只能通过转换操作生成新的 RDD。
-
容错性(Fault-Tolerant):RDD 可以容忍节点故障,通过存储每个分区的转换操作记录,可以在发生故障时重新计算丢失的分区。
-
可分区(Partitioned):RDD 将数据划分为多个分区,这些分区可以在集群中的多个节点上并行处理。
-
可持久化(Persisted):RDD 可以通过调用
persist()或cache()方法将其缓存在内存中,以便在后续操作中重用。 -
惰性评估(Lazy Evaluation):RDD 的转换操作是惰性的,只有在遇到行动操作时才会真正执行转换操作。
-
RDD由很多分区(partition)构成,有多少partition就对应有多少任务(task)
-
算子实际上是作用在每一个分区上
-
RDD之间有依赖关系,宽依赖和窄依赖,用于切分Stage
-
Spark默认是hash分区,ByKey类的算子只能作用在kv格式的rdd上
-
Spark为task的计算提供了最佳的计算位置,移动计算而不是移动数据
1.3 依赖关系
1.宽依赖:父rdd对应多个子rdd
2.宽依赖的算子:
- 所有byKey算子:如partitionBy、groupByKey、reduceByKey、aggregateByKey、foldByKey、combineByKey、sortByKey等。
- repartition、cartesian算子。
- 部分join算子,特别是非hash-partitioned的join算子。
3.窄依赖:一个父rdd或者多个父rdd对应一个子rdd
4.窄依赖算子:
map、filter、flatMap、mapPartitions、mapPartitionsWithIndex、sample、union、distinct、coalesce、repartitionAndUnion等。
5.切分stage,stage的个数等于宽依赖的个数+1
6.计算rdd之间的依赖关系构建DAG
7.窄依赖的分区数是不可以改变,取决于第一个RDD分区数,宽依赖可以在产生shuffle的算子上设置分区数
1.4 算子
1.4.1 map算子
1.map算子是处理里面每一个元素的
2.语法:
xxx.map((变量名:变量类型)=>{
变量的处理
})
3.可以结合匹配选择,抽取元素
val clazzWithAgeRDD: RDD[(String, Int)] = splitRDD.map {
case Array(_, _, age: String, _, clazz: String) => (clazz, age.toInt)
} //创建spark环境
val conf = new SparkConf()
//明确运行模式
conf.setMaster("local")
//给任务取名字
conf.setAppName("Map算子的演示")
//创建对象
val context: SparkContext = new SparkContext(conf)
//读取文件
val stuRDD: RDD[String] = context.textFile("spark/data/ws/students.csv")
//Map算子:将rdd中的数据,一条一条的取出来传入到map函数中,map会返回一个新的rdd,map不会改变总数据条数
val mapRDD: RDD[List[String]] = stuRDD.map((stu: String) => {
stu.split(",").toList
})
//使用foreach行动算子
mapRDD.foreach(println)1.4.2 filter
1.筛选的作用,返回另一个RDD
2.语法:
xxx.filter((变量名:变量类型)=>{
变量的处理
})
/创建spark环境
val conf = new SparkConf()
//确定运行模式
conf.setMaster("local")
//给任务取名字
conf.setAppName("filter算子演示")
//创建对象
val context: SparkContext = new SparkContext(conf)
//读取文件
val stuRDD: RDD[String] = context.textFile("spark/data/ws/students.csv")
/**
* filter:过滤,将RDD中的数据一条一条取出传递给filter后面的函数,
* 如果函数的结果是true,该条数据就保留,否则丢弃,取出来的结果组成一个新的RDD
*/
//取出所有男生
val filterRDD: RDD[String] = stuRDD.filter((stu: String) => {
val stuList: Array[String] = stu.split(",")
"男".equals(stuList(3))
})
filterRDD.foreach(println)//全都是男生的全部信息1.4.3 flatMap
1.扁平化
2.语法:
xxx.flatMap((变量名:变量类型)=>{
变量的处理
})
//创建spark环境
val conf = new SparkConf()
//确定运行模式
conf.setMaster("local")
//给任务取名字
conf.setAppName("flatMap算子演示")
//创建对象
val context: SparkContext = new SparkContext(conf)
//读取文件
val stuRDD: RDD[String] = context.textFile("spark/data/ws/students.csv")
/**
* flatMap算子:将RDD中的数据一条一条的取出传递给后面的函数,
* 函数的返回值必须是一个集合。最后会将集合展开构成一个新的RDD
*/
//扁平化
val value: RDD[String] = stuRDD.flatMap((stu: String) => {
stu.split(",")
})
value.foreach(println)//结果是所有信息都是换行的1.4.4 sample
1.抽取RDD的部分
2.语法:
xxx.sample(withReplacement = true, 0-1的小数)
//创建spark环境
val conf = new SparkConf()
//确定运行模式
conf.setMaster("local")
//给任务取名字
conf.setAppName("sample算子演示")
//创建对象
val context: SparkContext = new SparkContext(conf)
//读取文件
val stuRDD: RDD[String] = context.textFile("spark/data/ws/students.csv")
/**
* sample算子:从前一个RDD的数据中抽样一部分数据
* 抽取的比例不是正好对应的,在抽取的比例上下浮动 比如1000条抽取10% 抽取的结果在100条左右
*/
//withReplacement: Boolean, fraction: Double,
val sampleRDD: RDD[String] = stuRDD.sample(withReplacement = true, 0.1)
sampleRDD.foreach(println)1.4.5 groupBy
1.按照指定的字段进行分组,返回的是一个键是分组字段,值是一个存放原本数据的迭代器的键值对 返回的是kv格式的RDD
2.key: 是分组字段
value: 是spark中的迭代器
迭代器中的数据,不是完全被加载到内存中计算,迭代器只能迭代一次
groupBy会产生shuffle
//创建spark环境
val conf = new SparkConf()
//确定运行模式
conf.setMaster("local")
//给任务取名字
conf.setAppName("groupBy算子演示")
//创建对象
val context: SparkContext = new SparkContext(conf)
//读取文件
val stuRDD: RDD[String] = context.textFile("spark/data/ws/students.csv")
val splitRDD: RDD[Array[String]] = stuRDD.map((stu: String) => {
stu.split(",")
})
//求出每个班级的评价年龄
//使用匹配模式
//1、先取出班级和年龄
val clazzWithAgeRDD: RDD[(String, Int)] = splitRDD.map {
case Array(_, _, age: String, _, clazz: String) => (clazz, age.toInt)
}
//2、按照班级分组
/**
* groupBy:按照指定的字段进行分组,返回的是一个键是分组字段,
* 值是一个存放原本数据的迭代器的键值对 返回的是kv格式的RDD
*
* key: 是分组字段
* value: 是spark中的迭代器
* 迭代器中的数据,不是完全被加载到内存中计算,迭代器只能迭代一次
*
* groupBy会产生shuffle
*/
val kvRDD: RDD[(String, Iterable[(String, Int)])] = clazzWithAgeRDD.groupBy((str: (String, Int)) => {
str._1
})
//简写groupBy
// val kvRDD: RDD[(String, Iterable[(String, Int)])] = clazzWithAgeRDD.groupBy((_._1))
//(理科二班,CompactBuffer((理科二班,21), (理科二班,23), (理科二班,21), (理科二班,23)
val clazzAvgAgeRDD: RDD[(String, Double)] = kvRDD.map((kv: (String, Iterable[(String, Int)])) => {
val allAge: Iterable[Int] = kv._2.map((kv: (String, Int)) => {
kv._2
})
(kv._1, allAge.sum.toDouble / allAge.size)
})
clazzAvgAgeRDD.foreach(println)1.4.6 groupByKey
1. groupByKey: 按照键进行分组,将value值构成迭代器返回
2.将来你在spark中看到RDD[(xx, xxx)] 这样的RDD就是kv键值对类型的RDD
3.只有kv类型键值对RDD才可以调用groupByKey算子
4.与groupBy的区别:
数据格式:groupBy不用考虑数据格式,而groupByKey必须是kv(键值对)数据格式。
分组规则:groupBy需要指定分组规则,即根据某个或某些字段进行分组;而groupByKey则是根据key对value进行分组。
返回值类型:groupBy是将整条数据放在集合中,即它会将数据集按照指定的规则划分成若干个小区域,并将这些小区域(包含整个数据行)作为集合返回;而groupByKey只是将具有相同key的value放在集合中,即它会把RDD的类型由RDD[(Key, Value)]转换为RDD[(Key, Value集合)]。
性能:groupByKey的性能更好,执行速度更快,因为groupByKey相比较与groupBy算子来说,shuffle所需要的数据量较少
//创建spark环境
val conf = new SparkConf()
//确定运行模式
conf.setMaster("local")
//给任务取名字
conf.setAppName("groupByKey算子演示")
//创建对象
val context: SparkContext = new SparkContext(conf)
//读取文件
val stuRDD: RDD[String] = context.textFile("spark/data/ws/students.csv")
val splitRDD: RDD[Array[String]] = stuRDD.map((stu: String) => {
stu.split(",")
})
//需求:求出每个班级平均年龄
//使用模式匹配的方式取出班级和年龄
val clazzWithAgeRDD: RDD[(String, Int)] = splitRDD.map {
case Array(_, _, age: String, _, clazz: String) => (clazz, age.toInt)
}
/**
* groupByKey: 按照键进行分组,将value值构成迭代器返回
* 将来你在spark中看到RDD[(xx, xxx)] 这样的RDD就是kv键值对类型的RDD
* 只有kv类型键值对RDD才可以调用groupByKey算子
*
*/
val kvRDD: RDD[(String, Iterable[Int])] = clazzWithAgeRDD.groupByKey()
//(理科六班,CompactBuffer(22, 22, 23, 22, 21, 24, 21, 21, 22))
val clazzAvgAgeRDD: RDD[(String, Double)] = kvRDD.map((kv: (String, Iterable[(Int)])) => {
(kv._1,kv._2.sum.toDouble/kv._2.size)
})
clazzAvgAgeRDD.foreach(println)1.4.7 reduceByKey
1.利用reduceByKey实现:按照键key对value值直接进行聚合,需要传入聚合的方式
2.reduceByKey算子也是只有kv类型的RDD才能调用
3.与groupByKey的区别
-
功能:
- reduceByKey:该函数用于对具有相同键的值进行聚合操作。它会将具有相同键的值按照指定的合并函数进行迭代和聚合,最终生成一个新的RDD,其中每个键都是唯一的,与每个键相关联的值是经过合并操作后的结果。
- groupByKey:该函数仅根据键对RDD中的元素进行分组,不执行任何聚合操作。它只是将具有相同键的元素放在一个组中,形成一个包含键和其对应值的迭代器。因此,groupByKey的结果是一个新的RDD,其中每个键都与一个迭代器相关联,迭代器包含了与该键关联的所有值。
-
结果:
- reduceByKey:返回一个新的RDD,其中每个键都是唯一的,与每个键相关联的值是经过合并操作后的结果。
- groupByKey:返回一个新的RDD,其中每个键都与一个迭代器相关联,迭代器包含了与该键关联的所有值。
-
性能:
- reduceByKey:在某些情况下可能更高效,因为它可以在分布式计算中在map阶段进行一些本地聚合,从而减少数据传输。
- groupByKey:可能导致数据移动较多,因为它只是对键进行分组,而不进行本地聚合。因此,在处理大数据集时,groupByKey可能会导致更高的网络传输成本和更长的处理时间。
4.以后遇见key相同,value相加直接用reduceByKey
xxx.reduceByKey((x:Int,y:Int)=>x+y)
//创建spark环境
val conf = new SparkConf()
//确定运行模式
conf.setMaster("local")
//给任务取名字
conf.setAppName("reduceByKey算子演示")
//创建对象
val context: SparkContext = new SparkContext(conf)
//读取文件
val stuRDD: RDD[String] = context.textFile("spark/data/ws/students.csv")
val splitRDD: RDD[Array[String]] = stuRDD.map((stu: String) => {
stu.split(",")
})
//求每个班级的人数
//1、将每个元素变成(clazz,1)
val mapRDD: RDD[(String, Int)] = splitRDD.map {
case Array(_, _, _, _, clazz: String) => (clazz, 1)
}
/**
* 利用reduceByKey实现:按照键key对value值直接进行聚合,需要传入聚合的方式
* reduceByKey算子也是只有kv类型的RDD才能调用
*/
//聚合
val clazzSumPersonRDD: RDD[(String, Int)] = mapRDD.reduceByKey((x: Int, y: Int) => x + y)
clazzSumPersonRDD.foreach(println)1.4.8 union
1.上下合并两个RDD,前提是两个RDD中的数据类型要一致,合并后不会对结果进行去重
注:这里的合并只是逻辑层面上的合并,物理层面其实是没有合并
val conf = new SparkConf()
conf.setMaster("local")
conf.setAppName("Union算子演示")
val context = new SparkContext(conf)
//====================================================
val w1RDD: RDD[String] = context.textFile("spark/data/ws/w1.txt") // 1
val w2RDD: RDD[String] = context.textFile("spark/data/ws/w2.txt") // 1
/**
* union:上下合并两个RDD,前提是两个RDD中的数据类型要一致,合并后不会对结果进行去重
*
* 注:这里的合并只是逻辑层面上的合并,物理层面其实是没有合并
*/
val unionRDD: RDD[String] = w1RDD.union(w2RDD)
unionRDD.foreach(println)1.4.9 join
1.内连接,左连接,右连接,全连接
2.连接的2个RDD里面数据类型必须一样
val conf = new SparkConf()
conf.setMaster("local")
conf.setAppName("Join算子演示")
val context = new SparkContext(conf)
//====================================================
//两个kv类型的RDD之间的关联
//通过scala中的集合构建RDD,通过context中的parallelize方法将集合变成RDD
val rdd1: RDD[(String, String)] = context.parallelize(
List(
"1001" -> "hjx",
"1002" -> "hdx",
"1003" -> "hfx",
"1004" -> "hhx",
"1005" -> "hkx",
"1007" -> "hbx"
)
)
val rdd2: RDD[(String, String)] = context.parallelize(
List(
("1001", "崩坏"),
("1002", "原神"),
("1003", "王者"),
("1004", "修仙"),
("1005", "学习"),
("1006", "敲代码")
)
)
/**
* 内连接:join
* 左连接:leftJoin
* 右连接:rightJoin
* 全连接:fullJoin
*/
//join
// val joinRDD: RDD[(String, (String, String))] = rdd1.join(rdd2)
// joinRDD.foreach(println)//(1005,(hkx,学习))
//leftJoin
// val leftRDD: RDD[(String, (String, Option[String]))] = rdd1.leftOuterJoin(rdd2)
// val leftRDD1: RDD[(String, String, String)] = leftRDD.map {
// case (id: String, (name: String, Some(like))) => (id, name, like)
// case (id: String, (name: String, None)) => (id, name, "没有爱好")
// }
// leftRDD1.foreach(println)
//rightJoin
// val rightRDD: RDD[(String, (Option[String], String))] = rdd1.rightOuterJoin(rdd2)
// val rightRDD1: RDD[(String, String, String)] = rightRDD.map {
// case (id: String, (Some(name), like: String)) => (id, name, like)
// case (id: String, (None, like: String)) => (id, "查无此人", like)
// }
// rightRDD1.foreach(println)
//fullJoin
val fullJoin: RDD[(String, (Option[String], Option[String]))] = rdd1.fullOuterJoin(rdd2)
val fullJoin1: RDD[(String, String, String)] = fullJoin.map {
case (id: String, (Some(name), Some(like))) => (id, name, like)
case (id: String, (None, Some(like))) => (id, "查无此人", like)
case (id: String, (Some(name), None)) => (id, name, "没有爱好")
}
fullJoin1.foreach(println)1.4.10 sortBy
1.返回的也是一个RDD
//创建spark环境
val conf = new SparkConf()
//明确运行模式
conf.setMaster("local")
//给任务取名字
conf.setAppName("统计总分年级排名前10的学生的各科分数")
//创建对象
val context: SparkContext = new SparkContext(conf)
//需求:统计总分年级排名前10的学生的各科分数
//1、读取文件
val mapRDD: RDD[(String, String, Int)] = context.textFile("spark/data/ws/score.txt")
.map((s: String) => {
s.split(",")
}) //切分数据
.filter((array: Array[String]) => {
array.length == 3
})//过滤数据
.map {
case Array(sid: String, subject_id, score: String) => (sid, subject_id, score.toInt)
}//筛选数据
//2、计算每个学生的总分
val mapRDD1: RDD[(String, Int)] = mapRDD.map {
//RDD中的模式匹配,case后面不需要加类型,直接是RDD小括号中的数据类型匹配
case (sid: String, _, score: Int) => (sid, score)
}
//以后遇见key相同,value相加,直接用reduceByKey。reduceByKey((x: Int, y: Int) => x + y
val reduceRDD: RDD[(String, Int)] = mapRDD1.reduceByKey((x: Int, y: Int) => x + y)
//3、按照总分排序
val sortByRDD: Array[(String, Int)] = reduceRDD.sortBy((kv: (String, Int)) => {
-kv._2
}).take(10)
//4、求各科成绩
//拿出学号
val ids: Array[String] = sortByRDD.map((kv: (String, Int)) => {
kv._1
})
val clazzScoreTop10RDD: RDD[(String, String, Int)] = mapRDD.filter {
case (sid: String, _, _) => ids.contains(sid)
}
clazzScoreTop10RDD.foreach(println)1.4.11 mapValues
1. mapValues算子:也是作用在kv类型的RDD上
2.主要的作用键不变,处理值
//需求:统计总分年级排名前10的学生的各科分数
//1、读取文件
val mapRDD: RDD[(String, String, Int)] = context.textFile("spark/data/ws/score.txt")
.map((s: String) => {
s.split(",")
}) //切分数据
.filter((array: Array[String]) => {
array.length == 3
})//过滤数据
.map {
case Array(sid: String, subject_id, score: String) => (sid, subject_id, score.toInt)
}//筛选数据
//2、计算每个学生的总分
val mapRDD1: RDD[(String, Int)] = mapRDD.map {
//RDD中的模式匹配,case后面不需要加类型,直接是RDD小括号中的数据类型匹配
case (sid: String, _, score: Int) => (sid, score)
}
//以后遇见key相同,value相加,直接用reduceByKey。reduceByKey((x: Int, y: Int) => x + y
val reduceRDD: RDD[(String, Int)] = mapRDD1.reduceByKey((x: Int, y: Int) => x + y)
/**
* mapValues算子:也是作用在kv类型的RDD上
* 主要的作用键不变,处理值
*/
val mapValuesRDD: RDD[(String, Int)] = reduceRDD.mapValues(_ + 1000)
//等同于
val mapValues1: RDD[(String, Int)] = reduceRDD.map((kv: (String, Int)) => {
(kv._1, kv._2 + 1000)
})1.4.12 mapPartitions
1.mapPartitions与mapPartitionsWithIndex的用法
mapPartitions:不用指定分区,里面传入的是迭代器,迭代器存储的是每个分区的数据
mapPartitionsWithIndex:指定分区,
//创建spark环境
val conf = new SparkConf()
//明确运行模式
conf.setMaster("local")
//给任务取名字
conf.setAppName("mapPartition算子的演示")
//创建对象
val context: SparkContext = new SparkContext(conf)
val scoreRDD: RDD[String] = context.textFile("spark/data/ws/*") // 读取数据文件
//打印分区
println(scoreRDD.getNumPartitions)
//
// val mapPartition: RDD[String] = scoreRDD.mapPartitions((itr: Iterator[String]) => {
// itr.flatMap((s: String) => {
// s.split("\\|")
// })
// })
// mapPartition.foreach(println)
// scoreRDD.mapPartitionsWithIndex{
// case (index:Int,itr:Iterator[String])=>
// println(s"当成分区${index}")
// itr.flatMap((s:String)=>{
// s.split("\\|")
// })
// }.foreach(println)
val mapPartitionRDD: RDD[String] = scoreRDD.mapPartitionsWithIndex((i: Int, itr: Iterator[String]) => {
println(s"分区是${i}")
itr.flatMap(_.split("\\|"))
})
mapPartitionRDD.foreach(println)1.4.13 行动算子
1.一个行动算子,执行一次任务。没有行动算子,RDD没有结果
2.执行顺序:除去算子的操作先执行,再执行RDD里面的操作
3.collcet:将RDD变成scala中的集合
//创建spark环境
val conf = new SparkConf()
//明确运行模式
conf.setMaster("local")
//给任务取名字
conf.setAppName("action算子")
//创建对象
val context: SparkContext = new SparkContext(conf)
//读取文件
val stuRDD: RDD[String] = context.textFile("spark/data/ws/students.csv")
println("hhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhh")
//
val studentsRDD: RDD[(String, String, String, String, String)] = stuRDD.map(_.split(","))
.map {
case Array(id: String, name: String, age: String, gender: String, clazz: String) =>
println("jjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjj")
(id, name, age, gender, clazz)
}
println("xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx")
studentsRDD.foreach(println)二 spark流程
2.1 任务流程
1.读文件
2.切分/筛选
3.筛选
4.分组聚合
5.筛选
6.写入文件
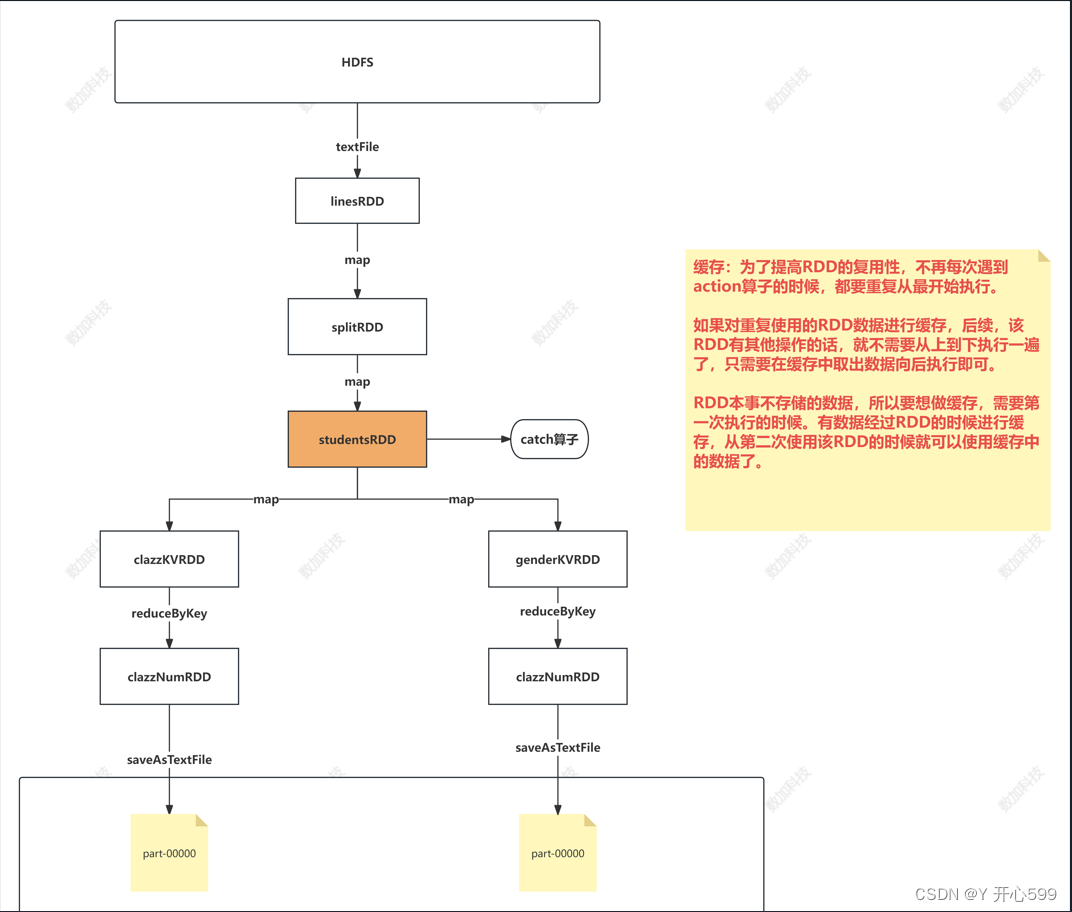
2.2 缓存
2.2.1 catch算子
1.默认将数据缓存在内存中,程序结束,缓存数据没了
xxxRDD.catch()
2.2.2 persist算子
1.默认将数据缓存在内存中,catch的实际就是用的persist,程序结束,缓存数据没了
2.可以设置级别
xxxRDD.persist(StorageLevel.级别)
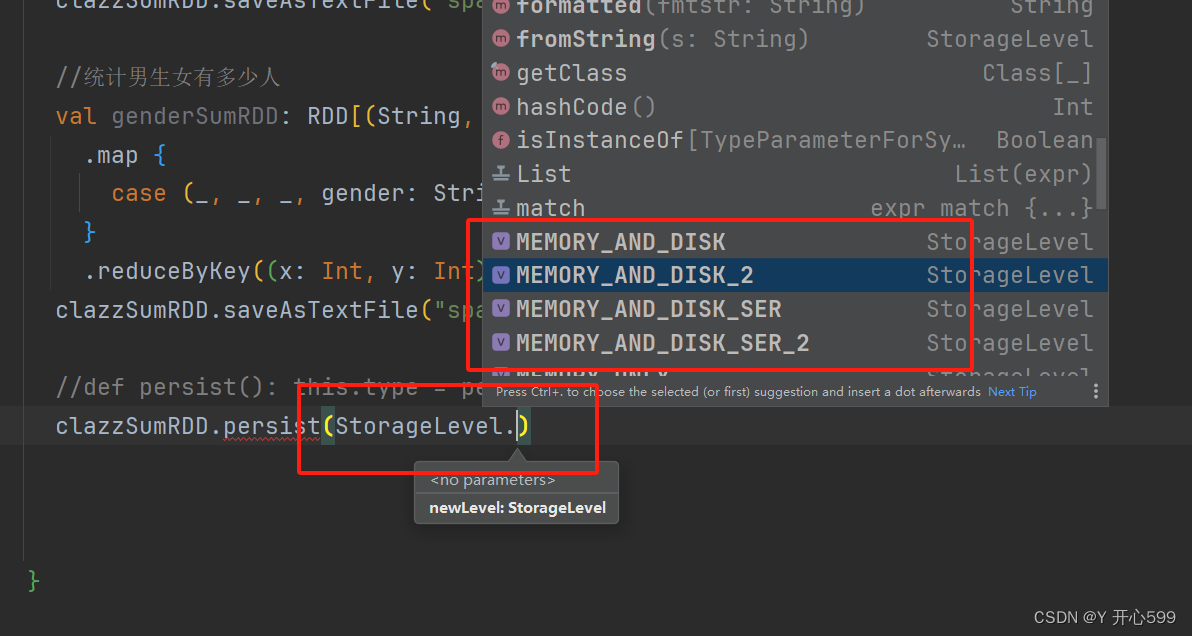
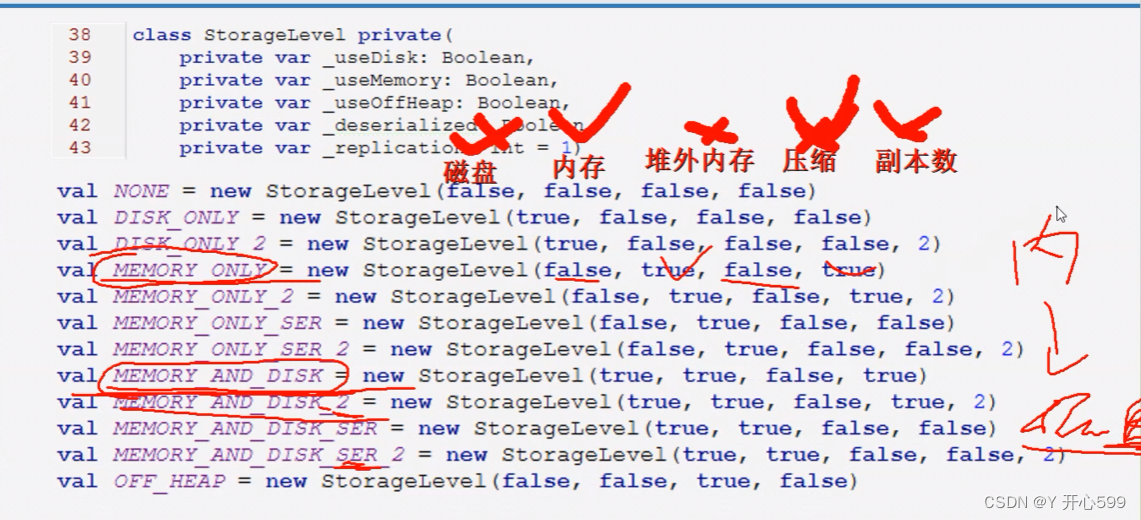
2.2.3 checkPoint
1.可以将RDD运行时的数据永久持久化在HDFS上,这个方案叫做checkpoint,需要在spark环境中设置checkpoint的路径
2.这个不能写在一个程序的末尾,要不然还是没有数据
//创建spark环境
val conf = new SparkConf()
//明确运行模式
conf.setMaster("local")
//给任务取名字
conf.setAppName("persist")
//创建对象
val context: SparkContext = new SparkContext(conf)
//设置缓冲路径
context.setCheckpointDir("spark/data/checkpoint")
//读取文件
val stuRDD: RDD[String] = context.textFile("spark/data/ws/students.csv")
//切分,筛选元素
val studentsRDD: RDD[(String, String, String, String, String)] = stuRDD.map(_.split(","))
.map {
case Array(id: String, name: String, age: String, gender: String, clazz: String) =>
(id, name, age, gender, clazz)
}
//统计每个班的人数
studentsRDD.checkpoint()
val clazzSumRDD: RDD[(String, Int)] = studentsRDD
.map {
case (_, _, _, _, clazz: String) => (clazz, 1)
}
.reduceByKey((x: Int, y: Int) => x + y) //可以简写为(_+_)
clazzSumRDD.saveAsTextFile("spark/data/clazz_num")
//统计男生女有多少人
val genderSumRDD: RDD[(String, Int)] = studentsRDD
.map {
case (_, _, _, gender: String, _) => (gender, 1)
}
.reduceByKey((x: Int, y: Int) => x + y) //可以简写为(_+_)
clazzSumRDD.saveAsTextFile("spark/data/gender_num")
//def persist(): this.type = persist(StorageLevel.MEMORY_ONLY)
// clazzSumRDD.persist(StorageLevel.MEMORY_ONLY)三 spark部署环境
3.1 Standalone
3.1.1 解压
tar -zxvf 文件名 -C 路径
3.1.2 配置文件
1.环境变量
/etc/profile
2.复制一份模板,配置spark-env.sh文件
export SPARK_MASTER_IP=master
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_CORES=2
export SPARK_WORKER_INSTANCES=1
export SPARK_WORKER_MEMORY=2g
export JAVA_HOME=/usr/local/soft/jdk1.8.0_1713.复制一份模板配置workers文件
node1
node23.1.3 复制
1复制一份给其他节点
3.1.4启动
1.本地集群模式启动进入sbin目录下启动
./start-all.sh
看是否启动成功,输入网址master:8080,有页面即是成功。
3.1.5 提交spark任务
1.client模式提交:
进入spark/example/jars目录下输入
spark-submit --class org.apache.spark.examples.SparkPi --master spark://master:7077 --executor-memory 512m --total-executor-cores 1 spark-examples_2.12-3.1.3.jar 100
spark-examples_2.12-3.1.3.jar:是jars下的jar名
spark-submit:命令的名字
class org.apache.spark.examples.SparkPi:类名
2.cluster模式
进入spark/example/jars目录下输入
spark-submit --class org.apache.spark.examples.SparkPi --master spark://master:7077 --executor-memory 512M --total-executor-cores 1 --deploy-mode cluster spark-examples_2.12-3.1.3.jar 100
3.1.6 实例
//创建spark环境
val conf = new SparkConf()
//提交Linux运行不需要明确运行模式
// conf.setMaster("local")
//给任务取个名字
conf.setAppName("Standalone运行模式")
//创建对象
val sparkContext = new SparkContext(conf)
//使用对象中的parallelize方法将Scala中的集合变成RDD
val arrayRDD: RDD[String] = sparkContext.parallelize(
(
List(
"java,hello,world",
"hello,scala,spark",
"java,hello,spark")
)
)
val flatMapRDD: RDD[String] = arrayRDD.flatMap(_.split(","))
val mapRDD: RDD[(String, Int)] = flatMapRDD.map((s: String) => (s, 1))
val reduceRDD: RDD[(String, Int)] = mapRDD.reduceByKey(_ + _)
reduceRDD.foreach(println)
/**
* 将项目打包放到spark集群中使用standalone模式运行
* standalone client
* spark-submit --class com.shujia.core.Demo17SparkStandaloneSubmit --master spark://master:7077 --executor-memory 512m --total-executor-cores 1 spark-1.0.jar 100
*
* standalone cluster
* spark-submit --class com.shujia.core.Demo17SparkStandaloneSubmit --master spark://master:7077 --executor-memory 512m --total-executor-cores 1 --deploy-mode cluster spark-1.0.jar 100
*
*/1.将这个打包,放到Linux中
2.client模式提交:
spark-submit --class com.shujia.core.Demo17SparkStandaloneSubmit --master spark://master:7077 --executor-memory 512m --total-executor-cores 1 spark-1.0.jar 100
这里就能看见结果
3.cluster模式:
先把jar包复制给子节点,再提交任务
spark-submit --class com.shujia.core.Demo17SparkStandaloneSubmit --master spark://master:7077 --executor-memory 512m --total-executor-cores 1 --deploy-mode cluster spark-1.0.jar 100
结果跟上面的看法一样
3.2 YARN
3.2.1配置文件
1修改spark-env.sh文件
export HADOOP_CONF_DIR=/usr/local/soft/hadoop-3.1.1/etc/hadoop2.修改yarn-site.xml
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>(在master输入hadoop classpath,将那段话复制过来,不要有空格)</value>
</property>
3.同步到其他节点
3.2.2 提交任务
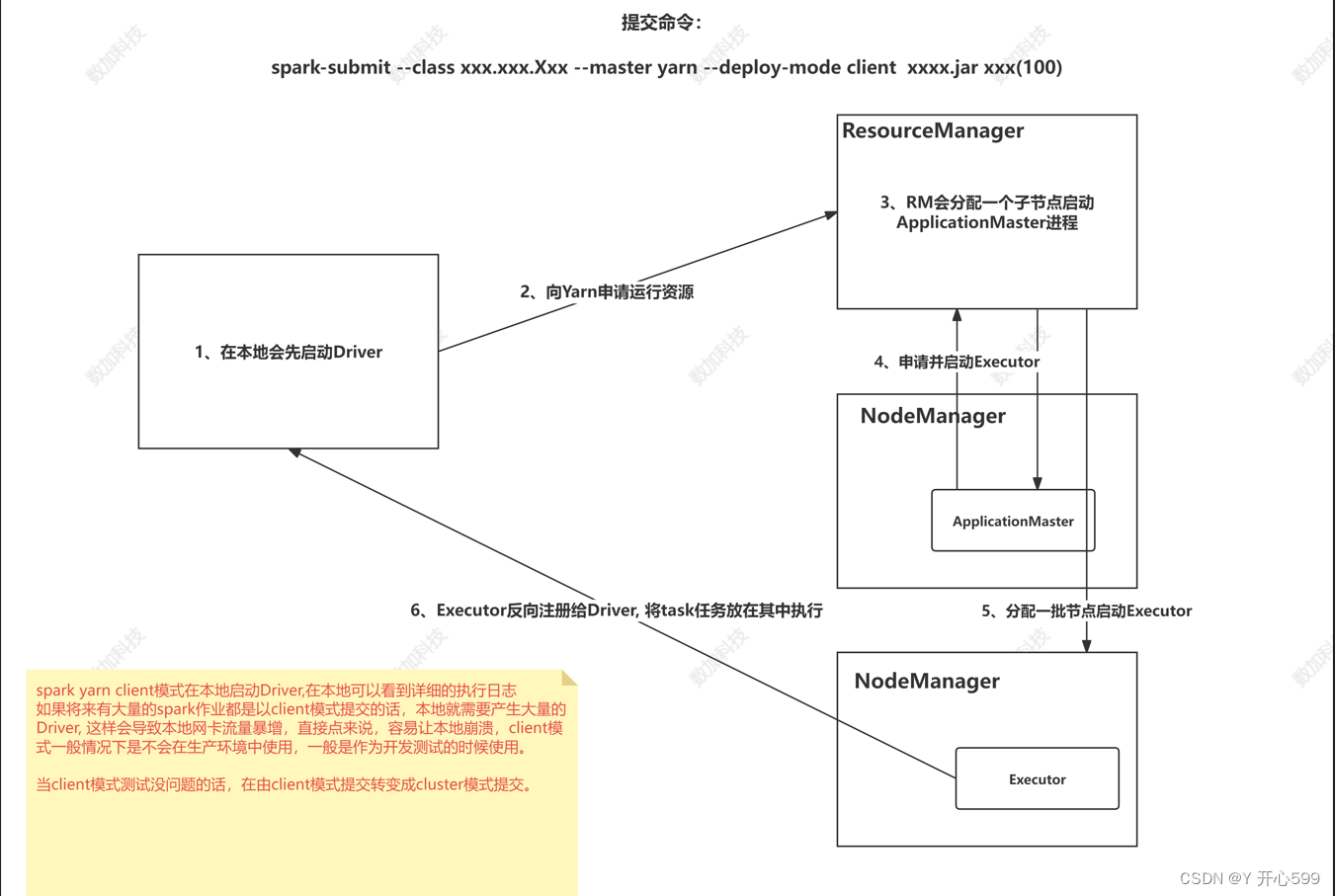
1.yarn-client提交
spark-submit --master yarn --deploy-mode client --class org.apache.spark.examples.SparkPi spark-examples_2.12-3.1.3.jar 100
spark-submit:命令名字
deploy-mode client:啥类型提交
class org.apache.spark.examples.SparkPi:类名
spark-examples_2.12-3.1.3.jar 100:jar包名
运行大概流程
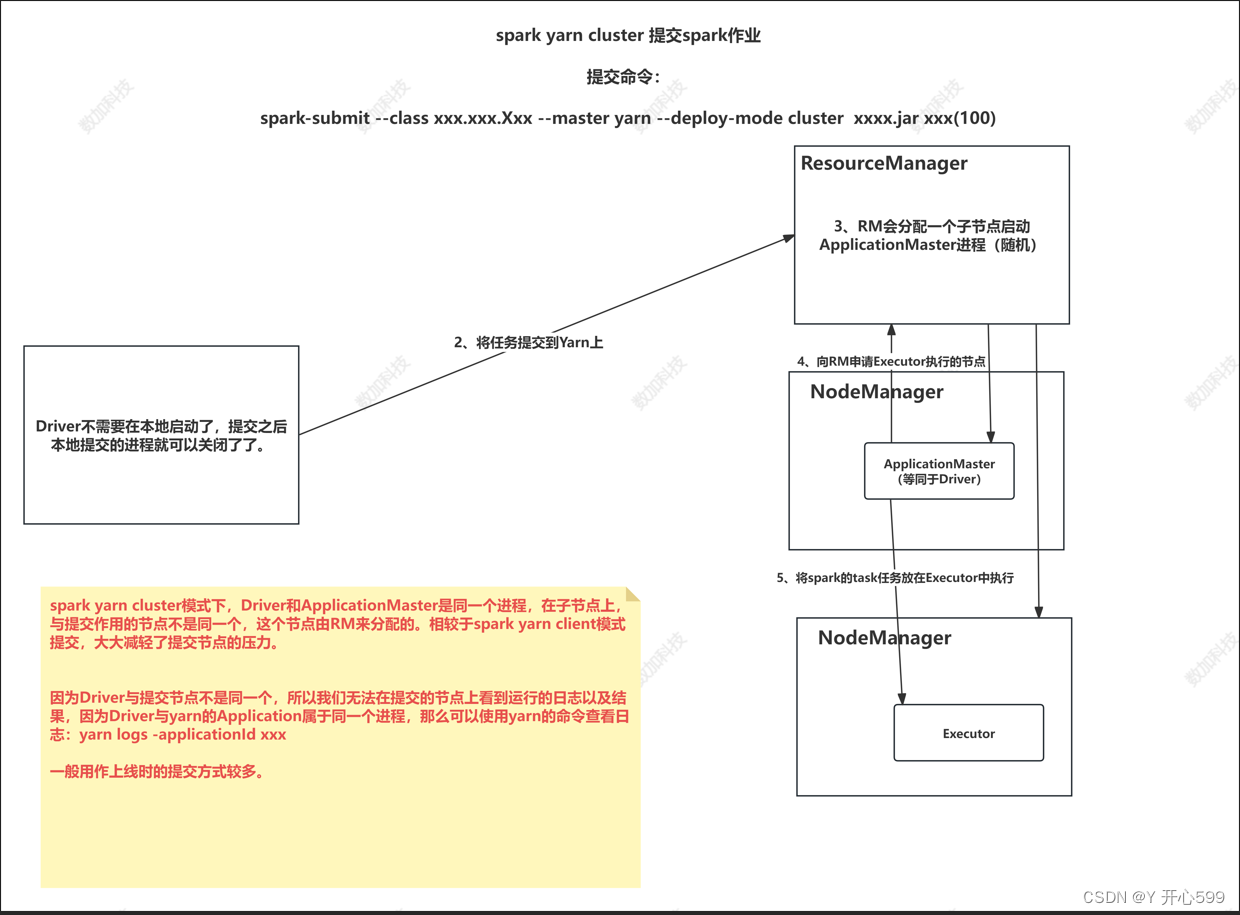
2.yarn-cluster提交
spark-submit --master yarn --deploy-mode cluster --class org.apache.spark.examples.SparkPi spark-examples_2.12-3.1.3.jar 100
查看结果:yarn logs -applicationId xxxxxxxxxx
 四 其他知识
四 其他知识
4.1 资源调度与任务调度
所说的基于spark-yarn client提交任务
4.1.1 资源调度
1.本地启动Driver
2.向yarn(ResourceManager)申请资源 ,提交spark Application
3.RM接收spark Application过后,会分配一个子节点启动ApplicationMaster进程
4.ApplicationMaster向RM申请节点并启动Executor
5.Executor反向注册给Driver
4.1.2 任务调度
1.当代码遇见一个action算子,开始进行任务调度
2.Driver根据RDD之间的依赖关系将Application形成一个DAG(有向无环图)。
4.将DAG发送给DAG Scheduler
3.DAG Scheduler会根据产生的shuffle划分窄宽依赖,通过宽依赖划分Stage
4.DAG Scheduler将Stage包装成taskset发送给Task Scheduler(stage里面有很多并行的task,taskset是每个stage里面的并行task封装的)
5.Task Scheduler拿到了task后发送到Executor中的线程池执行
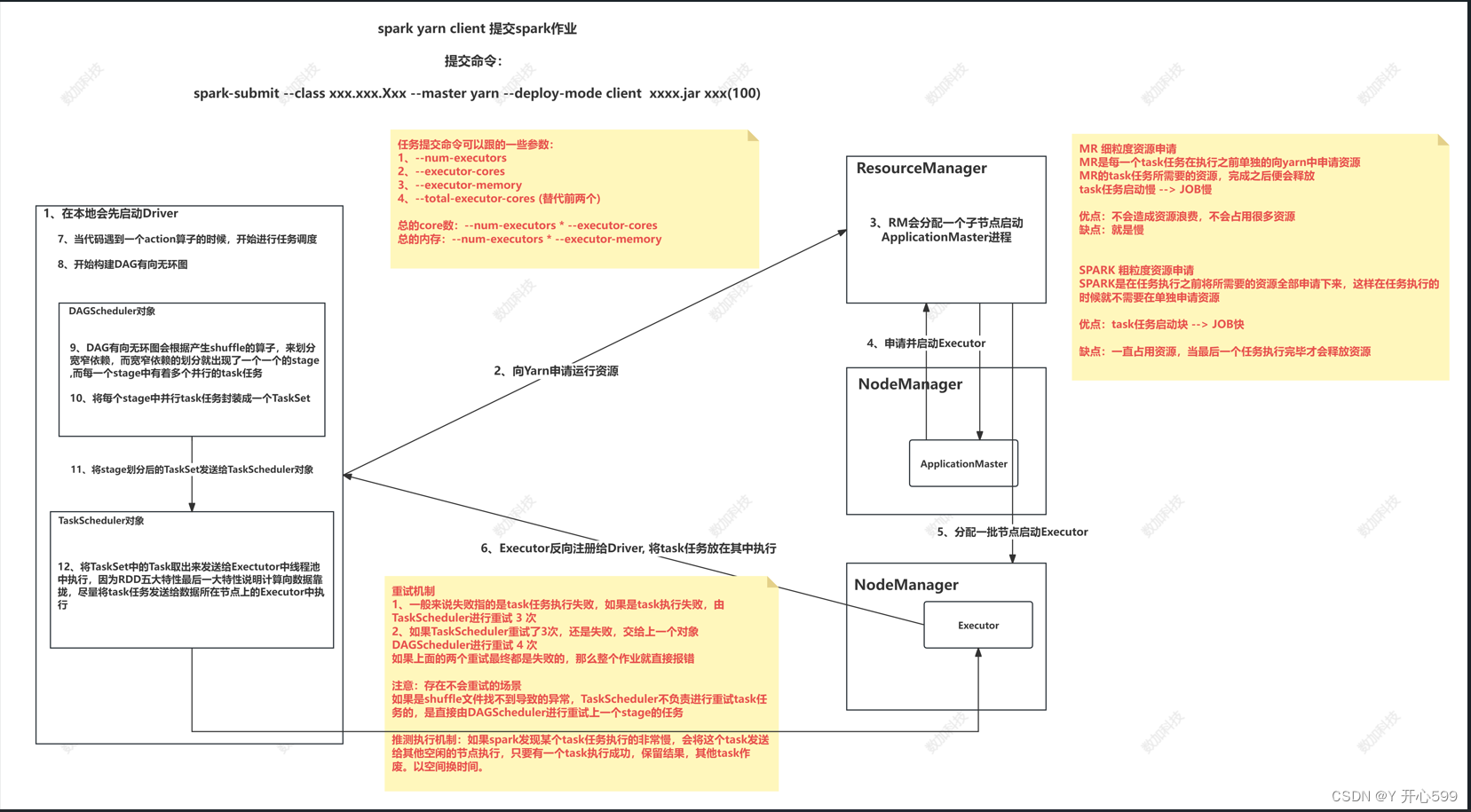
4.1.3 重试机制
1.如果task执行失败taskscheduler会重试3次,如果还失败,DAGscheduler会重试4次
2.存在不会重试的场景
如果是因为shuffle过程中文件找不到的异常,taskscheduler不负责重试task,而是由DAGscheduler重试上一个stage
4.1.4推行执行
1.如果有的task执行很慢,taskscheduler会在发生一个一摸一样的task到其它节点中执行,让多个task竟争,谁先执行完成以谁的结果为准
4.2 累加器
1.RDD内部的改变不会影响RDD外面的计算
val conf = new SparkConf()
conf.setMaster("local")
conf.setAppName("累加器演示")
val context = new SparkContext(conf)
//====================================================
val studentRDD: RDD[String] = context.textFile("spark/data/ws/students.csv")
var count = 0
studentRDD.foreach((line: String) => {
count += 1
println("-------------------------")
println(count)
println("-------------------------")
})
println(s"count的值为:${count}")//0上述这个程序RDD里面的count输出是1000,而RDD外面的count还是0
2.实现累加器(触发作业执行之后加的)
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local")
conf.setAppName("累加器演示")
val context = new SparkContext(conf)
//====================================================
val studentRDD: RDD[String] = context.textFile("spark/data/ws/students.csv")
// var count = 0
// studentRDD.foreach((line: String) => {
// count += 1
// println("-------------------------")
// println(count)
// println("-------------------------")
// })
// println(s"count的值为:${count}")//0
/**
* 累加器
*
* 由SparkContext来创建
* 注意:
* 1、因为累加器的执行实在RDD中执行的,而RDD是在Executor中执行的,而要想在Executor中执行就得有一个action算子触发任务调度
* 2、sparkRDD中无法使用其他的RDD
* 3、SparkContext无法在RDD内部使用,因为SparkContext对象无法进行序列化,不能够通过网络发送到Executor中
*/
val longAccumulator: LongAccumulator = context.longAccumulator
studentRDD.foreach((line:String)=>{
longAccumulator.add(1)
})
println(longAccumulator.value)4.3 广播变量
1.避免了每次Task任务拉取都要附带一个副本,拉取的速度变快了,执行速度也就变快了
2.未使用广播变量
//创建spark环境
val conf = new SparkConf()
//明确模式
conf.setMaster("local")
//给任务取个名字
conf.setAppName("广播变量")
//创建对象
val context = new SparkContext(conf)
//以scala的方式读取students.csv文件并进行相关操作
val stuMap: Map[String, String] = Source.fromFile("spark/data/ws/students.csv")
.getLines()
.toList
.map((line: String) => {
val lines: Array[String] = line.split(",")
(lines(0), lines.mkString(","))
}).toMap
//使用spark的形式读取文件
val scoreRDD: RDD[String] = context.textFile("spark/data/ws/score.txt")
/**
* 将Spark读取的分数RDD与外部变量学生Map集合进行关联
* 循环遍历scoresRDD,将学号一样的学生信息关联起来
*/
val idWithInfosRDD: RDD[(String, String)] = scoreRDD.map((score: String) => {
val id: String = score.split(",")(0)
val infos: String = stuMap.getOrElse(id, "查无此人")
(id, infos)
})
idWithInfosRDD.foreach(println)3.使用广播变量
def main(args: Array[String]): Unit = {
//创建spark环境
val conf = new SparkConf()
//明确模式
conf.setMaster("local")
//给任务取个名字
conf.setAppName("广播变量")
//创建对象
val context = new SparkContext(conf)
//以scala的方式读取students.csv文件并进行相关操作
val stuMap: Map[String, String] = Source.fromFile("spark/data/ws/students.csv")
.getLines()
.toList
.map((line: String) => {
val lines: Array[String] = line.split(",")
(lines(0), lines.mkString(","))
}).toMap
//使用spark的形式读取文件
val scoreRDD: RDD[String] = context.textFile("spark/data/ws/score.txt")
/**
* 将Spark读取的分数RDD与外部变量学生Map集合进行关联
* 循环遍历scoresRDD,将学号一样的学生信息关联起来
*/
// val idWithInfosRDD: RDD[(String, String)] = scoreRDD.map((score: String) => {
// val id: String = score.split(",")(0)
// val infos: String = stuMap.getOrElse(id, "查无此人")
// (id, infos)
// })
//创建广播变量
val stuBro: Broadcast[Map[String, String]] = context.broadcast(stuMap)
val value: RDD[(String, String)] = scoreRDD.map((score: String) => {
val id: String = score.split(",")(0)
val map: Map[String, String] = stuBro.value
val infos: String = map.getOrElse(id, "ddd")
(id, infos)
})
value.foreach(println)