LLM 大模型学习必知必会系列(十一):大模型自动评估理论和实战以及大模型评估框架详解
0.前言
大语言模型(LLM)评测是LLM开发和应用中的关键环节。目前评测方法可以分为人工评测和自动评测,其中,自动评测技术相比人工评测来讲,具有效率高、一致性好、可复现、鲁棒性好等特点,逐渐成为业界研究的重点。
模型的自动评测技术可以分为rule-based和model-based两大类:
-
rule-based方法:
-
benchmark以客观题为主,例如多选题,被测的LLM通过理解context/question,来指定最佳答案
-
解析LLM的response,与标准答案做对比
-
计算metric(accuracy、rouge、bleu等)
-
-
model-based方法:
-
裁判员模型(e.g. GPT-4、Claude、Expert Models/Reward models)
-
LLM Peer-examination
-

如何评估一个LLM
-
哪些维度?
-
语义理解(Understanding)
-
知识推理(Reasoning)
-
专业能力(e.g. coding、math)
-
应用能力(MedicalApps、AgentApps、AI-FOR-SCI …)
-
指令跟随(Instruction Following)
-
鲁棒性(Robustness)
-
偏见(Bias)
-
幻觉(Hallucinations)
-
安全性(Safety)
-

例:GPT-4 vs LLaMA2-7B能力维度对比评测
1. 自动评估方法
模型效果评估
- 基准和指标(Benchmarks & Metrics)
| 数据集 | 描述 | 评价指标 | 样例 |
|---|---|---|---|
| MMLU | MassiveMultitaskLanguageUnderstanding 一个多任务数据集,由各种学科的多项选择题组成。涵盖STEM、人文、社科等领域。包括57个子任务,包括初等数学、美国历史、计算机科学、法律等等。 | Accuracy | Question: In 2016, about how many people in the United States were homeless? A. 55,000 B. 550,000 C. 5,500,000 D. 55,000,000 Answer: B |
| TriviaQA | 阅读理解数据集,包含超过65万个问题-答案-证据三元组。其包括95K个问答对,由冷知识爱好者提供 + 独立收集的事实性文档撰写 | EM(ExactMatch) F1 (word-level) |  (问题-答案-证据文档) (问题-答案-证据文档) |
| MATH | 12500道数学题,每道包含step-by-step solution | Accuracy |  |
| HumanEval | HumanEval (Hand-Written Evaluation Set) 一个手写的问题解决数据集,要求根据给定的问题和代码模板,生成正确的代码片段。包含164个高质量的问题,涵盖五种编程语言:Python, C++, Java, Go, 和 JavaScript。 | pass@k | { “task_id”: “test/0”, “prompt”: “def return1():\n”, “canonical_solution”: " return 1", “test”: “def check(candidate):\n assert candidate() == 1”, “entry_point”: “return1” } |
- Rule-based自动评测
基本流程

- 根据数据集原始question来构建prompt
示例(few-shot)

示例:few-shot with CoT
# Examples in BBH
Evaluate the result of a random Boolean expression.
Q: not ( ( not not True ) ) is
A: Let's think step by step.
Remember that (i) expressions inside brackets are always evaluated first and that (ii) the order of operations from highest priority to lowest priority is "not", "and", "or", respectively.
We first simplify this expression "Z" as follows: "Z = not ( ( not not True ) ) = not ( ( A ) )" where "A = not not True".
Let's evaluate A: A = not not True = not (not True) = not False = True.
Plugging in A, we get: Z = not ( ( A ) ) = not ( ( True ) ) = not True = False. So the answer is False.
Q: True and False and not True and True is
A: Let's think step by step.
Remember that (i) expressions inside brackets are always evaluated first and that (ii) the order of operations from highest priority to lowest priority is "not", "and", "or", respectively.
We first simplify this expression "Z" as follows: "Z = True and False and not True and True = A and B" where "A = True and False" and "B = not True and True".
Let's evaluate A: A = True and False = False.
Let's evaluate B: B = not True and True = not (True and True) = not (True) = False.
Plugging in A and B, we get: Z = A and B = False and False = False. So the answer is False.
- 模型预测
Generate
# Demo -- model_genereate 直接生成response
def model_generate(query: str, infer_cfg: dict) -> str:
inputs = tokenizer.encode(query)
input_ids = inputs['input_ids']
...
# Process infer cfg (do_sample, top_k, top_p, temperature, special_tokens ...)
generation_config = process_cfg(args)
...
# Run inference
output_ids = model.generate(
input_ids=input_ids,
attention_mask=attention_mask,
generation_config=generation_config,
)
response = tokenizer.decode(output_ids, **decode_kwargs)
return response
Likelihood
#Demo -- model_call方式计算loglikelihood
# context + continuation 拼接,示例:
# Question: 法国的首都是哪里?
# Choices: A.北京 B.巴黎 C.汉堡 D.纽约
# pair-1: (ctx, cont) = (法国的首都是哪里?,A.北京)
# pair-2: (ctx, cont) = (法国的首都是哪里?,B.巴黎)
# pair-3: (ctx, cont) = (法国的首都是哪里?,C.汉堡)
# pair-4: (ctx, cont) = (法国的首都是哪里?,D.纽约)
# Logits -->
def loglikelihood(self, inputs: list, infer_cfg: dict = None) -> list:
# To predict one doc
doc_ele_pred = []
for ctx, continuation in inputs:
# ctx_enc shape: [context_tok_len] cont_enc shape: [continuation_tok_len]
ctx_enc, cont_enc = self._encode_pair(ctx, continuation)
inputs_tokens = torch.tensor(
(ctx_enc.tolist() + cont_enc.tolist())[-(self.max_length + 1):][:-1],
dtype=torch.long,
device=self.model.device).unsqueeze(0)
logits = self.model(inputs_tokens)[0]
logits = torch.nn.functional.log_softmax(logits.float(), dim=-1)
logits = logits[:, -len(cont_enc):, :]
cont_enc = cont_enc.unsqueeze(0).unsqueeze(-1)
logits = torch.gather(logits.cpu(), 2, cont_enc.cpu()).squeeze(-1)
choice_score = float(logits.sum())
doc_ele_pred.append(choice_score)
# e.g. [-2.3, 1.1, -12.9, -9.2], length=len(choices)
return doc_ele_pred
2.评价指标(Metrics)
-
WeightedAverageAccuracy 加权平均准确率
-
Perplexity 困惑度
-
Rouge (Recall-Oriented Understudy for Gisting Evaluation)
-
Bleu (Bilingual evaluation understudy)
-
ELO Rating System
-
PASS@K
2.1 Model-based自动评测

-
中心化评测
- 中心化评测模式下,裁判员模型只有一个,可靠性高,但容易收到裁判员模型的bias影响
-
去中心化评测
-
去中心化评测方式,要求模型之间做peer-examination
-
特点是公平性好,但计算量大,且鲁棒性不高
-
裁判员模型
-
GPT-4、Claude、Qwen-Max等 (产品APIs)
-
PandLM、Auto-J (tuned from LLM, like LLaMA)
-
Reward models (Ranking learning)
-
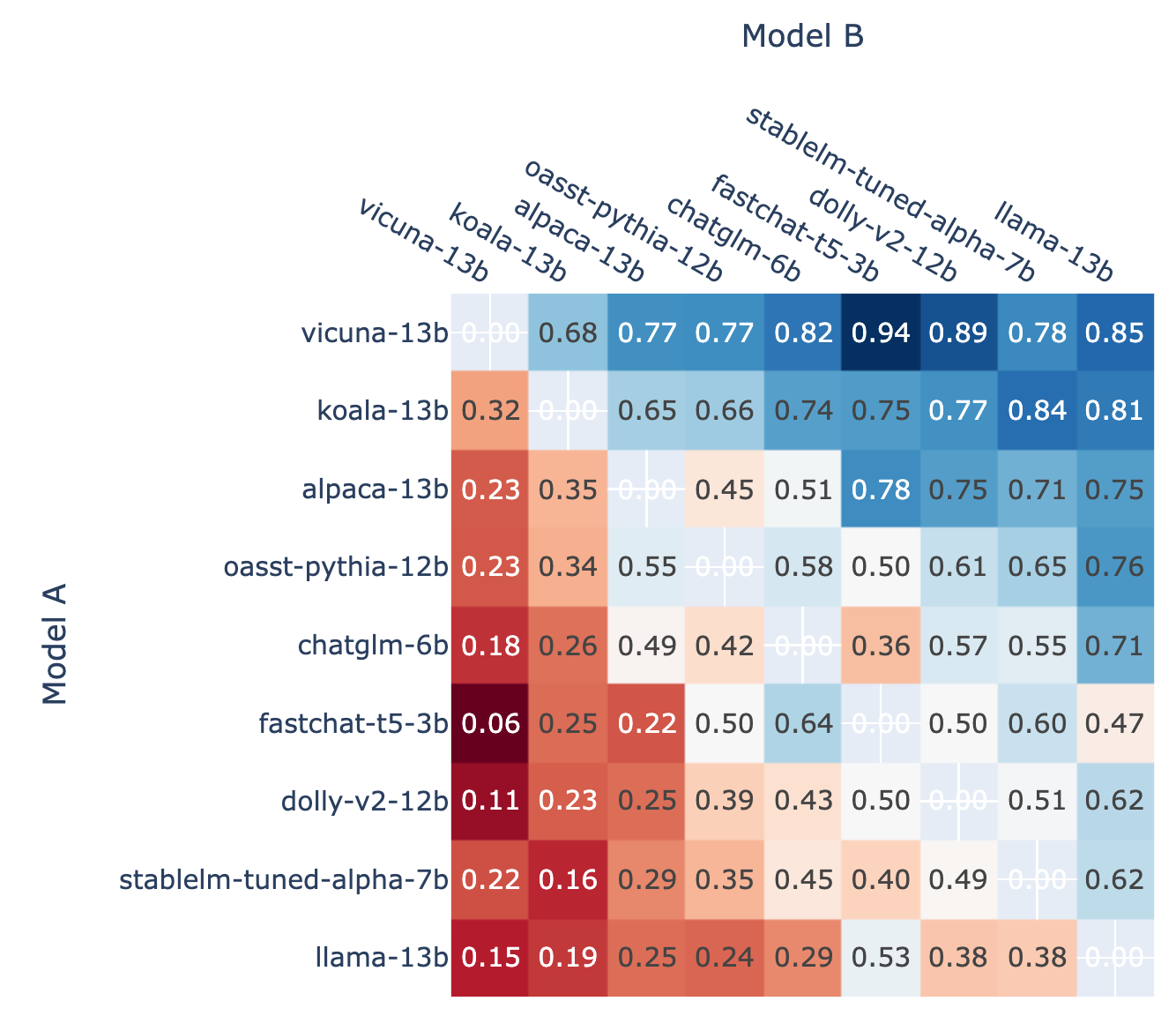
Chatbot Arena -竞技场模式
- (Battle count of each combination of models, from LMSYS)

- (Fraction of Model A wins for all non-tied A vs. B battles, from LMSYS)
-
LLM指令攻防
-
指令诱导 (诱导模型输出目标答案,from SuperCLUE)
-

-
有害指令注入 (将真实有害意图注入到prompt中, from SuperCLUE)
-

-
2.2 模型性能评估
model serving performance evaluation
| 指标名称 | 说明 |
|---|---|
| Time | 测试总时间(时间单位均为秒) |
| Expected number of requests | 期望发送的请求数,和prompt文件以及期望number有关 |
| concurrency | 并发数 |
| completed | 完成的请求数 |
| succeed | 成功请求数 |
| failed | 失败请求数 |
| qps | 平均qps |
| latency | 平均latency |
| time to first token | 平均首包延迟 |
| throughput | output tokens / seconds 平均每秒输出token数 |
| time per output token | 平均生成一个token需要的时间 总output_tokens/总时间 |
| package per request | 平均每个请求的包数 |
| time per package | 平均每包时间 |
| input tokens per request | 平均每个请求的输入token数 |
| output tokens per request | 平均每个请求输出token数 |
2.3 问题和挑战
- 基准失效&数据泄露
-
静态数据集与快速演进的LLM能力形成GAP,导致基准失效
-
公开的benchmark被泄露到LLM的开发PT、CPT、SFT等开发环节
解决思路: 动态数据集

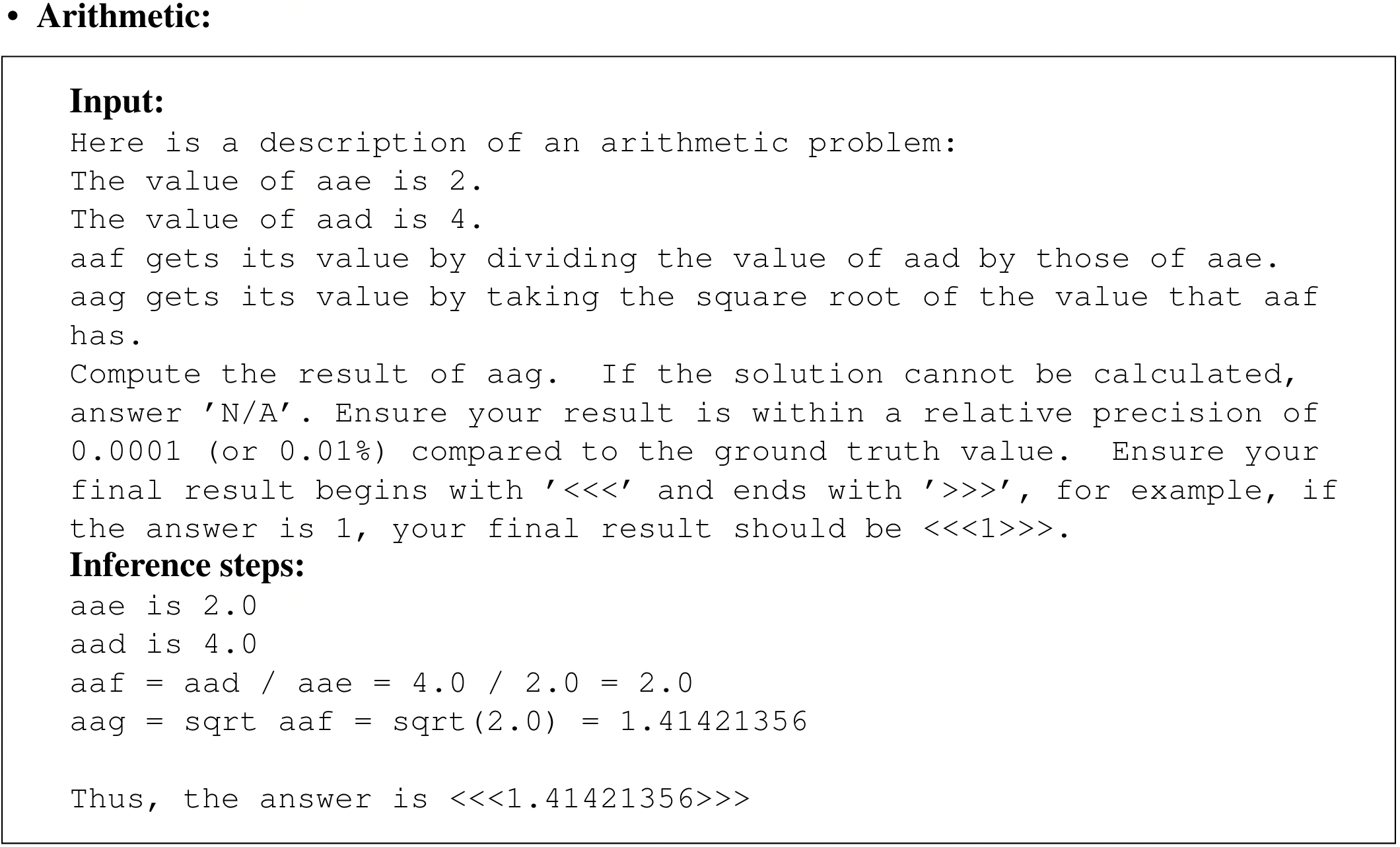
- 裁判员模型的能力上限
-
裁判员模型的存在明显的能力边界,很难胜任更多场景、更强模型的评测工作
-
泛化性问题
-
LLM幻觉的诊断问题
3.LLM评估实战
LLMuses框架–轻量化、端到端的大模型自动评估框架
GitHub: https://github.com/modelscope/llmuses
框架特性
-
预置常用的测试基准,包括:MMLU、C-Eval、GSM8K、ARC、HellaSwag、TruthfulQA、MATH、HumanEval、BBH、GeneralQA等
-
常用评估指标(metrics)的实现
-
统一model接入,兼容多个系列模型的generate、chat接口
-
客观题自动评估
-
使用专家模型实现复杂任务的自动评估
-
竞技场模式(Arena)
-
评估报告生成与可视化
-
LLM性能评测(Performance Evaluation)
环境安装
# 1. 代码下载
git clone git@github.com:modelscope/llmuses.git
# 2. 安装依赖
cd llmuses/
pip install -r requirements/requirements.txt
pip install -e .
- 简单评测
python llmuses/run.py --model ZhipuAI/chatglm3-6b --datasets ceval --outputs ./outputs/test --limit 10
-
–model: ModelScope模型id, (https://modelscope.cn/models/ZhipuAI/chatglm3-6b/summary) ,也可以是模型的本地路径
-
–datasets: 数据集的id
-
–limit: (每个sub-task)最大评测样本数
- 带参数评测
python llmuses/run.py --model ZhipuAI/chatglm3-6b --outputs ./outputs/test2 --model-args revision=v1.0.2,precision=torch.float16,device_map=auto --datasets arc --limit 10
-
–model-args: 模型参数,以逗号分隔,key=value形式
-
–datasets: 数据集名称,参考下文`数据集列表`章节
-
–mem-cache: 是否使用内存缓存,若开启,则已经跑过的数据会自动缓存,并持久化到本地磁盘
-
–limit: 每个subset最大评估数据量
- 竞技场模式–Single mode
Single mode,使用专家模型(GPT-4)对待测LLM进行打分
# Example
python llmuses/run_arena.py --c registry/config/cfg_single.yaml --dry-run
- 竞技场模式–Baseline mode
Baseline mode,选定baseline模型,其它待测LLM与该模型进行对比
# Example
python llmuses/run_arena.py --dry-run --c registry/config/cfg_pairwise_baseline.yaml
- 竞技场模式–Pairwise mode
Pairwise mode,待测LLM两两组合进行对弈
python llmuses/run_arena.py -c registry/config/cfg_arena.yaml --dry-run

- 效果评测报告
按照预定格式存放数据,使用streamlit启动可视化服务
# Usage:
streamlit run viz.py -- --review-file llmuses/registry/data/qa_browser/battle.jsonl --category-file llmuses/registry/data/qa_browser/category_mapping.yaml
-
报告可视化
-

-
Leaderboard: https://modelscope.cn/leaderboard/58/ranking?type=free

- 模型性能评测(Perf Eval)
性能评测报告示例


4.大模型评估框架-llmuses
链接:https://github.com/modelscope/eval-scope
大型语言模型评估(LLMs evaluation)已成为评价和改进大模型的重要流程和手段,为了更好地支持大模型的评测,我们提出了llmuses框架,该框架主要包括以下几个部分:
-
预置了多个常用的测试基准数据集,包括:MMLU、CMMLU、C-Eval、GSM8K、ARC、HellaSwag、TruthfulQA、MATH、HumanEval等
-
常用评估指标(metrics)的实现
-
统一model接入,兼容多个系列模型的generate、chat接口
-
自动评估(evaluator):
- 客观题自动评估
- 使用专家模型实现复杂任务的自动评估
-
评估报告生成
-
竞技场模式(Arena)
-
可视化工具
-
模型性能评估
-
特点
-
轻量化,尽量减少不必要的抽象和配置
-
易于定制
- 仅需实现一个类即可接入新的数据集
- 模型可托管在ModelScope上,仅需model id即可一键发起评测
- 支持本地模型可部署在本地
- 评估报告可视化展现
-
丰富的评估指标
-
model-based自动评估流程,支持多种评估模式
- Single mode: 专家模型对单个模型打分
- Pairwise-baseline mode: 与 baseline 模型对比
- Pairwise (all) mode: 全部模型两两对比
4.1 环境准备
我们推荐使用conda来管理环境,并使用pip安装依赖:
- 创建conda环境
conda create -n eval-scope python=3.10
conda activate eval-scope
- 安装依赖
pip install llmuses
- 使用源码安装
- 下载源码
git clone https://github.com/modelscope/eval-scope.git
- 安装依赖
cd eval-scope/
pip install -e .
4.2快速开始
- 简单评估
在指定的若干数据集上评估某个模型,流程如下:
如果使用git安装,可在任意路径下执行:
python -m llmuses.run --model ZhipuAI/chatglm3-6b --template-type chatglm3 --datasets arc --limit 100
如果使用源码安装,在eval-scope路径下执行:
python llmuses/run.py --model ZhipuAI/chatglm3-6b --template-type chatglm3 --datasets mmlu ceval --limit 10
其中,–model参数指定了模型的ModelScope model id,模型链接:ZhipuAI/chatglm3-6b
- 带参数评估
python llmuses/run.py --model ZhipuAI/chatglm3-6b --template-type chatglm3 --model-args revision=v1.0.2,precision=torch.float16,device_map=auto --datasets mmlu ceval --use-cache true --limit 10
python llmuses/run.py --model qwen/Qwen-1_8B --generation-config do_sample=false,temperature=0.0 --datasets ceval --dataset-args '{"ceval": {"few_shot_num": 0, "few_shot_random": false}}' --limit 10
参数说明:
- –model-args: 模型参数,以逗号分隔,key=value形式
- –datasets: 数据集名称,支持输入多个数据集,使用空格分开,参考下文
数据集列表章节 - –use-cache: 是否使用本地缓存,默认为
false;如果为true,则已经评估过的模型和数据集组合将不会再次评估,直接从本地缓存读取 - –dataset-args: 数据集的evaluation settings,以json格式传入,key为数据集名称,value为参数,注意需要跟–datasets参数中的值一一对应
- –few_shot_num: few-shot的数量
- –few_shot_random: 是否随机采样few-shot数据,如果不设置,则默认为true
- –limit: 每个subset最大评估数据量
- –template-type: 需要手动指定该参数,使得eval-scope能够正确识别模型的类型,用来设置model generation config。
关于–template-type,具体可参考:模型类型列表
可以使用以下方式,来查看模型的template type list:
from llmuses.models.template import TemplateType
print(TemplateType.get_template_name_list())
4.3 使用本地数据集
数据集默认托管在ModelScope上,加载需要联网。如果是无网络环境,可以使用本地数据集,流程如下:
- 下载数据集到本地
#假如当前本地工作路径为 /path/to/workdir
wget https://modelscope.oss-cn-beijing.aliyuncs.com/open_data/benchmark/data.zip
unzip data.zip
则解压后的数据集路径为:/path/to/workdir/data 目录下,该目录在后续步骤将会作为–dataset-dir参数的值传入
- 使用本地数据集创建评估任务
python llmuses/run.py --model ZhipuAI/chatglm3-6b --template-type chatglm3 --datasets arc --dataset-hub Local --dataset-dir /path/to/workdir/data --limit 10
#参数说明
#--dataset-hub: 数据集来源,枚举值: `ModelScope`, `Local`, `HuggingFace` (TO-DO) 默认为`ModelScope`
#-dataset-dir: 当--dataset-hub为`Local`时,该参数指本地数据集路径; 如果--dataset-hub 设置为`ModelScope` or `HuggingFace`,则该参数的含义是数据集缓存路径。
- (可选)在离线环境加载模型和评测
模型文件托管在ModelScope Hub端,需要联网加载,当需要在离线环境创建评估任务时,可参考以下步骤:
#1. 准备模型本地文件夹,文件夹结构参考chatglm3-6b,链接:https://modelscope.cn/models/ZhipuAI/chatglm3-6b/files
#例如,将模型文件夹整体下载到本地路径 /path/to/ZhipuAI/chatglm3-6b
#2. 执行离线评估任务
python llmuses/run.py --model /path/to/ZhipuAI/chatglm3-6b --template-type chatglm3 --datasets arc --dataset-hub Local --dataset-dir /path/to/workdir/data --limit 10
4.4 使用run_task函数提交评估任务
- 配置任务
import torch
from llmuses.constants import DEFAULT_ROOT_CACHE_DIR
#示例
your_task_cfg = {
'model_args': {'revision': None, 'precision': torch.float16, 'device_map': 'auto'},
'generation_config': {'do_sample': False, 'repetition_penalty': 1.0, 'max_new_tokens': 512},
'dataset_args': {},
'dry_run': False,
'model': 'ZhipuAI/chatglm3-6b',
'datasets': ['arc', 'hellaswag'],
'work_dir': DEFAULT_ROOT_CACHE_DIR,
'outputs': DEFAULT_ROOT_CACHE_DIR,
'mem_cache': False,
'dataset_hub': 'ModelScope',
'dataset_dir': DEFAULT_ROOT_CACHE_DIR,
'stage': 'all',
'limit': 10,
'debug': False
}
- 执行任务
from llmuses.run import run_task
run_task(task_cfg=your_task_cfg)
4.4.1 竞技场模式(Arena)
竞技场模式允许多个候选模型通过两两对比(pairwise battle)的方式进行评估,并可以选择借助AI Enhanced Auto-Reviewer(AAR)自动评估流程或者人工评估的方式,最终得到评估报告,流程示例如下:
- 环境准备
a. 数据准备,questions data格式参考:llmuses/registry/data/question.jsonl
b. 如果需要使用自动评估流程(AAR),则需要配置相关环境变量,我们以GPT-4 based auto-reviewer流程为例,需要配置以下环境变量:
> export OPENAI_API_KEY=YOUR_OPENAI_API_KEY
- 配置文件
arena评估流程的配置文件参考: llmuses/registry/config/cfg_arena.yaml
字段说明:
questions_file: question data的路径
answers_gen: 候选模型预测结果生成,支持多个模型,可通过enable参数控制是否开启该模型
reviews_gen: 评估结果生成,目前默认使用GPT-4作为Auto-reviewer,可通过enable参数控制是否开启该步骤
elo_rating: ELO rating 算法,可通过enable参数控制是否开启该步骤,注意该步骤依赖review_file必须存在
- 执行脚本
#Usage:
cd llmuses
#dry-run模式 (模型answer正常生成,但专家模型不会被触发,评估结果会随机生成)
python llmuses/run_arena.py -c registry/config/cfg_arena.yaml --dry-run
#执行评估流程
python llmuses/run_arena.py --c registry/config/cfg_arena.yaml
- 结果可视化
#Usage:
streamlit run viz.py -- --review-file llmuses/registry/data/qa_browser/battle.jsonl --category-file llmuses/registry/data/qa_browser/category_mapping.yaml
4.4.2 单模型打分模式(Single mode)
这个模式下,我们只对单个模型输出做打分,不做两两对比。
- 配置文件
评估流程的配置文件参考: llmuses/registry/config/cfg_single.yaml
字段说明:
questions_file: question data的路径
answers_gen: 候选模型预测结果生成,支持多个模型,可通过enable参数控制是否开启该模型
reviews_gen: 评估结果生成,目前默认使用GPT-4作为Auto-reviewer,可通过enable参数控制是否开启该步骤
rating_gen: rating 算法,可通过enable参数控制是否开启该步骤,注意该步骤依赖review_file必须存在
- 执行脚本
#Example:
python llmuses/run_arena.py --c registry/config/cfg_single.yaml
4.4.3 Baseline模型对比模式(Pairwise-baseline mode)
这个模式下,我们选定 baseline 模型,其他模型与 baseline 模型做对比评分。这个模式可以方便的把新模型加入到 Leaderboard 中(只需要对新模型跟 baseline 模型跑一遍打分即可)
- 配置文件
评估流程的配置文件参考: llmuses/registry/config/cfg_pairwise_baseline.yaml
字段说明:
questions_file: question data的路径
answers_gen: 候选模型预测结果生成,支持多个模型,可通过enable参数控制是否开启该模型
reviews_gen: 评估结果生成,目前默认使用GPT-4作为Auto-reviewer,可通过enable参数控制是否开启该步骤
rating_gen: rating 算法,可通过enable参数控制是否开启该步骤,注意该步骤依赖review_file必须存在
- 执行脚本
#Example:
python llmuses/run_arena.py --c llmuses/registry/config/cfg_pairwise_baseline.yaml
4.5 数据集列表
| DatasetName | Link | Status | Note |
|---|---|---|---|
mmlu | mmlu | Active | |
ceval | ceval | Active | |
gsm8k | gsm8k | Active | |
arc | arc | Active | |
hellaswag | hellaswag | Active | |
truthful_qa | truthful_qa | Active | |
competition_math | competition_math | Active | |
humaneval | humaneval | Active | |
bbh | bbh | Active | |
race | race | Active | |
trivia_qa | trivia_qa | To be intergrated |
4.6 Leaderboard 榜单
ModelScope LLM Leaderboard大模型评测榜单旨在提供一个客观、全面的评估标准和平台,帮助研究人员和开发者了解和比较ModelScope上的模型在各种任务上的性能表现。
Leaderboard

4.7 实验和报告
| Model | Revision | Precision | Humanities | STEM | SocialScience | Other | WeightedAvg | Target | Delta |
|---|---|---|---|---|---|---|---|---|---|
| Baichuan2-7B-Base | v1.0.2 | fp16 | 0.4111 | 0.3807 | 0.5233 | 0.504 | 0.4506 | - | |
| Baichuan2-7B-Chat | v1.0.4 | fp16 | 0.4439 | 0.374 | 0.5524 | 0.5458 | 0.4762 | - | |
| chatglm2-6b | v1.0.12 | fp16 | 0.3834 | 0.3413 | 0.4708 | 0.4445 | 0.4077 | 0.4546(CoT) | -4.69% |
| chatglm3-6b-base | v1.0.1 | fp16 | 0.5435 | 0.5087 | 0.7227 | 0.6471 | 0.5992 | 0.614 | -1.48% |
| internlm-chat-7b | v1.0.1 | fp16 | 0.4005 | 0.3547 | 0.4953 | 0.4796 | 0.4297 | - | |
| Llama-2-13b-ms | v1.0.2 | fp16 | 0.4371 | 0.3887 | 0.5579 | 0.5437 | 0.4778 | - | |
| Llama-2-7b-ms | v1.0.2 | fp16 | 0.3146 | 0.3037 | 0.4134 | 0.3885 | 0.3509 | - | |
| Qwen-14B-Chat | v1.0.6 | bf16 | 0.5326 | 0.5397 | 0.7184 | 0.6859 | 0.6102 | - | |
| Qwen-7B | v1.1.6 | bf16 | 0.387 | 0.4 | 0.5403 | 0.5139 | 0.4527 | - | |
| Qwen-7B-Chat-Int8 | v1.1.6 | int8 | 0.4322 | 0.4277 | 0.6088 | 0.5778 | 0.5035 | - |
- Target – The official claimed score of the model on the dataset
- Delta – The difference between the WeightedAvg score and the Target score
- Settings: (Split: test, Total num: 13985, 5-shot)
| Model | Revision | Precision | Humanities | STEM | SocialScience | Other | WeightedAvg | Avg | Target | Delta |
|---|---|---|---|---|---|---|---|---|---|---|
| Baichuan2-7B-Base | v1.0.2 | fp16 | 0.4295 | 0.398 | 0.5736 | 0.5325 | 0.4781 | 0.4918 | 0.5416 (official) | -4.98% |
| Baichuan2-7B-Chat | v1.0.4 | fp16 | 0.4344 | 0.3937 | 0.5814 | 0.5462 | 0.4837 | 0.5029 | 0.5293 (official) | -2.64% |
| chatglm2-6b | v1.0.12 | fp16 | 0.3941 | 0.376 | 0.4897 | 0.4706 | 0.4288 | 0.4442 | - | - |
| chatglm3-6b-base | v1.0.1 | fp16 | 0.5356 | 0.4847 | 0.7175 | 0.6273 | 0.5857 | 0.5995 | - | - |
| internlm-chat-7b | v1.0.1 | fp16 | 0.4171 | 0.3903 | 0.5772 | 0.5493 | 0.4769 | 0.4876 | - | - |
| Llama-2-13b-ms | v1.0.2 | fp16 | 0.484 | 0.4133 | 0.6157 | 0.5809 | 0.5201 | 0.5327 | 0.548 (official) | -1.53% |
| Llama-2-7b-ms | v1.0.2 | fp16 | 0.3747 | 0.3363 | 0.4372 | 0.4514 | 0.3979 | 0.4089 | 0.453 (official) | -4.41% |
| Qwen-14B-Chat | v1.0.6 | bf16 | 0.574 | 0.553 | 0.7403 | 0.684 | 0.6313 | 0.6414 | 0.646 (official) | -0.46% |
| Qwen-7B | v1.1.6 | bf16 | 0.4587 | 0.426 | 0.6078 | 0.5629 | 0.5084 | 0.5151 | 0.567 (official) | -5.2% |
| Qwen-7B-Chat-Int8 | v1.1.6 | int8 | 0.4697 | 0.4383 | 0.6284 | 0.5967 | 0.5271 | 0.5347 | 0.554 (official) | -1.93% |
4.8 性能评测工具
专注于大语言模型的压测工具,可定制化支持各种不通的数据集格式,以及不同的API协议格式。