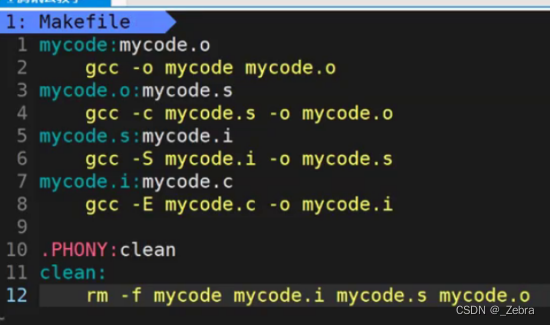
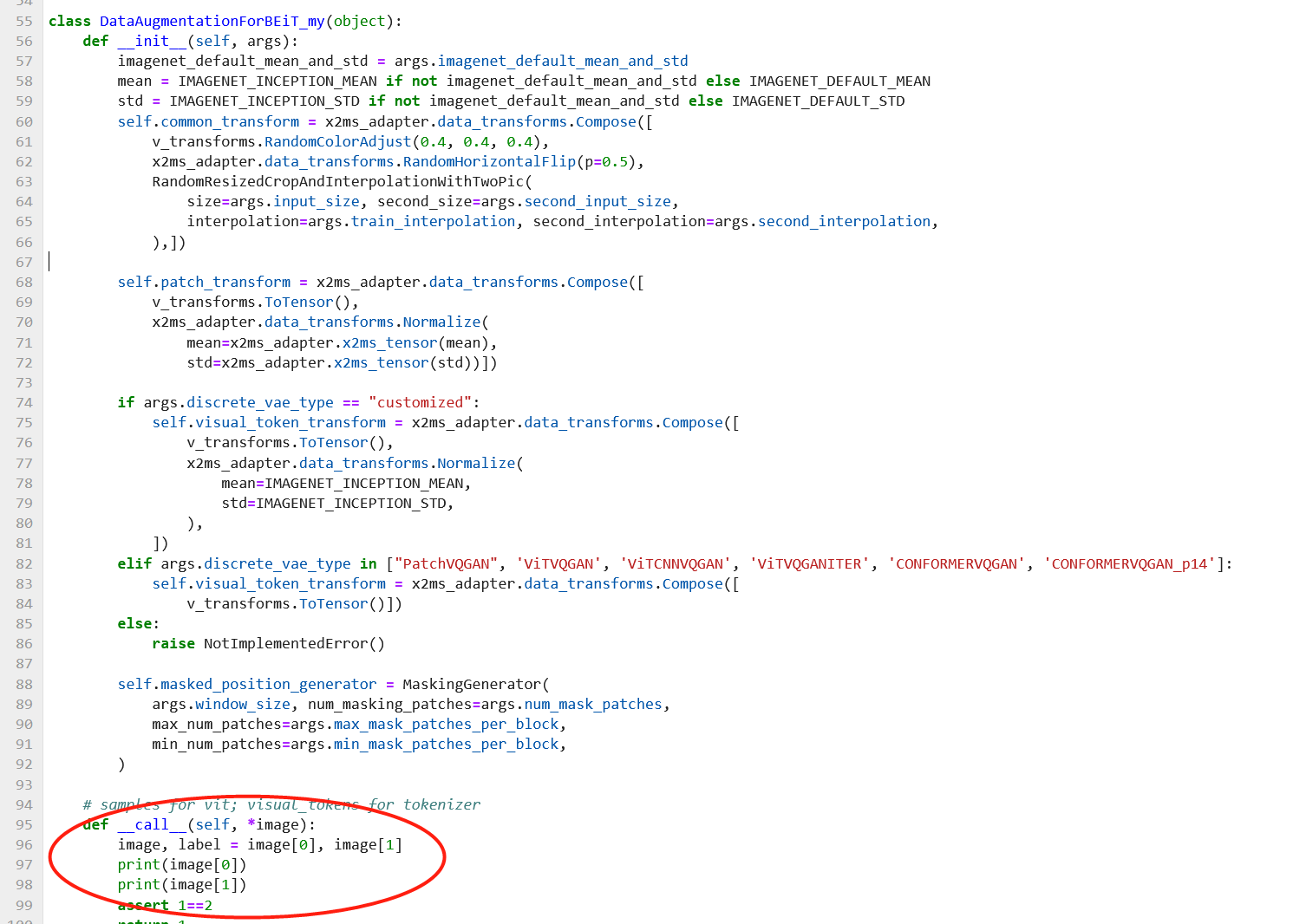
1、创建一个包含transform的自定义类并实例化

2. 类的实现如下:
请注意:在call函数中,我并没有调用init中定义的transform操作。
3. ImageFolder_forPretrain的定义如下。
在划红线的那行,出现错误。
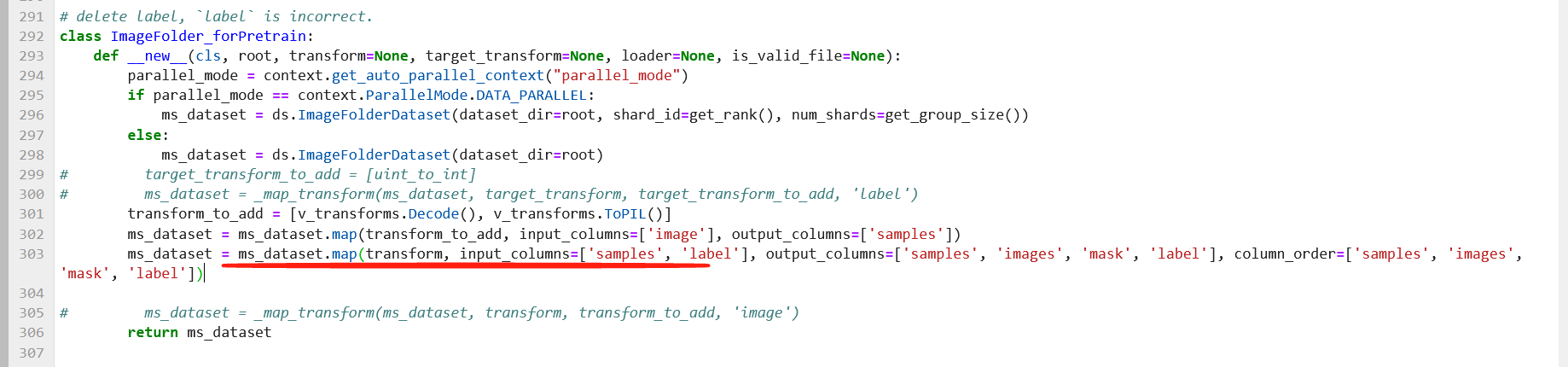
错误信息:
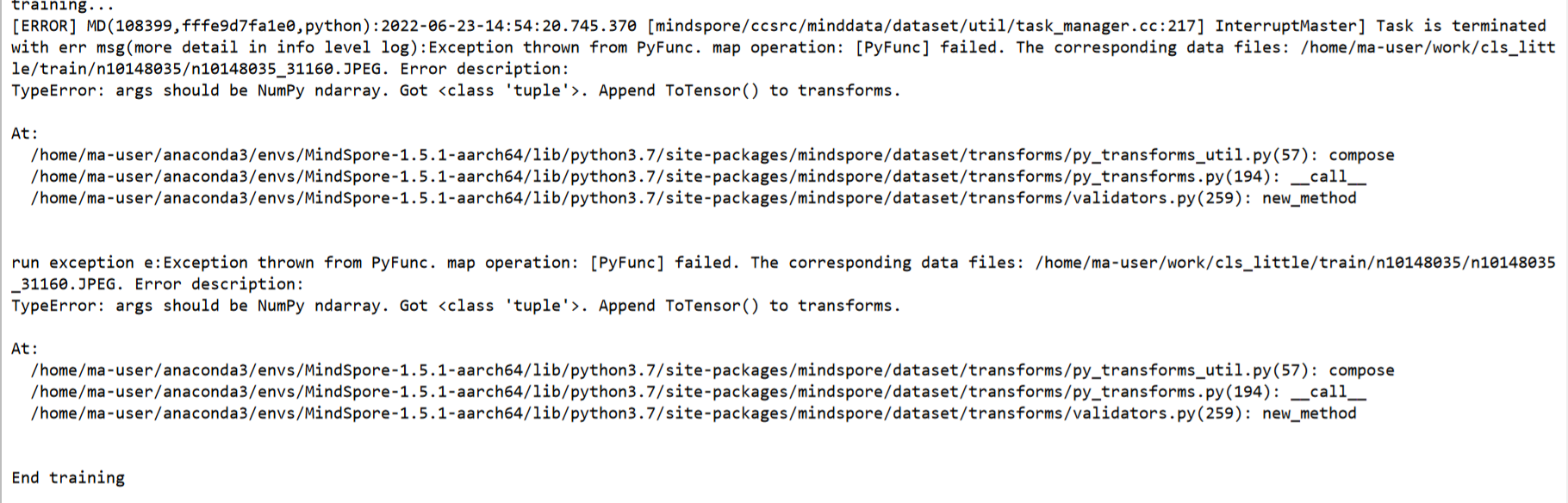
疑问:为啥我 DataAugmentationForBEiT_my中的`call`都没调用init中的函数,为啥出现了 `ToTensor`的传参错误?
先看这个会报错的示例
class ImageFolder_forPretrain:
def __new__(cls):
dataset = ds.ImageFolderDataset(DATA_DIR)
transform_to_add = [p_vision.Decode(), p_vision.ToPIL()]
dataset = dataset.map(transform_to_add, input_columns=["image"])
return dataset
def test_imagefolder_basic():
dataset = ImageFolder_forPretrain()
for item in dataset.create_dict_iterator(output_numpy=True, num_epochs=1): # each data is a dictionary
logger.warning("image is {}".format(item["image"].shape))
logger.info("label is {}".format(item["label"]))报错信息为:

这个错误跟您描述的一致。
经过日志的进一步排查信息,是因为MindSpore数据处理侧在c++与python交互的数据格式当前只能为Numpy。
那么我们看一下这个,transform_to_add = [v_transforms.Decode(), v_transforms.ToPIL()]。如果我没猜错的话,v_transforms应该是来源于 import mindspore.dataset.vision.py_transforms as v_transforms。
所以,数据集经过此步处理
transform_to_add = [v_transforms.Decode(), v_transforms.ToPIL()]
dataset = dataset.map(transform_to_add, input_columns=["image"])得到的数据类型为 PIL.Image。这样的话,会跟上述 在c++与python交互的数据格式当前只能为Numpy 的机制相悖。从而导致了这个错误。因此,对于校正这个用例,可以这么写
class ImageFolder_forPretrain:
def __new__(cls):
dataset = ds.ImageFolderDataset(DATA_DIR)
transform_to_add = [v_transforms.Decode(), v_transforms.ToPIL(), lambda x:np.array(x)]
dataset = dataset.map(transform_to_add, input_columns=["image"])
return dataset
def test_imagefolder_basic():
dataset = ImageFolder_forPretrain()
for item in dataset.create_dict_iterator(output_numpy=True, num_epochs=1): # each data is a dictionary
logger.warning("image is {}".format(item["image"].shape))
logger.info("label is {}".format(item["label"]))可以看到,在map的最后一个算子,使用了一个lambda函数强制转换为numpy,这样的话数据集可以正常迭代了