【摘要】根据观察数据估计个体治疗效果(ITE)是一项至关重要但具有挑战性的任务。解缠结表示已用于将代理变量分为混杂变量、工具变量和调整变量。然而,根据观测数据准确地进行反事实推理来识别 ITE 仍然是一个悬而未决的问题。在本文中,我们从数据和模型的角度重新审视 ITE 估计问题,揭示了以前未充分探索的方面。具体来说,我们研究了不平衡数据对 ITE 估计的影响,强调了假设兼容和方法简单性在处理不平衡数据中的重要性。从模型的角度来看,我们从信息论的角度重新审视了解缠结的表示学习,并提供了支持变分自动编码器(VAE)框架实现解缠结的有效性的理论证据。利用这些见解,我们提出了 EDVAE,这是一种用于解开潜在因素的数据驱动模型。 EDVAE 包含三个可扩展组件:用于不平衡数据的过采样层、用于分离潜在因子的表示层以及结果预测层。合成数据集和真实数据集的实验结果强调了我们提出的方法的有效性,展示了其解决根据观测数据估计 ITE 的复杂问题的潜力。
原文:EDVAE: Disentangled latent factors models in counterfactual reasoning for individual treatment effects estimation
地址:https://www.sciencedirect.com/science/article/abs/pii/S0020025523011635
出版:Information Sciences
机构: Wuhan University; Hubei Luojia Laboratory
解析人:公众号“码农的科研笔记”
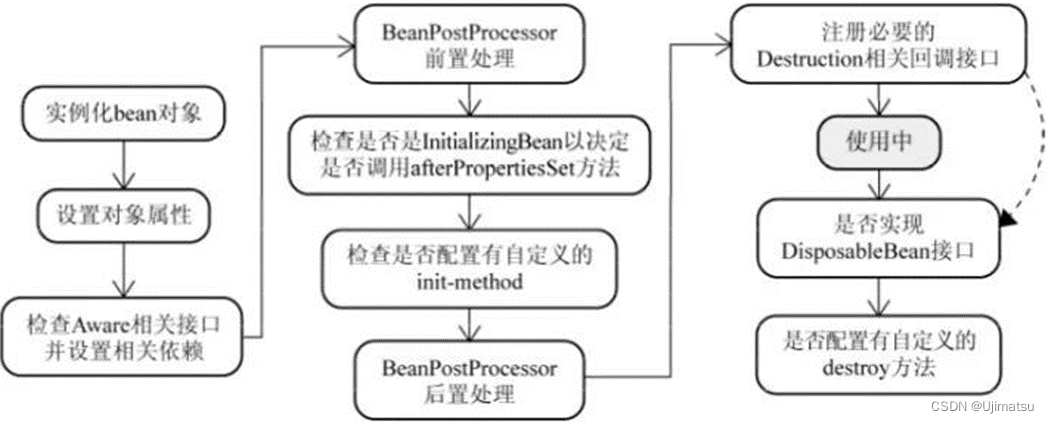
1 研究问题
本文研究的核心问题是: 如何设计一个数据驱动的解耦隐变量模型,用于从观察数据中估计个体治疗效应(ITE)。
在医疗领域,医生常常需要根据病人的个人特征,来决定是否给予某种治疗(如化疗)。这里的关键是要估计出每个病人在接受和不接受治疗情况下的预后差异,即个体治疗效应(ITE)。但现实中我们只能观察到病人实际接受的治疗结果,而无法知道反事实情况下的结果。
本文研究问题的特点和现有方法面临的挑战主要体现在以下几个方面:
-
观察数据中存在混淆偏差,即治疗分配与治疗结果之间存在共同的影响因素。传统的回归方法无法很好地消除这种偏差。
-
治疗组和对照组的样本分布不平衡,治疗组的样本量通常远小于对照组。现有的ITE估计方法大多忽略了这一问题。
-
从高维观察数据中准确识别出仅影响治疗、仅影响结果、同时影响治疗和结果的潜在因素,对于减少ITE估计偏差至关重要,但现有方法还不够理想。
针对这些挑战,本文提出了一种基于变分自编码器(VAE)框架的"EDVAE"方法:
EDVAE巧妙地将ITE估计问题分解为三个模块:过采样层、表示层和预测层。过采样层通过复制少数类(治疗组)样本来平衡数据分布。表示层利用VAE的解耦能力,从高维观察数据中提取出独立的工具变量、混淆变量和调整变量。预测层则基于治疗和潜在因素来预测反事实结果。 这种模块化设计就像一个齿轮传动装置,通过将复杂任务分解为几个简单步骤,最终实现了从观察数据到因果推理的无缝衔接。其中VAE框架起到了至关重要的作用,犹如变速箱中的"离合器",将原始数据压缩到低维隐空间,并实现了关键因素的解耦。实验表明,与现有方法相比,EDVAE在合成和真实数据集上都取得了优异的ITE估计性能,体现了其在因果推理领域的前景和潜力。
2 研究方法

为了从观察数据中准确估计个体治疗效应(ITE),本文提出了一种新的基于解开表示的方法EDVAE。EDVAE考虑了ITE估计中不平衡数据的影响,并从信息论的角度分析了变分自编码器(VAE)学习解开表示的有效性。如图3所示,EDVAE主要由三个模块组成:过采样层、表示层和预测层。
2.1 不平衡数据处理
在因果推断中,由于实际治疗的约束,治疗组的样本量通常远小于对照组,导致样本分布不平衡。不平衡数据会使一组相对另一组过度代表,造成治疗效果估计偏差。因此,EDVAE在表示学习前先引入过采样层来处理不平衡数据。
常见的过采样方法可分为生成式和非生成式两类。生成式方法(如SMOTE)通过对少数类样本插值来合成新样本。但它们可能破坏治疗、结果与协变量间原有的关系,违背因果推断所需的先验假设。非生成式方法(如随机重采样)通过对少数类样本复制来平衡数据,保持了原有关系,更适合ITE估计任务。因此,EDVAE采用随机重采样对少数的治疗组样本进行过采样,使治疗组和对照组的样本量接近。
2.2 基于VAE的解开表示学习
从因果图3(a)可知,研究者通常假设存在三类隐含因子:只影响治疗的工具变量 、同时影响治疗和结果的混淆变量 、只影响结果的调整变量 。学习相互独立的隐含因子,有助于从观察数据中准确估计治疗效应。
从信息论角度看,最小化互信息 可以降低隐含因子间的依赖性。本文推导出该互信息的一个上界(公式4),其形式与VAE的ELBO损失非常相似。因此,论文基于VAE框架来学习解开的隐含表示。表示层由一个编码器 和一个解码器 组成。其中编码器通过神经网络参数化隐变量 的后验分布,解码器对 施加先验。为了平衡治疗组和对照组在隐空间的分布差异,论文还引入Wasserstein距离作为正则项(公式13)。最终,表示层的损失由VAE重构误差、后验正则和分布差异度量三部分组成(公式6)。
2.3 协变量分解为隐含因子
个体治疗效应定义为 ,即在给定协变量 的条件下,个体 接受治疗()和未接受治疗()的潜在结果之差。为了从可观测的协变量中识别隐含的因果结构,论文将 分解为工具变量 、混淆变量 和调整变量 。这三类隐变量相互独立,分别只影响治疗、同时影响治疗和结果、只影响结果。
EDVAE的表示层负责从协变量中学习这三类相互独立的隐含因子。编码器 、、 分别对 、、 的后验分布进行建模,使其服从各自独立的高斯分布(公式10-12)。而解码器 对隐变量的联合先验分布进行建模,用于重构原始协变量。通过最小化VAE损失和分布差异度量,表示层可以学习到既能很好重构 、又能保持治疗组和对照组分布一致的隐含因子表示。
2.4 基于治疗和隐含因子的结果预测
获得隐含因子后,预测层通过因果图3(a)所示的因果关系,来预测个体在不同治疗条件下的潜在结果。其中工具变量 只影响治疗分配 而与结果 无关,因此 可以用混淆变量 和调整变量 在给定治疗 的条件下来预测。
预测层采用前馈神经网络来拟合 关于 的条件分布。它包含两个分支,分别预测个体 在治疗()和对照()条件下的潜在结果(公式9)。损失函数为预测值与观测值的对数似然(公式15)。为了估计ITE,需要对治疗前的协变量 分别假设施加治疗()和不施加治疗()两种干预,计算相应的潜在结果,再取其差值。这一过程要求隐含因子 满足可忽略性假设,即给定 的情况下,治疗分配与潜在结果相互独立。
2.5 EDVAE算法流程总结
EDVAE通过过采样层、表示层和预测层三个模块,实现端到端的个体治疗效应估计:
-
过采样层利用随机重采样平衡治疗组和对照组的样本分布;
-
表示层基于VAE框架,从平衡后的协变量中解开三个相互独立的隐含因子;
-
预测层在给定治疗和隐含因子的条件下,估计个体的潜在结果。
在训练阶段,三个模块的损失函数联合优化,使表示层学习到既满足因果假设、又与预测任务相关的隐含因子。在推理阶段,对于新的个体,表示层将其协变量映射到隐空间,预测层再估计其在不同治疗条件下的潜在结果,由此得到个体治疗效应。
总的来说,EDVAE在ITE估计中考虑了不平衡数据的影响,并利用VAE从信息论角度学习解开表示,以提高估计的准确性。同时该方法的三个模块可灵活拓展,增强了框架的通用性。 第四步、实验部分详细撰写:
5 实验
5.1 实验场景介绍
该论文提出了一个用于个体治疗效应(ITE)估计的可分离潜在因子模型EDVAE。论文实验主要在合成数据和真实数据上验证EDVAE模型的有效性,以及与其他模型的对比效果。
5.2 实验设置
-
Datasets:
-
合成数据集:通过不同的实验组比例设置生成,每个数据集包含2000个样本,25个特征
-
ACIC 2016:由4802个样本和58个变量组成
-
IHDP:一项随机临床试验数据,通过消除treated subjects的非随机子集来模拟选择偏差
-
-
Baseline:
-
TARNet
-
TEDVAE
-
CEVAE
-
DML4CATE
-
X-learner
-
DragonNet
-
-
metric:
-
PEHE:衡量估计的ITE与真实ITE之间的均方根距离
-
-
消融实验变体:
-
EDVAE-WR:不包含过采样层的EDVAE模型
-
5.3 实验结果
5.3.1 实验一、合成数据集上算法性能对比
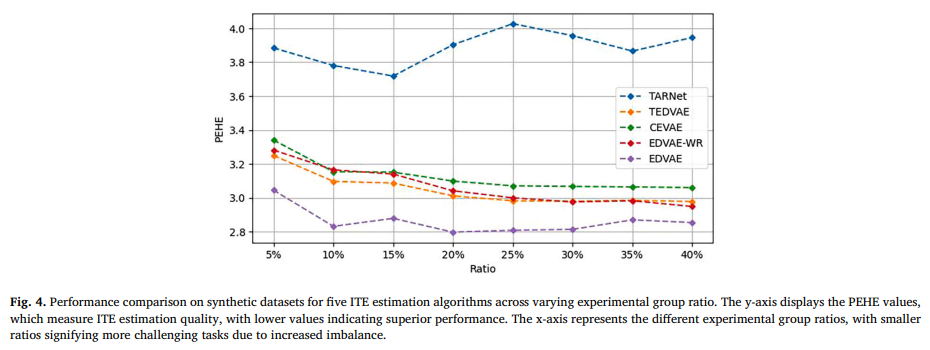
目的:验证不平衡数据对ITE估计的影响,并比较不同算法在不同程度不平衡数据下的性能
涉及图表:图4
实验细节概述:在具有不同实验组比例(5%到40%)的合成数据集上,比较TARNet、TEDVAE、CEVAE、DML4CATE、X-learner、DragonNet和EDVAE的PEHE性能
结果:
-
大多数方法在比例小于20%时性能较差
-
EDVAE在比例超过10%时表现相对稳定,在估计ITE方面具有优势
5.3.2 实验二、可分离模型性能的回归可视化
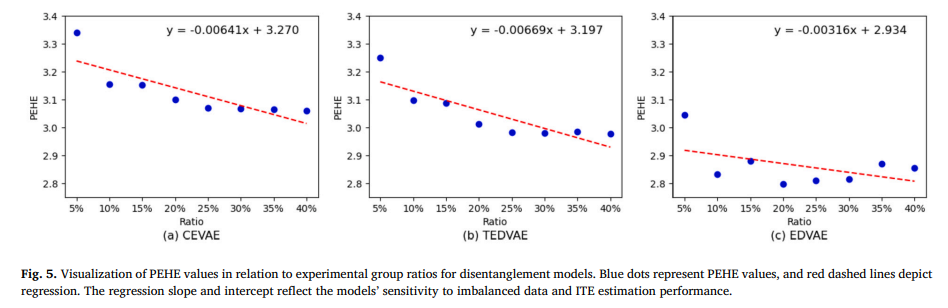
目的:直观展示EDVAE等可分离表示学习模型处理不平衡数据的优势
涉及图表:图5
实验细节概述:对CEVAE、TEDVAE和EDVAE模型的ITE估计结果进行回归拟合,并给出回归线方程
结果:
-
与CEVAE和TEDVAE相比,EDVAE的回归线斜率和截距更好
-
证实了不平衡数据对可分离潜在因子模型结果的重要影响
5.3.3 实验三、EDVAE消融实验
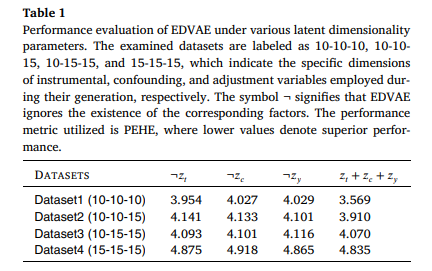
目的:研究EDVAE模型中关键组件(过采样层、不同潜在因子维度等)对模型性能的影响
涉及图表:图4,表1
实验细节概述:
-
比较包含和不包含过采样层的EDVAE模型性能
-
探究不同维度的混淆、工具和调整变量对EDVAE性能的影响
结果:
-
EDVAE整体优于EDVAE-WR,证实了过采样层在ITE估计中的有效性
-
当潜在维度参数非零时,EDVAE性能显著提升,验证了其成功识别潜在因子的能力
5.3.4 实验四、ACIC 2016数据集性能对比

目的:在ACIC 2016数据集上评估EDVAE相比其他方法的优势
涉及图表:表2
实验细节概述:使用训练集和测试集的PEHE指标比较DML4CATE、X-learner、DragonNet、CEVAE、TEDVAE、EDVAE-WR和EDVAE
结果:
-
学习可分离表示的方法(如EDVAE和TEDVAE)取得了更好的结果
-
EDVAE在平均值和方差方面实现了最佳性能
5.3.5 实验五、IHDP数据集性能对比
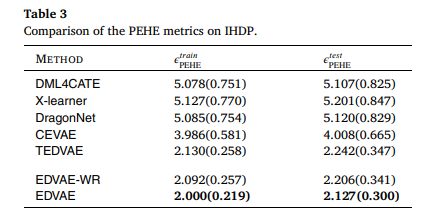
目的:在IHDP半合成数据集上评估EDVAE相比其他方法的优势
涉及图表:表3
实验细节概述:使用训练集和测试集的PEHE指标比较DML4CATE、X-learner、DragonNet、CEVAE、TEDVAE、EDVAE-WR和EDVAE
结果:
-
EDVAE的PEHE错误率在训练集和测试集上分别比TEDVAE低6.10%和5.12%
-
EDVAE的标准差较小,表明其在真实数据集上表现更稳定
4 总结后记
本论文针对从观察数据估计个体治疗效应(ITE)的问题,提出了一种新的数据驱动的解耦隐变量模型EDVAE。该模型包含三个可扩展的组件:用于不平衡数据的过采样层、用于解耦隐变量表示的表示层以及结果预测层。在合成数据和真实数据上的实验结果表明,所提出的方法在ITE估计任务上优于现有方法,展现了从观察数据估计ITE的潜力。
疑惑和想法:
-
EDVAE目前只考虑了二元治疗,如何扩展到多元治疗的场景?
-
除了VAE框架,是否可以探索其他形式的生成模型来学习解耦表示,如GAN、Flow等?
-
如何将EDVAE与其他减少选择偏差的技术(如匹配、重加权等)相结合,进一步提升ITE估计的性能?(聚焦数据挑战)
-
EDVAE能否扩展到估计其他形式的因果效应,如平均治疗效应(ATE)、条件平均治疗效应(CATE)等?
可借鉴的方法点:
-
在表示学习中引入VAE框架和互信息最小化准则来实现解耦表示,这一思想可以推广到其他领域,如视觉、语音等。
-
采用过采样层来处理不平衡数据问题的方法简单有效,可以应用于其他对不平衡数据敏感的机器学习任务。
-
将因果推断问题转化为表示学习和预测问题的思路值得借鉴,为因果效应估计提供了新的视角。
-
利用辅助损失函数来平衡治疗组和对照组在隐空间的分布差异,这一技巧可用于改进其他领域的域适应问题。