🚀 作者 :“大数据小禅”
🚀 文章简介 :本专栏后续将持续更新大模型相关文章,从开发到微调到应用,需要下载好的模型包可私。
🚀 欢迎小伙伴们 点赞👍、收藏⭐、留言💬
目录导航
- 1 什么是Embedding
- 2 为什么使用Embedding
- 3 数据向量化的处理流程
- 4 Embedding实战
1 什么是Embedding
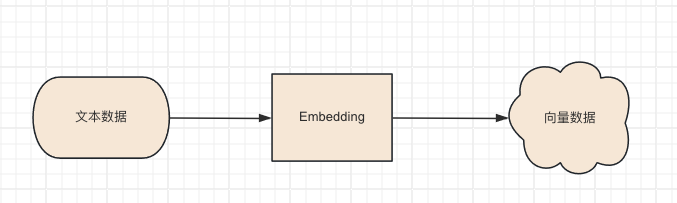
- 在大模型中,"embedding"指的是将某种类型的输入数据(如文本、图像、声音等)转换成一个稠密的数值向量的过程。
- 这些向量通常包含较多维度,每一个维度代表输入数据的某种抽象特征或属性。
- Embedding 的目的是将实际的输入转化为一种格式,使得计算机能够更有效地处理和学习
- 文本Embedding
在自然语言处理(NLP)中,文本embedding是一个常见的概念。是将文字或短语转换成数值向量的过程。这些向量捕捉了单词的语义特征,例如意义、上下文关系等。比如,使用词嵌入技术(如Word2Vec、GloVe或BERT),模型可以将具有相似意义的词映射到向量空间中的相近位置。
- 图像Embedding
对于图像,embedding过程通常涉及使用卷积神经网络(CNN)等模型来提取图像中的特征,并将这些特征转换为一个高维向量。这样的向量可以代表图像的内容、风格、色彩等信息,从而用于图像识别、分类或检索任务。
- 声音Embedding
在声音处理领域,embedding通常指的是将音频信号转换为一个表示其特征的向量,这包括音调、节奏、音色等。通过这样的转换,可以进行声音识别、音乐生成等任务。
2 为什么使用Embedding
- Embedding的主要优势是能够将实体转换为计算机易于处理的数值形式,同时减少信息的维度和复杂度。
- 有助于提高处理效率,而且也使得不同实体之间的比较(如计算相似度)变得可行。
- embedding通常通过大量数据的训练而得到,能够捕捉到复杂的模式和深层次的关系,这是传统方法难以实现的
3 数据向量化的处理流程
1. 收集
这一步骤是数据收集阶段,涉及到从不同的来源(如数据库、网站、文档等)收集需要分析的文本数据。这些数据可以是文章、评论、报告等形式。重点是确定数据源,并确保数据的相关性和质量。
2. 切块
对于大型文档,直接处理可能会因为模型的输入限制(如Token数量限制)而变得不可行。在这种情况下,需要将大文档分割成更小的部分。这些部分应该尽可能保持语义的完整性,例如按段落或章节切分。切块的目的是确保每块文本的大小适合模型处理,同时尽量减少上下文信息的丢失。
3. 嵌入
在切块后,每个文本块将被转换为数值向量,即通过OpenAI的embedding API进行嵌入。这一步涉及调用API,将文本数据发送到OpenAI的服务器,服务器会返回文本的向量表示。这些向量捕捉了文本的深层语义特征,使得文本之间的比较、搜索和分析变得可能。
4. 结果存储
嵌入向量生成后,需要将它们存储起来以便于后续的检索和分析。对于大型数据集,推荐使用专门的向量数据库(如Faiss、Annoy、Elasticsearch等),这些数据库优化了向量的存储和相似性搜索操作。存储不仅要保证数据的可检索性,也要考虑查询效率和存储成本
4 Embedding实战
- 演示是通过OPENAI的embedding进行,根据最新的api测试
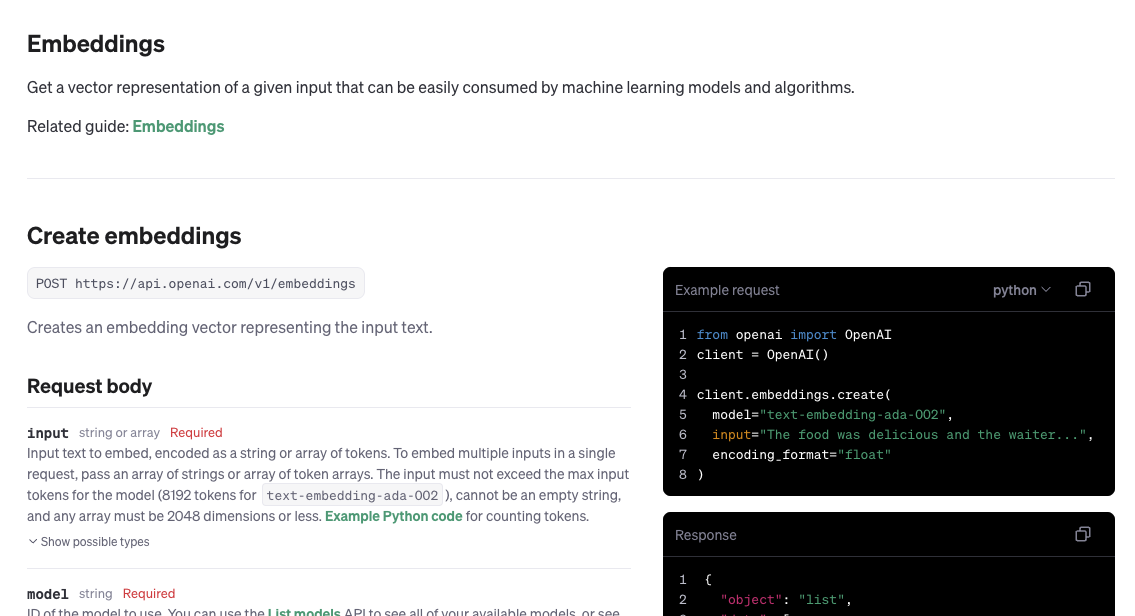
- 测试代码如下
response = openai.embeddings.create(
input="abc s da d asd a da d ",
model="text-embedding-ada-002" # 选择一个合适的模型,如ada
)
print("测试数据:",response.data[0].embedding)
- 文本转化向量

- 如何计算两个向量的相似度?
余弦相似度是一种用来衡量两个向量方向上的相似性的方法。在文本分析中,它常用于比较两段文本的语义相似性。当我们使用向量化模型(如OpenAI的text-embedding-ada-002模型)将文本转化为向量后,每个向量的维度表示某种语义特征,向量中的值反映了相应特征的强度。
余弦相似度的计算公式为:
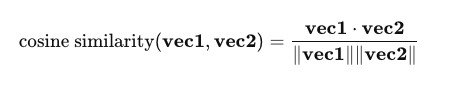
其中,
v
e
c
1
⋅
v
e
c
2
\mathbf{vec1} \cdot \mathbf{vec2}
vec1⋅vec2 表示两个向量的点积,
∣
v
e
c
1
∣
|\mathbf{vec1}|
∣vec1∣ 和
∣
v
e
c
2
∣
|\mathbf{vec2}|
∣vec2∣ 分别是这两个向量的欧几里得范数(即向量的长度)。
这个比例的本质是测量两个向量之间夹角的余弦值,范围从-1到1:
当余弦值为1时,表示两个向量方向完全相同。
当余弦值为0时,表示两个向量正交,即在高维空间中不相关。
当余弦值为-1时,表示两个向量方向完全相反。
在文本相似度测量中,如果两个文本的向量化表示在方向上更接近,它们的余弦相似度就更高,这意味着它们在语义上更相似。因此,通过计算向量之间的余弦相似度,我们可以有效地评估两段文本的相似性。这种方法适用于处理高维空间中的数据,如自然语言处理中的文本数据。
- 整体实战代码 文本检索匹配
import time
from typing import List
import os
import pandas as pd
# 导入 tiktoken 库。Tiktoken 是 OpenAI 开发的一个库,用于从模型生成的文本中计算 token 数量。
import tiktoken
from openai import OpenAI
import numpy as np
os.environ['OPENAI_API_KEY']='sk-api-0REliWJkobjeqQlObLN0T3BlbkFJ0j4bHtDhEEQGEAboNYah'
openai = OpenAI()
def embed_text(text):
""" 使用OpenAI API将文本向量化 """
response =openai.embeddings.create(
input=text,
model="text-embedding-ada-002" # 选择一个合适的模型,如ada
)
return response.data[0].embedding
def cosine_similarity(vec1, vec2):
""" 计算两个向量之间的余弦相似度 """
return np.dot(vec1, vec2) / (np.linalg.norm(vec1) * np.linalg.norm(vec2))
def find_top_similar_texts(input_text, text_list, top_n=3):
""" 找出与输入文本最相似的top_n个文本 """
input_vec = embed_text(input_text)
similarities = []
for text in text_list:
text_vec = embed_text(text)
similarity = cosine_similarity(input_vec, text_vec)
similarities.append((text, similarity))
# 按相似度排序并返回最高的top_n个结果
similarities.sort(key=lambda x: x[1], reverse=True)
return similarities[:top_n]
# 示例文本库
text_corpus = [
"The quick brown fox jumps over the lazy dog.",
"A fast brown fox leaps over a sleepy dog.",
"Exploring the mountains of the moon.",
"Data science involves the analysis of large amounts of data.",
"The capital of France is Paris.",
"Programming in Python is fun and versatile."
]
# 输入文本
input_text = "Python is"
# 执行查找
top_similar_texts = find_top_similar_texts(input_text, text_corpus)
# 打印结果
for text, similarity in top_similar_texts:
print(f"Text: {text}\nSimilarity: {similarity:.2f}\n")
#
# # 示例文本
# text1 = "The quick brown fox jumps over the lazy dog."
# text2 = "A fast brown fox leaps over a sleepy dog."
# text3 = "Exploring the mountains of the moon."
#
# # 向量化文本
# vec1 = embed_text(text1)
# vec2 = embed_text(text2)
# vec3 = embed_text(text3)
#
# # 计算相似度
# similarity12 = cosine_similarity(vec1, vec2)
# similarity13 = cosine_similarity(vec1, vec3)
#
# print(f"Similarity between text 1 and text 2: {similarity12:.2f}")
# print(f"Similarity between text 1 and text 3: {similarity13:.2f}")
response = openai.embeddings.create(
input="abc s da d asd a da d ",
model="text-embedding-ada-002" # 选择一个合适的模型,如ada
)
print("测试数据:",response.data[0].embedding)
- 结果
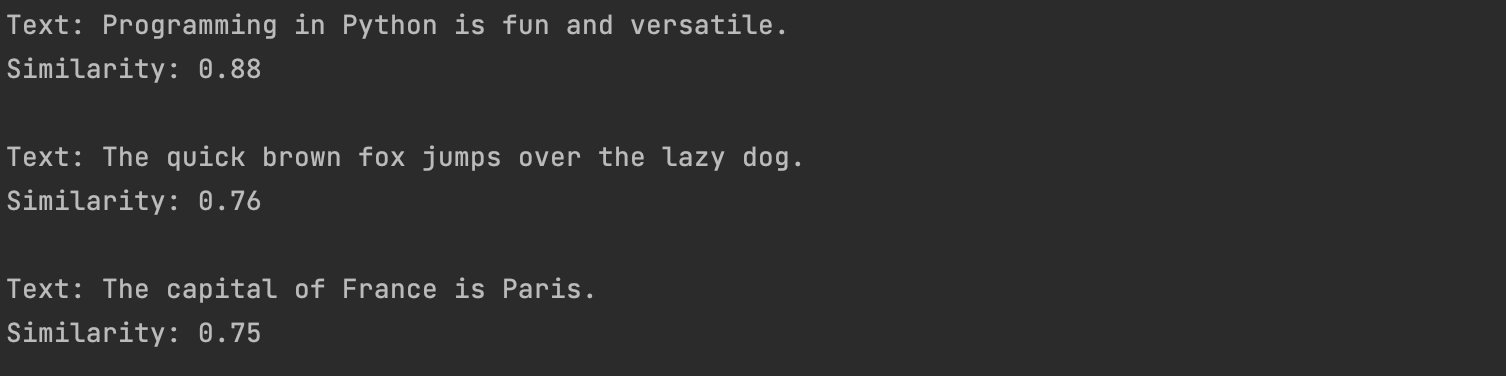
- 最终检索到匹配度前三的文本向量 后续会使用到向量数据库 完成知识库的搭建
-
🚀 欢迎小伙伴们 点赞👍、收藏⭐、留言💬 有问题可以咨询主页








![[面试题]软件测试性能测试的常见指标在Linux系统中,一个文件的访问权限是 755,其含义是什么](https://img-blog.csdnimg.cn/direct/1a33e1c1502848d8b1d2f4ebbb7d1b80.png)