引言
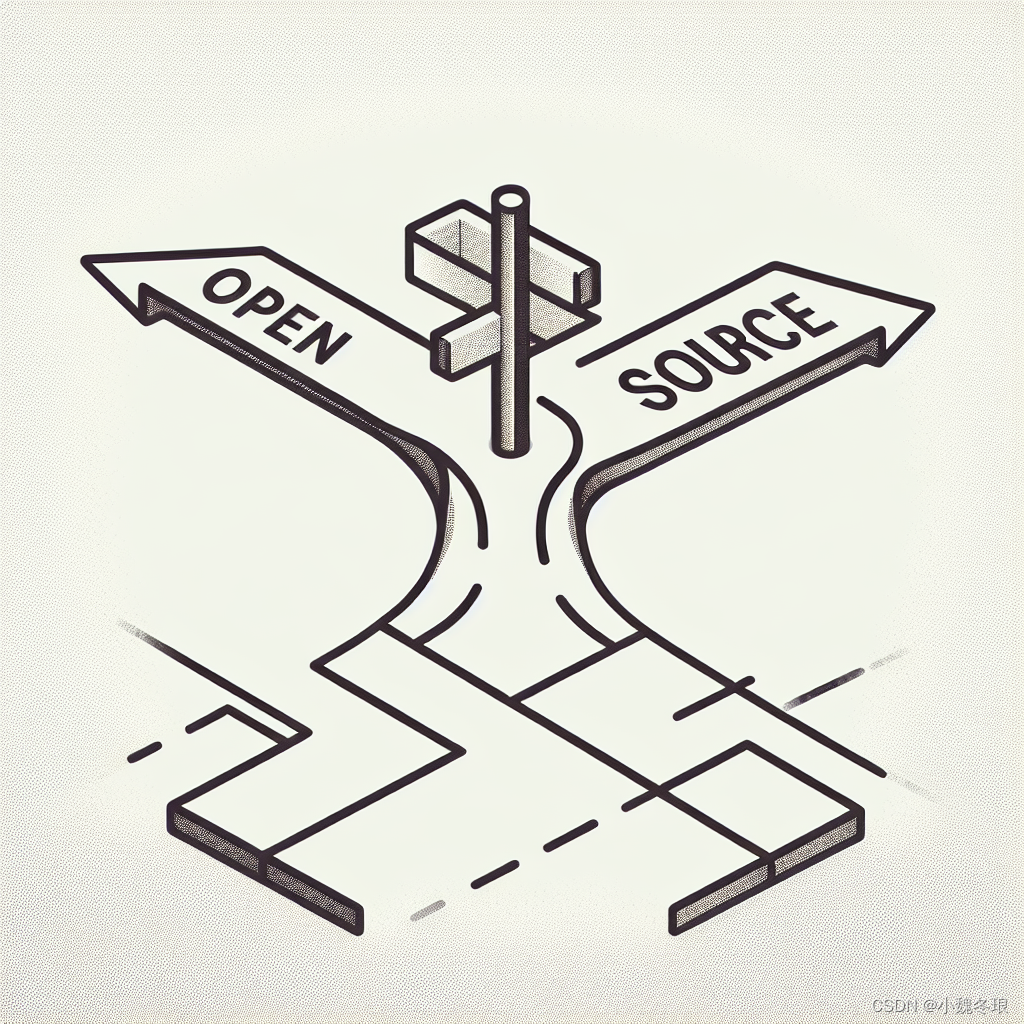
在人工智能(AI)领域,模型的发展路径主要分为“开源”和“闭源”两条。这两种模型在数据隐私保护、商业应用以及社区参与与合作方面各有优劣,是创业公司、技术巨头和开发者们必须仔细权衡的重要选择。那么,面对这些问题,我们究竟该更看好哪一种路径呢?
一、数据隐私保护:开源VS闭源
开源AI模型:
- 透明性:开源模型的源代码向公众公开,这一做法大大提高了系统的透明度,使开发者和用户能够深入了解模型的工作原理。从而更容易发现和修补潜在的安全漏洞和数据隐私问题。
- 社区审查:开源模型依赖一个庞大的开发者和研究者社区,这些人能够在模型发布后的第一时间进行代码审查,找出并解决隐私保护的薄弱环节。例如,TensorFlow和PyTorch的开源生态中,社区贡献者已经发现并修复多次安全漏洞。
- 隐私保护创新:开源社区的不断创新推动了许多隐私保护技术的普及,如差分隐私(Differential Privacy)和联邦学习(Federated Learning),并使这些技术能够快速扩展和应用于不同场景。
闭源AI模型:
- 严格的安全规范:尽管源代码不公开,闭源模型的开发公司通常会遵循严格的安全规范来保护用户数据。例如,许多科技巨头会实施端到端的数据加密和先进的访问控制机制。
- 专有技术与专用资源:闭源模型开发公司拥有专用的资源和技术可以投入到隐私保护中,例如,谷歌、微软等公司会使用专有的安全技术和工具来保护用户数据。
- 合规性:大型闭源模型开发公司通常具有较强的合规能力,他们会严格遵守GDPR等国际隐私保护法律法规,以确保用户数据不被滥用。
综上所述,开源模型在透明性及社区审查方面具有明显优势,而闭源模型则在资源集中和合规性方面表现不俗。
二、商业应用:开源VS闭源
开源AI模型:
- 灵活性与可定制性:开源模型因为源码开放,开发者可以根据自身业务需求进行定制化修改,提高了模型的灵活性。例如,许多创业公司和小型企业通过定制化的开源模型来打造自己的产品和服务。
- 成本效益:使用开源模型可以大大降低初期投资成本,企业无须支付昂贵的授权费。许多公司基于开源模型进行产品开发,如Hugging Face公司在BERT模型的基础上进行了大量优化和应用。
- 快速迭代:开源模型受益于广泛的社区支持,能够快速迭代更新。当新的算法或技术出现时,它们可以迅速应用于开源项目中。
闭源AI模型:
- 专业支持:闭源模型通常由大型科技公司提供支持,这些公司有能力提供一流的技术支持和售后服务。例如,微软的Azure和亚马逊的AWS都提供基于AI模型的云服务,并有专门的技术团队帮助客户解决问题。
- 稳定性与可靠性:闭源模型经过商业环境中的严格测试,通常具备较高的稳定性和可靠性。许多企业选择闭源模型就是因为其成熟的商业应用示例和稳定的性能。
- 完整的生态系统:闭源模型开发公司通常提供一整套的产品和服务,其中不仅包含AI模型本身,还有数据处理管道、模型管理和部署工具,以及配套的硬件设备。例如,IBM的Watson平台就提供了从数据采集到模型部署的全套解决方案。
因此,开源模型在灵活性和成本效益方面表现优异,而闭源模型则在专业支持和稳定性方面更胜一筹。
三、社区参与与合作:开源VS闭源
开源AI模型:
- 广泛的协作:开源模型的开发依赖于一个庞大的开放社区,这些社区成员分布在全球各地,涵盖了不同的行业和学科背景。他们能够为模型带来丰富的创意和创新,加速技术的迭代。例如,开源项目如SciPy、Pandas等项目就取得了显著的成就。
- 知识共享:开源模型倡导知识共享,使得更多的人能够接触到最新的技术进展和工具,从而推动整体技术水平的提升。这对于初创公司特别重要,他们可以迅速吸收最新的研究成果,并将其应用到产品开发中。
- 公开的科学研究:学术界对开源模型的认可度较高,许多研究人员倾向于使用和贡献开源项目,使得开源模型始终处于技术前沿。例如,许多顶尖学术会议的论文都基于开源框架,如TensorFlow、PyTorch等。
闭源AI模型:
- 集中化资源:闭源模型依赖于公司内部的团队进行开发,这些公司通常拥有强大的资金和人力资源,可以集中精力进行深度研发。例如,OpenAI在GPT-3模型的开发过程中就投入了大量资源。
- 垂直整合:闭源模型的开发公司通常会进行垂直整合,控制模型的开发、训练、部署和应用的整个生命周期。这种一体化的方式可以确保模型在整个过程中的一致性和高效性。
- 强大的市场推广:闭源模型开发公司通常有强大的市场推广能力,他们能够利用自己的品牌影响力和营销网络迅速推广新产品和服务。例如,谷歌的BERT模型尽管是开源的,但也在闭源环境中进行了多次优化和应用。
在社区参与与合作方面,开源模型具有显著的优势,能够有效推动技术的快速发展和创新,而闭源模型尽管在资源整合上有优势,但缺乏开源社区的广泛参与和创新动力。
总结
综合来看,开源AI模型和闭源AI模型各有优劣。在数据隐私保护方面,开源模型的透明性和社区审查机制使其具有一定优势,但闭源模型的专有技术和资源优势也不可忽视。在商业应用领域,开源模型因其灵活性和成本效益受到青睐,而闭源模型则凭借专业支持和稳定性赢得市场。在社区参与和合作方面,开源模型显然更具活力,推动了行业的快速进步和创新。
未来,AI模型的发展不仅需要技术的突破,更需要在开源与闭源间找到平衡,充分利用各自的优势,实现技术的可持续发展。这不仅有助于个体企业的发展,更将推动整个AI行业迈向新的高度。
| 分类 | 开源AI模型 | 闭源AI模型 |
|---|---|---|
| 数据隐私保护 | 透明性高,社区审查严格;推动隐私保护技术如差分隐私和联邦学习 | 依赖严格的安全规范和专有技术;资源集中,合规能力强 |
| 商业应用 | 灵活性和可定制性高,成本效益好,快速迭代 | 专业支持强,稳定性高,提供完整的生态系统 |
| 社区参与与合作 | 社区协作广泛,知识共享和公开研究,技术进步快 | 资源集中化,垂直整合强,市场推广能力强 |
![[面试题]软件测试性能测试的常见指标在Linux系统中,一个文件的访问权限是 755,其含义是什么](https://img-blog.csdnimg.cn/direct/1a33e1c1502848d8b1d2f4ebbb7d1b80.png)










![[Algorithm][动态规划][路径问题][不同路径][不同路径Ⅱ][珠宝的最高价值]详细讲解](https://img-blog.csdnimg.cn/direct/ec3c5fa9e1ed4768818e45f6a98c52ec.png)