AHOcoder声码器
目前最常见的声码器有WORLD,STRAIGHT,Griffin_Lim等,AHocoder算是少见的,但也可以学习一下。
代码下载网址:AHOcoder
简介
AHOcoder 语音声码器由 Daniel Erro 在巴斯克大学的 AHOLAB 信号处理实验室研发,专门为统计参数语音处理设计的语音编解码器,它可将语音信号转换为可处理的具有良好统计建模特性的向量。
AHOcoder 语音声码器的设计思想来源于谐波加噪声模型(Harmonics plus Noise Model, HNM),该模型将语音信号分解为低频段的谐波部分和高频段的噪声部分,但由于谐波数量会随基频的变化而变化。导致 HNM 特性不能直接用于统计系统。
参数分解
AHOcoder声码器将语音波形参数分解成三部分:对数基频,梅尔倒谱系数和最大浊音频率。
三部分的特征提取:
对数基频
基音检测,AHOcoder 声码器使用的是自相关法检测基音周期。
语音信号x(m)的短时自相关函数为:
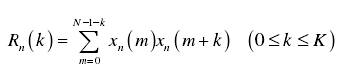
式中,
k:语音信号的延迟点数;
N:语音分帧的长度。
利用了自相关函数如下特征。
短时自相关函数反映了语音信号与其经过k 点延迟后的的相似程度。利用短时自相关函数的性质,比较原始信号与其延迟信号间的相似度,当两者具有最大相似度时,延迟量就等于基音周期。这就是获得语音信号基音周期的方法,称为自相关基音检测法。
如果信号x(m)具有周期性,则相关函数R(k)也是周期函数且周期性与x(m)相同;如果当k=0,T,2T…时,短时自相关函数取得最大值。这样就得到周期T。
梅尔倒谱系数
假设一个简化的语音产生模型,其中脉冲或噪声激励通过整型滤波器,得到的频谱包络就表示该滤波器的频率响应。
频谱包络不仅包含声道信息,还包括声门信息。
- 清音帧中,噪声激励的频谱是平坦的,这意味着滤波器的响应与信号本身的频谱一致。
- 浊音帧中,脉冲激发的频谱为恒定振幅,线性频率相位置于基频整数倍的脉冲序列。因此,信号的频谱为一系列的峰值,这些峰值由激励脉冲乘以滤波器响应的均匀间隔的频谱采样而得到。
假设信号短时平稳,全带谐波分析返回这些频谱包络的离散采样,然后可以通过插值来估计连续的包络。
k 帧处的 N 点幅度谱包络计算如下:

最大浊音频率(Maximum Voiced Frequency, MVF)
最大浊音频率是谐波与噪声在频域的分界点,假设高于 MVF 的部分只包含噪声,低于 MVF 部分只包含谐波。早期的声码器实现中 MVF 被认为是一个固定值,分解合成的语音效果也不错。但后来发现在语音合成的低频部分和句子结尾会伴随有轻微的嗡嗡声,这时就需要对MVF 进行调整。当局部最大浊音频率通过下面的线性关系进行调整时,这种现象可以得到缓解:
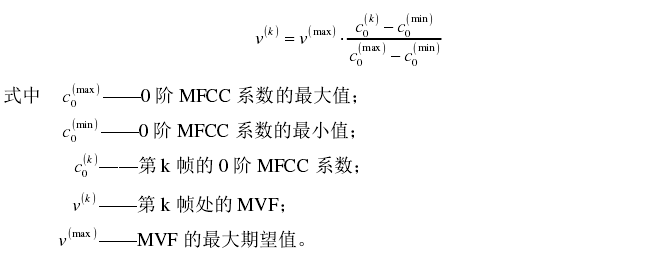
分析得到的 MVF 在合成语音时会产生更自然的结果,同时也保留了系统的实时生成能力。
语音合成
该模型以基音同步帧速率和帧长重建语音信号,时域卷积,频域乘积。