BeanPostProcessor,是bean的增强器,在bean初始化前后调用,常用的方法有postProcessBeforeInitialization和postProcessAfterInitialization,在Spring启动并初始化bean前后通过它们做一些扩展操作。
1、BeanPostProcessor 接口说明
BeanPostProcessor接口在org.springframework.beans.factory.config包下,该接口源码如下:
public interface BeanPostProcessor {
@Nullable
default Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
return bean;
}
@Nullable
default Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
return bean;
}
}名词解释:
- @Nullable:该注解可用在属性、方法、方法参数上,表示属性值、方法返回值、方法参数值可为空;
- bean:指容器中正在创建的bean引用;
- beanName:指容器中正在创建的bean名称;
- postProcessBeforeInitialization():可理解为前置处理器,在bean初始化之前被调用;
- postProcessAfterInitialization():可理解为后置处理器,在bean初始化之后被调用;
执行时机:
当创建bean实例并完成属性填充之后,会调用AbstractAutowireCapableBeanFactory类的initializeBean方法对bean进行初始化,在初始化前后会分别执行postProcessBeforeInitialization方法和postProcessAfterInitialization,源码如下:
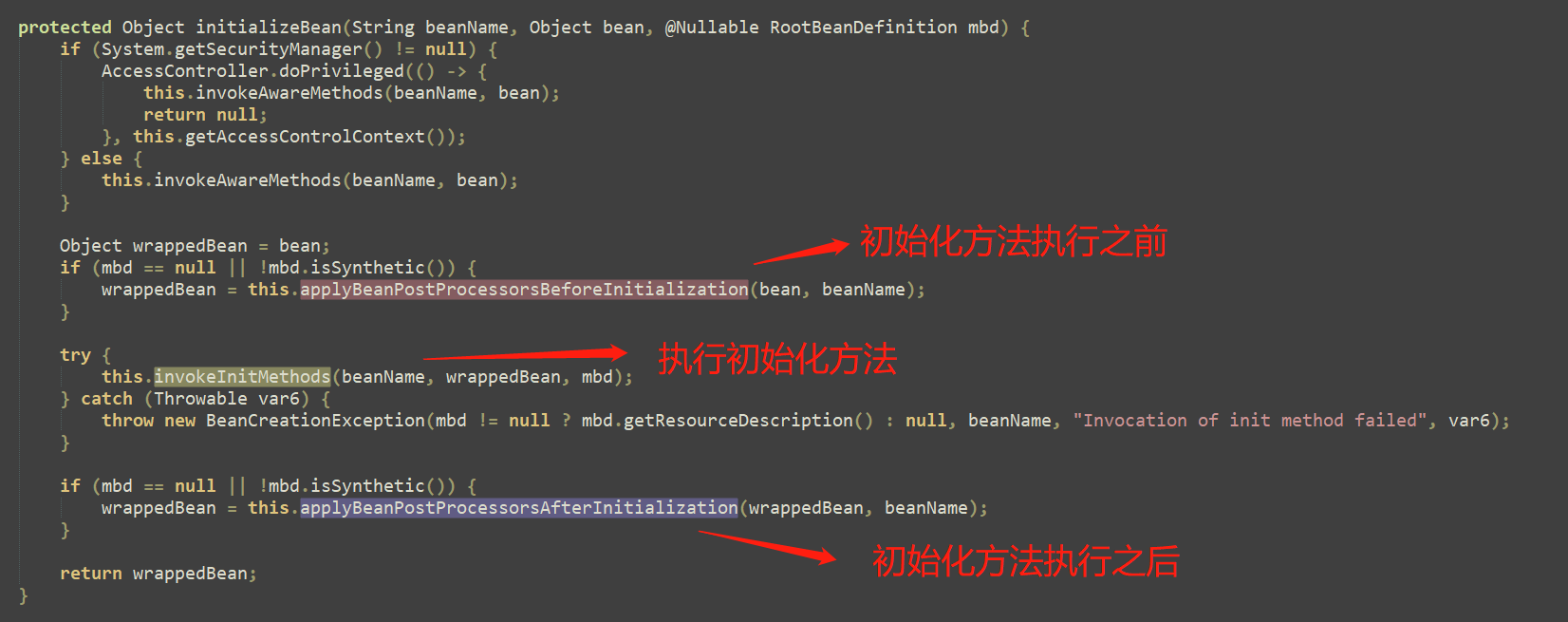
继续打开看一看applyBeanPostProcessorsBeforeInitialization方法或applyBeanPostProcessorsAfterInitialization方法,如下:
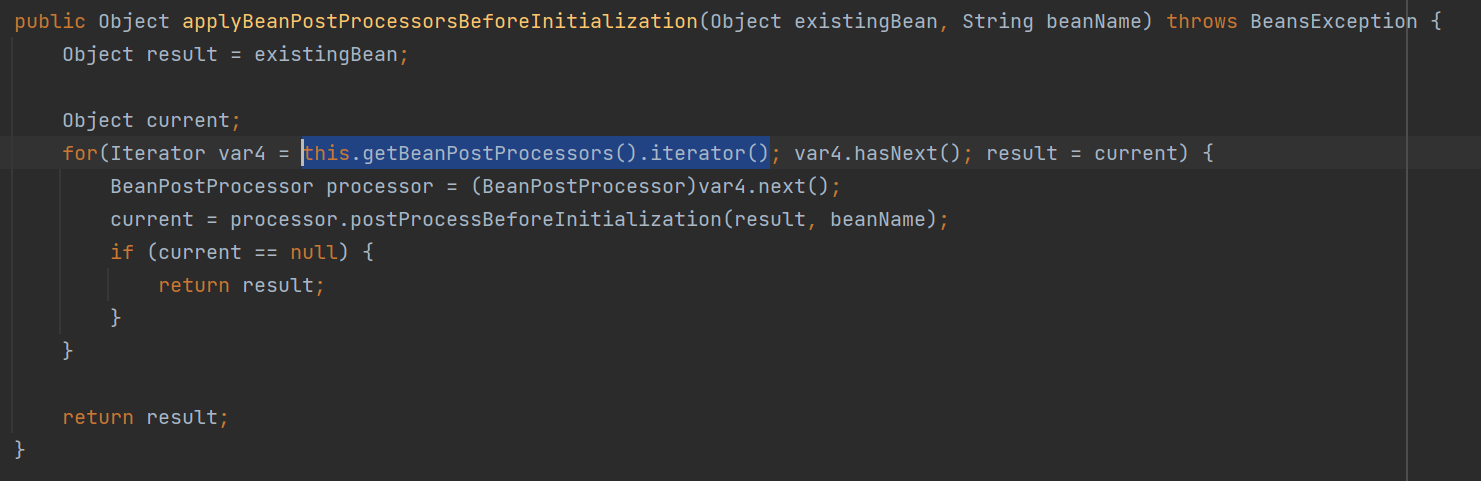
这里,能看到BeanPostProcessor会对Spring容器的所有bean进行处理。
有了对BeanPostProcessor接口的认识,就可以通过它做一些逻辑扩展了。
2、BeanPostProcessor 应用场景
插件管理器
顾名思义,就是不同功能的插件需要在一个地方进行统一管理,也可以看作是设计模式中的策略模式。接下来,演示使用BeanPostProcessor实现一个插件管理器。
第一步,自定义一个BeanPostProcessor的实现类,即插件管理类PluginManager,如下:
/**
* 插件管理器
*/
@Slf4j
@Component
public class PluginManager implements BeanPostProcessor {
//定义一个数据处理器Map,用于存储和数据类型绑定的数据处理器对象
private static final Map<String, DataProcessor> dataProcessorMap = new HashMap<>();
@Override
public Object postProcessAfterInitialization(@Nullable Object bean, @Nullable String beanName) throws BeansException {
if (bean instanceof DataProcessor) {
DataProcessor dp = (DataProcessor) bean;
dataProcessorMap.put(dp.getDataType(), dp);
log.info("PluginManager.postProcessAfterInitialization() | size={},dataProcessorMap={}"
, dataProcessorMap.size(), dataProcessorMap);
}
return bean;
}
public static DataProcessor getDataPlugin(String dataType) {
return dataProcessorMap.get(dataType);
}
}注意,当Spring bean初始化之后,接着会调用postProcessAfterInitialization方法,我们利用该方法就可以做一些扩展增强操作。这里,将bean引用进行了具体化,即强转为某个对象,然后把与数据类型绑定的该对象实例存储到map里,并向外暴露一个静态的getDataPlugin方法,用于根据数据类型匹配到不同数据处理器对象。
第二步,自定义DataProcessor接口,提供一些方法给该接口的实现类们使用,如下:
/**
* 数据处理器
*/
public interface DataProcessor {
//获取数据类型
String getDataType();
//实现对应数据类型的业务处理逻辑
void process(String var1, String var2)
}第三步,自定义DataProcessor接口的实现类TestAProcessor,并通过注解@Component注入容器,如下:
@Slf4j
@Component
public class TestAProcessor implements DataProcessor{
@Override
public String getDataType() {
return "01";
}
@Override
public void process(String var1, String var2) {
//当前插件对应的业务逻辑 TODO
}
}这里,我们按照该形式可以定义多个实现类(插件),我又增加了两个插件TestBProcessor和TestCProcessor,接着启动Spring容器做一些简单的测试,启动日志信息如下:

可以看到,当这些bean完成初始化之后,会走到postProcessAfterInitialization方法,通过该方法的扩展逻辑将这些bean与具体的数据类型绑定并存储在map里,从而达到了管理插件的目的。
第四步,根据不同的数据类型匹配对应的插件,统一入口如下:
public class PluginClass{
public void demo() {
String dataType = "01";
//根据dataType匹配
DataProcessor dataPlugin
= PluginManager.getDataPlugin(dataType);
//插件实现的处理逻辑
dataPlugin.process("", "");
}
}这样就实现了插件管理的目的了。