作者 | 郭炜
编辑 | Debra Chen
在当今的商业环境中,大数据的管理和应用已经成为企业决策和运营的核心组成部分。然而,随着数据量的爆炸性增长,如何有效利用这些数据成为了一个普遍的挑战。
本文将探讨大数据架构、大模型的集成,以及如何将大模型集成到公司大数据架构中,并使用Apache SeaTunnel和WhaleStudio将公司内部数据进行“百科全书化”,利用大数据和大模型来提升企业运营效率。
大模型在整体公司大数据架构中的位置
当今,无论大企业还是小公司,其实都会遇到同样的问题:公司里沉淀的数据量巨大,但到底该怎么使用?
大模型的横空出世让数据利用有了全新的使用途径,问题是如何大量获得公司的数据,变成“你”的大模型?
以及如何将大模型灌入公司内部数据,并“百科全书”化?
大数据与大模型架构概览
为了更好地回答这些问题,我们首先需要弄清楚大模型在企业复杂的数据结构中处于什么位置。目前,全球流行的大数据结构图如下所示:
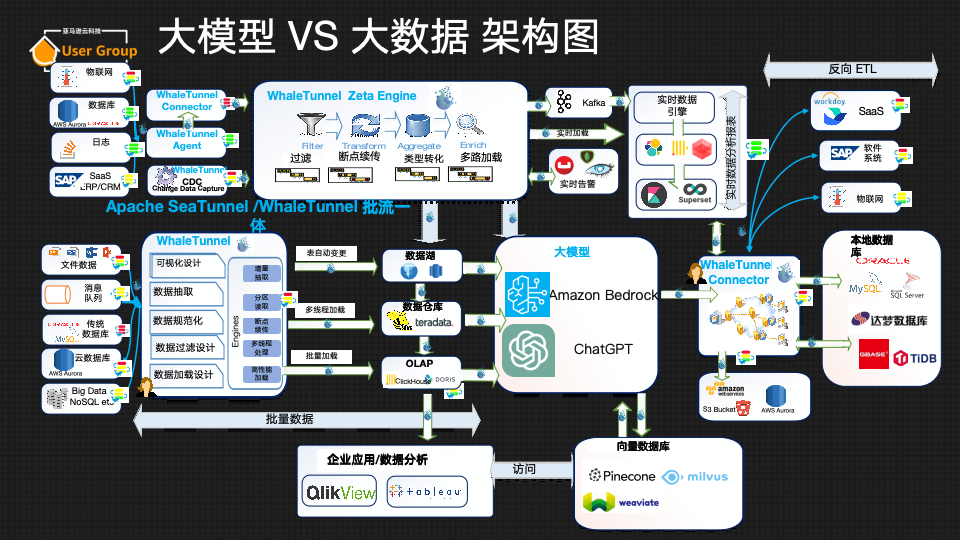
企业在处理大数据时,通常会将数据分为实时数据和批量数据两大类。实时数据可以来自车联网、数据库日志、点击流等多种来源,而批量数据则可能包括文件、报表、CSV文件等。这些数据可以通过各种工具和技术,如Apache Kafka、Amazon Kinesis等进行处理,最终被整合到企业的大数据分析系统中。
大模型在大数据架构中扮演着至关重要的角色。它们能够处理和分析大量数据,为企业提供深入的洞察和预测。大模型可以通过两种主要方法进行集成:
- 基于开源模型的优化:企业可以使用开源的大模型,并根据自己的数据进行优化,以提高模型的性能。这种方法虽然复杂,对于普通用户来做操作比较困难,但可以训练出高度定制化的模型,具体训练方法可以参考《用一杯星巴克的钱,训练自己私有化的ChatGPT》
- 数据向量化:另一种方法是将数据向量化,即将数据转换为大模型易于处理和查询的格式,然后快速地将其放入企业自己的向量数据库中。
这就是大模型在大数据架构中所处的位置和作用,大模型作为大数据架构的核心技术组件,在数据转换、预测分析和智能应用等方面发挥着不可替代的作用,是实现大数据价值的关键所在。
数据高速公路:Apache SeaTunnel& WhaleStudio
数据同步是大数据架构中的另一个关键环节。使用如Apache NiFi、Apache Spark、Sqoop等工具,可以实现数据在不同系统和数据库之间的实时和批量同步。这些工具支持跨云和混合云环境,能够处理来自各种数据源的数据,并将其同步到目标数据库或数据仓库中。但是因为依赖开源,它们的数据源支持力度非常有限。
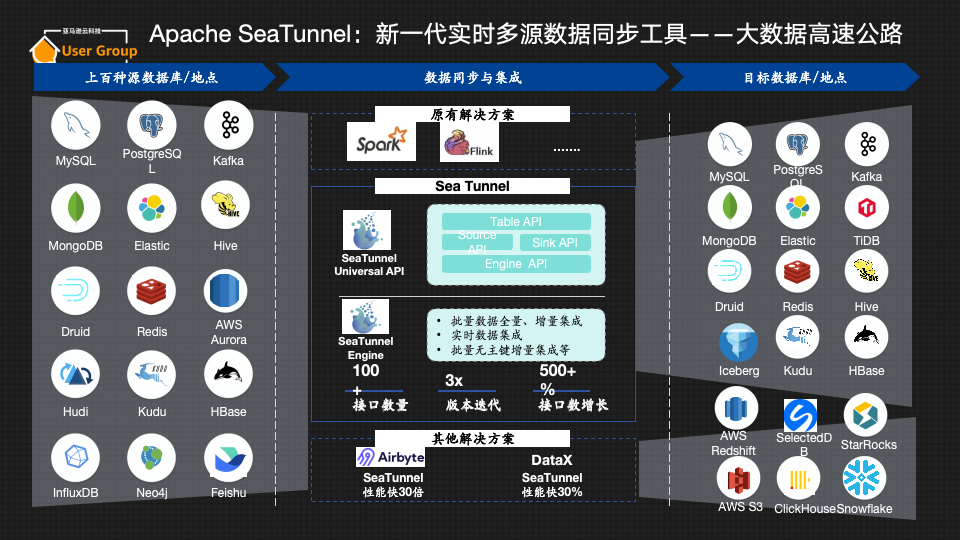
Apache SeaTunnel:新一代实时多源数据同步工具,大数据的高速公路
有一个非常形象的比喻可以简单明了地概括Apache SeaTunnel的作用——大数据的高速公路。它可以把各种各样的数据源,如MySQL、RedShift、Kafka等数据,实时和批量数据同步至目标数据库。区别于Apache NiFi、Apache Spark,新一代实时多源数据同步工具Apache SeaTunnel目前已经可以支持上百种源数据库/目的地的数据同步与集成,并支持以跨云和混合云的方式同步数据,便于不同的用户进一步进行大数据和大模型训练。
Apache SeaTunnel 典型案例
目前,Apache SeaTunnel在全球已经有大量用户,其中一个典型用户是JP Morgan(摩根大通银行)。
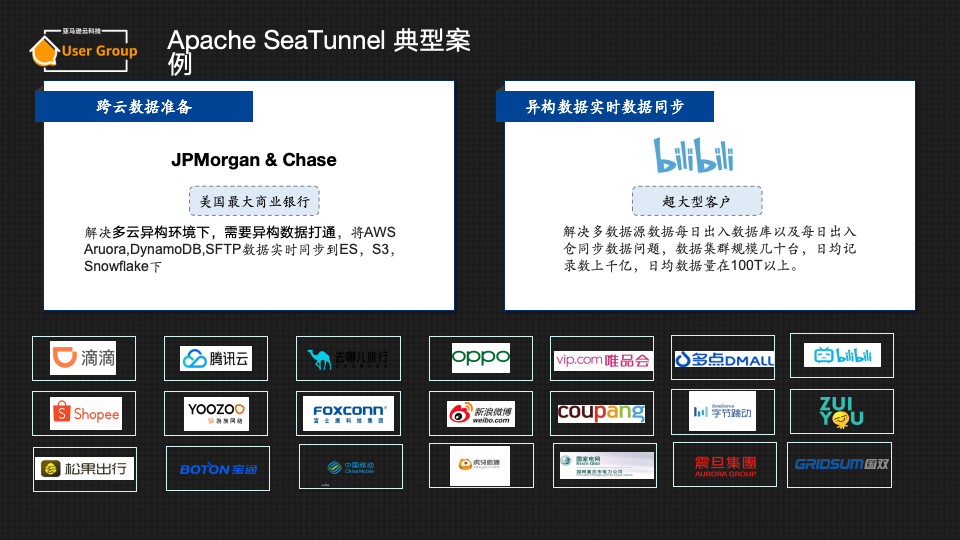
摩根大通银行是一家全球知名的拥有超过 200,000 名员工的金融巨头,其中包括 30,000 多名数据专业人员(工程师、分析师、科学家和顾问),正在与复杂的遗留系统和新兴的数据环境作斗争。该机构在 10 多个不同的数据平台组成的迷宫中运营,需要一种强大、安全且高效的数据集成方法。
对摩根大通银行来说,最重要的挑战是通过复杂的隐私和访问控制对数据进行摄取和处理,这虽然对于数据保护至关重要,但通常会延迟数据集成过程。再加上该公司向AWS的过渡阶段(两年后仍在进行中),以及对Snowflake等现代数据库解决方案的实验,对灵活的数据集成解决方案的需求很迫切。
在追求敏捷性的过程中,摩根大通银行对比了若干流行的数据同步产品,比如Fivetran、Airbyte,但最终选择了支持Spark集群来实现最佳性能的替代方案——Apache SeaTunnel。
原因就在于SeaTunnel与其现有的Spark基础设施兼容,一个关键优势是Apache SeaTunnel与Java代码库的无缝集成,允许从摩根大通银行的主要编码环境直接触发数据迁移作业。摩根大通银行利用SeaTunnel从 Oracle、DB2、PostgreSQL、DynamoDB和 SFTP文件等源获取数据,在Spark集群上处理数据,并最终将其加载到S3(摩根大通银行的集中式数据存储库)中,随后集成到Snowflake和Amazon Athena进行高级分析。
Apache SeaTunnel的一个突出功能是能够显式地处理数据类型转换,确保不同系统之间的数据完整性,这是摩根大通银行银行多元化数据生态系统的重要组成部分。
为什么我们需要Apache SeaTunnel?
既然已经有Flink、Spark等各种流行的数据处理工具存在,为什么我们需要Apache SeaTunnel呢?和摩根大通银行一样,深入了解这个工具,你会发现这个问题并不难回答。
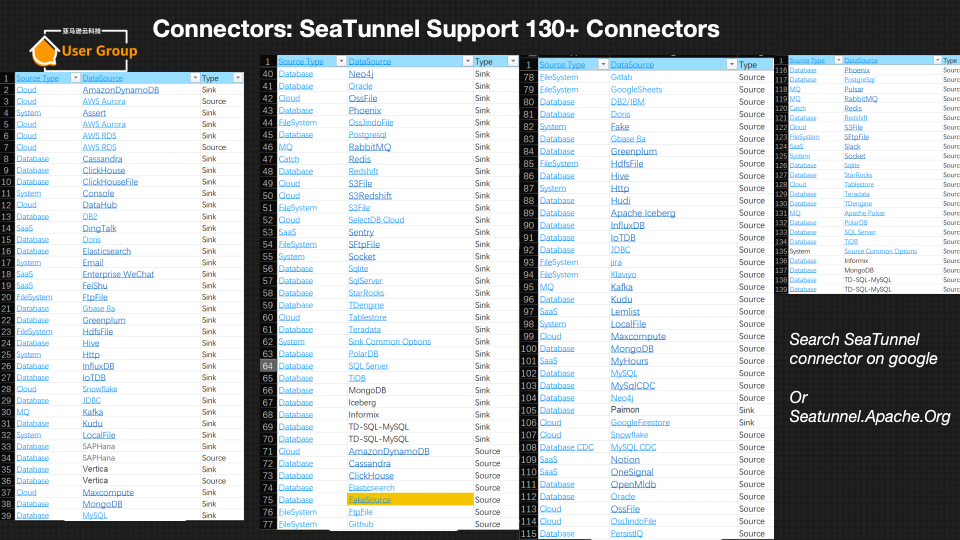
- Apache SeaTunnel支持开发版,目前支持130+ Connectors,商业版产品更是(WhaleTunnel)支持150+种数据库,这是其他产品所无法比拟的;
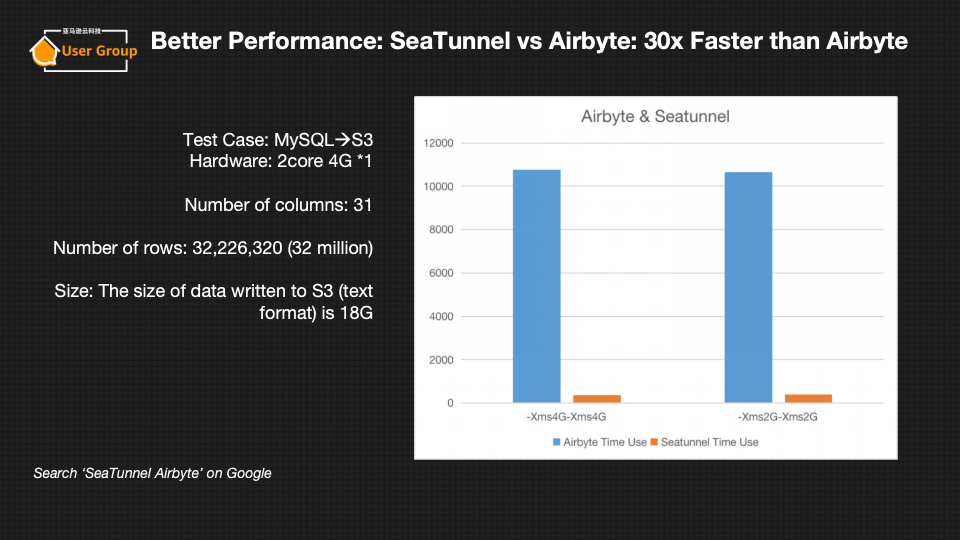
- SeaTunnel性能优势:比Airbyte快30倍,比DataX快30%;(性能报告可参考《最新性能对比报告:SeaTunnel 是 Airbyte 30 倍!》
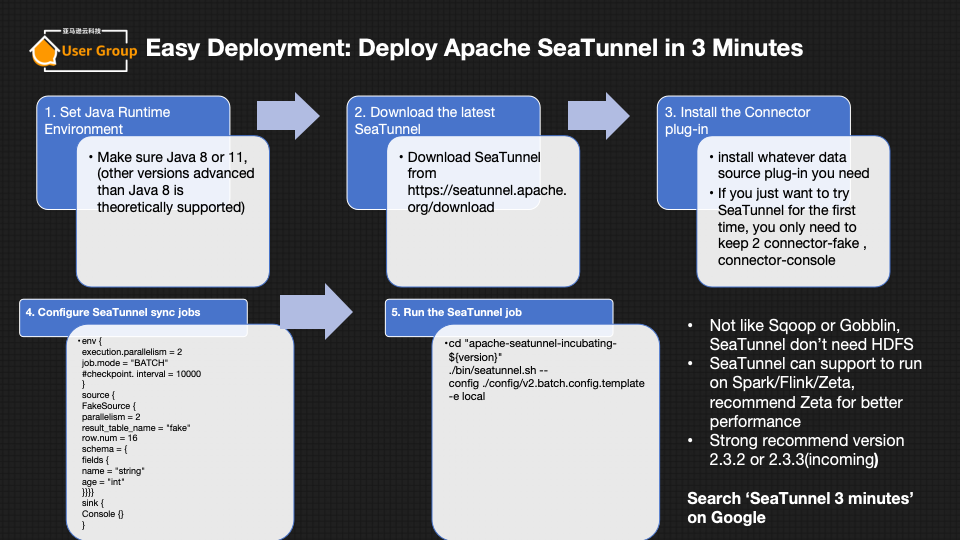
- 易于部署:可以在3分钟内部署Apache SeaTunnel,支持在Spark/Flink/Zeta上运行。
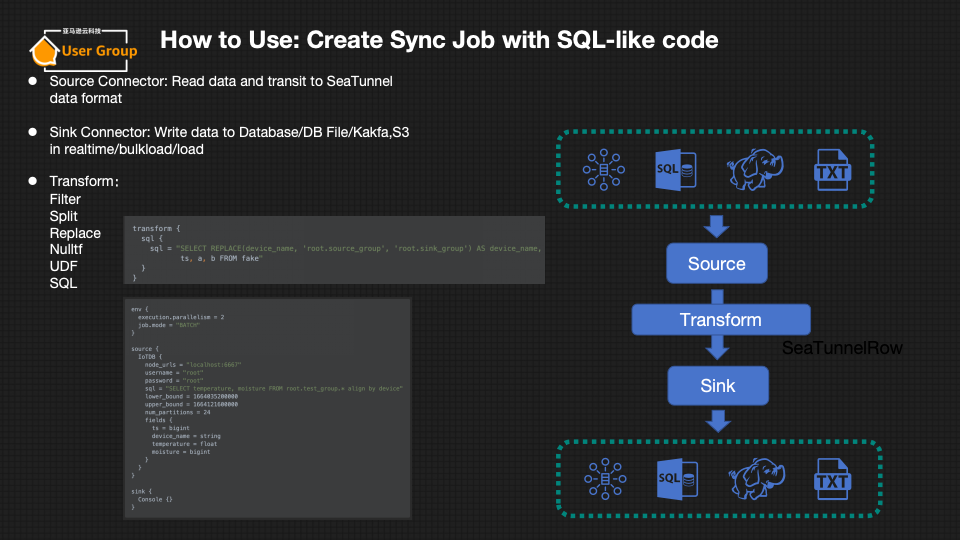
使用方式简单
在使用方式上,Apache SeaTunnel也秉持着为广泛大数据从业者服务为宗旨,使用方式以简单易用为主要设计目标。
- 可以使用SQL-like代码创建同步作业。
- 支持Source Connector、Sink Connector和Transform操作。
想要更简单的方式?AWS Market Place上的WhaleStudio
如果创建代码来进行数据集成对我们来说有挑战,还有更加简单易用的方式可以选择。白鲸开源基于Apache DolphinScheduler和Apache SeaTunnel打造的商业产品WhaleStudio ,是分布式、云原生并带有强大可视化界面的DataOps系统,增加了商业客户所需的企业级特性,零基础用户也可以简单上手:
- 所见即所得的数据Mapping和处理
- 全可视化操作的调度和数据处理,无需代码处理
- 全面兼容AWS及多云、混合云架构
- 多团队协作和开发
- 性能卓越、超过150种数据源的连接,包括
- AWS S3, Aurora, Redshift
- SAP
- Oracle, MySQL
- Hudi, Iceberg
简单来说,WhaleStudio的使用流程和大模型集成可以简单概括为以下几点:
- 数据源连接:首先,需要在WhaleStudio中配置数据源。这包括CSV文件、数据库、云存储服务等。用户可以通过拖放的方式将数据源组件添加到工作流中,并设置连接参数。
- 数据转换:数据在传输过程中可能需要进行清洗和转换以适应目标系统。WhaleStudio提供了多种数据转换工具,包括数据过滤、字段映射、数据合并等。
- 数据加载:转换后的数据需要加载到目标数据库或数据仓库中。WhaleStudio支持多种目标系统,包括关系型数据库、NoSQL数据库和云数据服务。
- API集成:为了使数据能够被大模型理解,需要通过API将数据转换为特定的格式。WhaleStudio可以调用外部API,并将转换后的数据输出到大模型中。
- 流程监控:用户可以实时监控数据流的状态,查看数据同步的进度和任何可能出现的错误。
- 数据同步与更新
- 定时任务:WhaleStudio支持定时任务,允许用户设置在特定时间自动运行数据流,以确保数据的实时更新。
- 数据版本控制:通过版本控制,用户可以追踪数据流的变更历史,并在必要时回滚到之前的版本。
如何将大模型灌入公司内部数据,并“百科全书”化
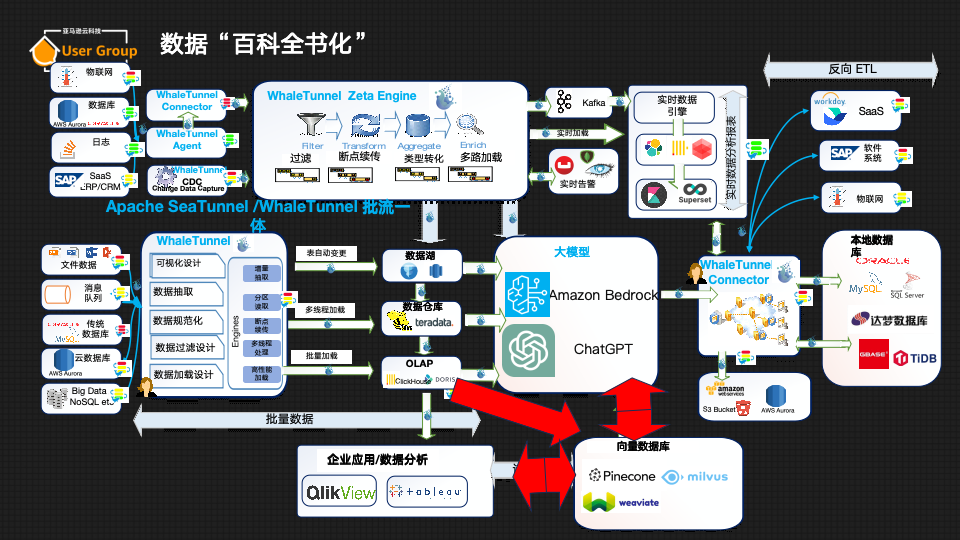
如上文所述数据的“高速公路”有了,那么如何通过“高速公路”将数据放到大模型中并利用呢?
上图以一个示例展示了大模型如何将公司内部数据“百科全书”化的概略图,将MySQL数据库中的所有关于图书的文章,通过图形化的方式输入大模型中,即以向量的方式让大模型理解,并最终将输入的数据以语言的方式进行问答。下面以实战案例详细解说此流程。
实战案例:在AWS上利用WhaleStudio+大模型将图书馆检索从书名检索到语义检索
现有的图书搜索解决方案(例如公共图书馆使用的解决方案)十分依赖于关键词匹配,而不是对书名实际内容的语义理解。因此会导致搜索结果并不能很好地满足我们的需求,甚至与我们期待的结果大相径庭。这是因为仅仅依靠关键词匹配是不够的,因为它无法实现语义理解,也就无法理解搜索者真正的意图。
有更好的方法可以让我们更加准确、高效地进行图书搜索。通过使用特定的API,可以将图书数据转换为大模型能够理解的格式,从而实现语义级别的搜索和问答功能。这种方法不仅提高了搜索的准确性,还为企业提供了一种新的数据利用方式。
WhaleStudio是一个强大的数据集成和处理平台,它允许用户通过图形化界面来设计和实施数据流。WhaleStudio被用于将图书馆的图书数据集成到大模型中,以便进行更深层次的语义搜索和问答。
下面我们来演示一下如何使用WhaleStudio、Milvus和OpenAI进行相似度搜索,实现对整个书名的语义理解,从而让搜索结果更加精准。
准备工作
在实验之前,我们需要去官网获取一个OpenAI的token,
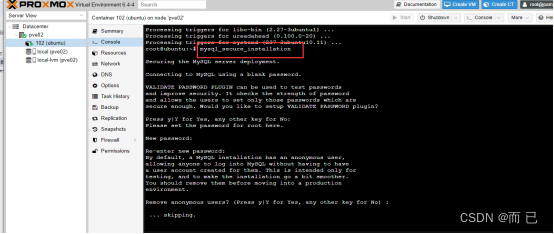
在AWS MarketPlace部署 WhaleStudio
然后部署一个Milvus的实验环境(https://milvus.io/docs/install_standalone-docker.md)。
我们还需要准备好将用于这个例子的数据,可以从这里下载,把它放到/tmp/milvus_test/book下(https://www.kaggle.com/datasets/jealousleopard/goodreadsbooks)
配置WhaleStudio任务
建立项目→新建工作流定义→建立SeaTunel任务→copy脚本到任务里
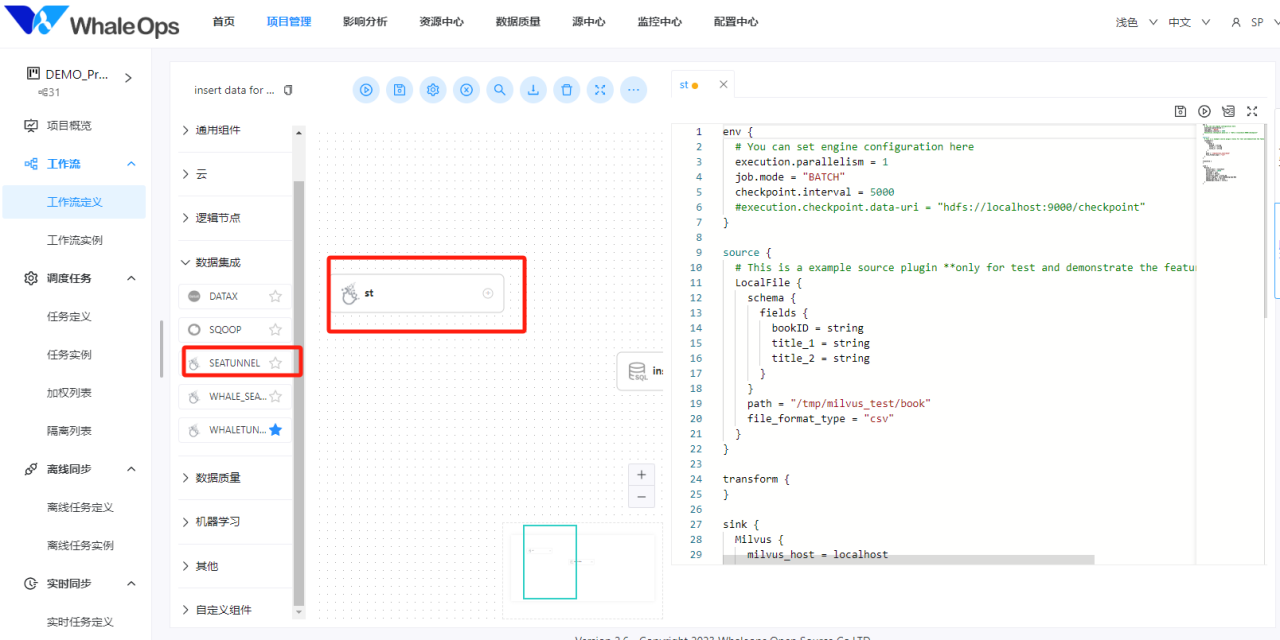
- 脚本代码
env {
# You can set engine configuration here
execution.parallelism = 1
job.mode = "BATCH"
checkpoint.interval = 5000
#execution.checkpoint.data-uri = "hdfs://localhost:9000/checkpoint"
}
source {
# This is a example source plugin **only for test and demonstrate the feature source plugin**
LocalFile {
schema {
fields {
bookID = string
title_1 = string
title_2 = string
}
}
path = "/tmp/milvus_test/book"
file_format_type = "csv"
}
}
transform {
}
sink {
Milvus {
milvus_host = localhost
milvus_port = 19530
username = root
password = Milvus
collection_name = title_db
openai_engine = text-embedding-ada-002
openai_api_key = sk-xxxx
embeddings_fields = title_2
}
}- 点击运行
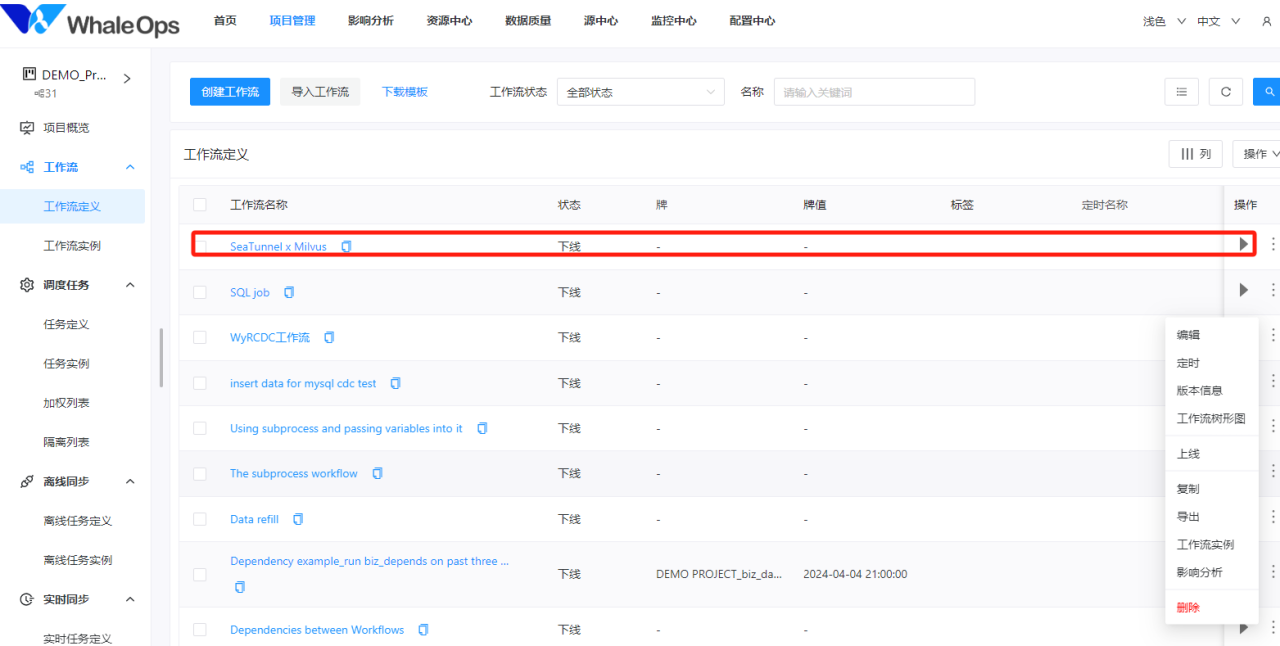
- 简单数据预处理也可以利用可视化界面
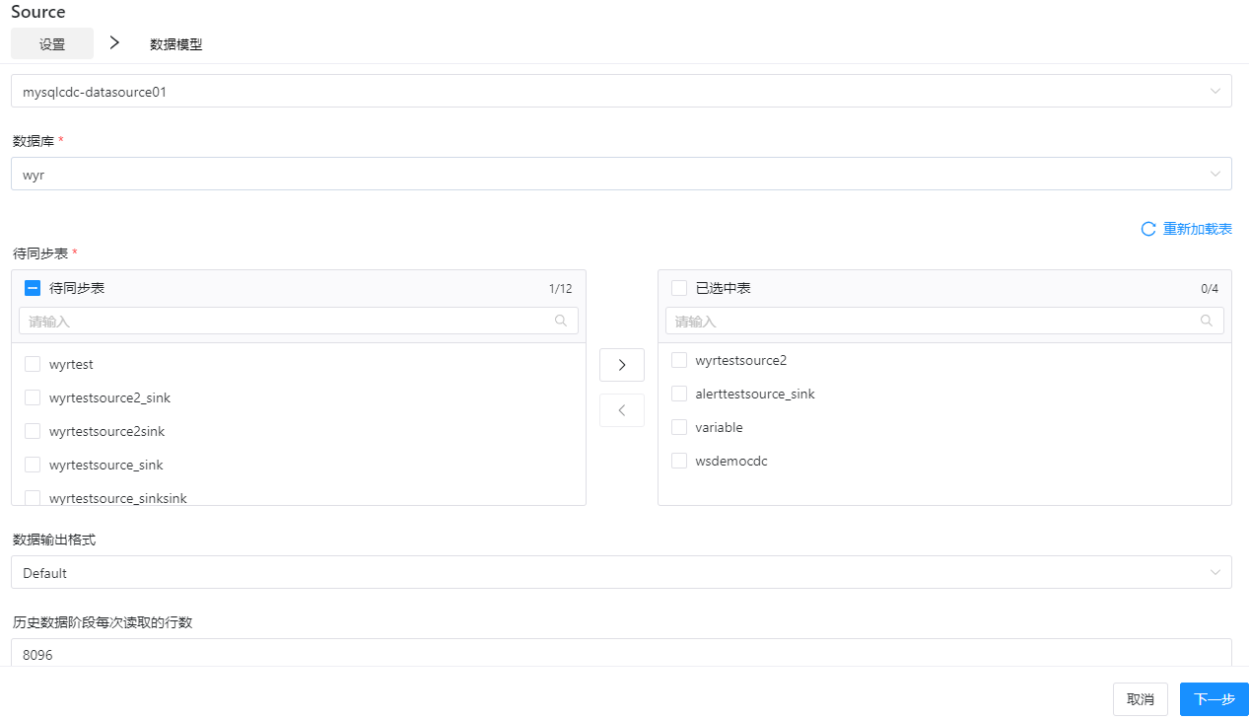
- 查询数据库,确认已经有数据
- 使用如下代码通过语义搜索书名
import json
import random
import openai
import time
from pymilvus import connections, FieldSchema, CollectionSchema, DataType, Collection, utility
COLLECTION_NAME = 'title_db' # Collection name
DIMENSION = 1536 # Embeddings size
COUNT = 100 # How many titles to embed and insert.
MILVUS_HOST = 'localhost' # Milvus server URI
MILVUS_PORT = '19530'
OPENAI_ENGINE = 'text-embedding-ada-002' # Which engine to use
openai.api_key = 'sk-******' # Use your own Open AI API Key here
connections.connect(host=MILVUS_HOST, port=MILVUS_PORT)
collection = Collection(name=COLLECTION_NAME)
collection.load()
def embed(text):
return openai.Embedding.create(
input=text,
engine=OPENAI_ENGINE)["data"][0]["embedding"]def search(text):
# Search parameters for the index
search_params={
"metric_type": "L2"
}
results=collection.search(
data=[embed(text)], # Embeded search value
anns_field="title_2", # Search across embeddings
param=search_params,
limit=5, # Limit to five results per search
output_fields=['title_1'] # Include title field in result
)
ret=[]
for hit in results[0]:
row=[]
row.extend([hit.id, hit.score, hit.entity.get('title_1')]) # Get the id, distance, and title for the results
ret.append(row)
return ret
search_terms=['self-improvement', 'landscape']
for x in search_terms:
print('Search term:', x)
for result in search(x):
print(result)
print()- 运行结果
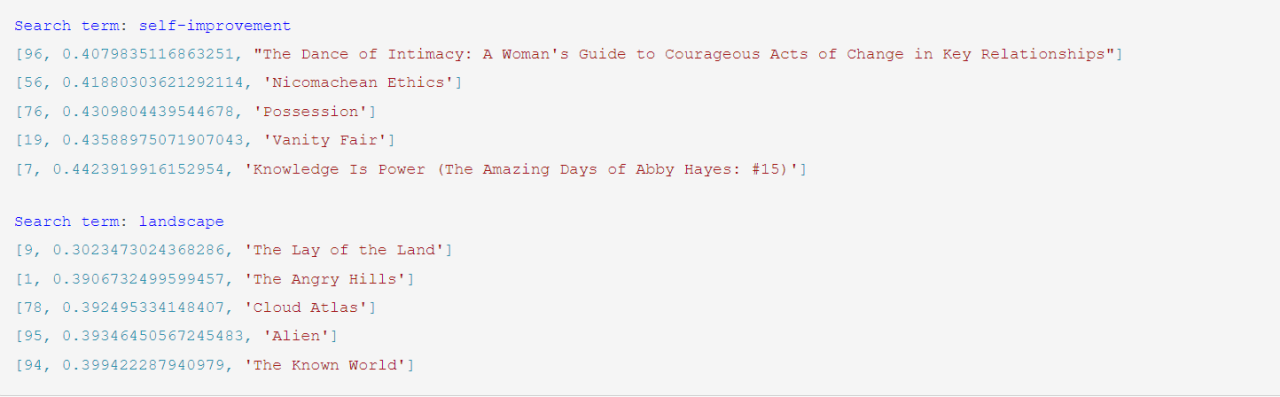
结果: 如果我们按照之前的老方法关键词搜索,书名中必须包含自我提升、提升等关键词;但是提供大模型进行语义级别的理解,则可以检索到更加符合我们需求的书名。比如在上面的例子中,我们搜索的关键词为self-improvement(自我提升),展示的书名《关系之舞:既亲密又独立的相处艺术》、《尼各马可伦理学》等虽然不包含相关关键词,却很明显更加符合我们的要求。
结语
大数据和大模型为企业提供了前所未有的数据处理能力和洞察力。通过有效的数据架构设计、大模型集成、实时与批量数据处理以及数据同步,企业可以更好地利用其数据资源,提升运营效率,并在竞争激烈的市场中保持领先。
Apache SeaTunnel和WhaleStudio作为企业数据高速公路,帮助快速对接企业内部数据,实现数据的向量化和“百科全书化”。其中,WhaleStudio作为一个数据集成工具,为企业提供了一个简单、高效且功能强大的解决方案,让企业可以轻松地将数据同步到大模型中,实现更深层次的数据分析和应用,从而提升企业的数据处理能力和业务洞察力。
本文由 白鲸开源科技 提供发布支持!