一、目录
- flash attention
- GPU运算流程
- flash attention 原理
- flash attention 与 standard attention 时间/内存 对比。
- flash attention 算法实现
- 比较flash attention 计算、memory-efficient attention 等不同内核下用时
二、实现
-
flash attention
目的: 提高运行速度,减少内存消耗。 -
GPU运算流程
见gpu 入门篇 -
flash attention 原理
3.1 原理:
flashAtention其加速的原理是非常简单的,也是最基础和常见的系统性能优化的手段,即通过利用更高速的上层存储计算单元,减少对低速更下层存储器的访问次数,来提升模型的训练性能。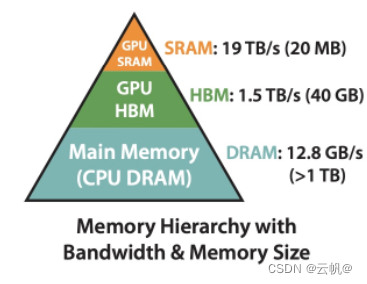
图片代表的为带宽大小与内存大小的关系,即从上面的数字可以看出SRAM的访问速率是HBM的10倍左右,然而其能承载的数据量却远远小于HBM。
CPU 内存大小》GPU 高带宽内存>>GPU SRAM(静态内存)
GPU SRAM速度>>GPU 高带宽 显存>>CPU 内存速度
3.2. 创新点:将flashAttention 计算过程由HBM 转为SRAM 中,减少访问次数。
3.3. 标准attention 计算方法 与flashAttention 计算方法
标准attention计算:
首先,从HBM中读取完整的Q和K矩阵(每个大小为N x d),计算点积得到相似度得分S(大小为N x N),需要进行O(Nd + N^2)次HBM访问。
其次,计算注意力权重P(大小为N x N)时,需要对S进行softmax操作,这需要进行O(N^2)次HBM访问。
最后,将注意力权重P和值向量V(每个大小为N x d)加权求和得到输出向量O(大小为N x d)时,需要进行O(Nd)次HBM访问。
标准 Attention 算法的总HBM访问次数为O(Nd + N^2)
flashAttention计算:
将原始的注意力矩阵分解成更小的子矩阵,然后分别对这些子矩阵进行计算,只要这个子矩阵的大小可以在SRAM内存放,就可以在计算过程中只访问SRAM。
计算过程中要尽量的利用SRAM进行计算,避免访问HBM操作。
3.4. 什么时候使用HBM,什么时候使用SRAM?
编程时,人为指定SRAM空间。 -
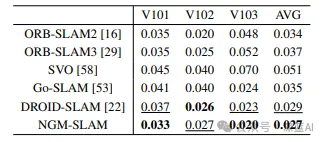
flash attention 与 standard attention 时间/内存 对比。
参考:https://zhuanlan.zhihu.com/p/638468472
以 batch=32, seq_len=512, n_head=16,head_dim=64 为例,记录flash attention 与standard attention 时间/内存对比。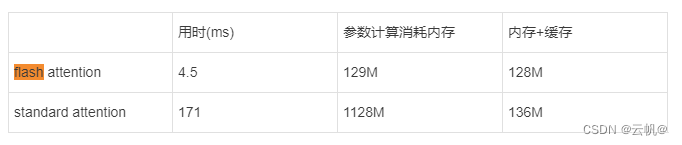 flash attention实现:
flash attention实现:
import torch
from xformers import ops as xops
import time
bs = 32
seq_len = 512
n_head = 16
head_dim = 64
query_states = torch.randn((bs, n_head, seq_len, head_dim), dtype=torch.float16).to("cuda:0")
key_states = torch.randn((bs, n_head, seq_len, head_dim), dtype=torch.float16).to("cuda:0")
value_states = torch.randn((bs, n_head, seq_len, head_dim), dtype=torch.float16).to("cuda:0")
flash_query_states = query_states.transpose(1, 2)
flash_key_states = key_states.transpose(1, 2)
flash_value_states = value_states.transpose(1, 2)
start_time = time.time()
#xformers 实现的注意力机制, 加速框架
flash_attn_output = xops.memory_efficient_attention(
flash_query_states, flash_key_states, flash_value_states,
attn_bias=xops.LowerTriangularMask()
)
print(f'flash attention time: {(time.time()-start_time)*1000} ms')
print(torch.cuda.max_memory_allocated("cuda:0")/1024**2) #192M
print("=============================")
print(torch.cuda.memory_allocated("cuda:0")/1024**2) #128M
standard attention 实现:
import torch
from xformers import ops as xops
import time
bs = 32
seq_len = 512
n_head = 16
head_dim = 64
query_states = torch.randn((bs, n_head, seq_len, head_dim), dtype=torch.float16).to("cuda:0")
key_states = torch.randn((bs, n_head, seq_len, head_dim), dtype=torch.float16).to("cuda:0")
value_states = torch.randn((bs, n_head, seq_len, head_dim), dtype=torch.float16).to("cuda:0")
flash_query_states = query_states.transpose(1, 2)
flash_key_states = key_states.transpose(1, 2)
flash_value_states = value_states.transpose(1, 2)
start_time = time.time()
import math
import torch.nn as nn
attention_mask = torch.tril(torch.ones((seq_len, seq_len), dtype=torch.bool)).view(1, 1, seq_len, seq_len)
attention_mask = attention_mask.to(dtype=torch.float16).cuda() # fp16 compatibility
attention_mask = (1.0 - attention_mask) * torch.finfo(torch.float16).min #数据类型
def standard_attention(query_states, key_states, value_states, attention_mask):
attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(head_dim)
attn_weights = attn_weights + attention_mask
# upcast attention to fp32
attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)
attn_output = torch.matmul(attn_weights, value_states)
attn_output = attn_output.transpose(1, 2)
return attn_output
start_time = time.time()
attn_output = standard_attention(query_states, key_states, value_states, attention_mask)
print(f'standard attention time: {(time.time()-start_time)*1000} ms')
#print(torch.allclose(attn_output, flash_attn_output, rtol=2e-3, atol=2e-3)) #判断两个张量是否接近相等(计算机计算的不精确性,完全相等的浮点数可能存在微小差异)
print(torch.cuda.max_memory_allocated("cuda:0")/1024**2) #1128M
print("=============================")
print(torch.cuda.memory_allocated("cuda:0")/1024**2) #136M
- flash attention 算法
参考:https://blog.csdn.net/qinduohao333/article/details/131449876FlashAttention
算法实现的关键在于以下三点:
1 softmax的tiling展开,可以支持softmax的拆分并行计算,从而提升计算效率
2 反向过程中的重计算,减少大量的显存占用,节省显存开销。
3 通过CUDA编程实现fusion kernel
参数了解:
SRAM:静态显存。嵌入在GPU芯片上的SRAM存储器。
HBM:高带宽内存。使得GPU能够更快地读取和写入数据。
DRAM: 动态显存。嵌入在CPU芯片上的DARM存储器。
所以:读写速度 SRAM>HBM>DRAM.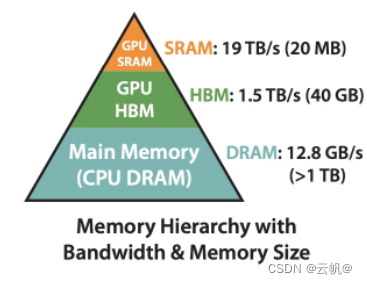
- 比较flash attention 计算、memory-efficient attention 等不同内核下用时
参考:https://blog.51cto.com/u_15293476/6131364
用时比较: 内核下torch 实现>不指定内核下torch 实现> 内核下flash attention> 内核下 efficient attention.
import torch
import torch.nn.functional as F
from rich import print
from torch.backends.cuda import sdp_kernel #内核计算
from enum import IntEnum
import torch.utils.benchmark as benchmark
device = "cuda" if torch.cuda.is_available() else "cpu" #cudnn 需要使用gpu
# 超参数定义
batch_size = 64
max_sequence_len = 256
num_heads = 32
embed_dimension = 32
dtype = torch.float16
# 模拟 q k v
query = torch.rand(batch_size, num_heads, max_sequence_len, embed_dimension, device=device, dtype=dtype)
key = torch.rand(batch_size, num_heads, max_sequence_len, embed_dimension, device=device, dtype=dtype)
value = torch.rand(batch_size, num_heads, max_sequence_len, embed_dimension, device=device, dtype=dtype)
# 定义一个计时器:
def torch_timer(f, *args, **kwargs):
t0 = benchmark.Timer(
stmt="f(*args, **kwargs)", globals={"args": args, "kwargs": kwargs, "f": f}
)
return t0.blocked_autorange().mean * 1e6
# torch.backends.cuda中也实现了,这里拿出了为了好理解backend_map是啥
class SDPBackend(IntEnum):
r"""
Enum class for the scaled dot product attention backends.
"""
ERROR = -1
MATH = 0
FLASH_ATTENTION = 1
EFFICIENT_ATTENTION = 2
# 使用上下文管理器context manager来
# 其他三种方案,字典映射
backend_map = {
SDPBackend.MATH: { #启用pytorch 实现
"enable_math": True,
"enable_flash": False,
"enable_mem_efficient": False},
SDPBackend.FLASH_ATTENTION: { #启用flashattention
"enable_math": False,
"enable_flash": True,
"enable_mem_efficient": False},
SDPBackend.EFFICIENT_ATTENTION: { #启用memory_efficient attention
"enable_math": False,
"enable_flash": False,
"enable_mem_efficient": True}
}
# 基本版,不指定
print(f"基本对照方案 运行时间: {torch_timer(F.scaled_dot_product_attention, query, key, value):.3f} microseconds")
# 基本对照方案 运行时间: 558.831 microseconds
#内核中运行
with sdp_kernel(**backend_map[SDPBackend.MATH]):
print(f"math 运行时间: {torch_timer(F.scaled_dot_product_attention, query, key, value):.3f} microseconds")
# math 运行时间: 1013.422 microseconds
with sdp_kernel(**backend_map[SDPBackend.FLASH_ATTENTION]):
try:
print(f"flash attention 运行时间: {torch_timer(F.scaled_dot_product_attention, query, key, value):.3f} microseconds")
except RuntimeError:
print("FlashAttention is not supported")
# flash attention 运行时间: 557.343 microseconds
with sdp_kernel(**backend_map[SDPBackend.EFFICIENT_ATTENTION]):
try:
print(f"Memory efficient 运行时间: {torch_timer(F.scaled_dot_product_attention, query, key, value):.3f} microseconds")
except RuntimeError:
print("EfficientAttention is not supported")
# Memory efficient 运行时间: 428.007 microseconds