大家好,我是不温卜火,昵称来源于成语—
不温不火,本意是希望自己性情温和。

PS:由于现在越来越多的人未经本人同意直接爬取博主本人文章,博主在此特别声明:未经本人允许,禁止转载!!!
目录
- 一、网页分析
- 二、内容解析
- 三、完整代码
- 四、运行结果
一、网页分析
在前几篇文章中,虽然已经有过用正则表达式解析数据的案例,但是个人感觉干货不够!所以,本次博主诚意满满的再次带来一篇博文~

下面博主先给出要爬取网页的网址:https://www.taobao.com/markets/3c/tbdc?spm=a217h.9580640.831011.1.1aa525aaKXwn5M
打开网页之后,我们可以看到网页是这样的:
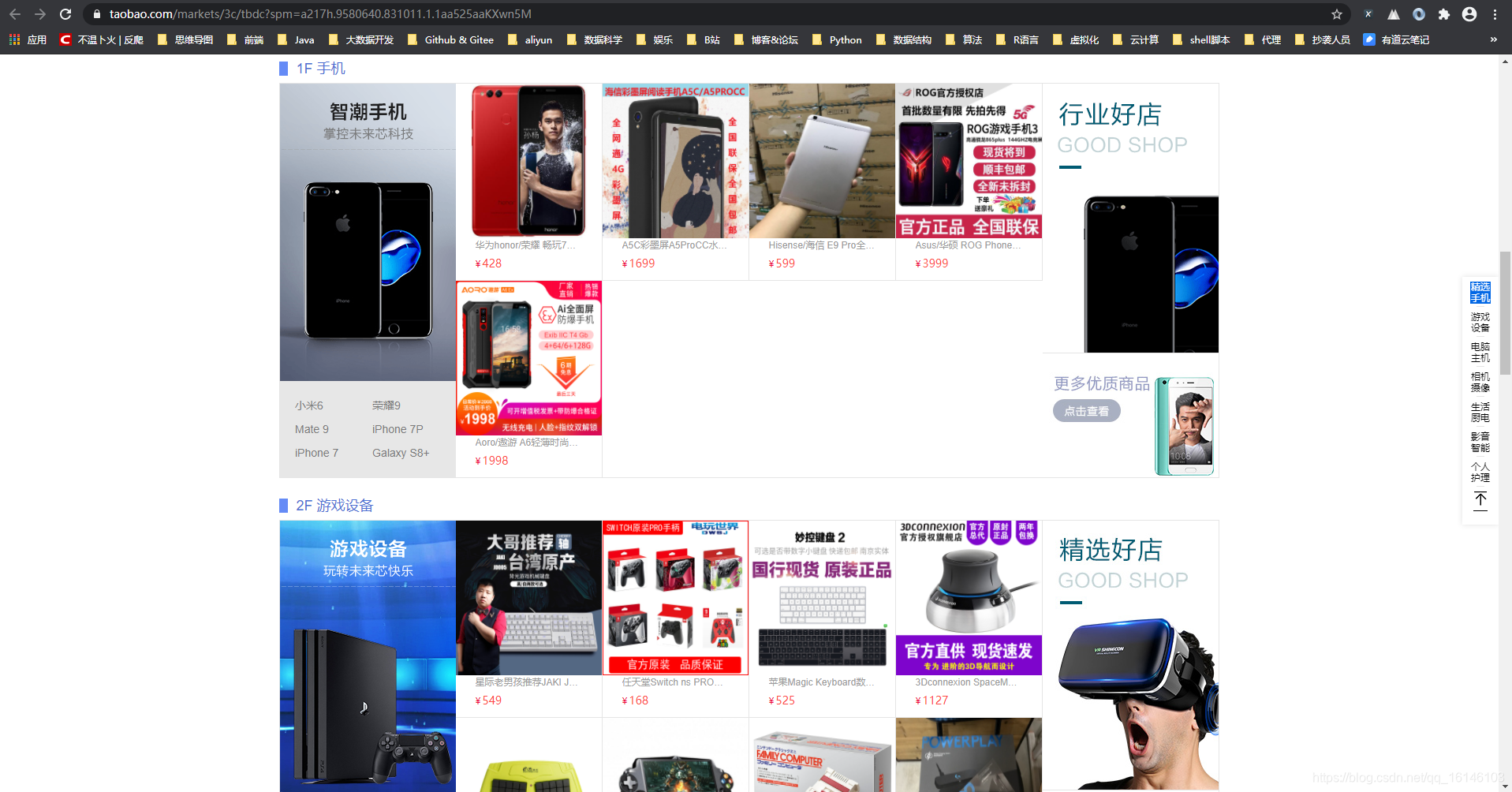
看到网页之后,下面我们就需要开始分析网页结构,首先,先通过打开开发者选项,查看网页结构。我们通过查看发现,此网页是静态网页,看到此结构的第一时间,博主先使用了xpath进行解析。

通过解析,博主发现是可行的。但是!既然说了,使用正则进行解析,怎么能为了偷懒就换用xpath呢?所以博主毅然的放弃了xpath。

但是如果使用正则的话,我们会发现, 我们需要找其他的URL。但是我们通过查看传统的NetWork无法找到我们需要的URL。
在这种时候我们可以通过开发者工具中的Sreach查找关键字:

我们看到网页中有关键字,如荣耀 畅玩7。我们以此为突破口,进行问题的切入

通过上图,我们可以知道此部分就是咱们要找的URL,这个时候我们只需点击Headers 就可以看到我们需要的URL

我们看到此网页共有七个模块,所以我们需要找到7个URL, 由于找其他URL的过程和举例是一样的,博主在此只给出URL。

url1 = "https://drc.alicdn.com/7/1870316_2____?callback=jsonp1870316_2____"
url2 = "https://drc.alicdn.com/7/1870321_2____?callback=jsonp1870321_2____"
url3 = "https://drc.alicdn.com/7/1870333_2____?callback=jsonp1870333_2____"
url4 = "https://drc.alicdn.com/7/1870340_2____?callback=jsonp1870340_2____"
url5 = "https://drc.alicdn.com/7/1870341_2____?callback=jsonp1870341_2____"
url6 = "https://drc.alicdn.com/7/1870342_2____?callback=jsonp1870342_2____"
url7 = "https://drc.alicdn.com/7/1870343_2____?callback=jsonp1870343_2____"
二、内容解析
需要的网址已经搞到了,下面当然是要解析网页了:

根据上图,我们可以看到价格、图片、标题、链接。
通过观察,我们发现是有规律的,我们只需(.*?)即可获取我们所需要的内容。 代码如下
# 获取数据
title_list = re.findall(r'"item_title":"(.*?)"', content)
price_list = re.findall(r'"item_current_price":"(.*?)"', content)
pic_list = re.findall(r'"item_pic":"(.*?)"', content)
url_list = re.findall(r'"item_url":"(.*?)"', content)
获取之后,别忘了使用zip()压缩一下数据
# 压缩数据
data_zip = zip(title_list, price_list, pic_list, url_list)
# 循环
for data in data_zip:
items.append(data)
最后,我们可以看到输出的格式如下图:

你以为这样就完了嘛!

我们现在只是获取了基本信息。在网页解析中,我们可以看到item_pic内有图片链接,我们可以打开看是不是我们想要保存的图片

复制到空白处,我们看下这个链接
http://gw.alicdn.com/bao/uploaded/i4/840091576/O1CN018aiCuF1NVqjqpMNB4_!!840091576.jpg
通过观察,我们可以看到需要添加http:
完整代码如下:
# 拼接成完整URL
content = parse_url("http:" + url)
print(content)

三、完整代码
# encoding: utf-8
'''
@author 李华鑫
@create 2020-10-07 14:46
Mycsdn:https://buwenbuhuo.blog.csdn.net/
@contact: 459804692@qq.com
@software: Pycharm
@file: 淘宝商品信息.py
@Version:1.0
'''
import requests
import time
import random
import re
import csv
import os
"""
https://s.taobao.com/search?q=%E5%8D%8E%E4%B8%BA&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.2017.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306&bcoffset=6&ntoffset=6&p4ppushleft=1%2C48&s=0
"""
url1 = "https://drc.alicdn.com/7/1870316_2____?callback=jsonp1870316_2____"
url2 = "https://drc.alicdn.com/7/1870321_2____?callback=jsonp1870321_2____"
url3 = "https://drc.alicdn.com/7/1870333_2____?callback=jsonp1870333_2____"
url4 = "https://drc.alicdn.com/7/1870340_2____?callback=jsonp1870340_2____"
url5 = "https://drc.alicdn.com/7/1870341_2____?callback=jsonp1870341_2____"
url6 = "https://drc.alicdn.com/7/1870342_2____?callback=jsonp1870342_2____"
url7 = "https://drc.alicdn.com/7/1870343_2____?callback=jsonp1870343_2____"
urls = [url1, url2,url3,url4,url5,url6,url7]
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36",
}
items = []
def parse_url(url):
"""解析url,得到响应内容"""
time.sleep(random.random() * 3)
response = requests.get(url=url, headers=headers)
return response.content
def parse_content(content):
"""解析响应内容,返回数据"""
# 获取数据
title_list = re.findall(r'"item_title":"(.*?)"', content)
price_list = re.findall(r'"item_current_price":"(.*?)"', content)
pic_list = re.findall(r'"item_pic":"(.*?)"', content)
url_list = re.findall(r'"item_url":"(.*?)"', content)
# 压缩数据
data_zip = zip(title_list, price_list, pic_list, url_list)
# 循环
for data in data_zip:
items.append(data)
def save():
"""保存数据"""
with open("./files/淘宝/淘宝.csv", "a", encoding="utf-8") as file:
writer = csv.writer(file)
for item in items:
writer.writerow(item)
save_img(item[2], item[0])
def save_img(url, title):
"""保存图片"""
# 获取字节
content = parse_url("http:" + url)
# 处理name
if title.rfind("/") != -1:
title = title.split("/")[-1]
name = title + os.path.splitext(url)[-1]
# 文件写
with open("./files/淘宝/img/{}".format(name), "wb") as file:
file.write(content)
def start():
"""开始爬虫"""
if not os.path.exists("./files/淘宝/img"):
os.makedirs("./files/淘宝/img")
for url in urls:
print(url)
content = parse_url(url).decode("utf-8")
parse_content(content)
save()
if __name__ == '__main__':
start()
四、运行结果



美好的日子总是短暂的,虽然还想继续与大家畅谈,但是本篇博文到此已经结束了,如果还嫌不够过瘾,不用担心,我们下篇见!

好书不厌读百回,熟读课思子自知。而我想要成为全场最靓的仔,就必须坚持通过学习来获取更多知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
如果我的博客对你有帮助、如果你喜欢我的博客内容,请“点赞” “评论”“收藏”一键三连哦!听说点赞的人运气不会太差,每一天都会元气满满呦!如果实在要白嫖的话,那祝你开心每一天,欢迎常来我博客看看。
码字不易,大家的支持就是我坚持下去的动力。点赞后不要忘了关注我哦!