目录
1。初始化(好几种方式),npos和string的使用说明
2。string的拷贝,隐式类型转换,[],size,iterator,begin,end,reverse,reverse_iterator,rbegin,rend,const_ iterator
3。算法库中sort的使用
4。push_back,append,+=,typeid
5。assign,insert,erase,replace,reserve,capacity,max_size,resize
6。find,rfind,substr,+,<,>,getline,to_string,stoi
7。全中文或者有中文的字符串大小说明
8。shrink_to_fit,at,c_str,data,copy,get_allocator,compare,find_first_of,find_first_not_of,find_last_not_of,find_last_of
9。swap
10。string类(及其部分好用的比较有意义的功能)的自我实现
本文是对STL库里面的string类及其附带的常见的函数和指令和算法库中sort的使用进行总结,std::string::函数或者指令,可以用于复习和查找。不会很详细,但是肯定非常全面。话不多说,我们现在开始

1。初始化(好几种方式),npos和string的使用说明
#include<iostream>
using namespace std;
//using std::string;//npos作为string类里的静态成员变量只会在全局找,类名 :: 静态成员变量名,这个就是类名访问静态成员的语法
#include<string>//string的头文件, 包括了就可以用里面的函数和string和这个类型
//string表示是字符数组,可以扩容,可以增删查改
int main()
{
//常用的数组构造方式
string s1;//构造一个名叫s1的字符数组
string s2("abcd");//构造一个成员为abcd的字符数组s2,直接在名字后面加(内容),就是用类的构造方式
string s3(s2);//拷贝构造s3
// 不常用 了解
string s4(s2, 1, 3);//将s2从下标位置1到下标位置3的字符都拷贝到s4,也是一种构造方式
string s5(s2, 1, string::npos);//规定位置拷贝构造的最大范围的右边界为npos,及整型的最大值,也就是最后一个参数的最大值
//npos在string这个类里,所以要包含一下这个类才可以用
string s6(s2, 1);//如果指定拷贝的范围太大或者没有右范围,就会只拷贝可以拷贝的最大的长度到\0之前,及最后一个参数可以不写或者写很大但不超过npos
string s7("sdsgsfgsg");
string s8(s7, 1, 100);
//string s9(s7, 100);//但是拷贝的范围的其实位置不可以越界
string s10("hello word", 5);//拷贝前面那个字符串的前5个字节,然后给s10
//string s11("hello word", 100);//如果读取的数据个数大于字符串的长度就会越界读取无效的数据,就会读取到别的东西
//所以读取数据个数不可以大于待读取字符串的长度
string s12(10, 'x');//创建10个x字符给s12
//string s13(10, 3);//一定要是字符才可以被写入,不然是打印不出东西的,也不会报错的
//cout << s2 << endl;
//cout << s3 << endl;
//cout << s4 << endl;
//cout << s5 << endl;
//cout << s7 << endl;
//cout << s8 << endl;
//cout << s9 << endl;
//cout << s10 << endl;
//cout << s11 << endl;
cout << s12 << endl;
//cout << s13 << endl;
return 0;
}
2。string的拷贝,隐式类型转换,[],size,iterator,begin,end,reverse,reverse_iterator,rbegin,rend,const_ iterator
#include<iostream>
#include<string>
using namespace std;
void push_back(const string& s)
{
cout << "push_back" << endl;
}
void test_string2()
{
//隐式类型转换,将字符型转换成具有string字符串型的s2
string s2 = "hello word";
const string& s3 = "hello";
push_back(s2);
push_back("hhhh");
}
//class string
//{
//public:
// // 引用返回
// // 1、减少拷贝
// // 2、修改返回对象
// char& operator[](size_t i)
// {
// assert(i < _size);
// return _str[i];
// }
//private:
// char* _str;
// size_t _size;
// size_t _capacity;
//};
//operator[] 符号重载,相当于char& operator[],string里面有一个指针是指向
//你初始化的空间的[],相当于在通过指针调用那快空间的字符,循环调用就是在遍历整个字符串
void test_string3()
{
string s3("hello word");
s3[0] = 'x';//将s3的第一个字符设置成x
for (int i = 0; i < s3.size(); i++)
{
cout << s3[i];//循环通过符号重载[]打印s3
//char ret = s3.operator[](i);//相当于上面这种写法
//cout << ret;
}
//size()是string自带的函数用来计算字符串的长度,可以直接用
//s3.length() 的作用等价于s3.size()
cout << endl;
cout << s3 << endl;
}
//遍历一个字符串的方法
//法一:用符号重载[]
//主流写法
void test_string4()
{
string s4 = "hello word";
for (size_t i = 0; i < s4.size(); i++)
{
cout << s4[i] << " ";
}
cout << endl;
}
//法2:运用迭代器iterator,iterator在string这个类里所以要指定类域才可以访问到
//迭代器iterator本身也是一种数据类型
void test_string5()
{
string s5 = "hello word";
string::iterator it = s5.begin();//begin()是因为begin是函数所以要加括号,可以直接调用,其他也类似
//auto it = s5.begin();//可以用自动推导类型auto,前提是你知道it的具体类型是iterator
//begin是任何容器包括string的第一个数据位置的iterator,然后将它返回用一个数据类型为iterator的变量接收
//end是任何容器包括string的最后一个数据的下一个数据位置的iterator,然后将它返回用一个数据类型为iterator的变量接收
while (it != s5.end())
{
cout << *it;
cout << " ";
it++;
}
cout << endl;
//迭代器it相当于指针,但不一定是指针,有指针的作用,开头先指向第一个元素,取完一个元素就++取下一个
}
//方法3:范围for
// 底层角度,他就是迭代器
void test_string6()
{
string s6("hello word", 10);//只有赋值才有等号
for (auto i : s6)
{
cout << i;//比iterator方便的是i会自己++,自己停止
cout << " ";
}
cout << endl;
}
void test_string7()
{
string s6("hello word", 10);//只有赋值才有等号
for (auto& i : s6)
{
i++;
cout << i;//比iterator方便的是i会自己++,自己停止
cout << " ";
}
cout << endl;
}
void test_string8()
{
const string s5 = "hello word";//如果字符串s5加上了const,就相当于字符串的值不可改变
string::const_iterator it = s5.begin();//begin()是因为begin是函数所以要加括号,可以直接调用,其他也类似
//auto it = s5.begin();//可以用自动推导类型auto,前提是你知道it的具体类型是iterator
//begin是任何容器包括string的第一个数据位置的iterator,然后将它返回用一个数据类型为iterator的变量接收
//end是任何容器包括string的最后一个数据的下一个数据位置的iterator,然后将它返回用一个数据类型为iterator的变量接收
while (it != s5.end())
{
//*it += 3;//const_iterator相对应的使用迭代器的类型也要加上const_以限制指针it指向的值发生改变
//所以*it += 3是会报错的,所以迭代器类型是有两个版本的,有没有const_
//为什么是const_而不是const
//因为:iterator是可读可写的
// const iterator是指迭代器本身不能写(修改指向)
// const_ iterator是指迭代器指向的内容不能写(修改数值)
cout << *it;
cout << " ";
it++;
}
cout << endl;
//迭代器it相当于指针,但不一定是指针,有指针的作用,开头先指向第一个元素,取完一个元素就++取下一个
}
//reverse 逆制字符串
//搭配iterator使用,需要使用迭代器进行变量组成reverse_iterator, 此为数据类型
void test_string9()
{
string s9 = "hello word";
//const string s9 = "hello word";
string::reverse_iterator it2 = s9.rbegin();
//string::const_reverse_iterator cit1 = s9.rbegin();//const版本
//auto cit1 = s9.rbegin();
//rbegin是任何容器包括string的最后一个数据位置的iterator,然后将它返回用一个数据类型为reverse_iterator的变量接收
//rend是任何容器包括string的头一个数据的上一个数据位置的iterator,然后将它返会用一个数据类型为reverse_iterator的变量接收
while (it2 != s9.rend())
{
//*it2 += 3;
cout << *it2 << " ";
++it2;//逆序变历,从尾到头,尾为第一个数据,逆着变量上去所以还是++
}
cout << endl;
}
int main()
{
//test_string2();
//test_string3();
//test_string4();
//test_string5();
//test_string6();
//test_string7();
//test_string8();
//test_string9();
return 0;
}
//二叉树
//template<class T>
//struct ListNode
//{
// ListNode<T>* _next;
// ListNode<T>* _prev;
// T _data;
//};
//
//template<class T>
//class list
//{
//private:
// ListNode<T>* _head;
//};
3。算法库中sort的使用
#include<iostream>
using namespace std;
#include<algorithm>//使用算法如sort快速排序的头文件,包括了就可以直接使用了
int main()
{
string s1 = "hello wordff";
string s2("hhfheef");
// sort的作用是将任意数据如s1里的每个字符按字典序排序
//排序时传入一个待排序的区间的头尾下标的iterator(指针)就可以了,传入的区间下标的iterator是左闭右开的,sort底层会自己通过iterator编译出值
//[0, 13)
sort(s1.begin(), s1.end());
//[0, 5) 排列前5个数
sort(s2.begin(), s2.begin() + 5);
cout << s1 << endl;
cout << s2 << endl;//打印的还是整个字符串
return 0;
}
4。push_back,append,+=,typeid
#include<iostream>
#include<string>
using namespace std;
void test_string7()
{
string s1 = "hello word";
string s2 = "hello word";
string s3 = "hello word";
s1.push_back('x');// push_back属于string这个类里面的函数可以直接调用
// push_back的作用为将一个字符尾插到一个字符串上面
//s1.push_back("daf"); //push_back只能尾插字符不可以尾插字符串
cout << s1 << endl;
s2.append("dffawf");// append属于string这个类里面的函数可以直接调用
// append的主流的作用(用法)为将一个字符串尾插到一个字符串上面
//s2.append('s');// append不能直接尾插一个字符
s3 += "sss";// +=为string的符号重载,作用为尾插字符或者字符串到一个字符串上面(比较好用)
s3 += 'p';
s3 += s2;// += 可以用在string和string之间
cout << s2 << endl;
cout << s3 << endl;
//push_back += append都是尾插
}
void test_string8()
{
cout << typeid(std::string::iterator).name() << endl;//获取变量名称
string s2("hello world");
cout << sizeof(s2) << endl;
//typeid是操作符,不是函数,这点与sizeof类似,typeid的作用是
//运行时获取变量类型名称,一般(可以)使用typeid(变量).name()
//不是所以编译器使用typeid都可以输出“int” “double”等之类的名称
}
int main()
{
test_string7();
test_string8();
return 0;
}
5。assign,insert,erase,replace,reserve,capacity,max_size,resize
#include<iostream>
#include<string>
using namespace std;
void test_string8()
{
string s1("hello word");
cout << s1 << endl;
s1.assign("111111");
//assign的作用是将原本的字符串变成assign函数括号后面指定的字符串
cout << s1 << endl;
}
void test_string9()
{
string s2 = "hello word";
cout << s2 << endl;
s2.insert(0, "xxx");
//insert的作用就是将给定的字符串或者字符头插到s2的给定位置之前,insert是类里的函数
s2.insert(s2.begin(), 'y');
//如果插入位置之前是类似begin()的这种东西,只能插入字符串
cout << s2 << endl;
char ch = 'k';
string s3("hello bit");
s3.insert(0, 1, 'k');
cout << s3 << endl;
s2.insert(s2.begin(), s3.begin(), s3.end());
//又一种insert的用法,可以看出可以将一个字符串整个弄到另一个字符串的第一个位置
//这种用法可以看到,第一个参数不可以是数字的
//用insert插入字符串时要提供个数
cout << s2 << endl;
//insert慎用,因为效率不高 -> O(N)
// 实践中需求也不高
}
void test_string10()
{
string s2("hello word");
cout << s2 << endl;
s2.erase(0, 2);
//erase的作用是可以删除s2一个左闭右开的区间的字符,然后将此区间后面的字符向前拼接
//其实就是删除字串(其实这一步都不用做的),再合成新的字符串,注意erase的参数是一个左闭右开的区间, 而且用的是下标
cout << s2 << endl;
//如果所给区间的右边超出了s2的最大值那就会默认删除到结尾,此时就没有移动的操作了
s2.erase(5, 100);
//s2.erase(5);
//通过网站可以得到最后一个参数是有缺省值的npos,所以可以不写
cout << s2 << endl;
//erase效率不高,慎用,和insert类似,要挪动数据
}
void test_string11()
{
string s2("hello word");
cout << s2 << endl;
//replace的作用是在字符串的给定位置(不是下标)后面的指定字节个数替换成给定的字符串,所以会使字符串变长,所以是3个参数
//作用和insert刚好相反了
//会发现第二个参数指定要换的字节个数如果给的过于大就会只替换到数组的最大值
s2.replace(5, 1, "%20");
cout << s2 << endl;
//replace效率不高,慎用,和insert类似,要挪动数据
}
void TestPushBack()
{
string s;
// 知道需要多少空间,提前开好
s.reserve(200);
s[100] = 'x';
size_t sz = s.capacity();
cout << "capacity changed: " << sz << '\n';
cout << "making s grow:\n";
for (int i = 0; i < 200; ++i)
{
s.push_back('c');
if (sz != s.capacity())
{
sz = s.capacity();
cout << "capacity changed: " << sz << '\n';
}
}
}
void test_string12()
{
string s1("hello world hello bit");
cout << s1.size() << endl;//字符串的大小没有\0
cout << s1.capacity() << endl;//capacity不一定是字符串的大小, capacity表示的是字符串所占空间的大小,capacity会比较大
cout << s1.max_size() << endl;
for (size_t i = 0; i < s1.max_size(); i++)
{
s1 += 'x';
}
}
void test_string13()
{
string s2("11111111111111111111111111111");
string s3("111111111");
//s2.reserve(100);
//reserve的作用是保留一个字符串s2为指定的空间,就是将字符串设定为reserve指定的空间大小
//就是在给字符串开空间
s2.reserve(20);
cout << s2.capacity() << endl;
s2.reserve(100);
cout << s2.capacity() << endl;//VS通过reserve开的空间会比实际要开的空间大
//s2.reserve(20);
//cout << s2.capacity() << endl;
//通过reserve开空间是不可逆的,就是如果先开了大的空间就无法在通过reserve减小了
}
void test_string14()
{
string s2("hello word");
//resize的功能有两个
//尾插字符x直到字符串长度达到20,只能尾插字符(两个参数)
s2.resize(20, 'x');
cout << s2 << endl;
s2.resize(5);
//尾删字符串,直到字符串长度为5 (一个参数)
cout << s2 << endl;
}
int main()
{
//test_string8();
//test_string9();
//test_string10();
test_string11();
//test_string12();
//test_string13();
//test_string14();
return 0;
}
6。find,rfind,substr,+,<,>,getline,to_string,stoi
#include<iostream>
using namespace std;
#include<string>
void test_string1()
{
string s1("string.cpp.zip");
size_t pos = s1.find('.', 7);
size_t pos2 = s1.find('.', 700);
size_t ret = s1.find('s');
int pp = s1.find('a');
size_t ppp = s1.find('a');
//find就是找的意思,两个参数,只能查找字符,第一个参数为你要查找的字符
//第2个参数为你要从那个下标开始查找,返回值为那个字符在字符串中的下标位置
//如果没有指定要从哪里开始查找就默认从开头开始查找
//如果要查找的字符字符串没有,就会返回-1
//如果指定的查找位置越界了,就会按原有的最大位置或者最小位置开始查找
cout << pos << endl;
cout << pos2 << endl;
cout << ret << endl;
cout << pp << endl;
cout << ppp << endl;
}
void test_string2()
{
string s1("string.cpp.zip");
size_t pos = s1.rfind('.', 100);
size_t ret = s1.rfind('t', 4);
int pp = s1.rfind('a');
size_t ppp = s1.rfind('a');
//rfind就是倒着找的意思,两个参数,只能查找字符,第一个参数为你要查找的字符
//第2个参数为你要从那个下标开始倒着查找,返回值为那个字符在字符串中的下标位置
//如果没有指定要从哪里开始查找就默认从结尾开始查找
//如果要查找的字符字符串没有,就会返回-1
//如果指定的查找位置越界了,就会按原有的最大位置或者最小位置开始
cout << pos << endl;
cout << ret << endl;
cout << pp << endl;
cout << ppp << endl;
}
void test_string3()
{
string s1("string.cpp.zip");
string s2("string.cp\0p.zip");
string sd = s1.substr(2, 2);
string sdl = s1.substr(2, 3);
string pp = s2.substr(4);
string ppp = s2.substr(4, 100);
//substr的作用是提取字符串,两个参数,第一个是要提取的开始位置(下标)
//第2个参数为要提取的字符串的长度,提取成功后返回值为string类型的字符串
//如果没有指定提取长度就会默认提取字符串直到出现\0为止
//如果第2个参数过大就会提取到\0之前,也就是提前到能提取的最大长度
cout << sd << endl;
cout << sdl << endl;
cout << pp << endl;
cout << ppp << endl;
}
void test_string33()
{
//find rfind和substr的混合应用(分割字符串)
string file("string.cpp.zip");
size_t pos = file.rfind('.');
//string suffix = file.substr(pos, file.size() - pos);
string suffix = file.substr(pos);
cout << suffix << endl;
string url("https://gitee.com/ailiangshilove/cpp-class/blob/master/%E8%AF%BE%E4%BB%B6%E4%BB%A3%E7%A0%81/C++%E8%AF%BE%E4%BB%B6V6/string%E7%9A%84%E6%8E%A5%E5%8F%A3%E6%B5%8B%E8%AF%95%E5%8F%8A%E4%BD%BF%E7%94%A8/TestString.cpp");
size_t pos1 = url.find(':');
string url1 = url.substr(0, pos1 - 0);
cout << url1 << endl;
size_t pos2 = url.find('/', pos1 + 3);
string url2 = url.substr(pos1 + 3, pos2 - (pos1 + 3));
cout << url2 << endl;
string url3 = url.substr(pos2 + 1);
cout << url3 << endl;
}
void test_string4()
{
string s1 = "hello";
string s2 = "fword";
string s3 = s1 + s2;
// + 是重载的运算符是字符串附加的意思,+的右边的字符串附加在+左边的字符串的后面
string s4 = s1 + "ssss";//这个是有隐式类型转换的, "ssss"由char型转换成string型
cout << s3 << endl;
cout << s4 << endl;
}
void test_string5()
{
string s1 = "hello";
string s3 = "hello";
string s2 = "fword";
// <和> 是重载的运算符是两个字符串按字典序比较的意思, 如果比较正确就会输出1,否则输出0
cout << (s1 > s2) << endl;//流插入<<的优先级大于<,所以一定要加()
cout << (s1 > s3) << endl;//流插入<<的优先级大于<,所以一定要加()
}
void test_string6()
{
string s1;
//cin >> s1;
//cin默认规定空格或者换行是多个值之间分割, cin一次只能读取一个字符串
getline(cin, s1);
//getline的作用就是可以解决cin无法读全中间有空格或者换行的字符串
//getline是string的类的函数,包了头文件就可以直接单独的用,第一个参数是输入流cin,第2个参数为待输入的字符串
cout << s1 << endl;
}
void test_string7()
{
int x = 0;
int y = 0;
double y2 = 0.0;
string pp("100");
string pp2("1001");
string str = to_string(x + y);
string str3 = to_string(x + y2);
string str2 = to_string(x);
//to_string的作用是将其他类型的数据或者计算式的计算结果变成string类型,所以参数可以是式子也可以是一个变量
//所以to_string的返回值就是string类型的字符串
//to_string的作用有点像atoi函数
//to_string是string的类的函数,包了头文件就可以直接单独的用
int z = stoi(pp);
double z1 = stoi(pp);
int z2 = stoi(pp + pp2);
//stoi的作用是将string类型的数据或者计算式的计算结果变成整型,所以参数可以是式子也可以是一个变量
//所以stoi的返回值就是一个整型
//stoi的作用有点像itoa函数
//stoi是string的类的函数,包了头文件就可以直接单独的用
cout << str << endl;
cout << str2 << endl;
cout << str3 << endl;
cout << z << endl;
cout << z1 << endl;
cout << z2 << endl;
}
template<class T>
void func(const T& left, const T& right)
{
cout << "void func(const T& left, const T& right)" << endl;
}
template<>
void func<int*>(int* const& left, int* const& right)
{
cout << "void func<int*>(int* const & left, int* const & right)" << endl;
}
int main()
{
test_string1();
//test_string2();
//test_string3();
//test_string33();
//test_string4();
//test_string5();
//test_string6();
test_string7();
//bit::test_string1();
int a = 0, b = 1;
func(a, b);
func(&a, &b);
return 0;
}
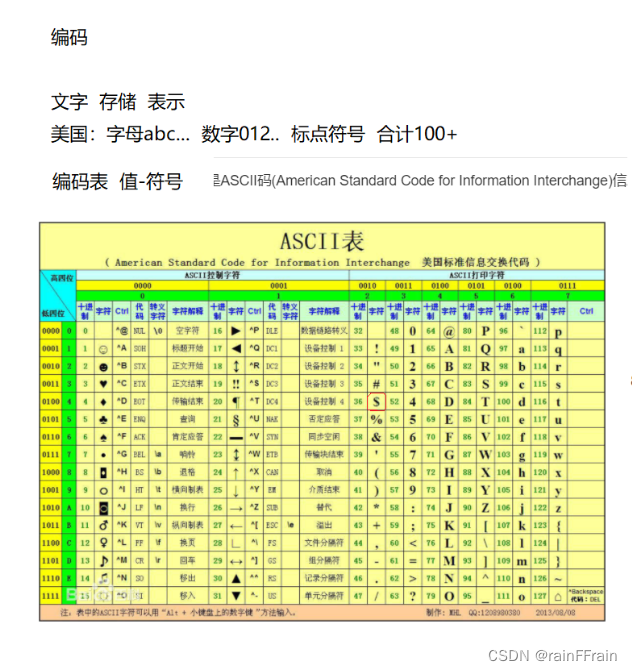
7。全中文或者有中文的字符串大小说明
#include<iostream>
#include<string>
using namespace std;
int main()
{
char s1[] = "我们";
char s2[] = "abcd";
//可以看出全是中文的字符串和全是英文的字符串在长度一样时
//所占的字节数是一样的,可以得出一个中文占的字节数是一个英文的两倍
cout << sizeof(s1) << endl;
cout << sizeof(s2) << endl;
cout << s1 << endl;
cout << s2 << endl;
return 0;
}
专业解释如下图:



8。shrink_to_fit,at,c_str,data,copy,get_allocator,compare,find_first_of,find_first_not_of,find_last_not_of,find_last_of
#include<iostream>
#include<string>
using namespace std;
void string_test1()
{
string s1("hello word");
s1.shrink_to_fit();
//shrink_to_fit的作用是缩容,使所开空间和已存数据大小相等
//resize也可以缩容,但是不常用,上面这个是专门原来缩容的
//但是这个不要经常用,不好,缩容的本质是时间换空间
//shrink_to_fit 没有参数
cout << s1 << endl;
}
void string_test2()
{
string s2 = "hello word";
cout << s2[2] << endl;
cout << s2.at(2) << endl;
//可以看出at的作用和[]一样,都是可以访问特定下标的字符。
//at有一个参数即要访问的字符的下标
//
}
void string_test3()
{
string s2("hello world");
try
{
s2[15];
s2.at(15);
//这个可以将保存报错的信息,打印出来的代码可以看出at和[]的区别
//at越界访问时会把错误信息先打印出来
//[]越界访问时会直接弄出报错弹窗的,不会打印报错信息
}
catch (const exception& e)
{
cout << e.what() << endl;
}
string file("test.cpp");
FILE* fout = fopen(file.c_str(), "r");
char ch = fgetc(fout);
while (ch != EOF)
{
cout << ch;
ch = fgetc(fout);
}
//这个c_str的作用是获取指向string的指针,也就是获取空间的首元素的地址
//用以兼容C语言
}
void string_test4()
{
//data 作用和c_str一样,属于不同时期的产物
//copy copy属于库函数,有三个参数,S.copy(A, B, C), 将S的从第B个字符开始拷贝C个字符给string A
//copy不常用一般用c_str
//get_allocator string这个类底下的一个空间配置器,暂时了解一下就行
//compare 比较函数,可以两个string类型的对比,可以string自己和自己的一部分对比,还可以string和不同类型的数据对比
//compare没什么用,看看就好,虽然功能很强大,但是用的很少
}
void string_test5()
{
//find_first_of 的意思是在一个字符串中查找find_first_of函数中输入的字符串
//的相同字符,找到相同的字符就返回对应的下标,然后再找下一个
//find_first_of 有两个参数,第一个为要查找的字符构成的字符串,第二个(可以不写就默认从开头开始查找)是查找的开始位置
//find_first_of的时间复杂度为O(N*M)
//find_first_of的作用和C语言的strtok类似且都用得比较少
//find_first_of的作用相反的是find_first_not_of和find_last_not_of
//find_first_not_of 的意思是在一个字符串中从前往后查找find_first_not_of函数中输入的字符串的不相同的字符,找到不相同的字符就返回对应的下标,然后再找下一个
//find_last_not_of 的意思是在一个字符串中从后往前查找find_last_not_of函数中输入的字符串的不相同的字符,找到不相同的字符就返回对应的下标,然后再找下一个
string str("Please, replace the vowels in this sentence by asterisks.");
int find = str.find_first_of("aeiou");
while (find != string::npos)
{
str[find] = '$';//找到就替换成$
find = str.find_first_of("aeiou", find + 1);//循环赋值
}
cout << str << endl;
}
//find_last_of的作用是取出一个路径串的path和file
//Linux下的路径和windows下的路径都可以取的
void SplitFilename(const std::string& str)
{
std::cout << "Splitting: " << str << '\n';
std::size_t found = str.find_last_of("/\\");
std::cout << " path: " << str.substr(0, found) << '\n';
std::cout << " file: " << str.substr(found + 1) << '\n';
}
int main2()
{
std::string str1("/usr/bin/man");
std::string str2("c:\\windows\\winhelp.exe");
cout << str2 << endl;
SplitFilename(str1);
SplitFilename(str2);
return 0;
}
int main()
{
//string_test1();
//string_test2();
//string_test3();
//string_test4();
string_test5();
return 0;
}
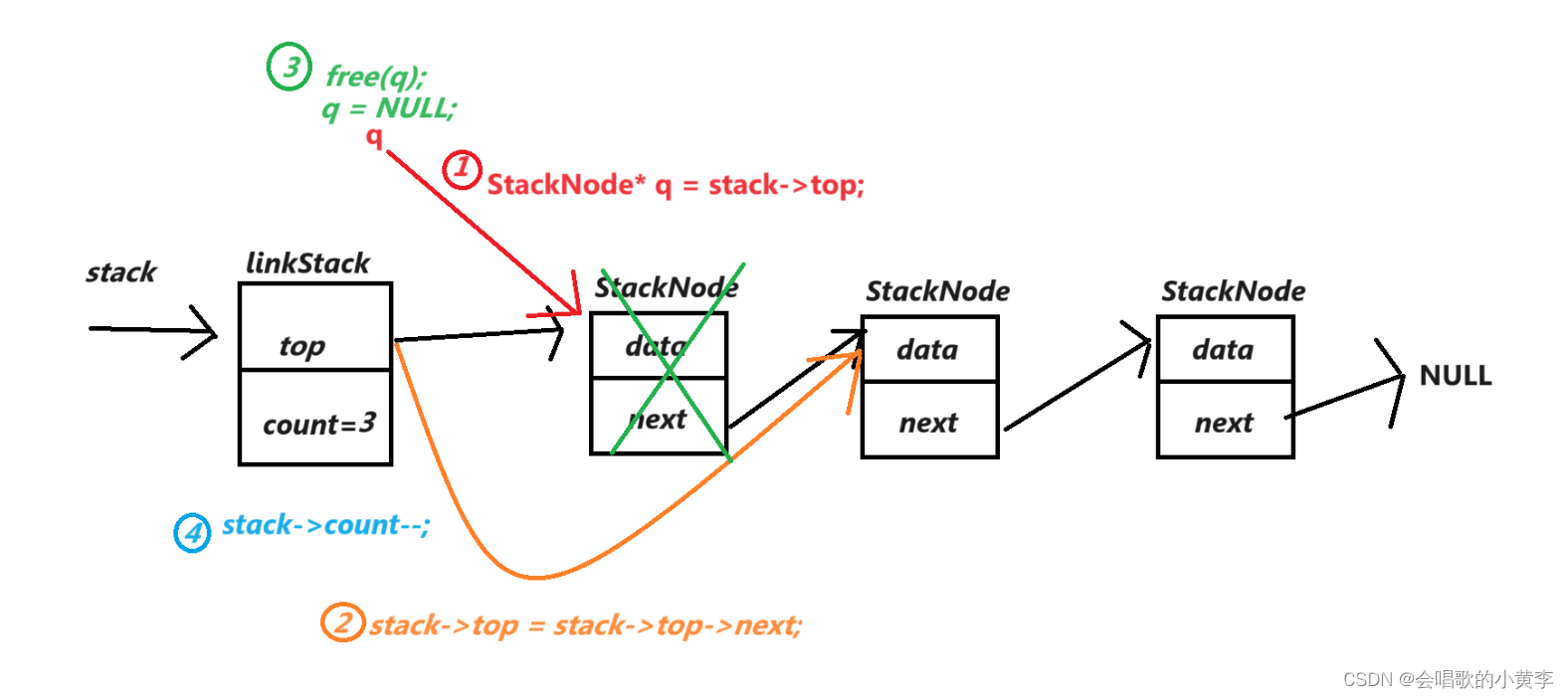
9。swap
由于std流里也有个swap,string类里面的swap和string里面的swap功能基本一致,但是由于std流里的swap进行交换时消耗比较大会生成很多拷贝构造,string里面的由于没有那么多拷贝构造,所以消耗比较小,用法也和std流里的swap基本一样。
#include <iostream>
#include <string>
main ()
{
std::string buyer ("money");
std::string seller ("goods");
std::cout << "Before the swap, buyer has " << buyer;
std::cout << " and seller has " << seller << '\n';
seller.swap (buyer);
std::cout << " After the swap, buyer has " << buyer;
std::cout << " and seller has " << seller << '\n';
return 0;
}可以看到,swap就一个参数,就是待交换的一个string类型的字符串,把待交换的字符串的内容和调用swap函数的string的内容互相交换

但是类里的std是可以交换string类型的数据的,所以可以直接使用std里面的swap交换两个string,交换两个string类型的数据时可以直接交换指向两块空间的指针,这样可以减少拷贝构造的产生。
下面自我实现和上图都有利用到!!!
10。string类(及其部分好用的比较有意义的功能)的自我实现
(本部分的test.cpp只显示了部分功能的测试,如果想自己测试更多string.cpp里的功能,可以自己进行测试,欢迎添加新功能,欢迎添加新功能)
//string.h//
#pragma once
#include<iostream>
#include<assert.h>
using namespace std;
namespace bit
{
class string
{
public:
typedef char* iterator;
typedef const char* const_iterator;
//string();构造函数
string(const char* str = "");//全缺省可以给个空的,这样没有参数也可以用
string(const string& str);//由于和string冲突了所以用&
string& operator=(const string& str);//赋值
~string();
const char* c_str() const;//打印函数
size_t size() const;//字符串的长度
char& operator[](size_t pos);//提取pos位置的元素
const char& operator[](size_t pos) const;
void reserve(size_t n);//保存或者指定长度为n, 这里相当于扩容
void push_back(char ch);//尾插一个字符
void append(const char* str);//尾插一个字符串
string& operator+=(char ch);//尾插一个字符
string& operator+=(const char* str);//尾插一个字符串
void insert(int pos, char ch);//指定位置尾插一个字符
void insert(int pos, const char* str);//指定位置尾插一个字符串
void erase(size_t pos = 0, size_t len = npos);//给定位置删除字符串
size_t find(char ch, size_t pos = 0);//查找字符
size_t find(const char* str, size_t pos = 0);//查找字符串
void swap(string& s);//字符串交换
string substr(size_t pos = 0, size_t len = npos);//提取字符
bool operator<(const string& s) const;//比较<
bool operator>(const string& s) const;//比较>
bool operator<=(const string& s) const;//比较<=
bool operator>=(const string& s) const;//比较>=
bool operator==(const string& s) const;//比较==
bool operator!=(const string& s) const;//比较!=
void clear();//string内存清0
private:
//char _buff[16];//原本还会有个buff但是我们这边就不考虑了
char* _str;
int _capacity;//空间大小
int _size;
const static size_t npos;
};
istream& operator>> (istream& is, string& str);//流写入和下面的流提取第一个参数都不是成员变量,所以不能写成成员函数
ostream& operator<< (ostream& os, const string& str);
}
//string.cpp//
#include"string.h"
namespace bit
{
const static size_t npos = -1;//得在这个域里完成对静态全局变量的定义不然会有链接错误
string::string(const char* str)
:_size(strlen(str))
{
_str = new char[_size + 1];//留个位置给\0
_capacity = _size;
strcpy(_str, str);
}
//string::string()//单独空string的初始化,也可以用全缺省的
//{
// _str = new char[1]{'\0'};
// _size = 0;
// _capacity = 0;
//}
string::string(const string& str)
{
_str = new char[str._capacity + 1];
strcpy(_str, str._str);
_size = str._size;
_capacity = str._capacity;
}
string& string::operator=(const string& str)
{
if (this != &str)
{
char* tmp = new char[str._capacity + 1];
strcpy(tmp, str._str);
delete[] _str;
_str = tmp;
_capacity = str._capacity;
_size = str._size;
}
return *this;
}
const char* string::c_str() const
{
return _str;//重载函数的函数体内做了处理,打印的是指针指向空间中的内容
}
string::~string()
{
delete[] _str;
_str = nullptr;
_capacity = 0;
_size = 0;
}
size_t string::size() const
{
return _size;
}
char& string::operator[](size_t pos)
{
assert(pos < _size);
return _str[pos];
}
const char& string::operator[](size_t pos) const
{
assert(pos < _size);
return _str[pos];
}
void string::reserve(size_t n)
{
assert(n >= _capacity);
char* tmp2 = new char[n];
strcpy(tmp2, _str);
delete[] _str;
_str = tmp2;
_capacity = n;
}
void string::push_back(char ch)
{
assert(ch != '\0');
if (_capacity == _size)
{
int newcapacity = _capacity == 0 ? 4 : 2 * _capacity;
reserve(newcapacity);
}
_str[_size] = ch;//_size位置给\0了
_str[_size + 1] = '\0';
_size++;
}
void string::append(const char* str)
{
int len = strlen(str);
reserve(_capacity + len);
strcpy(_str + _size, str);
_size = _size + len;
}
string& string::operator+=(char ch)
{
assert(ch != '\0');
push_back(ch);
return *this;
}
string& string::operator+=(const char* str)
{
append(str);
return *this;
}
void string::insert(int pos, char ch)//pos的类型不要写成size_t
{
assert(ch != '\0');
assert(pos <= _size);
assert(pos >= 0);
if (_capacity == _size)
{
int newcapacity = _capacity == 0 ? 4 : 2 * _capacity;
reserve(newcapacity);
}
int end = _size;
while (end >= pos)//不然这边两个数比较一定要先统一类型(int)pos
{
_str[end + 1] = _str[end];
end--;
}
_str[end + 1] = ch;
}
//另一种写法
size_t end = _size + 1;
while (end > pos)
{
_str[end] = _str[end - 1];
--end;
}
_str[pos] = ch;
++_size;
void string::insert(int pos, const char* str)
{
assert(pos <= _size);
assert(pos >= 0);
int len = strlen(str);
reserve(_capacity + len + 1);
int end2 = _size;//结尾有个\0
int end = _capacity - 1;
while (end2 >= pos)
{
_str[end] = _str[end2];
end--;
end2--;
}
memcpy(_str + end2 + 1, str, len);
}
void string::erase(size_t pos = 0, size_t len = npos)
{
assert(pos < _size);
if (len >= _size - pos)
{
_str[pos] = '\0';
_size = pos;
}
else
{
memcpy(_str + pos, _str + pos + len, len);
_size = _size - len;
}
}
size_t string::find(char ch, size_t pos)
{
for (int i = pos; i < _size; i++)
{
if (_str[i] == ch)
{
return i;
}
}
return npos;//没有找到就返回一个无穷大的数
}
size_t string::find(const char* sub, size_t pos)
{
char* p = strstr(_str + pos, sub);//strtsr就作用是找到字串找到就返回,找不到就返回nullptr
return p - _str;//指针减指针得到一个相对位置
}
void string::swap(string& s)
{
std::swap(_str, s._str);//库里的swap可以完成指针及其指向空间的交换, 交换指向的指针就可以了
std::swap(_capacity, s._capacity);
std::swap(_size, s._size);
}
string string::substr(size_t pos, size_t len)
{
assert(pos < _size);
assert(pos >= 0);
int i = 0;
//len大于后面剩余字符,有多少取多少
if (len > _size - pos)
{
string u(_str + pos);//强制性类型转换成string再赋值
return u;
}
else
{
string u;//创建一个空string
u.reserve(len);
for (int i = 0; i < len; i++)
{
//u += _str[pos + i];//尾插法
u._str[i] = _str[pos + i];
}
return u;
}
}
bool string::operator<(const string& s) const
{
int ret = strcmp(_str, s._str);
if (ret < 0)
{
return ret;
}
else
{
return npos;
}
}
bool string::operator>(const string& s) const
{
return !(*this <= s._str);//学会复用
}
bool string::operator<=(const string& s) const
{
int ret = strcmp(_str, s._str);
if (ret > 0)
{
return npos;
}
else
{
return ret;
}
}
bool string::operator>=(const string& s) const
{
return !(*this < s._str);
}
bool string::operator==(const string& s) const
{
int ret = strcmp(_str, s._str);
if (ret == 0)
{
return ret;
}
else
{
return npos;
}
}
bool string::operator!=(const string& s) const
{
return !(*this == s._str);
}
void string::clear()
{
_str[0] = '\0';
_size = 0;
}
istream& operator>> (istream& is, string& str)
{
str.clear();
char ch = is.get();//系统自动写入is后,先读取第一个字符
while (ch != ' ' && ch != '\0')//注意是用&&
{
str += ch;//如果满足条件就尾插在后面
ch = is.get();//可以实现反复读取的,再get一下就再次读取下一个
//为什么不用>>而是用is.get(),因为>>, 不能提取/0和换行,所以不能判断,scanf可以读取空格和换行
}
return is;
}
ostream& operator<< (ostream& os, const string& str)
{
for (int i = 0; i < str.size(); i++)
{
os << str[i];
}
return os;
}
}
//test.cpp//
#include"string.h"
int main()
{
bit::string s2("hello word");
cout << s2.c_str() << endl;
//s2.insert(2, 'p');
//cout << s2.c_str() << endl;
s2.insert(2, "pp");
cout << s2.c_str() << endl;//流提取可以传入一个指针,这样就会打印指针指向的内容
return 0;
}