今日学习了解了常见的几种神经网络基础架构。
1.卷积神经网络
卷积神经网络CNN是一种人工神经网络,旨在处理和分析具有网格状拓扑结构的数据,如图像和视频。将 CNN 想象成一个多层过滤器,可处理图像以提取有意义的特征并进行推理预测。
想象一下,假设我们有一张手写数字的照片,希望计算机能识别出这个数字。CNN的工作原理是在图像上应用一系列滤波器,逐渐提取出越来越复杂的特征。浅层的滤波器检测边缘和线条等简单特征,而深层的滤波器则检测形状和数字等更复杂的模式特征。
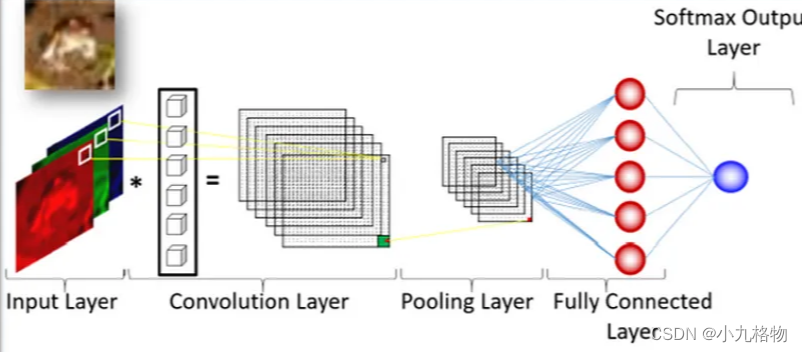
CNN 的层可分为三种主要类型:卷积层、池化层和全连接层。
● 卷积层:这些层将滤波器应用于图像。每个滤波器在图像上滑动,计算滤波器与其覆盖像素之间的点积。这一过程会生成新的特征图,突出图像中的特定模式。这个过程会用不同的滤波器重复多次,从而生成一组捕捉图像不同方面的特征图。
● 池化层:池化层对特征图进行下采样操作,在保留重要特征的同时减少数据的空间维度。这有助于降低计算复杂度,防止过拟合。最常见的池化类型是最大值池化,它从像素的一个小邻域中选择最大值。
● 全连接层:这些层与传统神经网络中的层类似。它们将一层中的每个神经元与下一层中的每个神经元连接起来。卷积层和池化层的输出会被平铺并通过一个或多个全连接层,从而让网络做出最终预测,例如识别图像中的数字。
总之,CNN是一种神经网络,旨在处理结构化数据,如图像。它的工作原理是对图像应用一系列滤波器或核函数,逐渐提取更复杂的特征。然后,通过池化层,以减少空间维度,防止过度拟合。最后,输出将通过全连接层进行最终预测。
2.循环神经网络
循环神经网络RNN是一种人工神经网络,旨在处理时间序列、语音和自然语言等序列数据。将RNN 想象成传送带,一次处理一个元素的信息,从而 "记住 "前一个元素的信息,对下一个元素做出预测。想象一下,我们有一串单词,我们希望计算机生成这串单词中的下一个单词。RNN 的工作原理是每次处理序列中的每个单词,并利用前一个单词的信息预测下一个单词。
RNN 的关键组成部分是递归连接,它允许信息从一个时间步流动到下一个时间步。递归连接是神经元内部的一个连接,它能 "记住 "上一个时间步的信息。
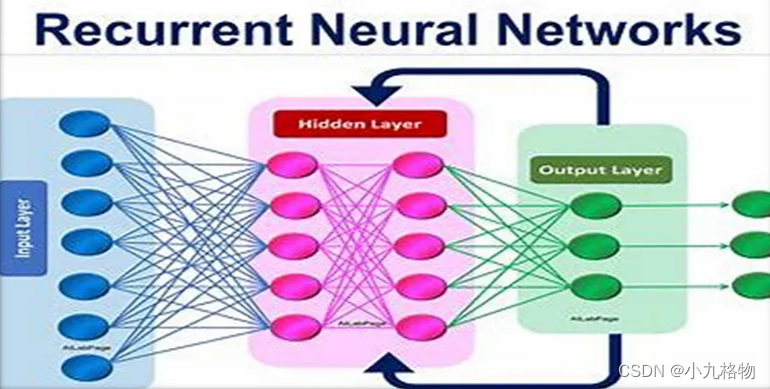
RNN 可分为三个主要部分:输入层、递归层和输出层。
● 输入层:输入层接收每个时刻的输入信息,例如序列中的一个单词。
● 递归层:递归层处理来自输入层的信息,利用递归连接 "记忆 "前一时刻的信息。递归层包含一组神经元,每个神经元都与自身有递归连接,并与当前时刻的输入进行连接。
● 输出层:输出层根据递归层处理的信息生成预测结果。在生成序列中下一个单词的情况下,输出层会预测序列中前一个单词之后最有可能出现的单词。总之,RNN 是一种用于处理顺序数据的神经网络。它每次处理一个元素的信息,利用递归连接来 "记忆 "前一个元素的信息。递归层允许网络处理整个序列,使其非常适合语言翻译、语音识别和时间序列预测等任务。
3.生成对抗网络
生成对抗网络GAN是一种深度学习架构,它使用两个神经网络(生成器和判别器)来创建新的、逼真的数据。将 GAN 想象成两个敌对的艺术家,一个创造假艺术,另一个则试图辨别真假。GAN 的目标是在图像、音频和文本等不同领域生成高质量的真实数据样本。生成器网络创建新样本,而判别器网络则评估所生成样本的真实性。这两个网络以对抗的方式同时进行训练,生成器试图生成更逼真的样本,而判别器则更善于检测伪造样本。
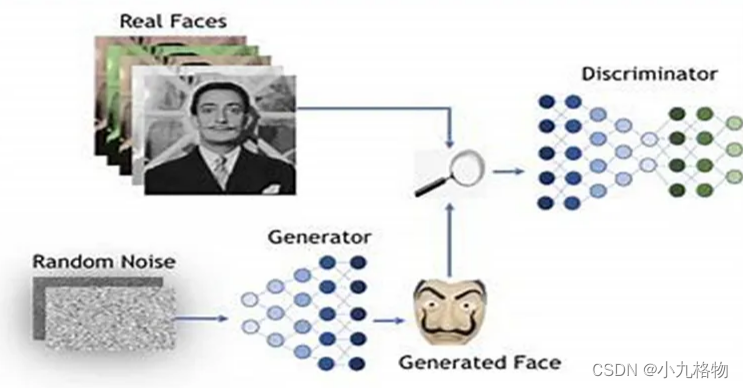
GAN 的两个主要组成部分如下:
● 生成器:生成器网络负责创建新样本。它将随机噪声向量作为输入,并生成输出样本,如图像或句子。生成器通过最小化损失函数来测量生成样本与真实数据之间的差异,从而训练生成更真实的样本。
● 判别器:判别器网络评估生成样本的真伪。它将一个样本作为输入,然后输出一个概率,表明该样本是真的还是假的。判别器通过损失函数来测量真实样本和生成样本概率之间的差异,从而训练判别器分辨真假样本。GAN的对抗性源于生成器和判别器之间的竞争。生成器试图生成更逼真的样本来欺骗判别器,而判别器则试图提高自己分辨真假样本的能力。这个过程会一直持续下去,直到生成器生成高质量、逼真的数据,而这些数据很难与真实数据区分开来。总之,GAN是一种深度学习架构,它使用两个神经网络(生成器和判别器)来创建新的真实数据。生成器创建新样本,判别器评估样本的真实性。这两个网络以对抗的方式进行训练,生成器生成更逼真的样本,而判别器则提高检测真假样本的能力。GAN目前可应用于各种领域,如图像和视频生成、音乐合成和文本到图像合成等。
4.Transformers架构
Transformers是一种神经网络架构,广泛应用于自然语言处理NLP任务,如翻译、文本分类和问答系统。它们是在 2017 年发表的开创性论文 "Attention Is All You Need "中引入的。将Transformers想象成一个复杂的语言模型,通过将文本分解成更小的片段并分析它们之间的关系来处理文本。然后,该模型可以对各种查询生成连贯流畅的回复。
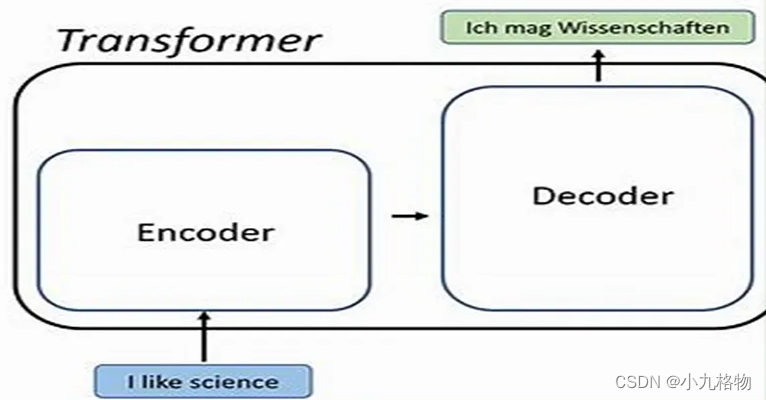
Transformers由多个重复模块组成,称为层。每个层包含两个主要组件:
● 自注意力机制:自注意力机制允许模型分析输入文本不同部分之间的关系。它的工作原理是为输入序列中的每个单词分配权重,以显示其与当前上下文的相关性。这样,模型就能将注意力集中在重要的词语上,而淡化不那么相关的词语的重要性。
● 前馈神经网络:前馈神经网络是处理自我注意机制输出的多层感知机。它们负责学习输入文本中单词之间的复杂关系。Transformers的关键创新之处在于使用自注意机制,这使得模型能够高效处理长序列文本,而无需进行昂贵的递归或卷积操作。这使得Transformers的计算效率高,能有效地完成各种NLP 任务。简单地说,Transformers是一种功能强大的神经网络架构,专为自然语言处理任务而设计。它们通过将文本分解成更小的片段,并通过自注意机制分析片段之间的关系来处理文本。这样,该模型就能对各种查询生成连贯流畅的回复。
5.encoder-decoder架构
编码器-解码器架构在自然语言处理NLP任务中非常流行。它们通常用于序列到序列问题,如机器翻译,其目标是将一种语言(源语言)的输入文本转换为另一种语言(目标语言)的相应文本。
把编码器-解码器架构想象成一个翻译员,他听一个人说外语,同时将其翻译成听者的母语。
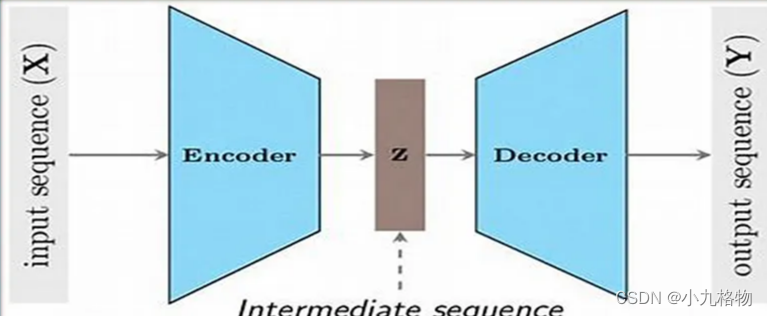
该架构由两个主要部分组成:
● 编码器:编码器接收输入序列(源文本)并按顺序进行处理,生成一个紧凑的表示形式,通常称为 context vector或context embedding。这种表示概括了输入序列,并包含有关其语法、语义和上下文的信息。编码器可以是递归神经网络RNN,也可以是Transformers,具体取决于具体任务和实现方式。
● 解码器:解码器采用编码器生成的上下文向量,逐个元素生成输出序列(目标文本)。解码器通常是一个递归神经网络或Transformers,与编码器类似。它根据前面的单词和上下文向量中包含的信息预测目标序列中的下一个单词,从而依次生成输出序列。
在训练期间,解码器接收真实的目标序列,其目标是预测序列中的下一个单词。在推理过程中,解码器接收直到此时为止生成的文本,并用它来预测下一个单词。
总之,编码器-解码器架构是自然语言处理任务中的一种流行方法,尤其适用于序列-序列问题,如机器翻译。该架构由一个编码器和一个解码器组成,编码器负责处理输入序列并生成一个紧凑的向量表示,解码器负责根据该表示生成输出序列。这样,该模型就能将一种语言的输入文本翻译成另一种语言的相应文本。